网页被植入暗链是企事业网站上常见的攻击行为,攻击手法变化多样,传统方法基于规则检测已经无法高效检出。
本文使用域识别机制提取风险文本和安全文本,通过 LDA 模型和 Doc2vec 模型计算主题异样度、风险文本异常概率、风险文本向量等特征,分别选用 SVM 模型、逻辑回归模型、随机森林模型构建监督学习模型检测网页暗链并对比模型效果。
实验结果表明,该方法具有较好的检出效果和运行效率,其中随机森林模型检出准确率达到了 0.999。
近年来,互联网行业蓬勃发展,网络信息成指数级增长。在这种海量信息下,搜索引擎成为主要的信息搜索工具,搜索引擎通过爬取网站信息并对网页内容计算权重做排名展示在搜索结果中。
由于展示在搜索结果前部的网站有更大概率被用户访问,某些网站管理者为了获取更多访问量,往往采取各种作弊手段。
“暗链”就是一种提高网站排名的作弊手段。具体说,“暗链”指的是攻击者获取网站权限后,修改网页源码,插入指向其他网站的反向连接代码,并且用户在正常浏览网页时无法看到此链接,但可被搜索引擎检索计算权重。
一旦网页中存在暗链,通常这个网站已经被入侵,网站存在被植入恶意代码、网页被恶意篡改、数据信息泄露等风险。
因此,“暗链”相比于其他搜索引擎作弊方式,具体有更大的危害性,并且难于发现。
相关学者在这方面做了大量研究,从已公开的文献看,多数是使用基于规则的检测,如文献是使用基于规则加黑名单识别网页暗链,此方式对于高度混淆的暗链代码识别较弱。
仅有少数是使用机器学习算法实现,孟池洁等人使用了机器学习对页面中提取的所有锚文本作为特征构建模型识别暗链,此种方式提取了页面所有锚文本,会产生很多噪音数据,提取的特征较粗,会降低识别效果,并且由于仅通过锚文本做特征会将不含暗链的页面内容篡改误识别为暗链。
周文怡等人通过网页中抽取暗链a 标签文本敏感词特征、暗链域名特征、暗链隐藏结构特征构建机器学习模型,此方法中敏感词特征很容易通过混淆绕过,并且文中标签种类选取较单一,会导致大量漏报产生。
针对这些问题,本文提出一种对高混杂暗链代码识别效果好、特征提取得比较完整、且能够很好区分暗链和页面篡改的多域识别构建机器学习模型检测网页暗链的方法。
网页暗链检测模型构建
根据网页中暗链植入特点,提取可疑链接信息,可疑代码信息,可疑文本信息,做暗链检测,使用多模型融合提高结果准确度。
具体逻辑如图 1 所示,分为安全域识别模型、可疑域识别模型、主题识别模型,通过设置各模型权重,并将三个模型结果信息融合导入机器学习模型训练,得到综合结果用于鉴别。检测结果导入人工审核机制,对审核确认后的样本自动加入模型重训练流程。
图 1 网页暗链检测模型架构
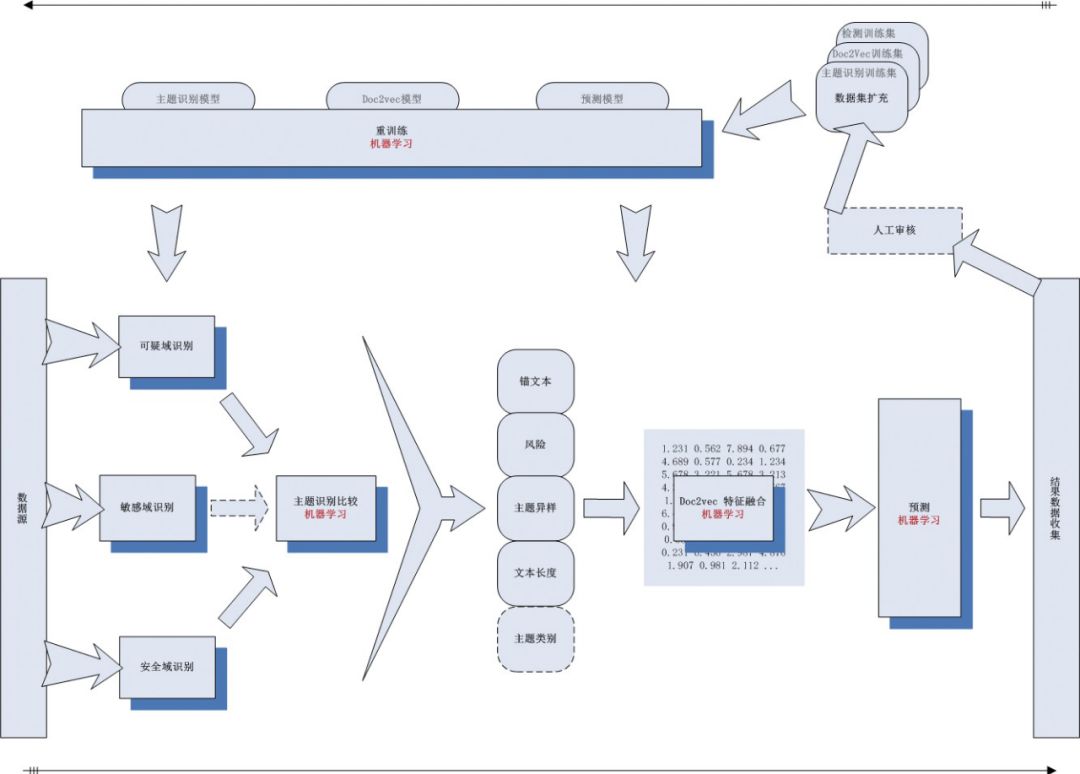
网页暗链检测模型收集大量网页源码作为训练集,所述训练集中包含已被标注为包含暗链的网页和标注为正常的网页,提取训练集用于构建机器学习模型的特征数据,包括风险度、主题异样度、主题、风险文本向量、风险文本异常概率以及风险文本长度等。
具体来说,使用基于规则的模型提取可疑敏感文本信息,模型包括:可疑域识别模型、敏感域识别模型、安全域识别模型。使用机器学习模型对特征做深度抽取融合检测,模型包括:主题识别模型、基于 Doc2vec( 文档向量模型 ) 特征融合模型、基于监督学习的暗链检测模型。
多域结合的主题识别比较算法
网页中被植入的暗链,通常是淫秽、博彩、商广等内容,其锚文本含义与整体网页主题有很大差异,这种主题差异可作为最终监督学习决策模型的重要特征。本文使用基于规则的多域模型提取网页中可疑文本信息和正常文本信息,导入 LDA(Latent Dirichlet Allocation) 主题识别算法提取主题并计算差异度。
2.1多域识别
结合安全专家知识,通过对历史样本数据分析,根据网页不同位置可被植入的风险度, 划分为可疑域、敏感域、安全域。对不同域识别匹配可估算出网页整体风险度。
2.1.1可疑域识别
分析网页源码,提取网页源码中所有可疑域,对每个可疑域进行风险度识别并获取风险文本。可疑域具体指包含隐藏效果的代码区域, 包括但不限于:
(1)链接位于页面可见范围之外,即通过改变 position 位置达到页面不可见。可以将 position 位置属性设置成负数,则链接无法显示在可见页面之内。代码示例如下:
<divstyle="position:absolute;left:expression_r(1900);top:expression_r(3-999);">
<a href=" 暗链 "> 锚文本 </a>
</div>
<div style="position:absolute;top:-999px;right:- 999px;">
<a herf=" 暗链 "> 锚文本 </a>
</div>
<div style="text-indent:-9999em; display:block; float:left">
<a herf=" 暗链 "> 锚文本 </a>
</div>
(2)利用跑马灯 marquee 属性,即通过改变跑马灯 marquee 参数达到用户不可见。链接以跑马灯形式迅速闪现,跑马灯的长宽设置很小,同时将闪现的频率设置很大,使得查看页面时不会有任何影响。代码实例如下:
<marqueeheight=1width=4 scrollamount=3000 scrolldelay=20000>
<a href= " 暗链 "> 锚文本 </a>
</marquee>
(3)利用 display:none 和 visibility:hidden 隐藏区域里的内容,即通过设置“ display:none”, “overflow:hidden”达到用户不可见。代码实例如下:
<div style="display:none;">
<a href=" 暗链 "> 锚文本 </a>
</div>
<div style=" overflow:hidden;">
<a href=" 暗链 "> 锚文本 </a>
</div>
2.1.2敏感域识别
分析网页源码,提取网页源码中所有敏感域,对每个敏感域进行风险度识别并获取风险文本。敏感域具体指可能含有隐藏效果的代码区域,包括但不限于:
(1)包含 style 属性赋值的 <div> 标签区域
(2)包含 id 属性赋值的 <div> 标签区域
(3)包含 class 属性赋值的 <div> 标签区域
(4)<td> 标签区域
(5)<marquee> 标签区域
(6)<ul> 标签区域
(7)<tr> 标签区域
2.1.3安全域识别
分析网页源码,提取网页源码中安全域,分析每个安全域,提取安全域的锚文本信息, 将提取的所有安全域的锚文本信息作为安全文本。其中,安全域指内链接的 <a> 标签域。
2.2基于 LDA 的主题识别比较
2.2.1主题识别
本文使用 LDA 主题模型提取域识别中风险文本和安全文本主题。LDA 是由 Bleide[5] 等人提出的一种非监督的贝叶斯文档主题生成模型。
假设对文档 t 做分析,其中包含多个主题,θd 表示每个主题的占比,θd,k表示文档t中包含主题d 的占比,α和η为狄利克雷分布,W 为文档词语集,z 为文档中的词汇主题集,β 为词项分布超参数,LDA 模型的概率分布可表示为:
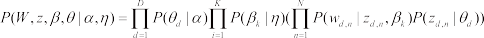
其 中,p(θd|α) 和 p(θd|α) 和 p(βk|η) p(βk|η) 假设为以α和η 为参数的K 维和N 为狄利克雷分布,并且有如下关系:

给 定 训 练 文 本 每 片 文 本 的 词 频W={w1,w2,...,wD}, LDA 的参数 α 和 η 可以通过极大似然法估计:
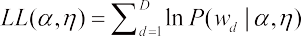
但由于 p(wd|α,η)p(wd|α,η) 计算难度较大,常用变分法和吉布斯采样来近似求解。若α 和 η 已经确定,则可以通过文档词频来推断文档包含的主题结构。
2.2.2主题异样度计算
对近十年中国境内网站被植入暗链类型统计,将主题类别分为:商广、淫秽、博彩、游戏、医疗五个类别。从收集的 10 万级别暗链网站样本中,使用 LDA 主题抽取算法,针对 5 个类别暗链网页,抽取所有主题词并集合安全专家提供的专有词汇构成每一个主题类别下的主题词集合 T,并设置每个主题词权重W。
在模型训练检测阶段,通过敏感域识别后提取出了风险文本和安全文本,分别使用 LDA 算法抽取两类文本的主题集,使用表 1 主题异样度算法计算得到 prob。
如表 1 所示,输入值为安全文本 safe_text、风险文本 risk_text、阈值 threshold, 输出为主题异样度 prob。
步骤 3 和4 对原始文本做去噪操作,具体为过滤掉特殊字符乱码等噪音。步骤 5 和 6 使用 LDA 算法提取安全文本和风险文本主题词集,步骤 7 和8 根据不同主题类别中匹配的主题词数量得到安全主题类别 saf_category、风险主题类别 risk_ category, 步骤 9 和 10 将主题词数量与对应权重W 乘积累加并做归一化操作得到匹配率,步骤11-16 根据匹配率和 threshold 大小计算最终主题异样度 pro。
表 1 主题异样度计算


基于 Doc2vec 的特征融合算法
3.1Doc2vec
Doc2vec 是由 Quoc Le 和 Tomas Mikolov[6] 于2014 年提出。它是在 word2vec[7] 上扩展的获取文本向量表达方式的一种非监督算法。使用生成的文本段落向量,可进一步判定多个文本段落的相似性。
Doc2vec 分为两种方法:distributed memory 和 distributed bag of words, 与 word2vec 模型 中 的 CBOW 和 skip-gram 相 似。
Doc2vec 以word2vec 中的神经网络模型为基础,同时在模型训练过程中加入文本向量 ID,所有文本向量和词向量做连接或相加,通过梯度下降收敛到最终文本向量。
Doc2vec 模型增强了语义稀疏向量在相似度计算上能力,同时使用 Doc2vec 模型可避免单一词语间排序对结果造成的影响。
3.2特征生成及融合
对提取的风险文本使用 Doc2vec 生成风险文本向量,并计算出风险文本异常概率、风险文本长度。
将训练集网页中提出的风险文本经去噪、分词、停用词过滤等处理后作为 Doc2vec 模型训练字符串样本集,还需将训练集中每个源码对应风险文本 ID与类别class 标识合并到字符串作为风险文本 tag, 经训练后生成 Doc2vec 模型。
风险文本异常概率 rta_prob 使用公式 6 计算。具体来说,检测阶段将提取的风险文本字符串导入 Doc2vec 模型生成风险文本向量 vecs, 将 vecs 与训练集中所有历史文本集向量 docvecs 做相似性计算取最相似 k 个文本向量,并提取每个向量类型标识 tag, 计算类型标识 tag 为暗链的数量与 k 的比值即为风险文本异常概率。
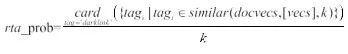
风险文本长度为对风险文本进行去噪后的文本的整体长度,去噪方法需保证与前文所述一致。将计算得到的风险文本异常概率、风险文本 D 向量,风险文本长度,第 3 节中得到的风险度、主题异样度、主题,所有特征融合到一个向量中,用于后续的监督模型决策。
基于监督学习的暗链决策算法
本文训练监督学习模型用于暗链网页检测。依据第 3、4 节介绍的算法可从原始包含正常网页和暗链网页数据集中抽取所有特征向量:风险文本异常概率、风险文本向量、风险文本长度、风险度、主题异样度、主题类别,将特征向量导入模型做训练和决策识别暗链网页。
依据网页暗链数据集规模、特征稀疏性、工程化可落地性,选取逻辑回归模型、SVM 模型、随机森林做测试比较,选取最优模型。
逻辑回归模型是一种分类模型,由于其高效的性能、简洁的原理,是目前工业界应用最广的模型。逻辑回归模型建立一个代价函数,通过在训练数据中对代价函数迭代求解出最佳模型参数,其核心思想是在线性回归模型上加入logistic 函数,把原线性回归模型以 logistic 归一化后用于处理分类问题。逻辑回归损失函数为:
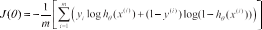
使用梯度下降算法计算得到最佳参数 θ:
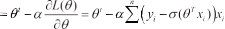
SVM 是经典的机器学习算法 [8],应用于许多分类和回归问题中。它的基准模型是在数据集上训练一个间隔最大的线性分类器,对于线性不可分情况,使用非线性映射算法 (SVM 核函数 ) 将低维空间线性不可分样本转为高维空间使之达到线性可分效果。常见核函数有如下几类:
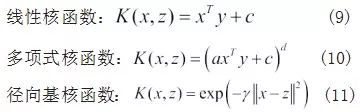
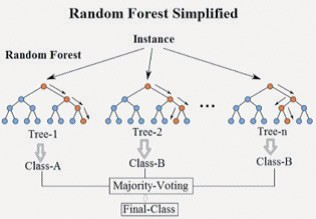
随机森林模型属于bagging 算法中的一种[9], 通过构建 k 个决策树模型作为基础模型,在每个决策树构建中都会引入随机的属性选择,最后使用投票策略将多决策树结果融合输出。模型主要步骤如图 2 所示,
可概述为:①对原始数据集做可放回随机抽样成 k 组子数据集;② 从样本的 N 个特征中随机抽样 m 个特征;③对每个子数据集构建最优学习模型;④对新输入数据,根据 k 个最优学习模型,投票得到最终结果。
图 2 随机森林模型
实验
5.1数据描述
本实验数据包括正常网页和被植入暗链网页数据。数据来源为 2017 年阿里云安全算法竞赛数据集、2017“网藤杯” 智能安全机器人养成计划暗链样本数据集,暗链网页数据集共计2 万余份,使用网络爬虫爬取正常网页数据 2 万余份,共计 4 万样本数据组成暗链检测数据集。
暗链网页数据集中包含多种形式的植入方式, 部分类型举例如下:
(1)display:none 方式隐藏
图 3 暗链通过 display:one 隐藏样例

(2)script 中 display:none 方式隐藏
图 4 暗链通过 script 方式隐藏样例

(3)通过颜色隐藏
图 5 暗链通过颜色方式隐藏样例

5.2特征抽取计算
依照前文所述,需从训练数据集中提取的特征包括:风险文本异常概率、风险文本向量、风险文本长度、风险度、主题异样度、主题。
(1)主题异样度、风险度、风险文本长度从训练样本集中使用 3.1 节多域识别方法抽取出风险文本、安全文本、风险度,使用 3.2 节介绍的基于 LDA 主题识别比较方法训练计算主题异样度,根据风险文本计算风险文本长度。
(2)风险文本向量、风险文本异常概率从训练样本集中使用 3.1 节多域识别方法抽取出风险文本,然后使用 4.1 节介绍的 Doc2vec算法生成风险文本向量,使用 4.2 节介绍的方法计算风险文本异常概率。
(3)主题使用 LDA 算法可提取文本集主题类别,导入机器学习模型时需将字符串类型数值化,因此将设置的五个主题类别 ( 商广、淫秽、博彩、游戏、医疗 ) 做数值化编码处理。
5.3模型训练及评估
5.3.1LDA 模型训练
在计算主题异样度等特征时,需要首先基于历史数据训练 LDA 模型。本文中,对采集到的 4 万个包含暗链样本和正常样本的数据集使用 LDA 模型训练,使用训练好的模型抽取 6.2节中需要的特征。
5.3.2Doc2vec 模型训练
在计算风险文本向量、风险文本异常概率特征时,需要首先基于历史数据训练 Doc2vec 模型。本文中,对采集到的包含 4 万个暗链样本和正常样本的数据集使用 Doc2vec 模型训练,使用训练好的模型抽取 6.2 节中需要的特征。
5.3.3监督模型训练
将包含 2 万个正常样本数据和2万个暗链样本数据的数据集, 使用 SVM 算法、逻辑回归算法、随机森林算法通过7折交叉验证方式选取最佳模型,所有算法使用默认参数配置,通 过模型初选后,对最佳模型做进一步参数调优。
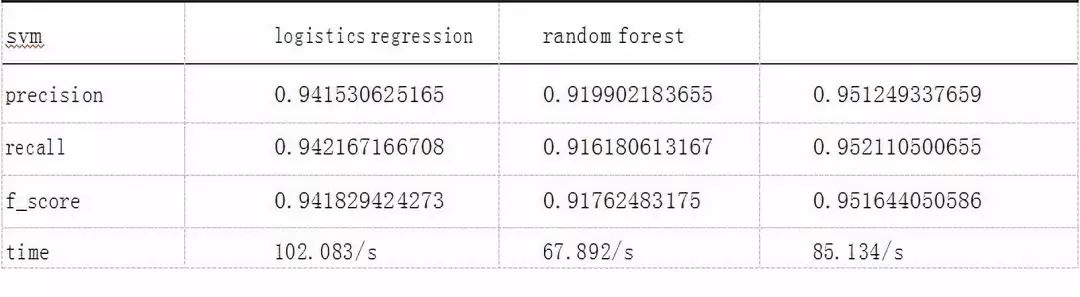
各模型效果如表 2 所示,分别展示了各模型经过7折交叉验证后的准确率 (precision)、召回率(recall)、f 分数 (f_score)、运行时间 (time),从模型效果方面考虑三个模型中随机森林模型效果 最好,准确率、召回率和 f 分数均高于其他两个模型,从运行效率方面考虑逻辑回归模型运行时间最短。
因此,综合考虑模型检测效果、运 行时间和可解释性等方面,选取随机森林模型 作为最佳模型。
表 2 三种模型评估指标对比
5.3.4模型调优
选取随机森林模型后,需对模型做进一步参数调优,使其达到最佳检出效果。以 scikit- learn[10] 中的随机森林为例,主要可调参数为criterion、max_features、min_samples_leaf、min_ samples_split、e_estimators。
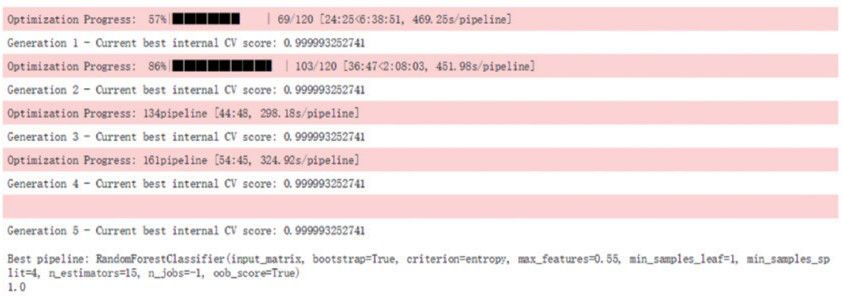
因可调参数数量多,本文中使用 TPOT[11] 完成自动化模型调优,TPOT 是一个 Python 编写的软件包,利用遗传算法进行特征选择和算法模型选择。通过 TPOT 模型调优后,如图 6 所示随机森林模型最终 CV scroe 为 0.999993252714。
图 6 使用 TPOT 工具对随机森林模型参数调优
本文介绍了一种通过多域模型识别提取特征构建监督学习模型检测网页暗链的方案,在4 万余份样本数据集中验证了本方案的可行性,并且通过多个监督学习模型比较,选取了随机森林模型作为最佳可工程化模型。对随机森林模型做了进一步的参数调优,使最终模型达到了较高的检出效果。
本方案中,使用了 LDA 模型和 Doc2vec 模型做特征抽取融合,使用随机森林模型做最终暗链网页和正常网页分类,整体方案属于多模型融合计算,对暗链攻击的变化模式可以有较好的自调整适应。
加入多域模型识别提取特征可解决传统模型特征提取较粗,降低识别效果,将不含暗链的页面内容篡改误识别为暗链等问题。
但多域模型属于规则模型,虽然我们在实际工程中对多域模型做了多种规则弱化处理,但是对整体检测效果还会有较直接影响。
后续研究中,我们会对多域识别特征提取方式做智能化改进,通过引入区域敏感性智能识别算法降低对规则的依赖性。
孟雷, 硕士,上海斗象信息科技有限公司机器学习专家,研究方向为网络安全、人工智能。
选自《信息安全与通信保密》2019年第十期
声明:本文来自信息安全与通信保密杂志社,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
