最近看到一篇很适合企业 AI 安全落地的论文,题目叫 《Positive Data Control: A Secure Architecture for LLM-Mediated Data Governance》。

https://assets-eu.researchsquare.com/files/rs-9317019/v1_covered_733b827c-2007-4c90-bed0-d8e2e8cd7429.pdf
这篇论文讨论的是:当用户用自然语言向数据库提问时,能不能让大模型参与理解需求,但又不让大模型直接接触敏感数据?
我的判断是:这篇文章的价值不在算法创新,而在于提出了一个很清晰的 LLM 数据访问安全架构范式。它对企业内部知识库、BI 问答、Text-to-SQL、数据治理 Agent 都有参考意义。
企业数据问答的真正风险,不在“会不会生成 SQL”
企业里有大量数据访问需求。过去一般靠 RBAC、ABAC、数据库权限、数据管理员审批、审计日志来做治理。但问题在于,真实用户不会天然按照“表名、字段名、权限策略”来表达需求,而是会说:
“帮我查一下客户订单情况。”
“分析一下某个部门员工薪资。”
“导出所有客户信息。”
这类自然语言请求和数据库里的结构化权限之间存在语义鸿沟。LLM 很适合把自然语言翻译成 SQL,也适合解释策略,但如果直接让 LLM 连接数据库,就会带来新的风险:提示注入、恶意 SQL 生成、越权查询、敏感字段泄露、结果被模型上下文吸收等。论文明确指出,Text-to-SQL 系统已经被证明存在提示注入和恶意查询生成风险,因此不能让 LLM 直接靠近敏感数据。
所以作者提出的核心思路是:LLM 只负责理解请求和草拟 SQL,真正的权限判断、SQL 校验、执行控制、结果脱敏都由确定性系统完成。
这就形成了论文所谓的 Positive Data Control,简称 PDC,积极数据控制。
PDC 的核心思想:把数据访问从“事后审计”改成“事前拦截”
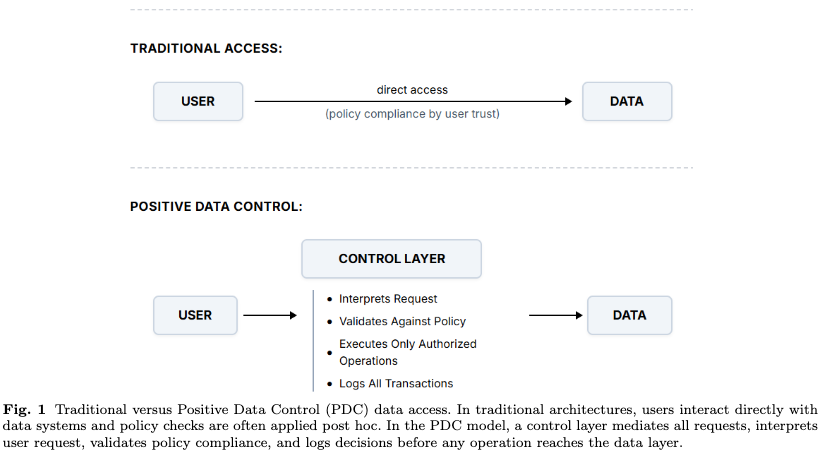
论文用一个类比解释 PDC:传统数据访问更像用户直接操作数据系统,治理主要依赖用户自觉、权限配置和事后审计;PDC 更像飞机的 fly-by-wire 电传操纵系统,用户发出意图,但中间有一个控制层负责解释、校验、限制和记录,然后才允许操作真正到达数据层。
这个设计的关键转变是:
用户不直接访问数据库。
LLM 不直接访问数据库。
所有请求必须经过控制层。
控制层在执行之前完成策略判断。
所有结果要经过后处理和审计。
这对 AI 安全很重要,因为很多企业现在做 AI 数据问答时,容易把“大模型能力”当成权限系统的一部分。论文反过来强调:LLM 可以参与语义理解,但不能成为安全边界。
“零知识治理”:大模型只看结构,不看数据
论文中有一个很容易被误解的词:zero-knowledge governance,零知识治理。
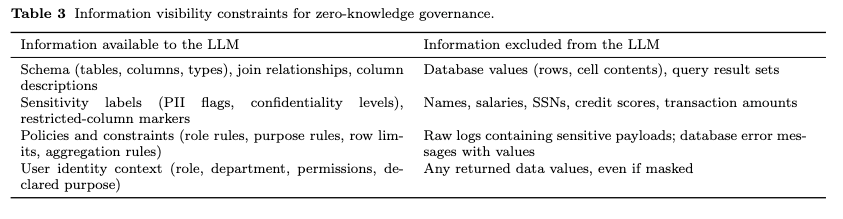
这里的“零知识”不是密码学意义上的零知识证明,不是说系统提供了严格的数学证明。论文自己的解释很明确:它说的是一种架构隔离。大模型永远不能看到数据库里的真实值,不能看到行数据、单元格内容,也不能看到查询结果。它只能看到元数据、字段说明、敏感标签、权限策略、用户角色和声明用途。
换句话说,大模型可以知道数据库里有一张员工表,可以知道里面有 salary 字段,也可以知道 salary 是 HR 限制字段。但它不能看到任何员工的真实工资。它可以知道客户表里有 email、phone、credit_score,也可以知道哪些字段属于 PII 或金融敏感信息,但它不能看到具体邮箱、手机号和信用分。
这套边界非常重要。企业引入大模型做数据问答时,常见的错误是把“让模型理解业务”误解成“把业务数据喂给模型”。实际上,很多治理决策并不需要真实数据值。判断一个用户能不能访问 salary 字段,不需要看某个人工资是多少;判断一个请求是否越权,不需要把客户名单发给模型;判断一个查询是否应该被聚合化,也不需要让模型看到原始记录。
论文用 Table 3 明确列出了大模型可以看到和不能看到的信息。大模型可以看到 schema、字段类型、join 关系、字段描述、敏感标签、权限规则、用途约束和用户身份上下文;大模型不能看到数据库真实值、查询结果、姓名、工资、SSN、信用分、交易金额,也不能看到包含敏感载荷的原始日志和数据库错误信息。
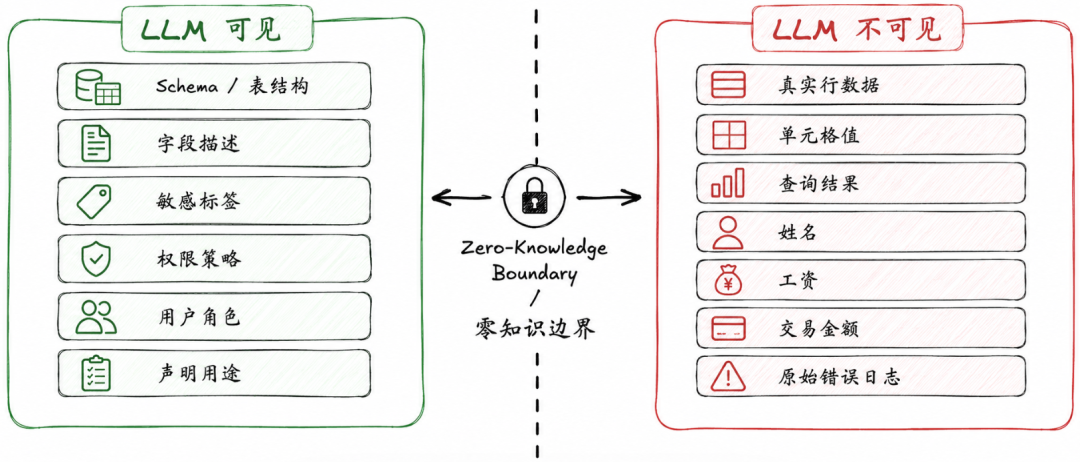
这给企业 AI 数据安全提供了一个很直接的产品原则:让模型理解数据结构和治理规则,但不要让模型接触数据内容。
这套架构怎么跑起来?
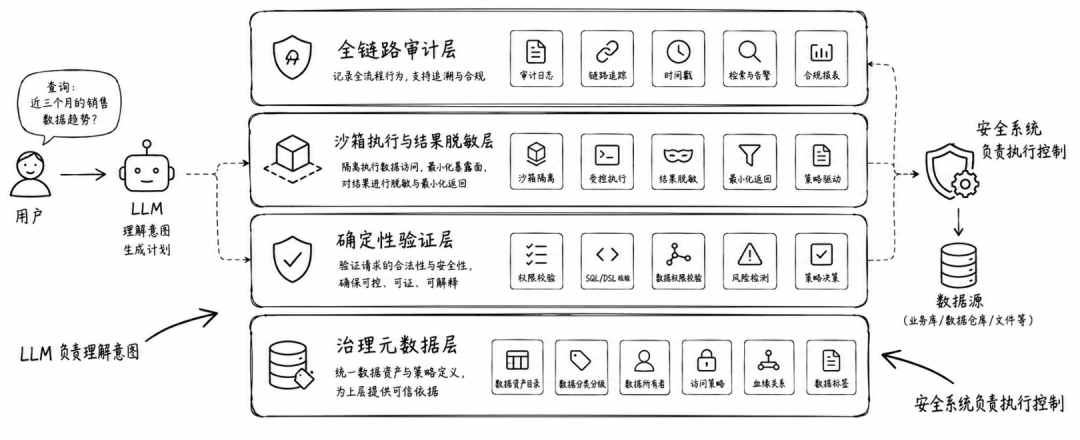
论文给出的 PDC 架构大致可以拆成六层:
第一层是用户界面和身份绑定。用户提交自然语言请求,同时带上认证身份、角色、部门、声明用途。也就是说,请求进入系统时,已经绑定了“谁在问、以什么身份问、为了什么目的问”。
第二层是 LLM 控制层。LLM 接收结构化 prompt,里面包含 schema 描述、字段敏感性标注、策略规则和用户权限上下文。它根据这些信息生成一个候选 SQL,并给出简短理由。这里的输出被视为“不可信草稿”。
第三层是确定性验证层。它检查 SQL 是否只读,是否包含 DDL/DML、SQL 注入痕迹、危险关键字,是否访问了用户没有权限的表或字段,是否需要加 LIMIT,是否违反聚合约束、用途约束等。论文强调,这一层是主要执行边界。
第四层是沙箱执行层。只有通过验证的 SQL 才会被执行,而且执行环境带有资源限制、隔离和超时控制,用来降低 DoS 或超大查询风险。
第五层是结果后处理。即使 SQL 通过了验证,返回结果也要做 PII 脱敏。例如邮箱部分脱敏、手机号完全脱敏、SSN 始终完全脱敏。这个设计相当于输出侧的第二道保险。
第六层是审计层。系统记录请求、身份、角色、声明目的、原始自然语言请求、模型生成内容、验证结果、执行查询和最终决策,用于合规、追责和策略优化。
整体来看,它是一种典型的 解释层与执行层分离 架构。LLM 在左侧做理解,数据库和验证器在右侧做执行,中间有一条明确的 zero-knowledge boundary。
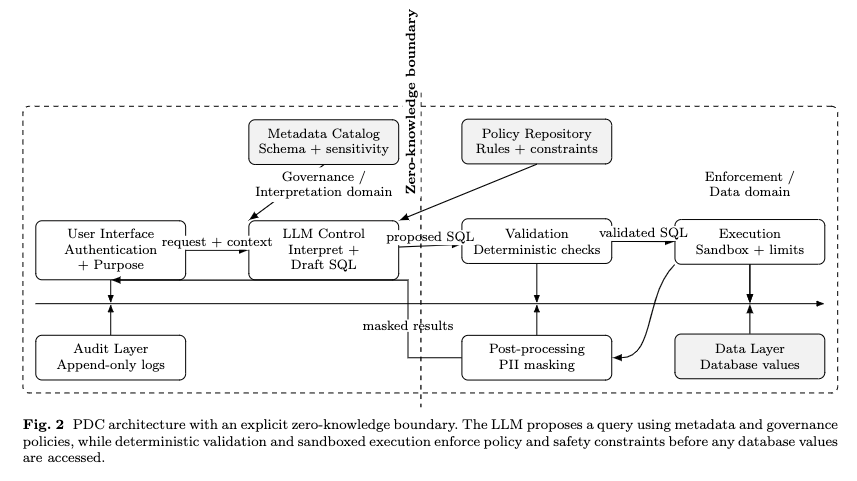
这个设计的关键是职责分离。LLM 负责理解,验证器负责授权,沙箱负责执行,后处理负责输出控制,审计负责追责。论文也明确说,LLM Control Layer 的角色是辅助生成,不承担 enforcement;Validation Layer 才是主要的确定性执行边界;Post-processing 是输出侧的纵深防御;Audit Layer 提供问责和监控。
这和很多企业正在做的“AI 数据分析助手”有明显差别。很多系统的链路是用户提问、大模型生成 SQL、数据库执行、结果返回。PDC 要求在大模型和数据库之间增加强制验证层,并且执行结果不能再进入模型上下文。这个看似保守,但对于企业数据治理来说,恰恰是必要的。
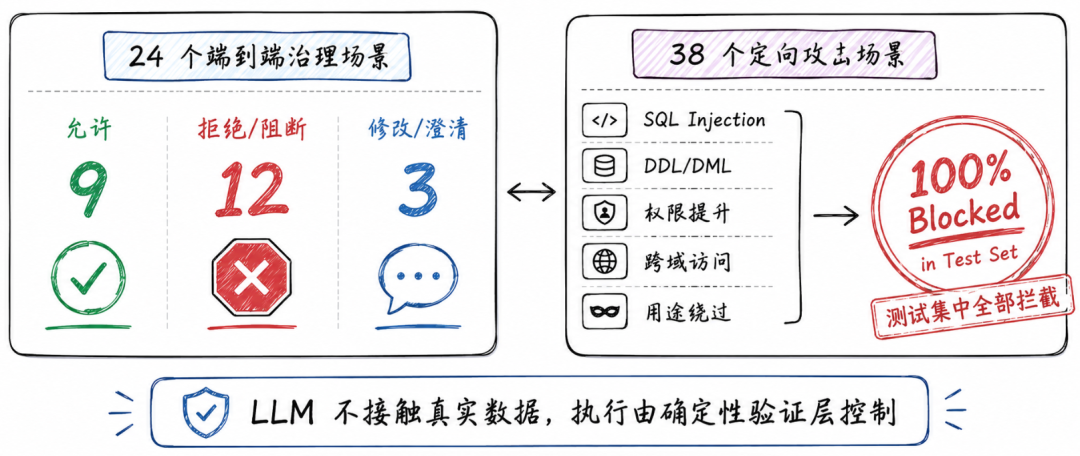
论文实验:24 个端到端场景,38 个攻击场景
作者实现了一个原型系统,技术栈包括 Amazon Bedrock、Claude 3、Python 3.11、Streamlit 和 SQLite 内存数据库。原型数据库设计了 customers、orders、employees、transactions 四张表,用来模拟客户信息、订单信息、员工 HR 信息和金融交易信息。字段里包含 PII、财务敏感信息、HR 受限字段、用途受限字段等治理约束。
评测分成两部分。
第一部分是 24 个端到端治理场景,覆盖允许访问、角色违规、请求转换、跨域访问、用途限制、自然语言中嵌入攻击内容、模糊请求等类别。结果显示,在这 24 个场景中,有 9 个被直接允许,12 个被拒绝或阻断,3 个被修改或要求澄清。论文强调,在这个固定测试集内,没有观察到违反策略的请求被执行,也没有观察到允许场景被错误拒绝。
第二部分是 38 个定向攻击场景,包括 SQL 注入变体、DDL/DML 危险操作、权限提升、跨域访问、用途绕过等。论文报告这些攻击场景全部被阻断,成功阻断率为 100%。不过这个数字要谨慎理解,它说明原型在作者设计的攻击集上有效,但不能直接等同于工业级安全证明。论文自己也承认,当前验证层主要是保守的 pattern-based screening,未来需要加强到 SQL AST 级别,并覆盖更多真实用户查询和更多 SQL 方言。
LLM 不是安全边界
我认为这篇论文最值得关注的地方,不在于它做出了多复杂的系统,而在于它把 LLM 在企业数据治理里的位置摆正了。
LLM 的优势是语义理解。它可以理解用户自然语言请求,可以把模糊的业务意图转成结构化查询,可以解释为什么某些请求被拒绝,也可以把不合规请求改写成合规替代方案。比如,用户想“查看所有客户”,系统可以不给原始客户列表,而是返回聚合统计;用户想查“客户姓名和订单总额”,系统可以去掉姓名,只返回按权限允许的聚合结果。
但 LLM 的弱点也很明确。它容易被提示注入影响,可能生成错误 SQL,可能误解权限策略,也可能在复杂上下文中表现不稳定。因此,它不能承担最终授权职责。真正能承担安全边界的,必须是可以审计、可复现、可测试、可验证的确定性系统。
这对当前 Agent 安全也有启发。Agent 系统里的工具调用、数据访问、文件读写、工单创建、代码执行,本质上都属于“高风险动作”。如果这些动作只靠模型自己判断,就会形成隐性权限扩张。PDC 的思路可以迁移到 Agent 场景:模型可以提出动作建议,但动作进入真实系统之前,必须经过策略验证、权限校验、沙箱执行、结果过滤和审计记录。
所以,这篇论文其实给出了一个很朴素但很重要的判断:企业 AI 安全的重点,不是让模型永远不犯错,而是让模型犯错时不能直接造成事故。
对 AI 安全产品的启发
如果把这篇论文转成产品设计,可以得到一套比较清晰的企业 AI 数据访问安全框架。
第一,企业需要建设治理元数据层。没有字段敏感标签,没有表关系说明,没有角色和用途策略,大模型就只能靠猜。PDC 架构把元数据、策略和权限提升为一等治理对象,模型看到的是这些治理工件,而不是原始数据。
第二,AI 数据问答必须有独立 SQL 验证器。只靠 prompt 提醒模型“不要越权”是不够的。验证器应该在执行前检查只读约束、表字段权限、危险关键字、SQL 注入、LIMIT、聚合限制、用途限制和跨域访问。生产环境里,这一层最好做到 SQL AST 级别,而不是停留在关键词和正则。
第三,结果返回也要做安全控制。即使查询本身合规,结果也可能泄露敏感信息。PII 脱敏、字段裁剪、最小化返回、小样本聚合保护、异常结果拦截,都应该成为输出后处理的一部分。论文也提到,未来可以进一步引入 k-anonymity 或差分隐私,用来降低聚合结果带来的推断风险。
第四,审计要覆盖完整链路。企业不能只记录“谁查了数据库”,还要记录用户原始请求、声明用途、模型生成的候选 SQL、验证层的拒绝或修改原因、最终执行语句和输出处理结果。这样才能在出现争议、误用或攻击时追溯完整路径。
局限性
这篇论文更像一个架构原型和设计范式验证,不能直接理解为成熟产品方案。
它的实验数据库规模很小,只有四张表和少量记录;测试场景也是作者预设的固定集合,不能代表真实企业中千差万别的数据模型、权限策略和用户表达方式。验证器目前也偏保守,主要依赖 pattern-based screening,对复杂 SQL 方言、嵌套查询、窗口函数、数据库特定函数、编码绕过等情况覆盖不足。论文也承认,后续需要更大规模测试、更多场景生成、多模型对比,以及基于 AST 的 SQL 验证。
还有一个问题是,它主要处理只读数据访问。但企业 Agent 的真实边界通常不止于查询。未来的 AI 助手可能会写数据、修改配置、触发审批、发起交易、创建工单,甚至调用外部系统 API。到了这个阶段,PDC 的思想仍然有价值,但执行层需要加入更严格的事务控制、审批流、回滚机制和动作级审计。
同时,元数据本身也不是完全无风险。表名、字段名、敏感标签、组织角色、业务规则,都可能泄露企业内部结构。所以即使大模型不接触真实数据,元数据访问也应该遵循最小权限原则。
写在最后
这篇论文给出的答案很清楚:企业可以让大模型参与数据治理,但不能把数据治理交给大模型。
大模型适合做自然语言接口,适合补齐用户意图和结构化查询之间的鸿沟,也适合给用户解释为什么某些请求被拒绝。但权限判断、SQL 校验、执行控制、结果脱敏和审计记录,必须由确定性系统承担。
从这个角度看,PDC 不是一个单纯的 Text-to-SQL 安全方案,而是一种更通用的企业 AI 安全架构思想:让模型靠近意图,远离数据;让模型生成建议,让系统控制执行;让 AI 提升效率,但不把安全边界让渡给 AI。
这可能会成为企业 AI 落地中越来越重要的一条原则。
让大模型理解数据,但不接触数据。让大模型参与流程,但不掌握最终权限。
这才是企业 AI 数据访问真正应该建立的新边界。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
