
原文标题:Attention is All You Need to Defend Against Indirect Prompt Injection Attacks in LLMs
原文作者:Yinan Zhong, Qianhao Miao, Yanjiao Chen, Jiangyi Deng,Yushi Cheng, Wenyuan Xu发表会议:NDSS 2026笔记作者:龙函城主编:黄诚@安全学术圈
研究概述
随着大语言模型被集成到Web Agent、邮件助手、智能规划器等应用中,LLM应用通常需要读取网页、邮件、文档等外部数据,再结合用户指令完成任务。但这种模式也带来了间接提示注入攻击(Indirect Prompt Injection, IPI)风险:攻击者可以将恶意指令隐藏在外部数据中,使模型在处理正常任务时被诱导执行攻击者的目标。现有防御方法要么依赖分类器或辅助LLM进行整体检测,容易受已知攻击模式限制;要么通过提示改写、分隔符或模型微调进行预防,但难以精确删除注入内容,且微调成本较高。针对这些问题,论文提出RENNERVATE,目标是在不修改目标LLM的前提下,实现对IPI攻击的细粒度检测与净化。
RENNERVATE的核心思想是利用LLM推理过程中的注意力特征进行防御。作者认为,注入指令即使在文本表面上看起来较为正常,但模型在处理这些内容时,其内部注意力模式可能会暴露出异常行为。因此,RENNERVATE不再只依赖文本关键词或语义分类,而是从目标 LLM 的注意力特征出发,对外部数据中的token进行逐个判断,并进一步定位和删除可疑注入片段。
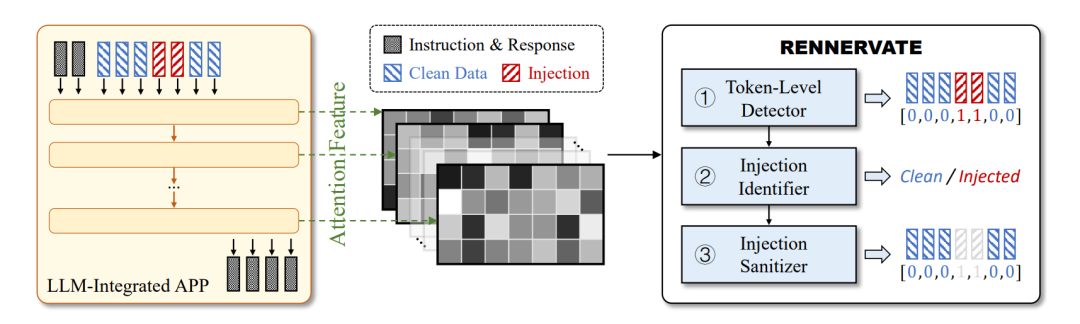
图 1 RENNERVATE 整体防御框架
如图1所示,RENNERVATE 主要由三个模块组成。首先,Token-level Detector从LLM推理阶段提取注意力特征,并判断每个token是否属于注入内容;其次,Injection Identifier对token级预测结果进行过滤和聚合,判断整段外部数据是否被注入;最后,Injection Sanitizer删除被标记为注入的token,生成净化后的文本,使LLM应用能够继续完成原本任务,而不是简单拒绝服务或被攻击者劫持。论文进一步设计了两步注意力池化机制,分别聚合响应token和注意力头维度的信息,以提取更适合注入检测的关键注意力特征。
实验结果表明,RENNERVATE在ChatGLM、Dolly、Falcon、LLaMA2和LLaMA3等5个目标LLM上均取得了较好效果,并优于15种商业和学术界IPI防御方法。论文还构建了细粒度IPI数据集FIPI,包含100k个注入样本,覆盖5类IPI攻击方法和300个NLP任务;同时在未见过的数据集、未知攻击以及自适应攻击场景下进行了验证,说明该方法具有一定迁移性和鲁棒性。
贡献分析
贡献点1 :提出面向间接提示注入攻击的检测与净化框架RENNERVATE
论文提出了RENNERVATE,用于防御大语言模型集成应用中的间接提示注入攻击。该框架不仅能够判断外部数据是否存在注入风险,还能够进一步定位并净化注入内容,在保持较高检测精度的同时,尽量维持原始任务功能。
贡献点2 :设计基于注意力特征的token级检测机制
论文利用目标LLM推理过程中的注意力特征进行IPI检测,而不是只依赖文本关键词、语义分类器或辅助大模型。通过token级检测机制,RENNERVATE可以判断外部数据中哪些 token可能属于恶意注入内容,从而实现更细粒度的攻击定位,也为后续注入净化提供基础。
贡献点3 :提出两步注意力池化机制提升检测效果
为了从复杂的注意力特征中提取更关键的信息,论文设计了2-step attentive pooling机制。该机制先聚合响应token维度的信息,再聚合注意力头维度的信息,使模型能够自动关注更有助于注入判断的注意力模式,从而提升检测准确性和泛化能力。
贡献点4 :通过大量实验验证方法有效性与鲁棒性
论文在多个目标LLM上对RENNERVATE进行了系统评估,并与15种商业和学术界IPI防御方法进行对比。实验结果表明,RENNERVATE在IPI检测和净化两个任务上均表现较好,同时在未见过的数据集、未知攻击和自适应攻击场景下也具有一定迁移性和鲁棒性。
实验结果分析
表 1 RENNERVATE 与当前主流IPI检测方法的对比结果
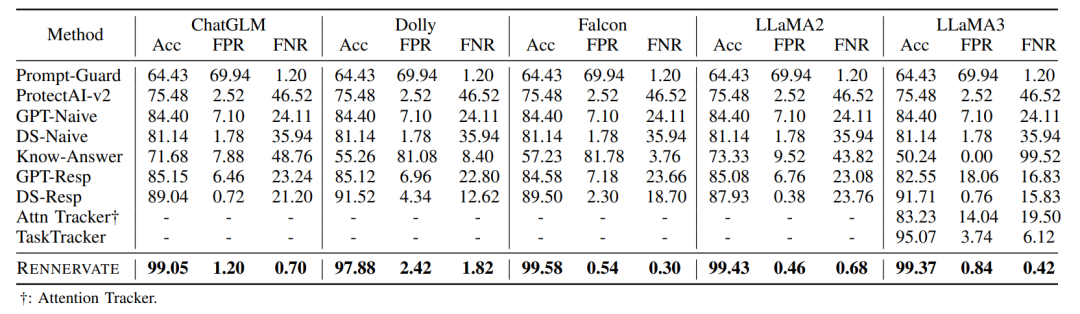
从整体检测效果来看,RENNERVATE在五个目标 LLM 上均取得了较高准确率。表1显示,其在ChatGLM、Dolly、Falcon、LLaMA2和LLaMA3上的检测准确率分别为99.05%、97.88%、99.58%、99.43%和99.37%,整体优于Prompt-Guard、ProtectAI-v2、GPT-Resp、DS-Resp、Attention Tracker和TaskTracker等方法。同时,其误报率和漏报率也保持在较低水平,说明该方法既能有效发现注入样本,也能减少对正常样本的误判。
表 2 RENNERVATE与现有IPI净化方法的攻击成功率对比
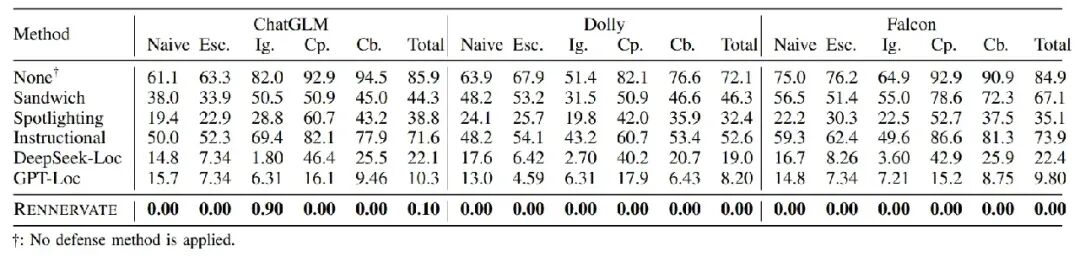
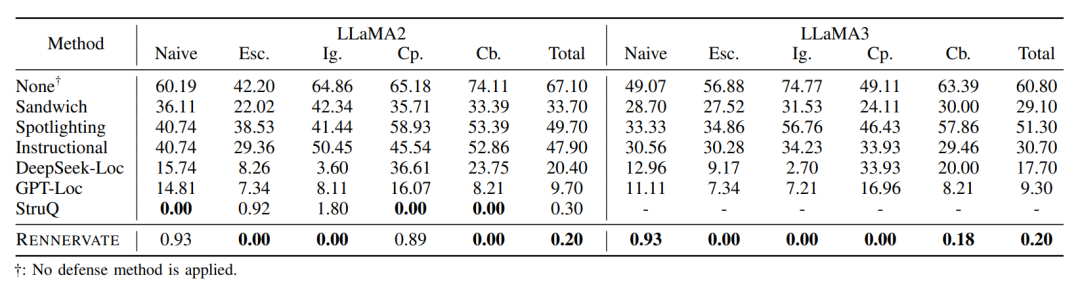
从IPI净化效果来看,RENNERVATE能够显著降低攻击成功率。表2显示,在没有防御时,多个目标LLM的攻击成功率较高,例如ChatGLM 为 85.90%,Falcon为 84.90%。加入RENNERVATE后,Dolly和Falcon的ASR降至 0.00%,ChatGLM 降至0.10%,LLaMA2和LLaMA3也仅为0.20%。这说明RENNERVATE不只是检测输入是否危险,还能通过token级定位与删除削弱注入指令的影响。
表 3 RENNERVATE在未知数据集上的检测结果

在未知数据集场景下,RENNERVATE 也表现出较好的迁移能力。表 3 中的 MRPC-HSOL、Jfleg-RTE、SST2-MRPC、MRPC-SST2 和 RTE-Jfleg 代表不同任务组合,用于模拟新任务和新数据分布下的 IPI 攻击。结果显示,该方法在多数场景中仍能保持较高检测准确率.
表 4 RENNERVATE 在未知攻击下的鲁棒性结果

论文进一步验证了RENNERVATE面对未知攻击时的鲁棒性。在GCG和Neural Exec两类未知梯度攻击下,无防御时ASR普遍较高,而经过RENNERVATE处理后,GCG的ASR降至0.00%–7.00%,Neural Exec在所有数据集上均降至0.00%。
表 5 RENNERVATE 关键模块消融实验结果
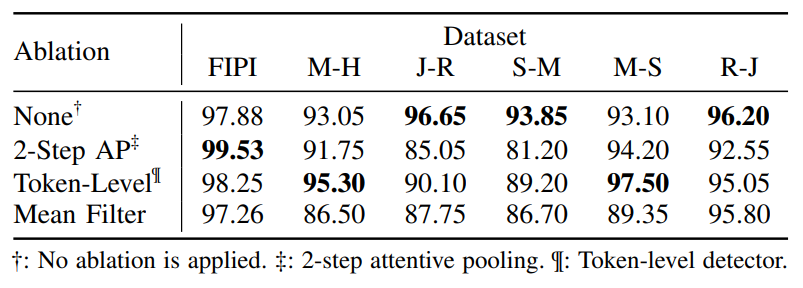
消融实验主要验证了2-step attentive pooling、token-level detector和mean filter等模块的有效性。表5显示,完整RENNERVATE在多个数据集上整体更稳定;当去除或替换2-step attentive pooling后,J-R和S-M等场景性能下降较明显;去除mean filter后,多个跨任务场景的准确率也出现下降。这说明模型效果并不只是来自注意力特征本身,而是依赖token级检测、注意力池化和连续注入片段过滤等模块共同作用。
总体来看,论文实验较好地证明了RENNERVATE的有效性:它不仅能检测IPI攻击,还能进一步定位并删除注入token,从而兼顾安全性与可用性。相比只做整体二分类的防御方法,该方法更适合需要持续完成任务的LLM集成应用。不过,RENNERVATE需要访问目标LLM的注意力信息,因此更适用于开源模型或本地部署场景;如果只能调用闭源API,其直接应用会受到一定限制。
论文点评
总体来看,这篇论文的价值在于它聚焦了LLM集成应用中非常现实的安全问题,即间接提示注入攻击。相比普通提示注入,IPI攻击往往隐藏在网页、邮件、文档等外部数据中,用户和系统不容易直接发现。本文提出的RENNERVATE并不是简单依赖关键词、分类器或额外大模型判断输入是否危险,而是利用目标LLM推理过程中的注意力特征进行token级检测,并进一步删除可疑注入内容。这使得方法不仅能够发现攻击,还能在一定程度上恢复正常输入,兼顾了安全性和应用可用性。
从方法设计上看,论文的亮点主要在于检测、定位与净化的一体化思路,以及两步注意力池化机制对关键注意力特征的提取。实验也比较充分,覆盖多个目标LLM、不同数据集、未知攻击和自适应攻击场景,能够较好支撑方法的有效性。不过,该方法也存在一定限制:RENNERVATE需要访问目标LLM的内部注意力信息,因此更适合开源模型或本地部署场景;如果只能调用闭源API,其直接应用会受到限制。总体而言,这篇论文为LLM Agent场景下的提示注入防御提供了一种较清晰、可实现的技术路线,对后续研究大模型安全防御具有较强参考价值。
论文文献
Zhong, et al. “Attention is All You Need to Defend Against Indirect Prompt Injection Attacks in LLMs.” Network and Distributed System Security Symposium (NDSS 2026). 2026.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
