作者:孙中豪,何跃鹰
序言
2019年6月18日,工信部发布了《网络安全漏洞管理规定(征求意见稿)》,在业内引起了一阵议论。该征求意见稿对漏洞修复和发布都做了明确的规定,以及违反该规定后的惩罚办法。
先不论该规定是否合理,仅就有关部门能义无反顾地站出来,承担起漏洞管理的责任,这本身就是一件值得肯定的事情。但是,征求意见稿对所有漏洞的危险等级不做区分,对不同行业对漏洞的容忍度不做区分,对高、中、低危漏洞一视同仁的修复和发布规定,在具体实施中可能面临重重困难。
此外,征求意见稿对漏洞发布的严苛要求,可能会打击漏洞研究人员的积极性,也可能把相关研究成果逼向国外的漏洞平台甚至是网络黑产。类似的事情已经在金融领域发生过一次,国内大量优质企业选在在美国或者香港上市,一定程度上与证监会严苛的管理规定有关。
言归正传,本文将通过整理一组最近的研究结果,揭示一些鲜为人知的漏洞管理方面的统计数据,供有关人员参考。
摘要:尽管IT安全相关的产品和研究在过去20年里取得了长足的进展,但是从业者依旧缺乏正确评估其系统风险的能力。换句话说,从业者不知道如何用最少的成本(时间、金钱、资源等),最大化的降低其安全风险。如果一个企业试图修复其产品中所有的已发现漏洞,毫无疑问将最大化的降低安全风险,但这需要投入巨大的成本;如果仅选择修复高危漏洞,又可能会遗漏很多那些真正造成风险的漏洞。本文从准确率(accuracy)、覆盖率(coverage)、效率(efficiency)等方面,详细对比了四种漏洞修复策略:(1)基于CVSS评分的修复策略,(2)基于已公布PoC的漏洞修复策略,(3)基于漏洞标签的修复策略,(4)随机的修复策略。我们希望通过本文展示的研究数据,能够给漏洞管理部门和相关从业者提供一些素材,最主要的是看到每种策略的局限性,从而避免在工作中被这些局限性所误导。
1、数据来源
本文采用CVE 2009-2018间收录的漏洞作为基础数据,总共约7.5万个漏洞。关于漏洞的评分和描述,则来自于NVD;关于漏洞标签,采用Rapid Automatic Keyword Extraction方法从CVE及其漏洞相关的参考文献中抽取关键字,共获得83个描述漏洞的标签;关于已公布PoC的漏洞数据,来自于三个数据库,分别是Metasploit、 D2 Security’s Elliot Kit 、Canvas Exploitation Framework;关于已被利用漏洞的数据,则来自于对10万个网站的监测数据。最终的数据汇总如下:
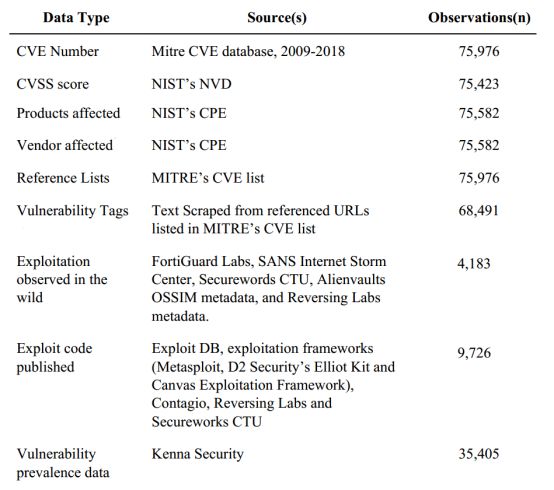
图1 数据汇总
1.1 CVSS评分
CVSS v2于2003年首次开发,现已成为衡量漏洞严重程度的国际标准和事实标准。CVSS的数值分数介于0(最低严重性)和10(最高严重性)之间。下图展示了CVSS评分系统中各分数段漏洞的分布以及被利用情况。例如,在所有漏洞中,有4686个漏洞获得了10分,其中有16.8%的漏洞在非受限环境下被利用。
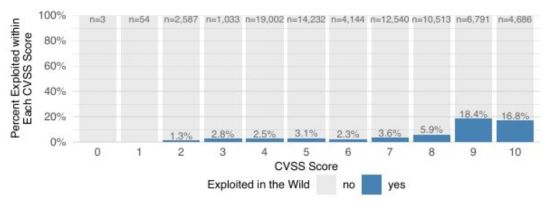
图2 基于CVSS评分的漏洞分布和利用情况
从上图可以看出,CVSS评分在9-10之间的漏洞被利用的比率最高,而漏洞平均利用率为5.5%。
1.2 已公布PoC的漏洞
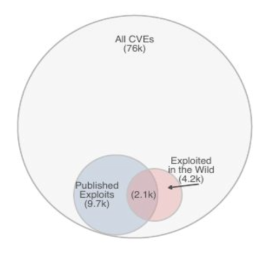
图3 已公布PoC的漏洞VS已被利用的漏洞
如图3所示,本文从三个数据库中一共找到了9.7K个已公布PoC的漏洞。通过对10万个网站的监测,一共发现了4.2K个在非受限环境下已被利用的漏洞。也就是说,在2009年至2018年期间,大约12.8%(9.7k/76k)的漏洞都发布了PoC;而在非受限条件下,只有大约5.5%(4.2k/76k)的漏洞被利用。
此外,只有大约一半被利用的漏洞(2.1K)是已公布PoC的。这说明,一个漏洞是否被黑客利用,与其是否发布了相关的PoC并没有强相关性。
1.3 漏洞标签
本文首先通过MITRE的 CVE列表获取漏洞的文本描述信息,然后再从漏洞参考文献中的URLs获取其他文本描述信息。通过采用Rapid Automatic Keyword Extraction方法从上述文本信息中抽取漏洞描述相关的标签,例如“代码执行”、“SQL注入”、“拒绝服务”等关键字,这些都是漏洞标签。
图4所示为随机选择的20个标签及其出现频率,以及拥有该标签的漏洞在非受限条件下被利用的比例。例如:一共有4608个漏洞具有缓冲区溢出(“buffer overflow”)标签,这其中有13.5%的漏洞已被利用。
在删除了几乎零差异的标签之后,我们的最终获得了83个独立的标签。
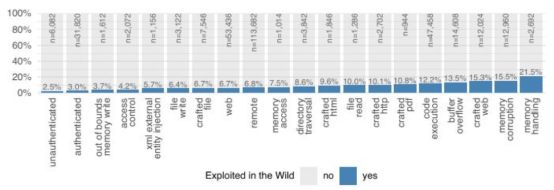
图4随机抽取的20个漏洞标签
2、评估标准
在整个分析过程中,本文将从覆盖率、效率、准确率和成本四个维度评估评估各种漏洞修复策略的性能。
覆盖率:衡量一种策略的完整性。如果被利用的漏洞一共有100个,但仅修复了15个漏洞,则这一策略的覆盖率为15%。覆盖率在数学上表示为真阳样本除以真阳样本和假阴样本之和,即tp/(tp+fn),当假阴性数趋于零时,覆盖率取得最大值。
效率:衡量一种策略的效率。如果我们修复了100个漏洞,但只有15个漏洞是被利用了的漏洞,那么这个策略的效率就是15%。另外85%就是无用功。效率以代数形式表示为真阳样本数除以真阳和假阳样本数之和,即tp/(tp+fp),并随着假阳性数量趋于零而最大化。
准确率:衡量一种策略的整体正确性。准确率是真阳样本和阴性样本之和除以样本总数,即(tp+tn)/(tp+tn+fp+fn)。
成本:在本文中表示采用某种策略一共需要修复的漏洞的个数。
3、常见漏洞修复策略对比
3.1 基于CVSS评分的漏洞修复策略
基于CVSS评分的漏洞修复策略是最常见的一种方法。例如,美国国土安全部(DHS)向联邦机构发布了一项具有约束力的指令,要求他们在15天内修复9分以上的漏洞,并在30天内修复7-8.9分的漏洞。此外,支付卡行业数据安全标准(PCI-DSS)要求所有商家修复CVSS分数高于4.0的漏洞。
图5展示了7中基于CVSS评分的漏洞修复策略的评估结果,以及对应的随机修复策略的结果。例如:“CVSS 7+”表示修复所有CVSS评分在7分以上的漏洞。
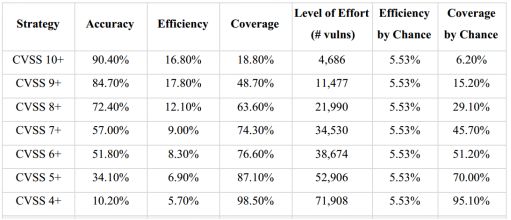
图5 基于CVSS评分的漏洞修复策略评估结果
图5的结果表明,使用CVSS 7+策略可以获得高于74%的覆盖率,效率为9%,准确度仅为57%。CVSS 7+策略似乎是基于CVSS评分的策略之中的最平衡的选择,虽然它仍然会多修复约31K的不必要修复的未利用漏洞。此外, PCI-DSS要求的对得分为4+的漏洞进行修复,这几乎和随机策略的效率一样,且以修复72K个漏洞为代价。
虽然一些研究表明,基于CVSS评分的漏洞修复策略并不比随机修复效果好[1],但是本文的研究结果表明,修复CVSS得分9+的漏洞明显好于随机修复策略。
3.2基于已公布PoC的漏洞修复策略
记录在非受限环境下漏洞利用的情况是最近才具备的一种能力。在此之前,最有价值的数据就是那些关于漏洞PoC的数据库。当时的人们会认为修复那些已经发布了PoC的漏洞才是有价值的,因为“已经发布PoC的漏洞集合”已经是当时人们能找到的最逼近“在非受限环境下被利用的漏洞集合”。
图6所示为根据三个PoC数据库(Elliot、Exploit DB、 Metasploit)的漏洞修复策略的评估结果。简而言之,这种策略就是修复对应数据库中所有已公布PoC的漏洞。
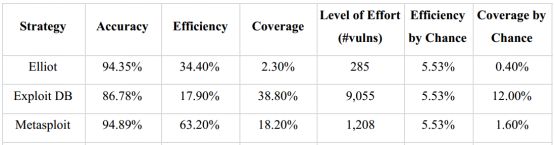
图6基于已公布PoC的漏洞修复策略评估结果
我们首先注意到,基于Exploit DB数据库的策略具有最好的覆盖率,但是效率最低。而基于Metasploit数据库的策略在效率上表现非常好,但是覆盖率却大大减少,并且满足工作量大大减少。基于Elliot数据库的策略虽然不如Metasploit效率高,但成本很低,仅修复285个漏洞 。
基于不同PoC数据库的策略,在效果上差别如此之大,主要原因还在于这3个数据库内容上的不同。Exploit DB中主要是源代码和脚本,利用这些代码需要一些基础知识,比如编译、执行等。而Elliot和Metasploit这两个数据库直接提供人机界面的可执行的漏洞利用程序,所以利用这两个数据库中的漏洞的技术门栏要低很多。
3.3基于漏洞标签的修复策略
最后,本文考虑一种基于漏洞标签的修复策略,该策略由CVE参考链接中提供的常用关键字(即标签)构成。除了从CVSS获取的数据之外,关键字还可以提供对特定漏洞的特征和潜在影响的简要分析。
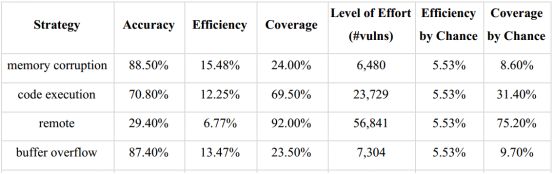
图7基于漏洞标签的修复策略评估结果(4个标签)
图7所示为从总共83个标签中抽取的4个标签的修复策略的评估结果。例如,基于“remote”标签的修复策略,就是把所有具有“remote”标签的漏洞都修复。所有83个标签评估结果如图8所示。
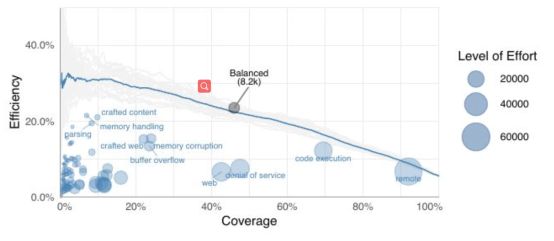
图8基于漏洞标签的修复策略评估结果(83个标签)
显而易见,所以基于标签的修复策略的效率都是低下的。基于“memory corruption”和“buffer overflow” 这两个标签的修复策略的效率相对高一点,因为具有这两个特征的漏洞往往提供了更具吸引力的攻击目标。更有趣的是,如果“buffer overflow”标签和CVSS得分9-10具有强相关性,那么基于“buffer overflow”标签的策略应该和基于CVSS9+、CVSS10+的策略应当具有相似的性能。
4、本文的局限性
本文的实验结果和推论仅限于本文所收集的数据,因此可能无法具有普遍的代表性。具体而言,漏洞扫描数据仅限于使用的商业和开源漏洞扫描程序,以及在那些网络中运行的软件,因此可能遗漏对部分漏洞利用数据的观察。
在整篇文章中,我们将已知的漏洞称为“在非受限环境下的漏洞”,但我们认识到这种推断仅限于基于特征的入侵检测/预防(IDS / IPS)系统观察到的漏洞。首先,我们不知道有多少未检测到的漏洞无法找到特征,因此我们永远无法在非受限环境下观察到这种漏洞。其次,IDS / IPS可能没有最新的特征库,因此错过了一些已知的漏洞。
此外,本研究中没有考虑零日漏洞,因为这些漏洞无法通过基于特征的漏洞扫描程序发现。
本文的风险度量仅与威胁有关(即漏洞被利用的可能性),并且不考虑决定风险的所有其他因素,例如目标组织采用的安全管控强度,或资产或资产数据的价值,或成功利用可能造成的实际影响等。此外,虽然有许多因素决定了漏洞被利用的可能性(例如,动机、攻击者的能力、经济、外交或政治方面的考虑因素),但我们无法单独确定这些因素。因此我们的结果衡量标准仅仅是看一个漏洞是否被在非受限环境下被观察到利用。
5、总结
本文所介绍的数据和研究成果主要来自对《Improving Vulnerability Remediation Through Better Exploit Prediction》这篇报告的汇编整理。主要从覆盖率、效率、准确率、成本等方面对不同的漏洞修复策略进行了评估,从本文的评估中,读者可以发现一些与我们感性认识不太一样的漏洞统计知识,我们最终的目的还是希望这篇文章能给漏洞管理部门、安全研究人员在制定相关政策、制度的时候提供一个参考。
[1] Allodi L, Massacci F. Comparing vulnerability severity and exploits using case-control studies[J]. ACM Transactions on Information and System Security (TISSEC), 2014, 17(1): 1.
声明:本文来自工业互联网安全应急响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
