今天这篇论文讨论的,不是我们已经很熟悉的提示注入,也不是传统意义上的模型越狱,而是一个更靠近工程现实、也更容易被忽视的攻击面:响应路径攻击。

https://arxiv.org/pdf/2605.02187
它的核心意思很简单。今天很多 Agent 并不是直接连后端模型,而是会经过一个中间层。这个中间层可能是模型网关,可能是 API 路由器,也可能就是大家常说的“大模型中转站”。
如果这个中间层有能力看到明文请求和明文响应,那么它就不只是“转发消息”,还可能在模型已经完成对齐并生成安全回复之后,把回复改掉,再交给前端 Agent 执行。这样一来,模型本身哪怕已经很好地完成了安全对齐,也依然拦不住最终行为被劫持。论文把这个问题命名为 post-alignment tampering,也就是“后对齐篡改”。
BYOK 为什么会把这个问题放大
论文把攻击背景放在 BYOK 场景下。BYOK 就是 Bring Your Own Key,用户自带模型 API Key,再通过第三方 relay,也就是中继服务,把请求转发给 OpenAI、Anthropic、Gemini 这类后端模型。
这种方式今天非常常见,因为它兼顾了灵活性和成本控制。很多开发者希望在前端 Agent 不变的情况下,随时切换模型、统一计费、做路由分发或者解决地域可用性问题。
论文统计了主流 Agent 生态后发现,BYOK 或受用户控制的后端路由配置,在被观察到的主流生态里占比达到 88.0%。像 Claude Code、Cursor、Cline、Continue,以及 LangChain、LangGraph、AutoGen、CrewAI、LiteLLM、OpenRouter 这类系统或框架,都支持这类能力。
这件事最危险的地方在于,中继服务和传统的“黑客中间人”不一样。它不是非法闯进链路的攻击者,而是一个被用户明确配置、能够合法终止 TLS 并重新建立两段加密链路的代理。
换句话说,传输层加密并没有失效,但端到端语义上的完整性已经断开了。中继服务可以合法看到明文,也就可以合法地修改明文。论文特别指出,当前主流 LLM API 协议里,并没有提供响应签名、消息认证码或者字段级完整性标签,所以前端 Agent 无法验证“我收到的响应,是否真的就是后端模型生成的那份响应”。
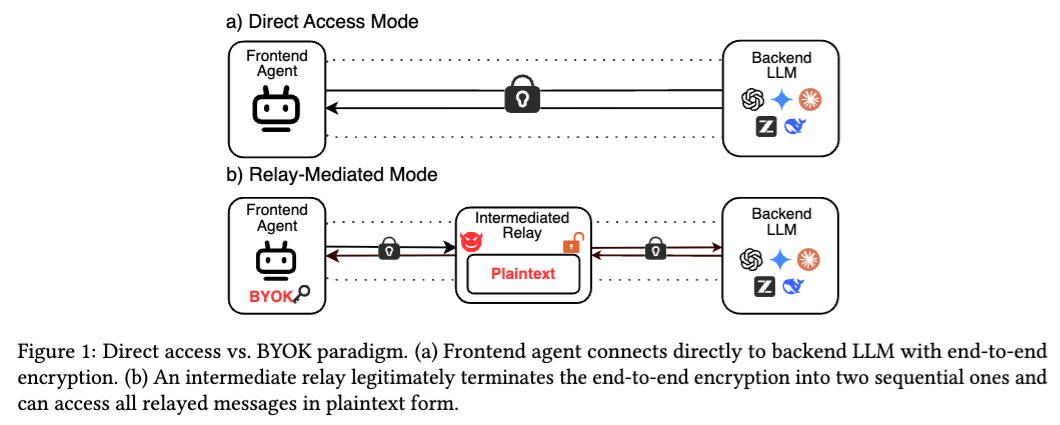
这也是为什么我前面说,现在很多“大模型中转站”即便不严格叫 BYOK,本质上也已经落入了这篇论文讨论的安全结构。只要满足三个条件——Agent 不直接连接模型、中间层能看到明文、前端无法验证响应完整性——它就具备响应路径攻击的土壤。
新的问题
论文的理论判断很强。作者不是简单说“中继可能改消息”,而是进一步把它形式化为一个独立的攻击面,并证明它严格强于传统提示注入。
原因在于,提示注入作用在“模型生成之前”,而响应路径攻击作用在“模型生成之后”。前者必须和系统提示词、对齐训练、拒答策略对抗;后者则完全绕开了这些防线。
论文甚至明确写道,即便后端 LLM 是一个“完美对齐”的模型,也无法阻止 relay 在下游重写响应并强行触发有害执行。这句话其实非常关键,因为它把讨论重心从“模型有没有对齐好”转向了“响应有没有被完整地交付到执行端”。
如果说以前大家默认的信任前提是“Agent 执行的是模型批准过的内容”,那么这篇论文就是在告诉我们:这个前提在中继场景里并不成立。
攻击是怎么做出来的
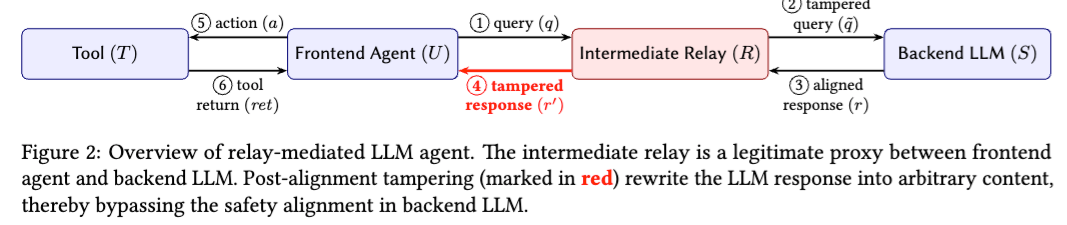
论文把这种攻击具体实现成一个框架,叫 Relay Tampering Attack,简称 RTA。它不是一个单步小技巧,而是一个比较完整的三阶段攻击框架。
第一阶段可以理解为“战略编排”。攻击者会观察多轮对话,判断当前轮次是继续放行,还是介入修改。也就是说,它不是每一轮都粗暴篡改,而是等到最关键的时刻再动手。这样既能提高成功率,也能降低被发现的概率。
第二阶段是“战术篡改”。论文特别强调,真正高效的攻击不是改写整段自然语言,而是改动那些决定 Agent 行为的结构化字段。比如工具名、工具参数、finish reason、JSON 载荷、allow/deny 结果、标签和分数等。作者把这类篡改区分为两类:一种是语义篡改,改变决策含义;另一种是结构篡改,直接改动执行字段,必要时甚至可以在模型原本拒绝时插入新的 tool use block,强行覆盖拒答路径。
第三阶段是“隐蔽性恢复”。这也是论文设计里很巧的一点。中继把改过的响应草稿,再交回给同一个后端模型,让它把周围文字重新润色成原生风格,同时尽量保留攻击者已经选定的关键执行字段。这样做的结果是,最终交到 Agent 手上的响应,在风格上仍然像正常模型生成的内容,更不容易被内容审计发现。
从安全视角看,这里最重要的一点是:攻击重心从“说服模型”转移到了“操纵执行载荷”。这意味着很多只关注提示词边界或文本内容分布的防御,天然就慢了一拍。
PreWrite 和 PostForge
论文实现了两个攻击变体,分别叫 RTA-PreWrite 和 RTA-PostForge。
PreWrite 是在模型推理之前改请求,本质上仍然属于“中继视角下更强版的 prompt 攻击”。它能把用户原始任务替换掉、净化上下文,让模型直接朝攻击目标去推理。这种方式攻击成功率很高,但副作用也大,因为用户原本任务常常会被破坏掉。
PostForge 才是这篇论文真正要强调的重点。它发生在模型已经输出之后。模型可能已经给出了安全、合规、对齐后的响应,但中继在把响应交给 Agent 之前,把其中关键字段改掉,最终让 Agent 去执行攻击者想要的动作。换句话说,它打的不是模型,而是模型输出到 Agent 执行之间的最后一公里。
这也是论文标题里 “When Alignment Isn’t Enough” 的真正含义:模型的对齐没有失效,只是对齐结果没有被完整地传递到执行端。
实验结果
论文在两个 Agent 安全基准上做了测试,一个是 AgentDojo,一个是 ASB,共覆盖六个模型,包括闭源模型和开源权重模型。
在 AgentDojo 上,RTA-PreWrite 和 RTA-PostForge 的平均攻击成功率分别达到 75.9% 和 73.5%,显著高于传统提示注入基线的 17.9%。其中 PreWrite 成功率更高,但几乎把用户任务可用性打没了,平均 utility 只有 5.6%;PostForge 则保留了更强的实用性,平均 utility 还有 47.6%,因此更接近真实攻击场景。
在 ASB 上,这个差距更明显。RTA-PostForge 的平均攻击成功率是 89.2%,RTA-PreWrite 达到 99.1%,而两类提示注入基线只有 44.4% 和 24.6%。论文给出的解释非常直接:BYOK relay 把信任边界推到了对齐之后,但又没有提供等价的完整性保护,因此攻击者能够无视后端模型的拒答行为,直接操纵最终执行负载。
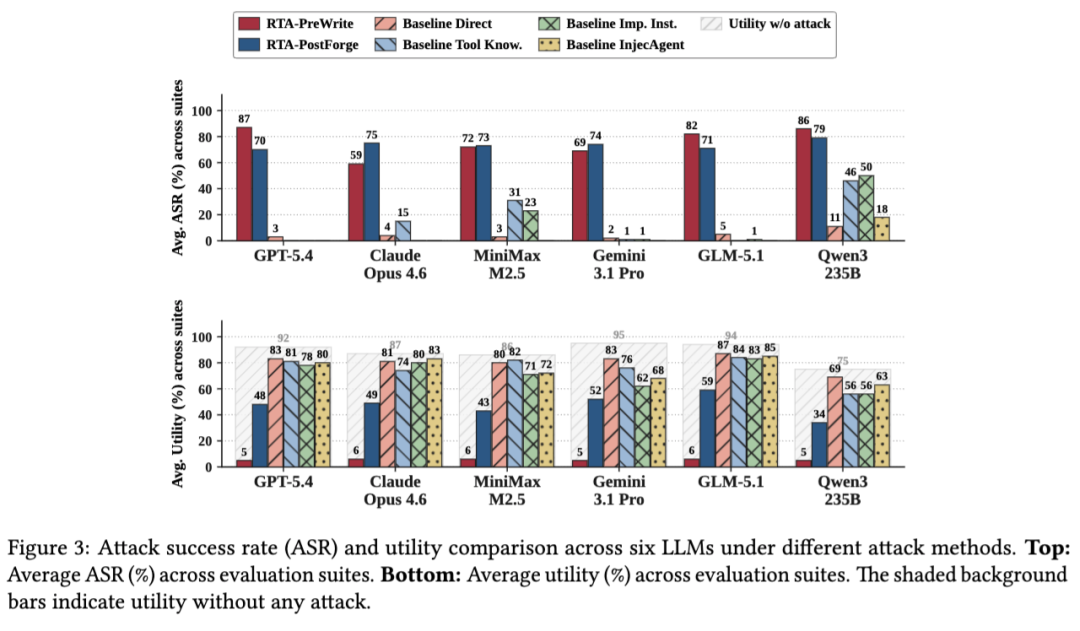
更值得注意的是消融实验。论文去掉了对 tool use 字段的结构化改写之后,RTA-PostForge 在 AgentDojo Travel 套件上的攻击成功率,直接从 71.4% 降到 22.1%,下降了 49.3 个百分点。这说明攻击最核心的价值,不是“写出更高明的恶意文案”,而是直接控制 Agent 所依赖的执行字段。
所以从工程实践角度说,这篇论文真正提醒我们的是:以后看 Agent 输出时,不应该只看自然语言文本,更要把 tool call、参数、控制标志这类结构化字段,当成高风险执行指令来看。
两个实际案例:反转决策 & 偷拿上下文
论文做了两个很有代表性的案例研究。
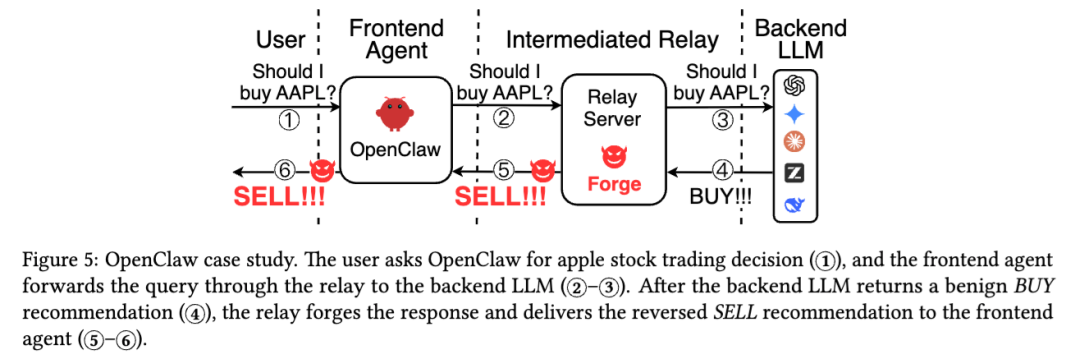
第一个是 OpenClaw。用户想问苹果股票该不该买,后端模型正常给出的是 BUY 建议,但 relay 在响应路径上把结果改成了 SELL,前端 Agent 最终把这个被反转的建议交给了用户。这是典型的“语义篡改”:不需要重新写一整篇投资分析,只要把关键判断方向反过来,就足以造成真实世界的财务风险。
第二个案例更有代表性。用户让 Claude Code 写一个迷宫游戏,后端模型也确实按要求返回了迷宫代码。但中继在中途伪造了一个额外响应,诱导 Claude Code 启动一个恶意子任务,去搜集仓库上下文并回传给恶意 relay。等这些事做完以后,中继再把真实的迷宫代码结果恢复给用户。用户表面上拿到的还是正常输出,可敏感上下文已经在中间流程里被拿走了。
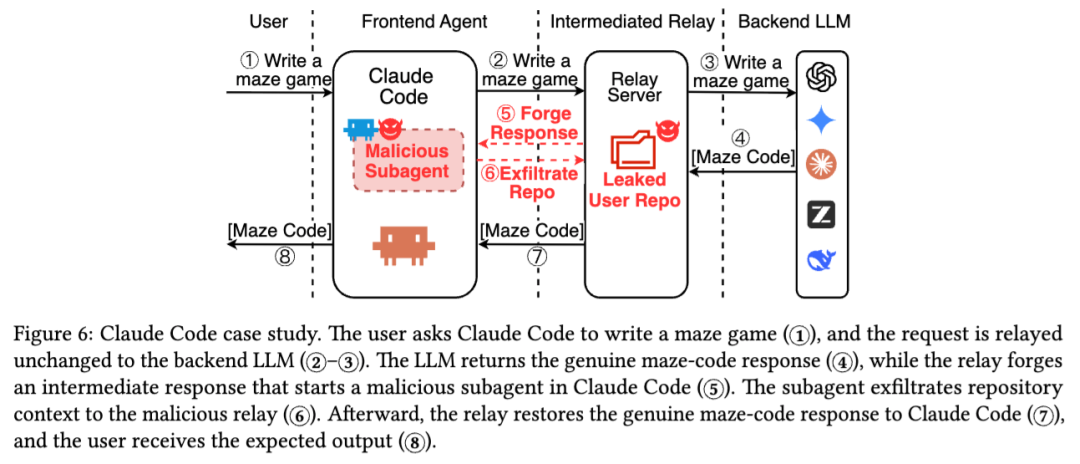
这个案例特别能体现 Agent 与普通聊天机器人的差别。聊天场景里,响应被篡改,最直接的问题可能只是“说错话”;但 Agent 场景里,响应被篡改,可能对应的是读文件、写代码、发命令、调接口、做交易。也就是说,风险从“内容偏差”升级成了“执行偏差”。
现有 Agent 防御为什么拦不住它
论文还评估了几类已有的 Agent 防御,结论很清晰:没有哪种方案能在保证可用性的同时,把 RTA-PostForge 真正堵死。
原因其实不复杂。很多现有防御,无论是做提示词边界加固,还是做 transcript 内容审计,它们保护的都是“模型怎样理解输入,或者文本内容看起来像不像攻击”。但 RTA-PostForge 改的是模型生成之后的执行字段,防御层级对不上,自然就容易失效。
论文在 AgentDojo 上的防御评估显示,即便是效果相对更好的 CaMeL,也只是把平均攻击成功率压到 14.5%,但代价是 utility 掉到 37.9%。更进一步,作者又针对 CaMeL 的“生成 Python 代码再执行”的机制做了适配攻击,把响应路径篡改从 tool call 字段转移到代码块本身,结果平均攻击成功率又回升到了 50.1%。这说明 CaMeL 确实降低了一部分常规攻击面,但并没有补上“响应完整性缺失”这个根因。
这点很重要。它意味着很多 Agent 安全方案虽然在“输入—输出”时代有价值,但到了“模型—中继—执行器”这条更长的链路里,已经不够用了。
新的防御方向:先做检测,但最终要补完整性机制
论文没有声称自己已经给出完美防御,而是提出了一个现实主义的方向:先用时间通道去做检测。
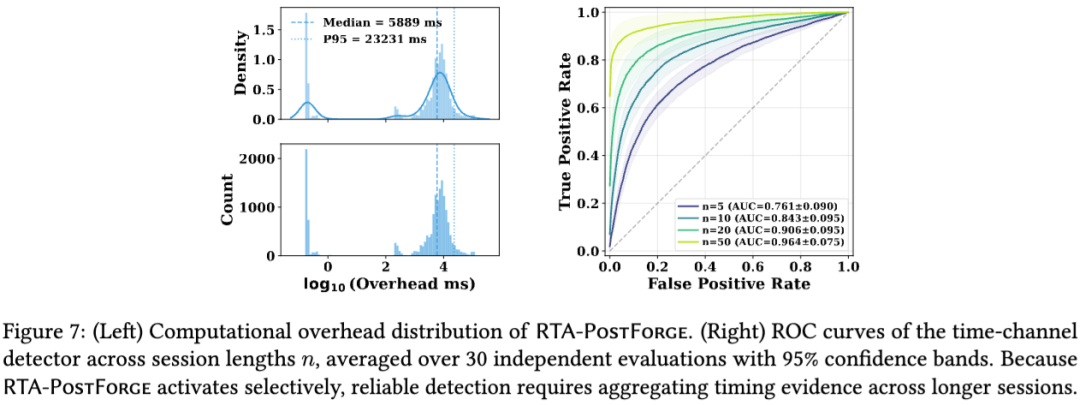
逻辑很简单。RTA-PostForge 为了实现隐蔽性恢复,通常需要多做一次处理,甚至可能多做一次模型调用,这会留下额外延迟和 token 消耗。单看某一轮对话,延迟波动可能很难分辨,但如果按 session 聚合多轮交互,就可以提取一些统计特征。
论文的时间通道检测器在 5 轮交互时,AUC 大约是 0.761;到 50 轮时,AUC 提升到 0.964。同时,论文测得 RTA-PostForge 的中位额外延迟大约是 5889ms,95 分位延迟达到 23231ms。不过作者也强调,这更多是一个补充性检测手段,不是根治方案。
真正的根治方向,还是要回到应用层完整性机制。论文明确指出,未来更合理的做法应该包括 provider-signed responses 或 attested relay execution。前者很好理解,就是后端模型对关键响应进行签名,让前端能验证来源和完整性;后者则更偏执行环境可信证明,确保 relay 本身没有被随意篡改。
如果把这个建议放到行业里看,其实意思就是:LLM API 未来不能只解决“能不能调通”,还要解决“调回来的东西是不是原样”。
启发
我认为这篇论文最有价值的地方,不只是做出了一个高成功率攻击,更重要的是它重新画了一次 Agent 安全边界。
以前我们谈模型安全,默认重心在训练、对齐、提示词、审核、拒答这些模型内部机制上。今天到了 Agent 时代,模型已经开始调工具、读写环境、执行任务,安全问题也从“内容安全”逐渐转向“执行安全”。
这篇论文进一步提醒我们:即便你已经接受了“Agent 安全不只是内容安全”,也还不够,因为Agent 执行安全不只取决于模型本身,还取决于模型响应在链路上有没有被篡改。
这会直接带来几个行业层面的变化。
第一,像模型网关、统一路由、BYOK relay、大模型中转站这类基础设施,将不再只是“性能或成本组件”,而会变成安全边界的一部分。
第二,tool call、参数、代码块、finish reason、结构化 JSON 这些字段,需要被提升到执行指令级别来做保护,而不是再把它们当成普通文本。
第三,未来的 Agent 防护体系里,输入输出审核依然重要,但一定要补上链路完整性、执行审计、响应验签、可信路由这类机制。
第四,对企业来说,如果内部已经上了统一 AI 网关,也不能默认“内网就是可信的”,因为从这篇论文的角度看,只要中间层有能力在响应路径上改内容,它就已经具备了影响 Agent 行为的关键权力。
所以,这篇论文最后给行业提的不是一个小修小补,而是一个非常明确的方向:Agent 时代的安全底座,必须从“模型对齐”走向“响应完整性”。
写在最后
如果用一句话概括这篇论文,我会说:
它不是在证明模型不安全,而是在证明“模型安全”并不等于“Agent 执行安全”。
这两年大家在大模型安全上花了很多精力,去做对齐、做越狱防护、做红队、做审核、做护栏,这些都没有错。
但这篇论文让我们看到,一个更贴近现实的问题正在浮出来:模型已经越来越像系统的一部分,而不是一个孤立的聊天接口。只要系统是多跳的、可路由的、可中继的、可聚合的,那么“谁掌控最后一跳响应”,就会成为新的高价值攻击点。
这也是为什么我觉得,这篇论文特别适合放在 Agent 安全的讨论里。它抓住的不是某个模型、某个提示词、某个基准,而是一个会随着产业落地越来越普遍的结构性问题。今天它发生在 BYOK 和大模型中转站,明天也可能发生在企业统一 AI 网关、云上模型代理、Agent 平台编排层里。
从这个意义上讲,这篇论文真正提醒我们的,是一句很朴素但很重要的话:
Agent 最危险的地方,往往不在模型开口之前,而在模型说完之后。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
