
来源:medium
编译:李雷、林安安、宋欣仪、周素云
这篇博文是Catherine Olsson在的两次短篇演讲的基础上撰写的,一次是2018年11月在人工智能合作伙伴会议上,另一次是2019年1月在波多黎各的通用人工智能(AGI)会议上。
我认为对抗样本很值得研究,应该引起高度的重视。然而大多数人关注对抗样本的理由都非常片面。我认为这是因为很多人将尚未解决的研究问题与现实世界的威胁模型混为一谈。
首先让我解释一下对抗样本是什么意思,用一个被很多记者和这类主题的论文会引用的例子,就是假设“人们在停车标志上贴上贴纸会导致撞车” ,通过做一个现实世界的威胁模型可以说明为什么对抗性样本引起。然后我会先通过典型小扰动对抗样本构建一个未解决的研究问题,与现实世界问题建立真实(但不那么直接)的联系,从而得出一些概念性证明。
什么是对抗样本
对抗性样本是旨在导致机器学习模型出错的输入。
常见的对抗样本(但不是必要的)是通过对正确的输入样本进行修改来构建的,这些输入有时被称为“ε-球对抗性样本”或“小扰动对抗样本”。
例如,如果你有一个图像分类模型,并且它能以相当高的置信度(57.7%)正确地对这张图片作出熊猫的分类,但事实上可以这张图片中每个像素变化一点点得到一张新的图片,这样它虽然看起来仍是熊猫,但却会被图像分类模型以极高的置信度(99.3%)错误地识别为长臂猿。

在稍微改变像素之后,新图像被以极高的置信度错误地分类。
值得注意的是,小扰动对抗样本不是深度学习所特有的,也不是特定模型才有的问题。在某些已知的情况下,几乎所有已知的机器学习模型都容易受到高维输入对抗样本的影响,现在还没有很好的解决方案。
识别停车标志的对抗样本
我们已经知道机器学习(ML)模型容易受到对抗样本的影响,因此人们可能很自然地担心在对抗样本会对现实世界产生什么样的影响。
举个例子,假设你正在设计一款自动驾驶汽车,你希望它能够识别停车标志。当你知道抗样本后,你就会很好奇这是否会影响你的车。

如果你正在设计一款可以识别停车标志的自动驾驶汽车,你可能想知道对抗样本是否会导致车辆不能正确识别停车标志。
我是一名负责研究工作的工程师,不做系统设计或部署,因此在分析模型在现实世界中如何发生错误方面我不是专家。但我从事计算机安全工作的朋友和同事教给我的一个方法,是问“你的威胁模型是什么?”
Kevin Riggle 撰写的《深入浅出解释威胁模型》是我最喜欢的一篇博文,也非常通俗易懂。这篇文章通过以下几点解释了威胁模型:
威胁模型只回答与你正在构建或扩展的任何系统相关的一些简单问题。
这是什么系统,系统干系人是谁?
系统需要做什么?
发生不幸的事或者有人蓄意破坏的时候,这个系统会怎样?
系统必须保证的参数,即使发生不幸的事,它使系统仍然能够正确地完成应完成的任务。
为简洁起见,我将这些问题称为干系人,目标,不利因素和不变量。
让我们尝试着把这个框架应用到实际问题中。
在前面的自动驾驶汽车例子中,让我们想象一下,我们的目标是让汽车能在“路口”停车标志前自动停下来。即使有人在停车标志上贴了一个奇怪的故障贴纸,导致它会被错误识别,我们仍然希望车子可以识别。我们列出所有可能会威胁到我们系统的不利因素。例如,雾天、雪天、停车标志被恶意涂抹或者交叉路口施工等情况。

我们的问题清单应该包括停车标志已经倒下的情况。
如果停车标志倒在地上,那么你的车就可能会撞车。这种情况比与原标志很相似的小扰动对抗样本更容易出现交通事故。
总之,我想说的是,如果有人在停车标志上贴上一张故障贴纸,并且任何标准视觉系统都因此检测不到停止标志,那么一辆完全依赖于该视觉系统的汽车很可能会因检测不到停车标志而开入迎面而来的车流,发生碰撞。如果汽车是这样设计的,错误分类的停车标志会导致汽车碰撞,那么在现实世界中很可能会发生类似情况。
但我还找不到一个真实的例子,真有这样的破坏分子去制作和贴贴纸。不仅仅是因为它只是种假设,而是破坏分子实现其目标的最可能的方式是未知的。虽然只是想象,但如果想要人为的造成车祸, 这便是一个既简单又经济的方式。
如果我只是告诉你“破坏分子利用模型梯度的下降,产生导致错误分类的故障贴纸并贴在路标上”是我实际上试图阻止的真实情况,那么我的威胁模型无疑是不完整的。但如果不只关注字面意思的话,它仍然是一个值得研究的模型。
停车标志的对抗样本是否令人担忧
我并不是想说明,“不要再担心了!机器学习模型非常严密和精准!“,我的观点恰恰相反,现实问题往往比一张贴纸的对抗样本更糟糕。
为了解释我的意思,让我们回头查看威胁模型并关注不变量(“系统需要保证什么参数,以便它能够完成需要完成的任务,即使所有不好的事情都发生呢?“)
如果我们的目的是让汽车始终停下,不仅仅是在对抗性标志存在的情况下,甚至是不存在或看不见停车标志的情况下。这意味着我们不能只根据道路标志检测决定何时停在十字路口。威胁模型告诉我们,仅使用一种检测模型不能准确进行安全关键性分析。
所以现在我们要提出一个非常有趣的问题!如何在不使用道路标志检测的情况下识别需要停车的路口? 我们要利用GPS和地图数据吗? 在经过没有 “停车(stop)”或“让道(yield)”标志的交叉路口时要格外小心吗?
考虑到威胁模型,我们意识到这个问题比我们想象的更严重。我们很难强化视觉模型使它能抵抗小扰动对抗标志。为了实现我们的目的,必须彻底放弃“完全依赖标志检测系统”。
为什么要关注对抗样本?
因此,鉴于“对抗性标志”和其它问题的存在,我们需要更全面的解决策略......那么问题来了,为什么我们如此关注小扰动对抗样本呢?
两个最不可抗拒的原因:
一:这是一种概念性证明(Proof of Concept),即某种问题存在的无可辩驳的证明。由于很容易找到小扰动对抗样本,我们可以肯定地说,如果你的系统安全性的前提是分类器永远不会出现明显错误,那么这个前提就是错误的,你的系统是不安全的。

现在的图像分类器甚至不能正确区分鸟类和自行车的图像。
我想强调的是,制造小扰动并不是找到错误分类的样本的唯一方法。还可以用其他方法来制造错误,例如尝试随机转化和旋转图片,或者使用不同的角度或不同的光照效果。
但是,由于小扰动对抗样本的存在,我们就可以找到更明显的错误。
除了一个人有意地通过错误的输入来寻找错误的情况外,任何具有干扰因素的选择都会在无意中发生错误搜寻(例如测试数千个输入的样本以查找哪些点击数最多或最赚钱)。
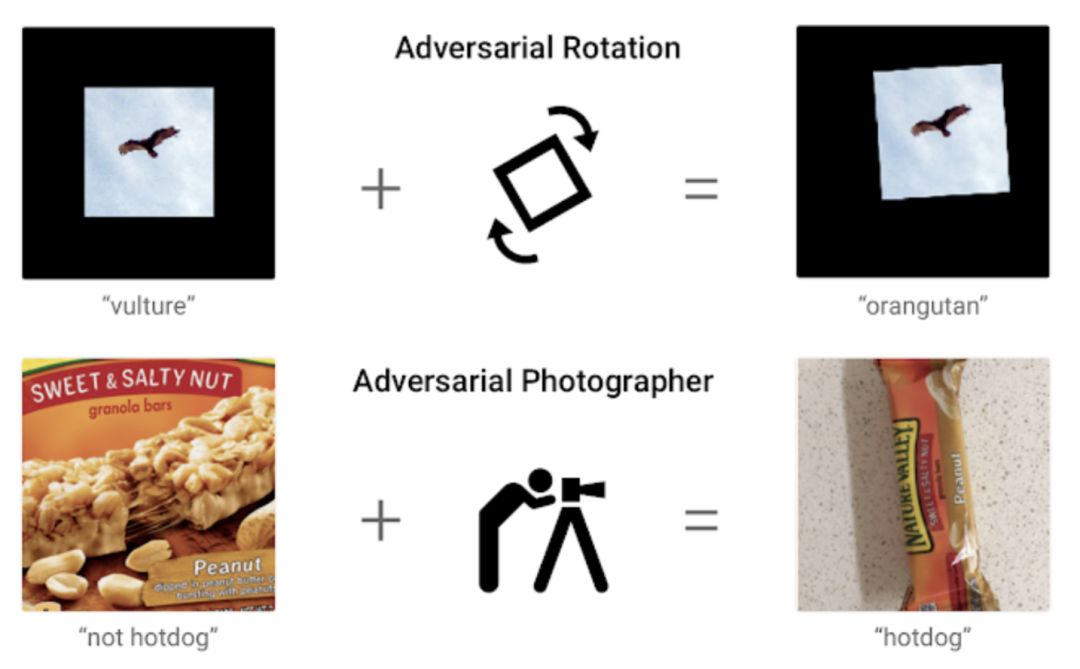
尝试随机转化和旋转,或者使用其它角度或光照效果,图片识别都会发生错误
二:对于研究人员来说,小扰动对抗样本是一个值得深入研究的领域。我咨询了我的同事们,为什么尽管“小扰动”设置不是一个引人注目的现实威胁模型,他们仍然给予高度关注。他们给出了一些理由:
稍微改变下每个像素就可以将其转化为代数运算,这使得形式分析成为可能。
这是分类器所具有的现实问题,因此研究人员可以在真实数据集(而不是合成数据)上进行研究。
研究人员能够由此发现和学习关于模型稳定性问题,我们知道迷惑一个模型的图可能也会迷惑另一个模型,这是一个很好的玩具问题(不具有直接科学意义的问题,但可以被用作说明复杂的问题的实例)。
虽然这并不是一个令人信服的观点,即“小扰动”设置是研究稳健性的最佳或唯一设置,但我仍深深为之着迷。
这基本上表明对抗样本作为一个尚未解决的研究问题,它不仅可以作为一系列可证明问题的概念性工具,还可以被用于处理有意义的现实问题。
我倾向于将对抗样本视为一种范式(在库恩意义上),可用于演示和研究机器学习系统中稳健性的失败,并且进一步探索解决方案。 虽然它有其作为范式的局限性,但我很高兴的看到机器学习研究人员通过开发和传播新的和改进的范式来迭代和完善模型稳健性方法。
未解决的研究问题不等于现实世界的威胁模型(但两者都很重要)
具体来说:
未解决的研究问题通常需要构建“玩具域“(toy domains),以便模拟关键困难。虽然不太可能与现实世界的结果相似,但它们可以帮助模拟系统可能出现的问题。在玩具问题上取得的概念性进展可以引导该领域形成新的范式。
在已生成的系统中,你还会碰到很多问题,比未解决的研究问题更加基本,因此你需要一个具体的威胁模型来指导采取有效的解决策略。甚至你可能需要彻底更改设计,而不是小修小补。

在已生成的系统中,你还会碰到很多比未解决的研究问题更加基本的问题。
“但这些问题早就存在了!”或“我们还有比这更基本的问题!”之类的说法并不是假装一切都会好的理由。 对抗样本更应该作为一种提醒,提醒我们仔细规划,检查假设,并充分考虑一切因素。
如果你正在开发模型,无论它是否包含机器学习,你都需要一个实际的、具体的计划来预测和减少负面结果。
如果你是一名研究员,我会督促你不要通过声称它确实代表一种现实威胁来证明你对玩具问题的研究是合理的,除非你同时提供了威胁模型。 我更愿意看到理由解释为什么你的玩具问题是一个有效的概念理解试验台,以及为什么我们可以期望这些概念能够进一步阐明现实问题。
如果你正在与人聊对抗样本,我强烈建议你和对方解释清楚这其中的区别!
这些想法并不是我新提出和独有的,很多人以前都说过这一点。 我主要受到以下研究的启发:
Gilmer et al. 2018 “Motivating the Rules of the Game for Adversarial Example Research”
Unrestricted Adversarial Examples Challenge & Brown et al. 2018
Demski 2018“Embedded Curiosities” (Specifically the line “it’s tempting to draw a direct line from a given research problem to a given safety concern”)
相关报道:
https://medium.com/@catherio/unsolved-research-problems-vs-real-world-threat-models-e270e256bc9e
声明:本文来自大数据文摘,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
