好久没写公众号了,收集整理了当前学术界与工业界的一些漏洞自动修复技术,对此作个简单分类与记录,谈谈原理,也聊聊个人看法。
1、基于依赖组件版本的修复方法
现在有很多包管理器,比如npm、maven,在里面指定下第三方组件版本号即可。所以如果想自动修复开源组件的历史漏洞,通过爬虫监控一些安全公告站点,去收集历史漏洞相关的版本信息,然后就可以直接生成安全版本号,然后Pull Request去合并即可。
去年Github收购Dependabot后,就是专门干了这件事。
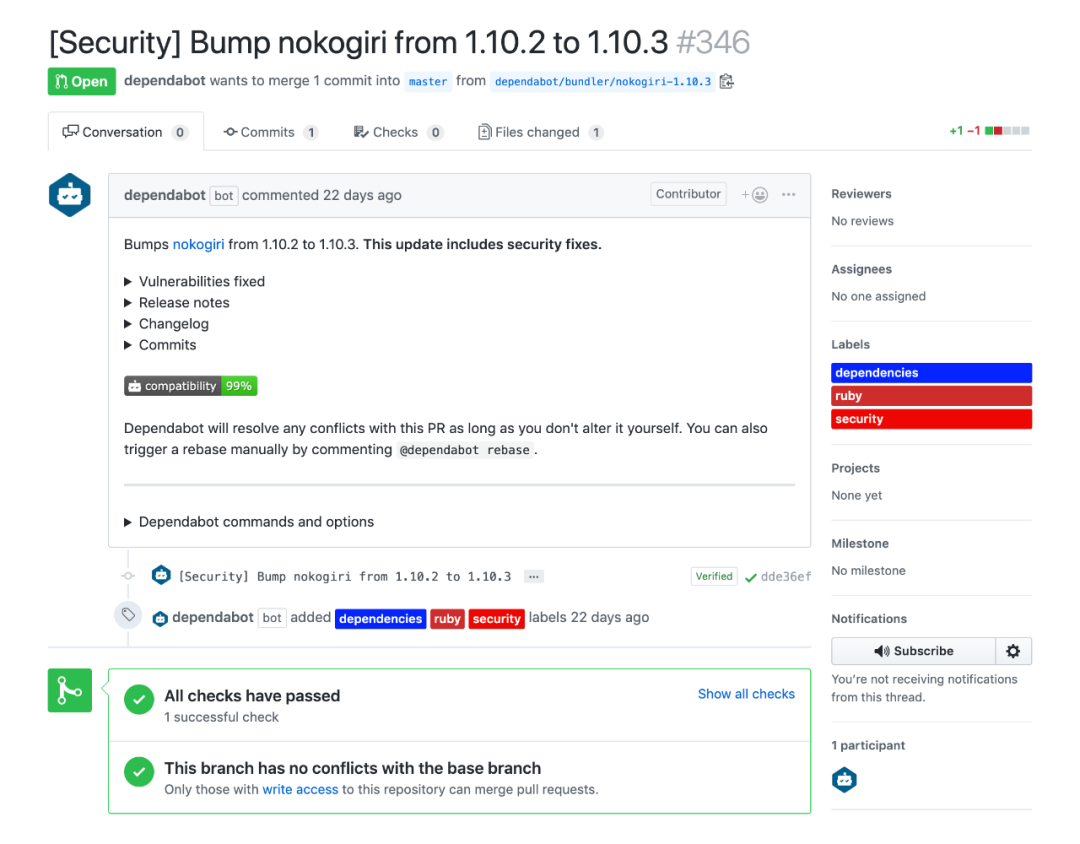
这种自动修复方式目前我们也已经应用了,准确度理论上也可以做到100%。除了用在日常检测与修复漏洞外,用于安全应急也是个不错的选择。
漏洞信息的收集也是个长期积累的过程,还有那种包依赖另一包的死循环问题,也是项令人头疼的问题,目前可能没有特别好的解决方案。
2、基于程序移植的修复方式
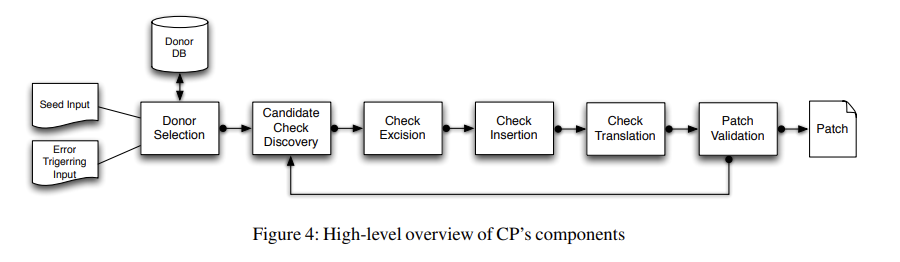
2015年麻省理工学院发布了一款叫CodePhage的漏洞自动修复系统(研究论文:https://people.csail.mit.edu/stelios/papers/codephage_pldi15.pdf),它不需要程序源码,其输入样本是:一个可造成目标程序(Recipient,接收者)崩溃,一个不会,然后从程序代码仓库中去搜索能够同时满足两个样本情况的程序(Donor,贡献者)。将两个样本的执行路径进行对比以定位错误位置(Candidate Check Discovery),提取Donor对输入数据的处理逻辑,以生成对应的补丁代码(Check Excision),然后插入错误位置进行修复(Check Insertion),再收集上下文信息对补丁代码进行适配转换(Check Translation),最后再验证补丁是否消除(Patch Validation)。
下面是CodePhage的实际案例测试结果:
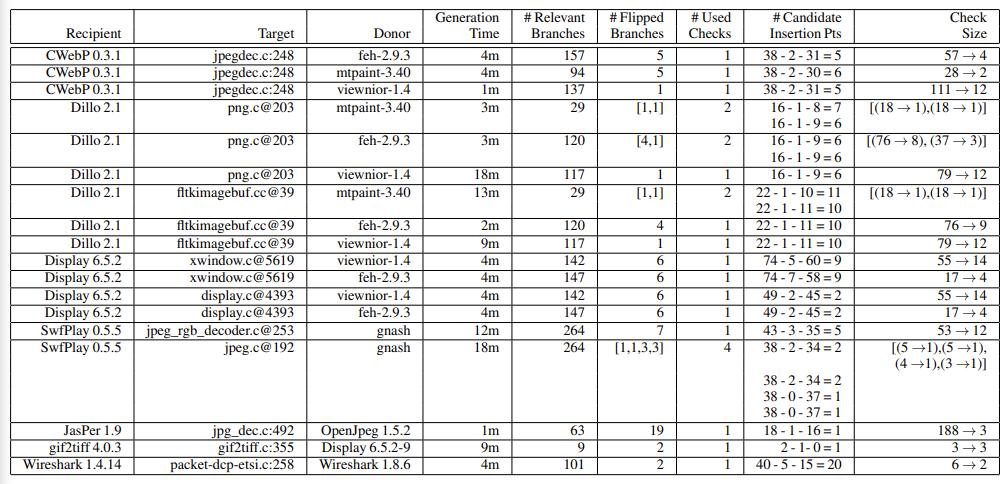
整个系统都是假设修复代码可以在其它程序中找到,这条其实很难满足的。几年过去了,这种修复方式的影响非常小,也证明了这一点。如果是同一帮人写的代码,那么就可能出现相似的漏洞,行业对这种寻找相似漏洞的分析方式,称为变体分析(Variant Analysis)。所以,这种检测方式倒不如用来挖掘相似漏洞,而不是寻找修复代码。
3、基于AST与模板的修复方式
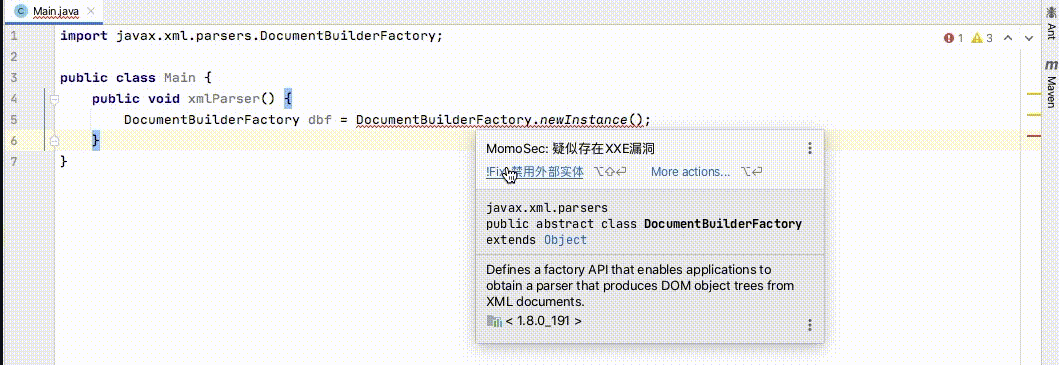
今年陌陌发布一个IDEA插件用于检测Java代码漏洞并提供自动修复代码生成的功能。它利用IDEA的Inspection机制去检测代码,提供“一键修复”功能,这种方式对开发者非常友好。
检测原理也比较简单,就是利用IDEA SDK提供的接口从语法上去检测表达式,判断程序使用的是哪个XML解析类:
publicvoidvisitMethodCallExpression(PsiMethodCallExpression expression) {if (MoExpressionUtils.hasFullQualifiedName(expression,"javax.xml.parsers.DocumentBuilderFactory","newInstance")) {commonExpressionCheck(expression,"setFeature", XmlFactory.DOCUMENT_BUILDER_FACTORY,false);}elseif (MoExpressionUtils.hasFullQualifiedName(expression,"javax.xml.parsers.SAXParserFactory","newInstance")) {commonExpressionCheck(expression,"setFeature", XmlFactory.SAX_PARSER_FACTORY,false);}elseif (MoExpressionUtils.hasFullQualifiedName(expression,"javax.xml.transform.sax.SAXTransformerFactory","newInstance")) {commonExpressionCheck(expression,"setAttribute", XmlFactory.SAX_TRANSFORMER_FACTORY,true);}elseif (MoExpressionUtils.hasFullQualifiedName(expression,"org.xml.sax.helpers.XMLReaderFactory","createXMLReader")) {commonExpressionCheck(expression,"setFeature", XmlFactory.XML_READER_FACTORY,false);}elseif (MoExpressionUtils.hasFullQualifiedName(expression,"javax.xml.validation.SchemaFactory","newInstance")) {commonExpressionCheck(expression,"setProperty", XmlFactory.SCHEMA_FACTORY,false);}elseif (MoExpressionUtils.hasFullQualifiedName(expression,"javax.xml.stream.XMLInputFactory","newFactory")) {commonExpressionCheck(expression,"setProperty", XmlFactory.XML_INPUT_FACTORY,false);}elseif (MoExpressionUtils.hasFullQualifiedName(expression,"javax.xml.transform.TransformerFactory","newInstance")) {commonExpressionCheck(expression,"setAttribute", XmlFactory.TRANSFORMER_FACTORY,true);} else if (MoExpressionUtils.hasFullQualifiedName(expression, "javax.xml.validation.Schema", "newValidator")) {commonExpressionCheck(expression,"setProperty", XmlFactory.VALIDATOR_OF_SCHEMA,false);}}
然后根据不同的XML解析类的修复模板生成代码:
// 生成待插入的语句内容List<String> blockTextes =new ArrayList<>();if (xmlFactory.equals(XmlFactory.DOCUMENT_BUILDER_FACTORY) ||xmlFactory.equals(XmlFactory.SAX_PARSER_FACTORY) ||xmlFactory.equals(XmlFactory.SAX_BUILDER) ||xmlFactory.equals(XmlFactory.SAX_READER) ||xmlFactory.equals(XmlFactory.XML_READER_FACTORY)) {blockTextes.add(varName +".setFeature(\"http://apache.org/xml/features/disallow-doctype-decl\", true);");}elseif (xmlFactory.equals(XmlFactory.SAX_TRANSFORMER_FACTORY) ||xmlFactory.equals(XmlFactory.TRANSFORMER_FACTORY)) {blockTextes.add(varName+".setAttribute(XMLConstants.ACCESS_EXTERNAL_DTD, \"\");");blockTextes.add(varName+".setAttribute(XMLConstants.ACCESS_EXTERNAL_STYLESHEET, \"\");");}elseif (xmlFactory.equals(XmlFactory.SCHEMA_FACTORY) ||xmlFactory.equals(XmlFactory.XML_INPUT_FACTORY) ||xmlFactory.equals(XmlFactory.VALIDATOR_OF_SCHEMA)) {blockTextes.add(varName+".setProperty(XMLConstants.ACCESS_EXTERNAL_DTD, \"\");");blockTextes.add(varName+".setProperty(XMLConstants.ACCESS_EXTERNAL_STYLESHEET, \"\");");}
这是开发过程中的检测与修复方式,还有开发完成后的检测与修复方式,在实际商业产品中,我只在RIPS中见过。
RIPS在检测代码发现漏洞后,会将source与sink存入数据库,然后对漏洞类型进行比较细化的分类,再根据分类寻找对应的修复代码模板,再将source这些上下文信息代入模块中生成最终的补丁代码。
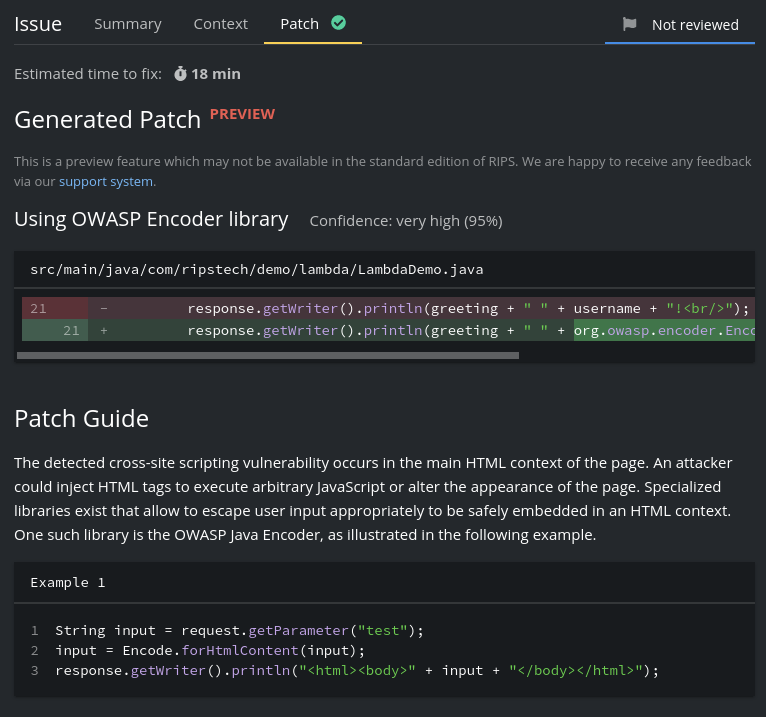
修复代码模板如下:
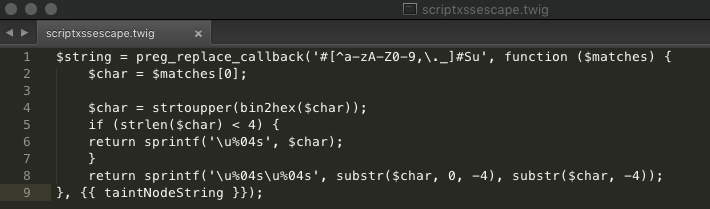
这种结合AST与模板的生成方案,准确率还是比较高的,但是支持的范围相对比较有限,代码逻辑一复杂就无法修复,更多地还是针对简单漏洞模型的修复。
4、基于约束求解与符号执行的修复方式
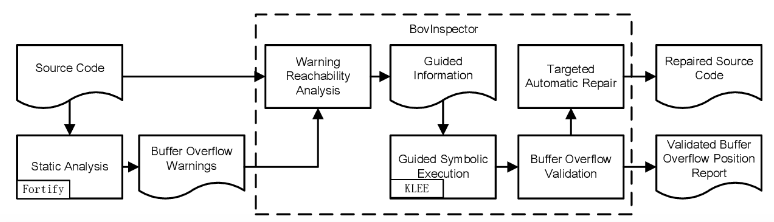
这种方法更多是针对缓冲区溢出一类内存破坏漏洞的修复,对源码和二进制都适用。对于检测到漏洞,先通过分析CFG控制流图、符号执行分析,生成路径可达条件和漏洞触发条件取交后的约束,再进行约束求解,根据求解结果生成相应的修复代码。比如加入对缓冲区边界的条件判断、将不安全的函数替换成安全函数、增大缓冲区内存大小等等。
可参考研究论文“BovInspector: Automatic Inspection and Repair of Buffer Overflow Vulnerabilities”:
https://seg.nju.edu.cn/uploadPublication/copyright/116-553503409.pdf
这种针对特定漏洞类型还是比较适用的,比如溢出,但因为涉及路径分析、符号执行、约束求解,对性能是一种挑战,还有路径爆炸等问题,对于大程序分析是一大挑战,也并不是那么通用。
5、基于AI的修复方式
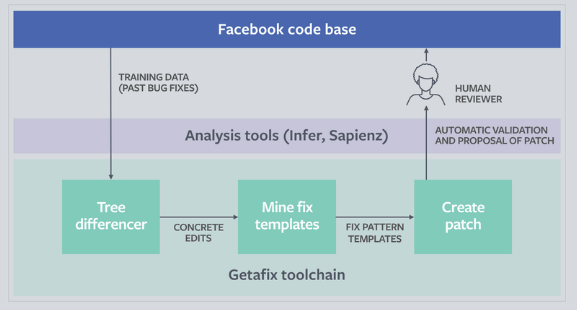
Facebook内部有一款叫Getafix的自动修复Bug的工具,它会利用AI去学习之前提交的代码,利用聚类算法从历史代码中找到一种修复Bug的模式,它能够创建一个包含各种语法树比较数据以及所隐含的修复模式集合,再结合当前上下文生成修复代码。
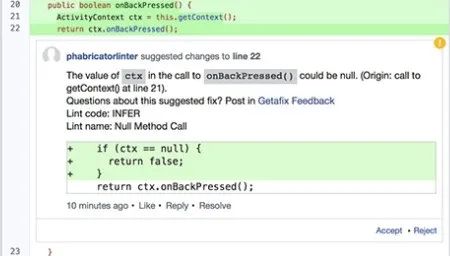
这工具还是偏代码Bug的修复,而非安全漏洞,而且支持类型很少,主要是针对空指针异常
参考资料:https://engineering.fb.com/2018/11/06/developer-tools/getafix-how-facebook-tools-learn-to-fix-bugs-automatically/
总结
纵观各种漏洞自动修复方法,落地到工业界的很少,对于漏洞自动修复技术的探索还有很有很长的路要走。
除上面提的方法外,其实还有一些学术论文有其它方法,但都很难实际利用到生产环境中,我主要整理了一些当前工业界正在用,以及学术界主流的一些思路,汇总归类下当作学习笔记了。
声明:本文来自漏洞战争,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
