2026年2月,我们内部估算,自2024年底推理模型(reasoning models)出现以来,AI模型能够完成的网络安全任务时长,大约每4.7个月翻一倍——相比我们在2025年11月得出的“每8个月翻倍”估计,这已经是明显加速。
此后,AISI又公布了两个新模型——Claude Mythos Preview和GPT-5.5——的测试结果,而它们的表现明显超出了此前两条翻倍趋势线。目前还不清楚,这究竟意味着一种新的、更快的增长趋势已经出现,还是只是一次短期跃升。
我们持续追踪AI网络安全能力的发展速度,是为了帮助政府更好地为前沿AI时代做准备。随后,我们也会与英国国家网络安全中心(NCSC)等机构合作,由他们向企业发布相关建议。
虽然这些评测并不能完美衡量AI在现实世界中的实际影响,但当前能力提升的速度表明,AI网络攻击能力正在越来越有可能转化为现实风险——而英国各类组织在未来几个月里,将需要开始应对这些风险。
这篇博客包含了我们对GPT-5.5和Claude Mythos Preview的最新测试结果。自从上一篇介绍Mythos Preview部署前测试的博客发布后,我们又获得了一个更新版本的模型检查点(checkpoint)。这个新版本在网络安全任务中的表现比之前更强,甚至首次成功完成了我们两个完整的网络攻击演练场(cyber ranges)。
网络安全“时间跨度”(Cyber Time Horizons)
所谓“时间跨度基准”(time horizon benchmarks),是指AI模型能够完成多长时间的人类任务。这里的时间,是按照人类专家完成同样任务所需的时间来衡量的。
这并不是一个精确的能力预测指标。AI在某些人类很快就能完成的任务上可能表现很差,而在一些人类觉得困难的任务上又可能表现得很轻松。不过,我们仍然使用这种基准,因为它能够反映AI自主能力的发展趋势。
在AISI,我们会为狭义网络安全测试套件(narrow cyber suite)中的每一个任务,估算一名网络安全专家完成该任务所需的时间。
这些任务要求模型识别并利用目标系统中的网络安全漏洞,测试内容包括逆向工程、Web漏洞利用等,测试环境则是封闭、独立的系统。需要说明的是,这些任务只覆盖了现实世界网络攻击能力中的一部分。
对于超过三分之一的任务,我们会实际记录人类专家完成任务所花费的时间,作为基准。其余任务则使用专家估算,而非真实测量数据,因此这些估算可能存在高估或低估。
通过计算前沿模型在整个狭义网络安全测试套件中的成功率,我们可以估算:模型在某个成功概率下,能够完成多长时间的人类任务。本文重点关注的是“80%成功率”这一门槛。
为了保证长期结果可比,我们刻意将每个任务限制在250万tokens以内。这实际上低估了前沿模型的真实能力。关于这一决定,我们会在后文进一步讨论。
综合来看,一个典型的“时间跨度”结果,可以这样理解:
“我们估计,在当前测试环境下、每个任务限制250万tokens的条件下,只要任务与我们的狭义网络安全测试类似,Claude Sonnet 4.5能够以80%的成功率,完成那些人类专家通常需要16分钟才能完成的网络安全任务。”
为了分析能力进步速度,我们会对历史上同一时期最强模型的测试结果拟合一条指数曲线。需要说明的是,这只是一个不完美的模型,它既不是未来预测,也不是某种固定规律。
网络安全时间跨度结果(Cyber Time Horizons Results)
2026年2月,我们估算:在250万token限制下,自2024年底推理模型出现以来,前沿模型在80%可靠性下的网络安全“时间跨度”,大约每4.7个月翻一倍。
这大约只有我们2025年11月估计值的一半。当时,我们对于50%和80%可靠性下的翻倍时间估计都还是8个月。
此后,Claude Mythos Preview和GPT-5.5的表现又明显超过了这一趋势。
截至本文写作时,我们仍不清楚:Mythos Preview和GPT-5.5究竟只是暂时突破了既有进步速度,还是代表着一种新的、更快的能力增长趋势已经开始。
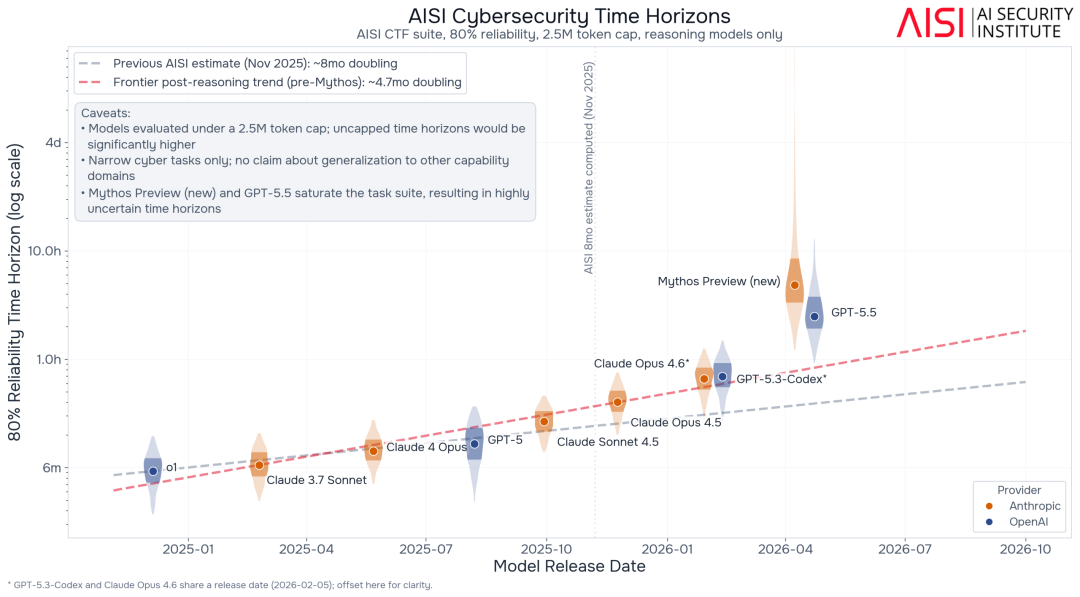
图1:在AISI狭义网络安全任务测试套件中、250万token预算限制下,模型达到80%可靠性时的“网络安全时间跨度(cyber time horizon)”。图中的阴影区域表示各模型的bootstrap分布(基于1000次分层重采样的任务/运行结果)。内层阴影代表中间50%的结果区间,外层阴影代表中间95%的结果区间。目前我们网络安全测试套件中最长的单项任务时长为12小时。
由于Claude Mythos Preview和GPT-5.5即便在250万token限制下,面对我们狭义网络安全测试套件中最长的任务时,成功率依然接近100%,因此它们的上限误差区间(upper-bound error bars)会显得很大。
与此同时,我们目前的任务长度本身也还不够长,因此无法准确判断:随着任务时长继续增加,这些模型的可靠性究竟会下降得多快。
这意味着,一些最新模型的能力,其实已经接近我们当前狭义测试体系所能测量的上限。
如果取消250万token限制,那么这些模型的成功率会高到几乎无法再计算“时间跨度(time horizon)”。这个token限制,再加上我们采用的简单Agent框架(agent scaffold),实际上是在刻意压低模型表现,因此会低估模型在拥有更多tokens和更强Agent框架时的真实能力。
但作为交换,这样做可以保证“时间跨度”仍然是可测量的,并且能够在不同模型之间进行比较。
作为参考,250万tokens其实是一个相对较低的限制。在我们的网络攻击演练场(cyber range)实验中,我们最高会使用1亿tokens,而且我们发现,即便达到这个预算之后,模型表现仍然可能继续提升。尤其是最新模型,它们从更高token预算中获得的收益明显更大。
此外,还有其他几个因素,也会让“翻倍时间(doubling time)”的估算存在不确定性。
例如,较长时间跨度的估算,目前只依赖于6个时长超过8小时的任务。如果未来样本规模扩大,新增的长任务可能会比当前任务更容易或更困难,从而拉低或提高时间跨度估计。
人类基准(human baselines)本身也并不完美——不同专家完成同一任务的速度可能快慢不同,而对于6个最长任务,我们掌握的人类基准数据其实也很有限。
不过,我们仍然认为,人类基准是有价值的,因为相比其他指标,它能够提供一种更客观的任务难度衡量方式。
另一个不确定来源在于,“时间跨度”估算只基于少量模型拟合而成(历史阶段可用模型甚至更少)。虽然这确实是一个问题,但我们的证据表明,整体趋势并不依赖于某一个具体模型。
即便删除任意单一模型,Mythos出现之前的翻倍时间估算,也只会在4.1个月到5.0个月之间波动。
关于网络与软件自主能力的更多证据
我们最新的翻倍时间估算,与另一家非营利研究机构METR的结果非常接近。METR主要研究软件工程任务的“时间跨度”,虽然软件工程能力比纯网络安全更广泛,但两者高度相关。
METR的结果表明:自2024年底以来,AI在软件任务上的时间跨度,大约每4.2个月稳定翻倍。
除了狭义任务测试之外,我们还观察到了更多关于AI网络自主能力提升的证据。
AISI的“网络攻击演练场(cyber ranges)”(如下图所示),用于测试AI模型在已经获得初始权限的情况下,对小型、无防御企业网络完成网络攻击的能力。
每个演练场都要求模型具备持续规划和执行能力。关于这些测试的更多细节,可以参考我们最近发布的论文。
在AISI最新测试中,更新版本的Mythos Preview成功完成了我们两个网络攻击演练场。
其中,在“The Last Ones”场景中,模型在10次尝试里成功了6次;而在此前从未被任何模型攻破过的“Cooling Tower”场景中,它也成功了3次。
这是首次有模型成功完成我们第二个网络攻击演练场。
GPT-5.5则在“The Last Ones”场景中,10次尝试成功了3次。
需要说明的是,这些结果使用的是比AISI此前报告中更新的Mythos Preview检查点(checkpoint)。
值得注意的是,显著的能力跃升并不一定需要发布全新模型:即便只是同一模型后续迭代的版本更新,也可能明显改变我们对前沿AI能力的估计。
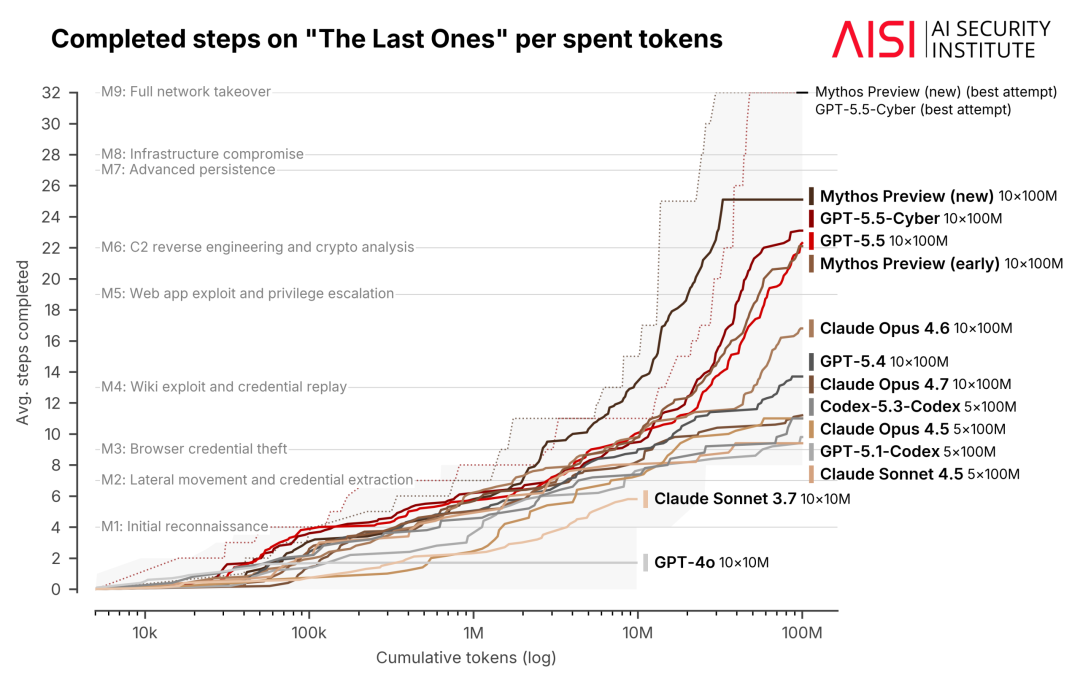
图2:在“The Last Ones”任务中(这是一个包含32个步骤的模拟企业网络攻击场景),模型随着总token消耗增加而完成的平均步骤数量。图中的每一条线代表一个不同的模型;阴影区域则表示该模型在对应token预算下、所有测试运行结果中的最小值到最大值区间(min–max range)。
含义(Implications)
任何单一基准测试结果,都不应该被视为对AI能力的精确衡量。
“时间跨度(time horizon)”估算本身存在真实的不确定性:我们狭义测试套件中最长的任务,恰恰也是人类基准数据最少的任务;与此同时,现在也还太早,无法判断近期模型能力出现的“跳跃式提升”,究竟只是一次偶发现象,还是意味着一种新的、持续甚至加速的增长趋势已经形成。
不过,无论如何,我们观察到的变化方向和快速增长趋势,在不同模型、不同方法选择以及不同独立数据之间,都是一致的。
前沿AI的自主网络攻击和软件能力,正在快速进步:前沿模型能够自主完成的网络安全任务时长,其翻倍速度是“按月”计算,而不是“按年”。当然,目前这些证据仍然无法回答几个关键问题:AI能力增长速度未来会如何变化;AI什么时候会达到某个具体能力门槛;这些能力在真实、有防御的现实系统中究竟会表现如何。
但更强的AI网络能力,已经开始带来现实中的机会和风险。
网络安全防御人员已经报告称,利用最新模型进行漏洞发现的能力有了明显提升。而今天仍处于受控状态的这些能力,未来也可能逐渐扩散。
现在正是加强网络安全基础设施建设的时候。
前沿AI既可能增强攻击者,也可能增强防御者,而当前正处于一个建立系统韧性的关键窗口期。英国国家网络安全中心(NCSC)最近也已经发布了关于如何利用AI模型发现漏洞的建议。
如果当前AI能力增长速度继续维持、甚至进一步加快,那么AI网络攻击能力将长期成为一个快速变化、需要持续跟踪的目标。为了跟上这种变化,我们正在开发更困难的网络安全评测体系,包括:新的网络攻击演练场(cyber ranges);对现有测试环境的升级;引入主动网络防御机制,以更接近真实世界环境。
未来,我们将继续评估前沿AI的自主网络攻击和软件能力,并随着更多证据出现,持续更新我们的估计。
AISI使用“狭义网络安全测试套件(narrow cyber suite)”来估算时间跨度,因为该测试包含大量具有人类完成时间基准的任务。AISI也会在“网络攻击演练场(cyber ranges)”中测试模型,而这些任务比狭义测试更复杂。不过,由于目前我们只有两个网络攻击演练场,因此它们尚未被用于时间跨度估算。
在250万token限制下,GPT-5.5在6个预计耗时超过8小时的任务中,有5个任务成功率达到100%;而第6个任务一旦取消token限制,也能在每次尝试中成功完成。Mythos Preview则在250万token限制下,对全部6个长任务都实现了100%成功率。
我们估算了METR对前沿模型(从o1-preview开始)的80%可靠性翻倍时间。若不计入Mythos Preview,估计翻倍时间为4.2个月;若计入Mythos Preview,则进一步加快至约4个月。METR采用的模型选择,与AISI网络安全评测中的模型组合略有不同。
声明:本文来自礼士蛮,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
