摘要
海量告警的筛选问题多年来一直困扰着安全行业。为了减轻运维人员排查告警的压力,提高对安全威胁的发现能力,需要对安全设备产生的告警日志进行进一步的分析,筛选出关键的具有高威胁度的告警。本文是AISecOps专题中的一篇,进一步介绍基于特征相似性的安全设备告警评估方法。
一、背景
海量告警的筛选问题多年来一直困扰着安全行业。企业侧的安全设备,例如IPS,WAF等每天产生大量的告警。这些告警远远超出了安全运维人员的排查能力。而在这些告警中,真正有威胁的(即代表系统真正被黑客攻击的)告警所占的比例却非常小。因此,为了减轻运维人员排查告警的压力,提高对安全威胁的发现能力,需要对安全设备产生的告警日志进行进一步的分析,筛选出关键的具有高威胁度的告警。之前的文章对基于多维度关联的告警评估方法进行了阐述,在告警评估过程中存在多种维度可以用来进行关联。本文以此为基础,进一步介绍采用对告警中某些特征相似性进行关联的评估方法。通过关联告警中的特定的特征,找出“独特”性较高的告警。这类告警一般具有很高的威胁度,需要管理员进行进一步的排查。
二、告警特征提取之惑
所谓“独特”的告警,就是具有某些特殊的特征的告警。因此为了从海量告警中筛选出真正具有高威胁度的告警,运维人员基于告警的特征制定了一系列的筛选策略,例如重点关注高中风险等级的告警、特定防护规则的告警、敏感业务系统的告警、恶意源IP触发的告警等。但是在真实的运维环境中,以上的筛选策略取得的效果都很有限。究其原因,主要是因为以上的筛选策略所参考的特征并不能有效描述告警的威胁度。在实际的运维场景中,运维人员在告警排查处置的过程中最关注的部分就是告警的payload。攻击行为信息包含在告警的payload中。因此为了筛选出具有高威胁度的告警,需要重点考虑payload中包含的特征信息。
告警的payload中包含着攻击者所使用的攻击手法,使用的攻击工具等特征,例如文件路径、IP、域名、URL、操作系统命令、脚本函数、SQL语句、系统表名称等。在实际的网络环境中,由于业务种类,通信协议等不同,告警的payload结构也千变万化。因此告警的payload是非结构化的文本数据。在现有的工作中,自然语言处理(NLP)技术为非结构化文本数据提供了多种处理方法。通过分词,Doc2vec等技术,可以将payload转化为向量化表示。
在实践中,以上方法在处理告警的payload数据的过程中往往会失效,所得到的向量化表示仍然无法有效的表征告警的特征。其原因在于,自然语言处理技术无法真正“理解”攻击者的攻击意图和所采用的攻击技术。也就是说,基于NLP方法得到的告警的向量化表示更多的利用了原始payload的统计特征。这些统计特征不能有效的描述告警中所包含的攻击技术。因此,在提取特征的过程中要引入专家知识,使得特征提取算法能够真正“理解”告警。
三、“人工”提取特征
在告警特征提取的过程中需要引入大量的安全专家知识,才能够有效提取出payload的特征。而引入专家知识需要由安全专家提供特征提取的正则式,正所谓人工智能还得人工来做。也就是说,特征提取过程相当于专家知识的引入过程。这一步对后续的告警评估效果影响巨大。专家知识引入的越多,准确度越高,后续告警评估的效果越好。
四、找出“独特”的告警
在真实的企业网络环境中,大部分的安全设备告警都是低危告警,真正有威胁的告警所占的比例非常小。低危告警往往是由扫描探测等行为产生。扫描探测一般会采用自动化工具来完成,因此这类工具对不同的主机进行扫描探测过程中所产生的告警往往具有相似的payload特征。而对于真正的攻击而言,攻击者为了攻破某一特定的主机,往往会采用一些比较独特的攻击技术。这样这类攻击所产生的告警,其payload的特征也会比较独特。因此根据告警payload特征的独特性可以对告警进行评估。告警特征越独特,其威胁度也就越高。
基于以上思路,可以基于特征相似度来对告警进行评估。其总体流程如图 1所示。
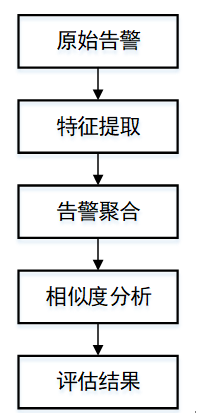
图 1. 告警评估流程
特征提取:如前所述,采用正则式匹配的方法提取每一条告警的payload特征,提取以后的特征经过编码,得到特征向量。
告警聚合:将告警按照源ip,目的ip,目的端口进行聚合,得到告警序列。每个序列中的告警代表着从一个源ip到一个目标ip攻击者所采取的攻击行为。这里可以认为攻击行为由一系列的特征向量所描述。
相似度分析:对聚合以后的每个告警序列之间进行相似度分析,检测序列之间的相似度的大小。这里需要选择一个测度,对任意两个告警序列进行相似度评估。根据测度找出与其他序列相似度较低的告警序列。这些告警序列中的告警被设定为高危告警。
在上面的第三步中,需要对告警序列的相似度进行评估。而每一个告警序列由一系列的特征向量组成,而且告警序列的长度各不相同,也就是说告警序列中特征向量的数量各不相同。因此需要一种能够比较两个告警序列相似度的方法。一种可行的方法是对于两个告警序列,分别对其中的特征向量进行相似度比较,记录特征向量相似度的值,然后取相似度的统计值,例如最小值,中位数,平均值等,作为告警序列的相似度。
由于图模型能够清晰地表征实体之间关联和相似的关系,因此在具体的告警评估的过程中,可以采用图模型来辅助告警序列相似度的评估。图模型由顶点和边构成。在本问题中,可以将告警序列设定为顶点,然后根据序列的相似度来构建边。选定一个相似度的阈值,如果用上面的方法计算得到的两个序列之间的相似度大于该阈值,则在这两个序列对应的顶点之间建立一条边。最终所得的图模型如图 2所示。
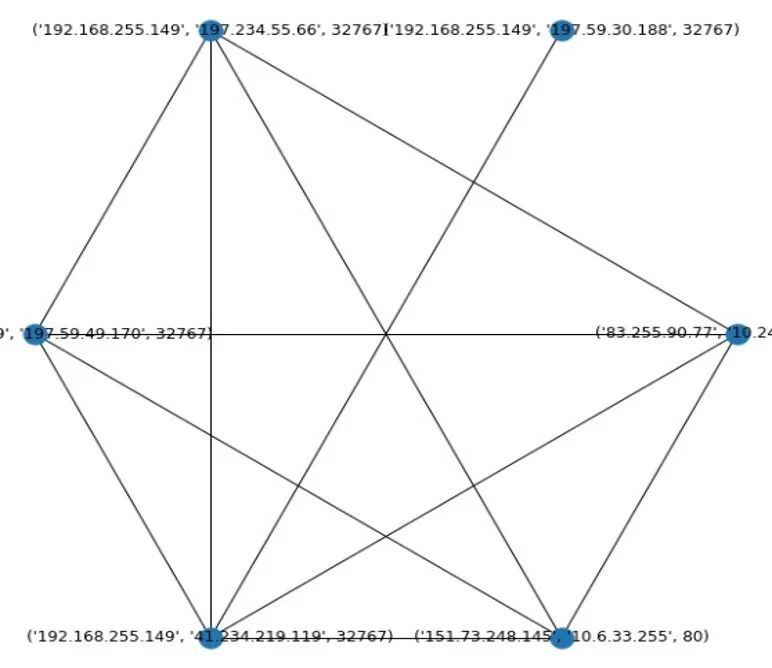
图2
图 2所示的图模型中,每个顶点的度是不相同的,这表示相应的告警序列之间相似性的差异。在实际的企业内网告警数据生成的图中,会有很多孤立的顶点,也就是度为0的顶点。这些顶点对应的告警序列与其他的序列的相似度非常低,因此可以认为这些序列中包含的告警具有更高的威胁度。另外,度比较低的顶点,其对应的告警序列中的告警同样具有较高的威胁度。通过以上方法,即可以筛选出具有较高威胁度的告警。
采用以上的方法对某次公司内部攻防演练中安全设备所产生的共2300万条告警进行评估。所得到的评估结果的top10中真正的高危告警有九条,如所示。
序号 | 人工研判结果 |
1 | RCE利用成功 |
2 | 试探,但不知道什么工具 |
3 | MetaSploit攻击包 |
4 | 手动渗透RCE利用,尝试反弹shell,漏洞利用成功 |
5 | 手动渗透DVWA靶机,尝试上传mimikatz |
6 | 手动渗透RCE利用,换用nc进行反弹 |
7 | RCE利用,尝试反弹shell,但没有成功。 |
8 | 手工渗透,不成功 |
9 | 扫描器,但是漏洞存在 |
10 | 抓鸡 |
五、总结
基于相似度的告警评估方法给安全设备告警的筛选问题提供了一种新的思路。从实际的企业内网环境测试结果来看,该方法可以有效的找出高危的告警。该方法比现有的方法效果好,一个主要原因是在基于正则式提取告警payload特征的过程中引入了大量的专家知识,使得后面建立的模型可以对告警有一定的“理解”。但是引入专家知识是一把双刃剑。如果专家知识不够全面或者不够准确,该方法的评估准确率也会降低。因此,该方法输出的高危告警需要经过安全专家进一步的研判,根据研判的结果进一步调整优化特征提取正则式,提高特征提取的准确度,进而提高评估算法的性能。也就是说,该方法需要一个持续运维的过程。随着专家知识不断地引入与完善,方法的评估效果会不断得到提升。
内容编辑:天枢实验室 吴子建 责任编辑: 王星凯
声明:本文来自绿盟科技研究通讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
