原文作者:Ying Dong, Wenbo Guo, Yueqi Chen, Xinyu Xing, Yuqing Zhang, Gang Wang
原文标题:Towards the Detection of Inconsistencies in Public Security Vulnerability Reports原文链接:https://www.usenix.org/system/files/sec19fall_dong_prepub.pdf笔记作者:nerd@SecQuan文章小编:bight@SecQuan
简介
该文为发表于USENIX 2019的Towards the Detection of Inconsistencies in Public Security Vulnerability Reports。CVE、NVD等公共漏洞数据库在促进漏洞披露和减少用户损失等方面取得了巨大成功。这些数据库在积累了大量数据的同时,它们的信息质量和一致性也倍受关注。在本篇论文中,作者提出了一种自动化系统VIEM,用以来检测NVD数据库中的结构化数据与非结构化的漏洞描述及其引用的漏洞报告之间的不一致信息。
方法
作者提出的检测系统VIEM主要包含三大任务:命名实体识别、关系抽取和迁移学习。其中,命名实体识别用于提取漏洞描述等非结构化文本信息中的脆弱软件名、版本号。而关系抽取用于正确关联抽取出的软件名和版本信息。二者使用的都是通用型比较强的算法,故对模型细节不再追朔。最后,考虑到人工标注成本较高,并且不同漏洞类型的报告不一定共享相同的数据分布。因此VIEM采用了迁移学习的策略,利用从一个主要类别中的漏洞报告数据上训练命名实体识别和关系抽取模型。
除VIEM三大任务外,Ground Truth也是不可不说的重要因素。实验用的数据集为5193个CVE的简短摘和1974个被引用的非结构化报告。作者团队首先手动标记易受攻击的软件名称和易受攻击的软件版本,用于评估命名实体识别模型;再手动将易受攻击的软件名称与版本配对,用于评估关系抽取模型。
实验
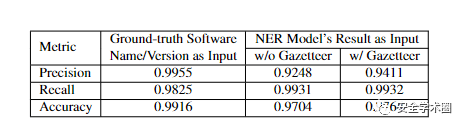
作者首先对模型进行评估,结果如下表所示,命名实体识别模型和关系抽取模型分别取得相当不错的性能指标。
 之后,作者针对迁移学习的效果进行评估,可以看到在进行迁移学习训练后(使用其他类型的漏洞数据对训练好的模型最后一层进行微调训练)准确率、查全率、查准率均有所提高。
之后,作者针对迁移学习的效果进行评估,可以看到在进行迁移学习训练后(使用其他类型的漏洞数据对训练好的模型最后一层进行微调训练)准确率、查全率、查准率均有所提高。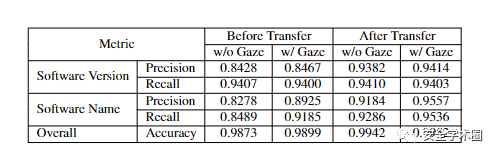 最后,也回到文章最初提到的问题,作者针对NVD条目中的结构化与其他信息源(包括CVE摘要和外部报告)的一致性进行评估。如下表所示,二者之间的软件名称和软件版本信息并不能完全匹配。另一方面,VIEM得出的结果与人工标数据得出的结果相差无几。
最后,也回到文章最初提到的问题,作者针对NVD条目中的结构化与其他信息源(包括CVE摘要和外部报告)的一致性进行评估。如下表所示,二者之间的软件名称和软件版本信息并不能完全匹配。另一方面,VIEM得出的结果与人工标数据得出的结果相差无几。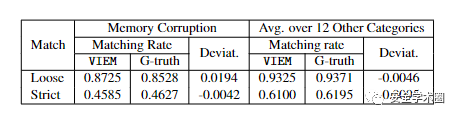 总的来说,这是首次针对公开漏洞信息一致性的大规模调研,其结果表明,易受攻击软件的版本信息不一致问题非常普遍。只有 59.82% 的漏洞报告/CVE摘要与结构化的NVD条目完全匹配。此外,作者也通过案例证实了NVD存在高估或低估易受攻击的软件版本的问题。但是,该文并没有给出一种方法来确定到底是NVD的数据有问题还是漏洞描述和漏洞报告中的信息有问题,或者说如何找到被漏报的软件版本。针对这一问题的扩展,ACM CCS 21的一篇论文(Facilitating Vulnerability Assessment through PoC Migration)给出其思路:结合已有的PoC使用基于模糊测试的方法对其他版本进行攻击以求发现被遗漏的具有相同漏洞的版本。该文将于11月中旬会议召开后公开,届时笔者也会尽快为大家带来分享。
总的来说,这是首次针对公开漏洞信息一致性的大规模调研,其结果表明,易受攻击软件的版本信息不一致问题非常普遍。只有 59.82% 的漏洞报告/CVE摘要与结构化的NVD条目完全匹配。此外,作者也通过案例证实了NVD存在高估或低估易受攻击的软件版本的问题。但是,该文并没有给出一种方法来确定到底是NVD的数据有问题还是漏洞描述和漏洞报告中的信息有问题,或者说如何找到被漏报的软件版本。针对这一问题的扩展,ACM CCS 21的一篇论文(Facilitating Vulnerability Assessment through PoC Migration)给出其思路:结合已有的PoC使用基于模糊测试的方法对其他版本进行攻击以求发现被遗漏的具有相同漏洞的版本。该文将于11月中旬会议召开后公开,届时笔者也会尽快为大家带来分享。

声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
