原文标题:Exploiting Code Knowledge Graph for Bug Localization via Bi-directional Attention
原文作者:Jinglei Zhang, Rui Xie, Wei Ye, Yuhan Zhang, Shikun Zhang 发表会议:ICPC 2020原文链接:https://dl.acm.org/doi/abs/10.1145/3387904.3389281笔记作者:zhanS@SecQuan文章小编:cherry@SecQuan
给定软件项目中缺陷的自然语言描述,缺陷定位可以自动定位相关的源文件。最近,基于深度学习的模型被用于提取代码的语义信息,对缺陷定位有显著的改进。然而,编程语言是一种高度结构化和逻辑化的语言,它包含源文件内部和跨源文件的各种关系。在本文中,作者提出了一个名为KGBugLocator的模型,利用知识图谱来提取代码内部的关系,使用基于关键字监督的双向注意力机制正则化模型,挖掘源代码文件和缺陷报告间的内在关联。 基于深度学习的缺陷定位存在两个问题:
1. 如何表示编程语言以更好地匹配自然语言。
2. 如何更好地提取特征以降低编程语言和自然语言之间的语义鸿沟。
文章所提模型的框架如图1所示,分为四个部分:
代码知识图谱嵌入
预编码
基于关键词监督的双向注意力机制
Bug定位
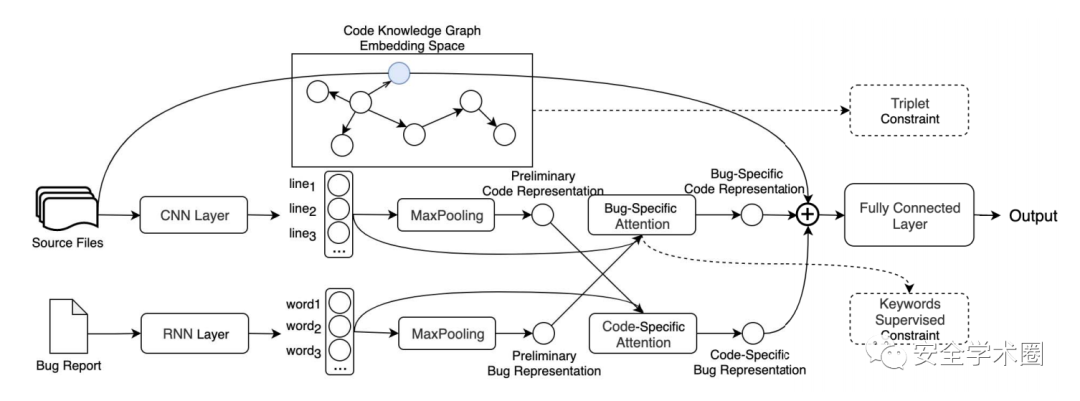
Fig. 1 模型框架
文章所构建的代码知识图谱示例如图2所示。代码知识图谱基于AST构建,节点和边分别对应代码实体和代码实体间关系。代码实体有5种类型:class、property、method、parameter和variable;对应的关系实体也是5类:class间的inheritance关系,class和property、class和method、method和parameter、method和variable之间的has关系,property和class、variable和class之间的instance_of关系,method和class之间的return type关系,method和method间的call关系。文章使用LSTM捕捉Bug报告的语义信息,使用CNN捕捉代码的语义信息,得到预处理的文本和代码表示。然后使用关键字监督帮助注意力机制更好地关注关键信息。具体来说,作者将既在代码中出现,又在报告中出现的token进行标记,将其所在的代码标记为关键代码行,关键代码行的权重高于非关键代码行。
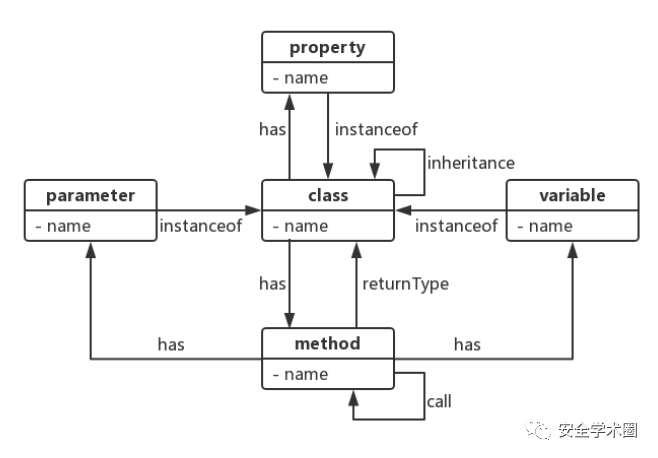
Fig. 2 代码知识图谱
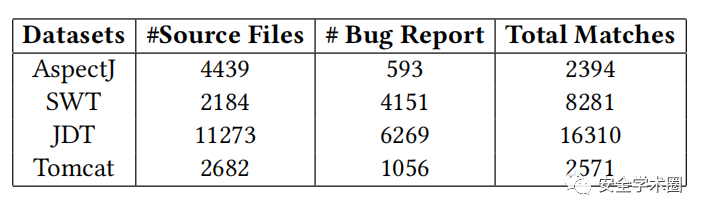
Fig. 3 数据集结构
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系secdr#qq.com

声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
