
深度伪造技术的滥用对社会造成了严重威胁,如何准确鲁棒地检测深度伪造视频依然是当前学界和业界急需解决的问题。充分发掘并表征跨帧面部局部区域上的不一致性成为关键。为此,本文提出了基于空时域剔除视觉变形器(spatiotemporal dropout transformer, STDT)的伪造人脸视频检测方法,引入空时剔除(spatiotemporal dropout,STD)操作充分捕捉视频中局部面部区域的帧间关联,同时实现数据增广以增强表征与泛化能力,从而提升深伪视频检测性能。
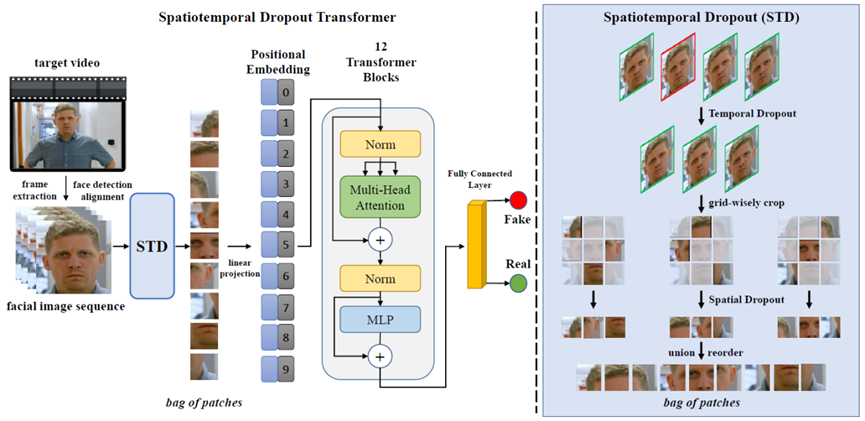
图1 检测方法整体框架
方法的整体框架如图1所示,从原视频提取的图像帧在经过人脸检测和对齐后,通过STD操作得到目标patch集合,将得到的patch集合作为token输入ViT主干网络中学习表征,经过最后的全连接层分类得到输入视频的预测结果。设计的STD操作如图1右侧所示,其目的是对于同一输入视频生成不同包含跨帧局部面部区域一致性信息的patch集合,包含时域和空域两个维度的随机剔除采样,前者对视频帧进行随机剔除采样,后者对保留的视频帧剪裁后的patch进行随机剔除采样,得到最终目标patch集合。设计的STD操作能够充分挖掘视频跨帧局部面部区域的一致性信息,同时由于剔除的随机性,大大减少了网络计算量,实现了数据增广以进一步提升网络的鲁棒性和泛化能力。方法在Celeb-DF(v2)、DFDC和Faceforensics++三个流行的基准集上进行了充分实验,均超过了当前25种当前最好方法的检测性能。方法同时也具有优异的跨数据集泛化性能。另外,多种扰动噪声环境下实验与特征可视化实验也证明该方法具有优异的鲁棒性和表征能力。
论文信息
相关论文已经被ACM MM 2022录用为oral,作者为中国科学院信息工程研究所的张岱墀,林繁钊,化盈盈,王鹏举,葛仕明,上海大学曾丹。
Daichi Zhang, Fanzhao Lin, Yingying Hua, Pengju Wang, Dan Zeng, Shiming Ge*. Deepfake Video Detection with Spatiotemporal Dropout Transformer. Accepted by ACM International Conference on Multimedia (MM), 2022 (Oral).(点击下方阅读原文查看论文全文)
供稿:中科院信工所葛仕明等
信工所主页:http://www.iie.cas.cn/
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
