过去谈 Agent 安全,很多讨论都会自然落到提示注入上。
网页里藏一段恶意指令,文档里混入诱导内容,工具返回结果污染上下文,攻击者通过语义伪装让 Agent 改变原始任务。这些问题当然重要,也确实构成了 Agent 落地过程中的高频风险。
但最近一篇论文提出了一个更底层的问题:即使提示注入被完全解决,多 Agent 系统仍然会面临一种独立的安全挑战。这个挑战不是“模型有没有被骗”,而是“权限在多 Agent 工作流中有没有被正确传递”。
这篇论文题为 《Authorization Propagation in Multi-Agent AI Systems: Identity Governance as Infrastructure》,作者将这个问题称为 Authorization Propagation,授权传播。

https://arxiv.org/pdf/2605.05440
论文的核心观点很直接:多 Agent 系统里的身份治理不能只是一个中间件、一个网关策略,或者一次性权限检查,而应该被当成基础设施来设计。授权状态必须在每一次数据检索、每一次任务委托、每一次结果合成中持续被检查。
Agent 安全不能只盯提示注入
这篇论文一开始就反驳了一个常见判断:提示注入是 Agent 时代最核心的新安全问题,只要像 Web 时代解决 SQL 注入那样,在架构上把数据和指令分离,剩下的问题就可以回到传统安全里解决,比如认证、授权、网络隔离和密钥管理。
作者认为,这个类比只说对了一半。
提示注入确实是 Agent 时代很重要的攻击向量,但它不是唯一的新问题。多 Agent 系统还会产生一种结构性问题:非人类主体,也就是 Agent,会代表用户访问数据、调用工具、拆分任务、委托其他 Agent、合成多个数据源的结果。在这个过程中,系统必须持续证明一件事:最终返回给用户的结果,仍然没有越过原始授权边界。
这和提示注入的差别很关键。
提示注入通常需要攻击者把恶意内容放进 Agent 的处理路径里。授权传播则不一定需要攻击者。只要系统中存在多个 Agent、多个数据源、多个工具和多个授权边界,问题就会自然出现。
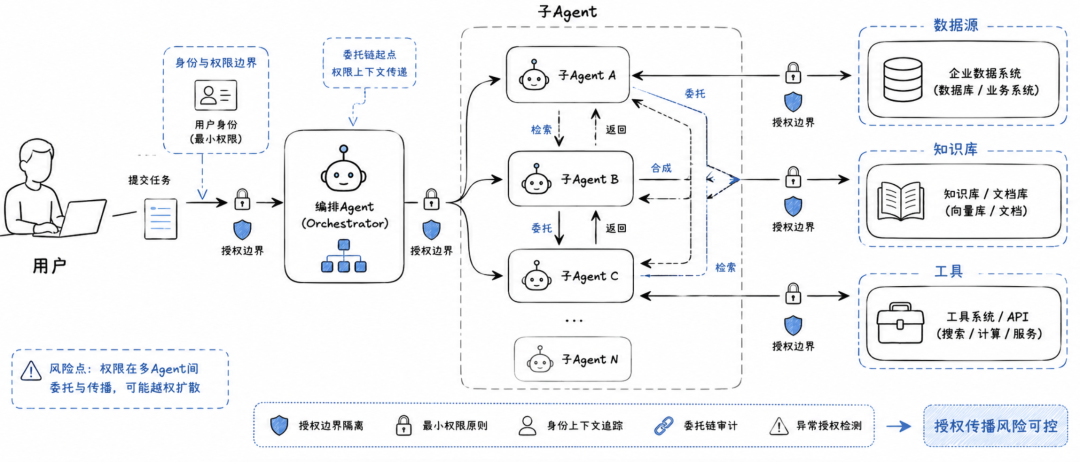
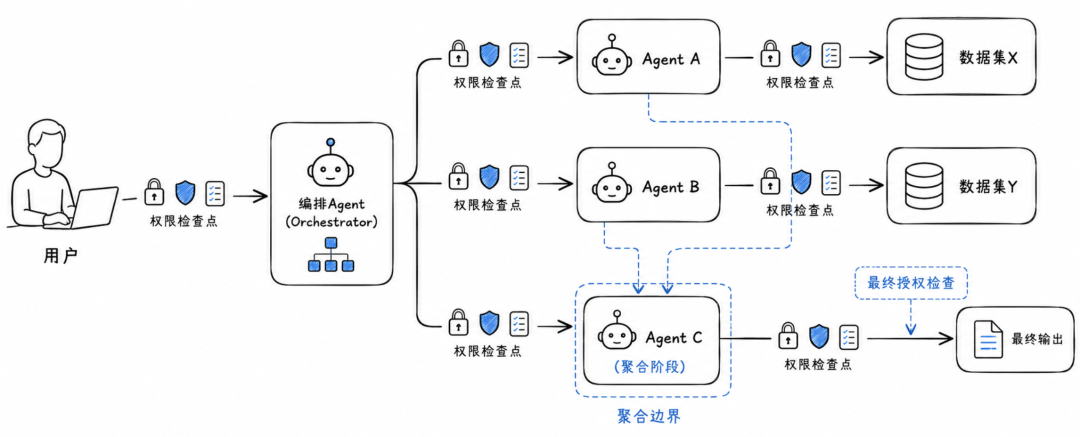
举个简单场景:一个编排 Agent 接到用户任务后,把任务拆给三个子 Agent。Agent A 读取 Dataset X,Agent B 读取 Dataset Y,Agent C 把 A 和 B 的结果合成后返回给用户。
即使这三个 Agent 都没有受到提示注入攻击,系统仍然要回答几个问题:A 是否有权访问 X,B 是否有权访问 Y,C 是否有权看到 A 和 B 的组合结果,用户是否有权看到最终答案,X 和 Y 组合之后是否暴露了单独数据源不会暴露的信息。论文明确指出,这些都是授权问题,不是提示注入问题。
换句话说,提示注入问的是:Agent 有没有被恶意内容操控。
授权传播问的是:Agent 在正常执行任务时,权限有没有沿着工作流正确传递。
这也是这篇论文最值得关注的地方。它把 Agent 安全从“内容是否危险”推进到了“执行链是否可治理”。
所谓“授权传播”,到底传播的是什么?
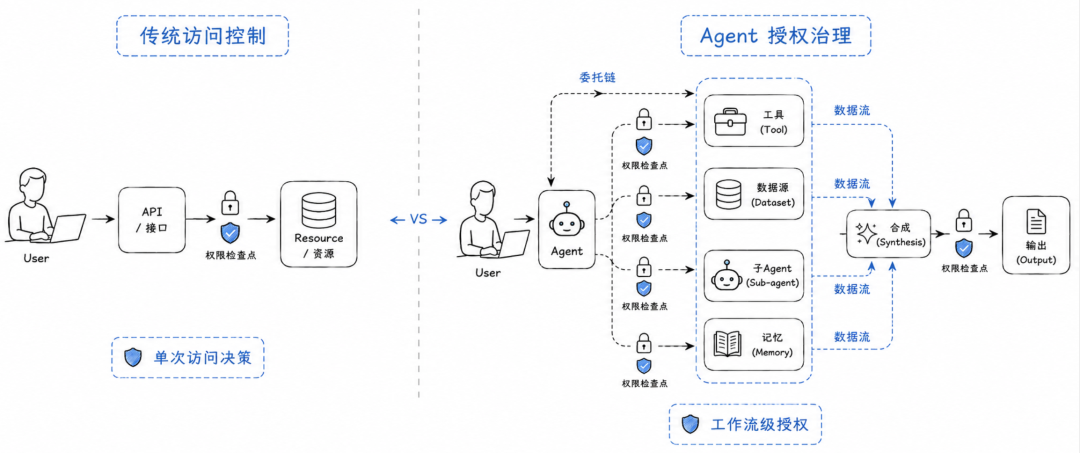
传统软件系统里,权限控制通常发生在一个清晰边界上。用户请求一个资源,系统判断这个用户能不能访问。能访问就放行,不能访问就拒绝。
但 Agent 工作流不是一次资源访问。
Agent 会先理解任务,再拆分任务,然后调用多个工具,读取多个数据源,把中间结果放进上下文,再调用其他 Agent 继续处理,最后生成一个综合答案。这个过程看起来像“智能执行”,实际上也是一条很复杂的数据流和权限流。
论文把多 Agent 系统建模成一个工作流图。图里的节点是检索、转换、合成、返回等 Agent 动作,边表示数据在这些动作之间流动。系统中同时存在人类主体、Agent 主体和数据资源,授权函数决定某个主体在某个时间能不能访问某个资源,委托函数决定一个主体把什么权限转移给另一个主体。
这个形式化表达背后有一个很重要的变化:权限不再是某次 API 调用上的静态判断,而是整个 Agent 工作流上的动态属性。
一个访问动作本身可能是合法的,但多个合法访问组合起来,可能产生非法结果。上游 Agent 有权访问某个数据源,不代表下游 Agent 自动拥有同样权限。用户在任务开始时有权限,不代表任务执行过程中权限状态不会变化。某个数据源单独可见,也不代表它和另一个数据源合成后的推断结果一定可见。
所以,“授权传播”传播的不是一个简单 token,而是用户身份、Agent 身份、委托范围、数据来源、工具调用、合成依赖和时间有效性共同构成的一条权限链。
三个真正难的问题:委托、聚合、时间
论文把授权传播拆成三个子问题:传递性委托、聚合推断和时间有效性。它们共同构成了多 Agent 系统区别于传统应用系统的权限治理难点。
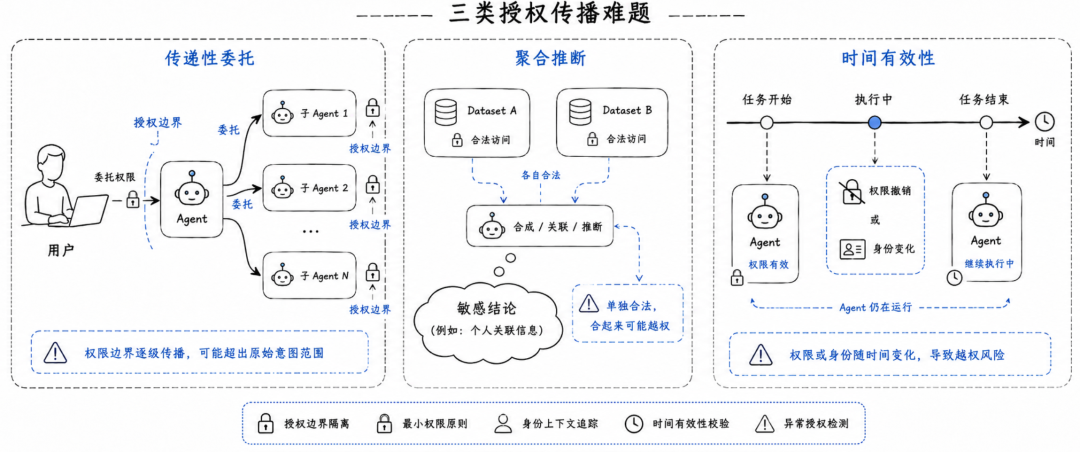
第一个问题是传递性委托。
当用户把任务交给 Agent 后,Agent 可能会继续把任务委托给其他 Agent。最简单的设计,是让所有子 Agent 都继承用户完整权限。但这样会直接破坏最小权限原则。另一个保守设计,是让每个 Agent 只使用自己的服务账号权限。但在复杂企业任务里,这又可能导致任务无法完成。
真正合理的模型应该是:每个 Agent 的有效权限必须有边界、可审计,权限不能在委托链条中不断累积,用户授权只能作为下游访问的必要条件,而不能自动成为充分条件,并且委托关系必须可以被撤销。论文指出,目前还没有广泛部署的授权系统能完整解决自主 Agent 之间的传递性委托问题。
第二个问题是聚合推断。
这是 Agent 系统里最容易被低估的问题。很多时候,单个数据源并不敏感,单次访问也完全合规,但多个数据源被 Agent 合成以后,可能推导出用户原本无权知道的信息。
这有点像“拼图”。每一块拼图本身都没有暴露全貌,但拼在一起之后,敏感信息就出现了。
Agent 的能力越强,这个问题越突出。因为 Agent 的价值恰恰在于跨系统检索、跨数据源总结、跨工具执行。如果企业希望 Agent 帮员工综合 CRM、邮件、工单、代码库、财务数据和知识库,那么系统就必须判断:这些数据源是否允许被组合,组合后的结果是否仍然对当前用户授权。
论文也承认,一般意义上的聚合推断问题还没有被完全解决。它不是简单加一个规则就能处理的问题。但架构至少要做到三件事:让参与合成的数据源可见,让合成路径可追溯,让哪些资源组合允许被合成成为可执行策略。
第三个问题是时间有效性。
多 Agent 工作流不是瞬间完成的。任务执行过程中,用户角色可能变化,团队成员关系可能更新,数据资源可能重新分级,某个授权关系也可能被撤销。
这就带来一个问题:权限到底应该在什么时候检查?
只在任务开始时检查,系统简单,但会放过中途失效的权限。每次访问都检查,更符合安全要求,但可能导致工作流中途失败。结果返回前再检查,可以避免非法结果交付,但可能浪费前面已经完成的计算。
论文的判断是,这不是一个纯技术细节,而是架构和治理策略。Agent 执行速度很快,传统基于 token TTL 的撤销机制可能过于粗糙。授权有效性必须成为工作流策略的一部分,而不是隐藏在实现里的默认行为。
为什么传统 RBAC、ABAC、ReBAC 都不够
这篇论文并不是否定传统访问控制模型。相反,它承认 RBAC、ABAC、ReBAC 都是重要基础。但它认为,这些模型无法完整覆盖 Agent 工作流里的授权传播问题。
RBAC 的优势是管理简单,把权限绑定到角色上。问题是粒度太粗。它很难表达“某个 Agent 只有在代表某个用户、执行某个任务、处于某个工作流步骤时,才能访问某个数据源”。
ABAC 的表达能力更强,可以基于属性做访问控制。但它通常还是把每次访问当成相对独立的决策,难以表达跨多个访问动作、多个数据源合成之后的授权约束。
ReBAC 最接近 Agent 场景,因为它基于关系图表达用户、组织、资源之间的授权关系。Google Zanzibar 之后,SpiceDB、OpenFGA、Authzed 等系统都属于这一类思路。论文也指出,ReBAC 很适合多租户企业环境,因为它能表达所有权、委托、组织层级和群组关系。但现有 ReBAC 主要面向人类主体访问静态资源,不原生处理非人类 Agent 主体、自主委托链、合成结果授权和工作流级时间有效性。
所以这篇论文真正想说的是:Agent 时代不是不要传统访问控制,而是传统访问控制需要升级为工作流感知的授权体系。
这套体系要关心的不只是“谁能访问什么”,还要关心“谁代表谁访问了什么、在什么任务下访问、访问结果流向哪里、是否被其他结果合成、最终交付给了谁”。
这就是 Agent 安全与传统 API 安全最大的差别之一。
身份治理为什么会变成基础设施
论文的标题后半句是“Identity Governance as Infrastructure”,这也是它的主张所在。
在传统系统里,身份治理经常被理解为一套策略、一组权限配置,或者一个接在业务系统前面的认证授权层。到了多 Agent 系统里,这种做法不够了。
因为 Agent 的行为不是固定 API 路由,而是动态组合出来的执行链。每一次数据检索、每一次任务委托、每一次工具调用、每一次结果合成,都可能跨越新的授权边界。论文把这件事类比为 TLS:早期 Web 系统可能只在敏感页面使用 HTTPS,现代架构则把传输加密当作默认基础设施,因为逐个判断哪个请求需要加密的成本太高,判断错误的代价也太大。
多 Agent 系统里的身份治理,也到了类似节点。
系统不能再问“这次 Agent 交互是否需要做授权检查”,而应该默认每一次 Agent 交互都需要授权检查。授权不能是 Agent 通过一次网关之后就结束的动作,而应该成为每一次数据检索、每一次委托、每一次合成的系统属性。
这也是为什么我觉得这篇论文对企业 Agent 平台很有启发。
很多企业现在做 Agent,重点放在模型能力、工具编排、知识库接入和流程自动化上。但只要 Agent 开始接入真实业务系统,它就不再只是一个“智能助手”,而是一个带有权限、能够行动、能够组合信息的非人类主体。
这个主体如果没有清晰身份,没有任务级授权,没有委托边界,没有合成审计,没有结果追溯,就会变成一个很难治理的执行黑箱。
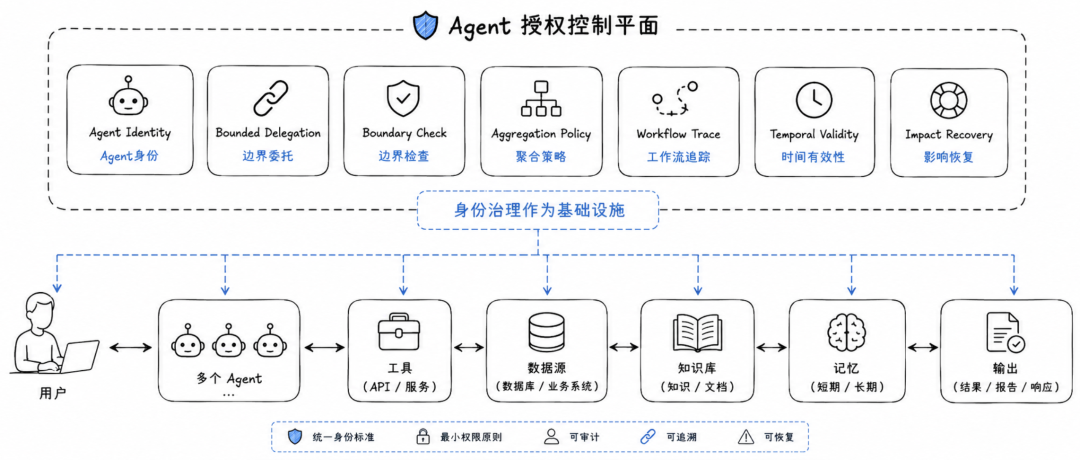
七个结构性要求:Agent 授权治理应该长什么样
论文提出了七个结构性要求,可以理解为多 Agent 授权架构的设计底线。
第一,Agent 必须成为一等授权主体,不能继续藏在宽泛的 service account 后面。企业系统需要知道到底是哪一个 Agent、以什么身份、代表谁、在什么任务中访问了资源。
第二,Agent 之间的委托必须显式、有边界、可审计。不能因为用户发起了任务,就让整条 Agent 链自动继承用户完整权限。
第三,每个数据检索边界都要重新评估授权。工作流开始时的检查不够,Agent 每跨过一个数据边界,都应该重新确认当前主体、任务和资源之间的关系。
第四,系统要能表达聚合策略。哪些数据源可以组合,哪些组合会产生敏感推断,哪些合成结果不能返回给当前用户,这些都应该成为可执行策略。
第五,授权轨迹必须以工作流为单位自包含记录下来。事后审计时,系统不能只看到单个 API 调用日志,而要能看到完整的委托链、数据链和合成链。
第六,时间有效性必须成为明确策略。授权在任务开始时有效,不代表任务结束时仍然有效。系统需要定义权限撤销、中途失效和结果交付前复查的处理方式。
第七,一旦发现授权违规,系统要能沿着合成图追溯所有受影响的下游结果。因为 Agent 输出往往是多个中间结果组合而来,某个上游数据越权,可能污染后续多个答案、报告或动作。论文将这些要求总结为多 Agent 授权架构必须满足的结构性条件。
这七点背后其实是同一个思想:Agent 授权治理不能只是“拦截一次请求”,而要管理“整条执行链”。
生产案例说明:很多风险来自正常工程选择
论文后半部分有三个来自生产企业 AI 平台稳定化过程中的观察案例。它们不是攻击案例,而是普通系统运行、配置、集成和错误处理过程中出现的问题。作者强调,这些问题不是工程质量低下,而是授权传播问题在真实系统中的自然表现。
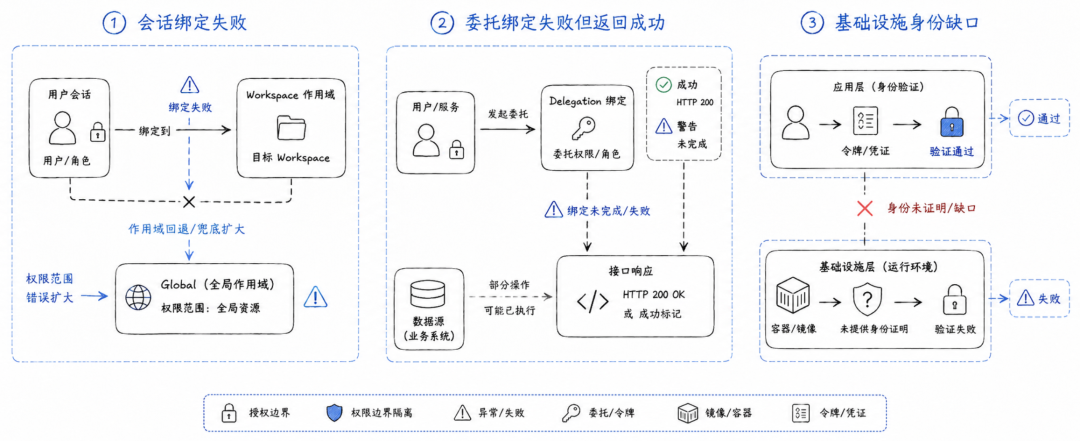
第一个案例是会话绑定失败后的静默权限扩大。
一个反向代理网关通过 ForwardAuth 把认证委托给外部认证服务。当 workspace session binding 失败时,中间件没有拒绝请求,而是退回到全局认证上下文。结果是,用户虽然仍然被认证了,但不再被限制在原本 workspace 范围内。后续请求可能访问超出预期边界的资源。论文认为,这违反了“每个数据检索边界都要授权”和“时间有效性必须作为策略决策”两个要求。修复方式是 fail closed:只要 workspace 绑定失败,请求就必须失败,不能退回到更宽的权限范围。
第二个案例是委托绑定失败但系统仍然返回 HTTP 200。
用户进入协作 workspace 时,系统本应建立 workspace 级授权上下文。但如果绑定没有完成,接口仍然返回成功,用户就会误以为自己处在隔离的 workspace 环境中,后续操作却在未限定范围的上下文里继续执行。论文将其视为传递性委托失败:系统报告委托成功,但真实的委托链并没有建立。
第三个案例是基础设施身份缺口。
某些扩展组件在应用层可以出示有效凭证,但容器镜像本身没有经过可信构建和证明。于是应用层说“这是 Extension X 发来的请求”,基础设施层却无法证明这个 Extension X 是真实、未被篡改的组件。论文认为,这说明 Agent 授权链不能只覆盖应用层身份,也必须覆盖容器、镜像、构建流水线等基础设施身份。
这三个案例很有现实感。它们说明,Agent 授权风险不一定来自黑客打穿系统,也可能来自系统在异常路径下选择了“宽松降级”“乐观成功”“局部可信”。
在普通业务系统里,这类问题可能只是边界 bug。到了 Agent 系统里,它会沿着委托链、数据链和合成链被放大,最终变成用户无法察觉的越权访问和数据暴露。
启发
这篇论文没有给出一个完整产品方案,也没有声称解决了所有授权传播问题。作者明确说,论文没有提出完整部署架构,没有解决一般意义上的聚合推断问题,也没有给出最终策略语言。它更像是一篇问题定义和架构要求论文。
但它的价值恰恰在于把一个过去比较模糊的问题命名了。
过去我们讲 Agent 安全,经常会说提示注入、工具滥用、越权调用、数据泄露、记忆投毒。但“越权调用”和“数据泄露”往往被讲成单点问题:某个 Agent 调用了不该调用的工具,某个用户看到了不该看的数据。
这篇论文把问题推进到工作流层面。真正的风险不只是某个点越权,而是权限在多 Agent 链条中传播、衰减、组合、失效和追溯的问题。
这对企业 Agent 安全产品有几个直接启发。
第一,Agent 安全不能只做 prompt injection 检测。未来企业会需要 Agent 权限链审计、Agent 委托链治理、工具调用授权检查、数据源组合策略控制、工作流级安全回溯等能力。
第二,Agent 护栏不能只卡输入输出。很多危险行为发生在中间过程里:任务如何拆分,哪个 Agent 调哪个工具,使用了哪个用户身份,读取了哪些数据源,多个结果如何合成,最终答案是否隐瞒了“部分数据不可访问”。
第三,企业 Agent 平台需要新的控制平面。这个控制平面既不是传统模型网关,也不只是 API 网关,而是面向 Agent 工作流的身份与授权基础设施。它要记录请求者身份、Agent 身份、委托范围、工具调用、数据来源、合成依赖和最终交付对象。
第四,Agent 评测体系也要升级。现在很多 benchmark 关注任务成功率、工具调用准确率和抗提示注入能力。但在企业场景里,还应该测试 silent scope widening、delegation drift、stale authority、unsafe completeness 等治理失败。论文也指出,当前 Agent benchmark 过度关注能力,对治理失败刻画不足。
写在最后
如果说大模型时代的安全重点是“模型会说什么”,那么 Agent 时代的安全重点正在变成“系统会做什么”。
而一旦系统开始做事,身份和权限就会重新成为核心。
过去,身份治理更多是企业 IT 和安全后台系统里的问题。到了 Agent 时代,它会变成产品架构的一部分。Agent 每一次访问数据、调用工具、委托任务、合成结果,都在重新定义权限边界。
这也是这篇论文最重要的提醒:Agent 安全的新问题,不只是模型有没有对齐,也不只是提示注入有没有防住。真正复杂的地方在于,企业要让一群非人类主体在真实业务系统里行动,同时还能证明它们每一步都没有越权。
这件事最后会落到一个非常工程化的问题上:企业是否拥有面向 Agent 工作流的身份与授权基础设施。
没有这套基础设施,Agent 越强,权限边界越模糊;Agent 越会协作,授权链越难追踪;Agent 越能合成信息,数据泄露越可能以“正常回答”的形式出现。
未来的 Agent 安全,不能只看提示词,也不能只看输入输出。它必须看完整执行链。
因为真正的风险,可能不在 Agent 被攻击的那一刻,而在它正常完成任务的过程中。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
