作者:imbeee、iswin@360观星实验室
1. 简介
机器学习目前已经在安全领域有很多的应用,例如Threat Hunting、攻防对抗、UEBA以及金融反欺诈等方面,本文将以Windows RDP服务为例子,详细阐述机器学习在后门检测、精准的服务版本检测等方面的应用,本文所涉及的相关检测思路和方法已经应用在观星实验室内部的自动化渗透测试平台(Gatling)以及互联网资产发现平台中,当然在年底我们实验室发布的国内首款针对域安全分析的工具—观域中也有很多机器学习的应用,后续的文章我们会详细给大家介绍。
2. 背景
本文中所提到的几个问题其实是来自于我们日常工作中实际面临的问题以及实验室内部的几次讨论。在一次给客户(某部委)做互联网资产发现的时候,我们发现一个奇怪的端口,最后经过验证发现这个是RDP的端口,当时Nmap显示的服务器版本是Windows 2008,但是当我们登录进去之后发现是Windows 2003,这是我们面临的第一个问题:如何提高Windows RDP版本识别的准确率?
然后实验室其它小伙伴习惯性的按了5下shift 突然冒出一个黑框,经分析发现是一个shift后门。当时我们遇到的另一个问题就是:如何检测shift后门?
由于我们的客户数量非常多,互联网侧的资产更是不在少数,一台一台登录去检测显然是不可能的,所以第二个问题就是如何自动化的批量检测互联网的shift后门?
基于上面的三个问题,我们进行了一些研究,发现机器学习在自动化RDP版本和shift后门检测方面有一定的应用场景,能帮助我们解决一些实际问题。
3. 实现思路
针对上面提出的3个问题,我们从实现上做了一些摸索,也大胆的设想了一下,下面就这两个问题进行分别讨论。
1. 当前RDP版本识别存在的问题
我们无法直接从RDP协议中取得系统版本,虽然特定版本的Windows系统默认会使用某个版本的RDP协议,比如Windows 7默认使用RDP 7协议,但是也可以通过安装补丁升级到RDP 8.1或者更高版本。所以通过RDP协议版本推断系统版本也不是很准确。
2. 如何高效自动化的检测RDP后门(不止shift后门)?
自动化检测RDP后门,关键在于触发相关程序,如按5次shift键触发sethc.exe,或者win+u触发放大镜等,这部分操作在RDP协议里都是简单键盘事件,并没有使用特定的报文。而对于不同版本的Windows系统,在登录界面触发辅助程序的按键序列也不一样,所以需要先判断Windows版本,使用对应的按键序列来触发粘滞键等程序,然后截图供后续检测。
经过我们调研发现Github上有个Python实现的RDP客户端项目rdpy,这个项目解决了基础的截图问题,在后面RDP后门的检测中,也遇到一些坑,比如稳定截图问题,这个会在后面具体提。
所以我们的整体解决方案就是使用rdpy来实现截图逻辑,版本识别使用机器学习技术,用原始图片样本固定位置截图进行训练,RDP后门检测则基于版本识别的结果(不同版本服务器shift后门弹框位置不一样)训练样本进行识别,关键信息提取直接用原始图片进行关键位置的文字识别即可。
4. Windows RDP截图
在截图的实现中,为了避免重复造轮子,我们直接使用了上面提到的rdpy库,其支持Classic RDP Protocol、SSL和CredSSP全部三种安全层协议,同时实现了不同图片格式(即RDP远程会话的颜色深度)的处理方法,基本满足我们的需求。
RDP稳定截图的难点在于我们无法从协议上得到“停止”反馈。由于RDP协议是将画面切割后分块传输的,且只传输画面变动的部分,所以在整个会话过程中,我们无法确定在哪张图片之后画面已经绘制完毕。
刚开始我们尝试了一些比较脏的方法,包括rdpy自己的截图脚本rdpy-rdpscreenshot.py里面也用到的一个方法,那就是设定一个时间阈值,从建立RDP链接开始,等待一段时间后截图然后关闭链接。这个方法的缺点很明显,那就是受网络质量影响,导致效率低下。对于链接质量好的目标,可能很短时间就完成了登录界面的传输与绘制,但是却浪费了大量时间在等待截图;而对于链接质量差的目标,可能在时间结束时还没有绘制完成,造成截图失败。
通过尝试,最后我们确定了一个比较合理的截图逻辑:建立链接后,每接收一张图片并绘制后,将当前时间记录为最后绘制时间,并且使用一个独立的线程每隔一定时间检查最后绘制时间与当前时间的时间差,如果时间差超过某个值,则认为当前画面已经稳定,可以进行下一步操作(如截图、发送按键触发后续事件),如果需要触发事件后截图,则使用相同的逻辑判断画面是否稳定,然后再次截图。这样的截图流程符合实际操作逻辑,后续可以通过其他手段判断链接质量,并动态调整等待时间,最终获得比较稳定的截图效果。
5. Windows版本检测
Windows Server的主流版本大致分为这么5个版本,Windows 7、Windows Server 2003、Windows Server 2008 R[1|2]、Windows Server 2012 R2、Windows 10,从我们在shodan的采样数据数据来看,除了Windows 10非常少之外,开3389的基本上就4个主流版本,所以本文将重点以这4个版本为主。
我们先来几张RDP登录界面的图片
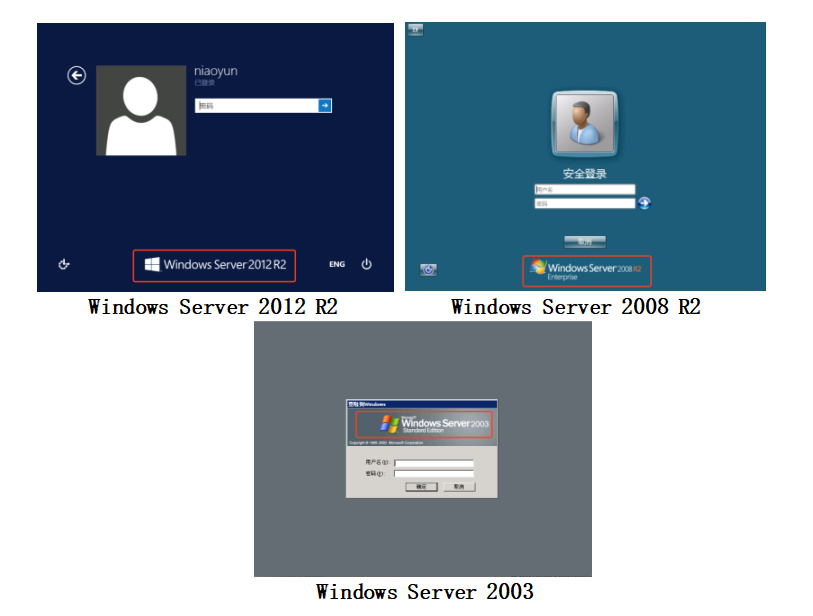
从上面几张图片标红的部分我们大致可以看到RDP的版本标识主要出现的位置在两个地方,所以我们的版本识别主要分为两种,Windows 2003 及以上版本,然后针对这两种类型的关键位置(标红部分)进行图片裁剪进行训练,当然有人可能说了其实不用裁剪直接来训练也行,这种办法不是说不行,只不过在处理效率上有点低,除了标红位置之外的地方主要占了整个图片的80%左右,如果整张图进行训练,在特征提取的时候你的维度就会特别大,而且这这部分基本上不会有变化。
按照关键位置剪切图片后,图片非常小,效果如下

处理完之后其实对于2003来说就是个二分类问题,即是不是2003版本,对于2003以上版本就是个多分类问题,这里主要是区分图片里面的关键元素,一般在实际处理的时候可以不用考虑图片的颜色,即将图片二值化,然后根据图片的Length*Width来作为特征向量的维度,用0和1表示黑白两种颜色,这样就可以将图片转换为可以用于计算的数学上的值,当然如果你直接用ocr去识别图片中的文字,当然也是可以的,不过效率和效果很一般,为了提高效率和识别效果我们采用Scikit-learn中的SVM算法来进行有监督的学习,这样在工程化的时候也比较好嵌入到我们已有的项目中。
整体的识别流程如下:
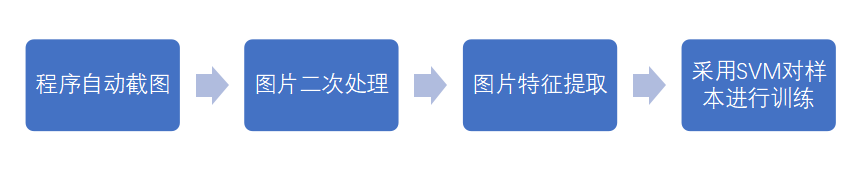
训练样本大家可以从shodan上去提取,然后截图之后手工分类下,按照如下文件夹的形式存放样本图片

由于有监督学习需要给每个样本打上标签,所以这里我们用数值来标识不同的操作系统版本,映射关系如下:

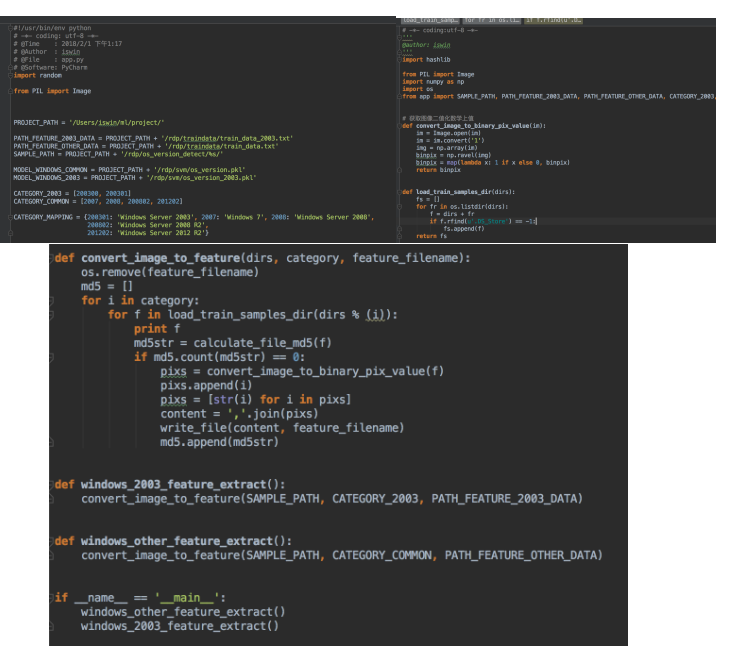
针对2003的系统需要注意下,这里是二分类,需要一些负样本进行训练对应图中的200300和200301,特征提取关键代码如下:
最后会在traindata里面产生两个文件
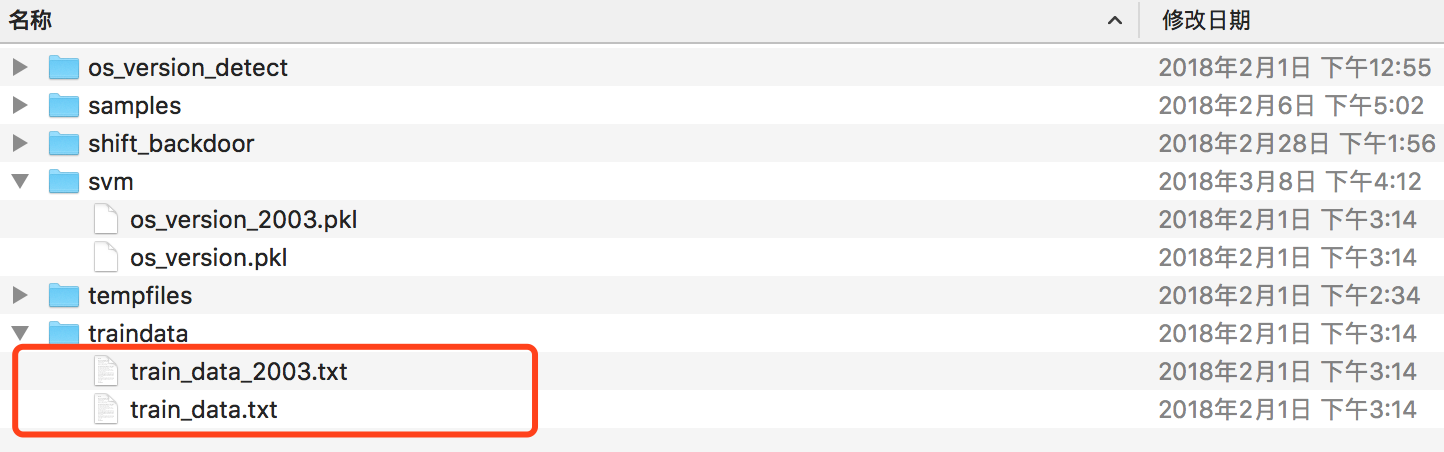
每条数据最后一列表示对应的标签

训练这块直接用Scikit-Learn 中的svm算法进行训练即可,关于SVM具体的算法原理这里不做介绍,网上有更专业的paper来进行介绍。
训练部分的代码如下

我们将测试集分为两组,80%作为训练,20%作为测试,目前就版本检测来说,准确接近100%,看以下4个版本例子

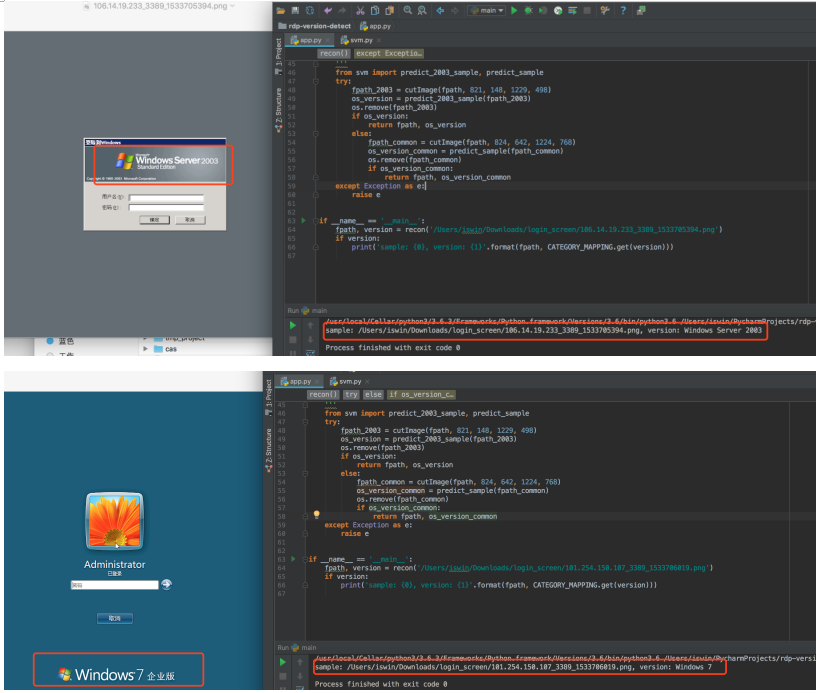
一条龙效果:
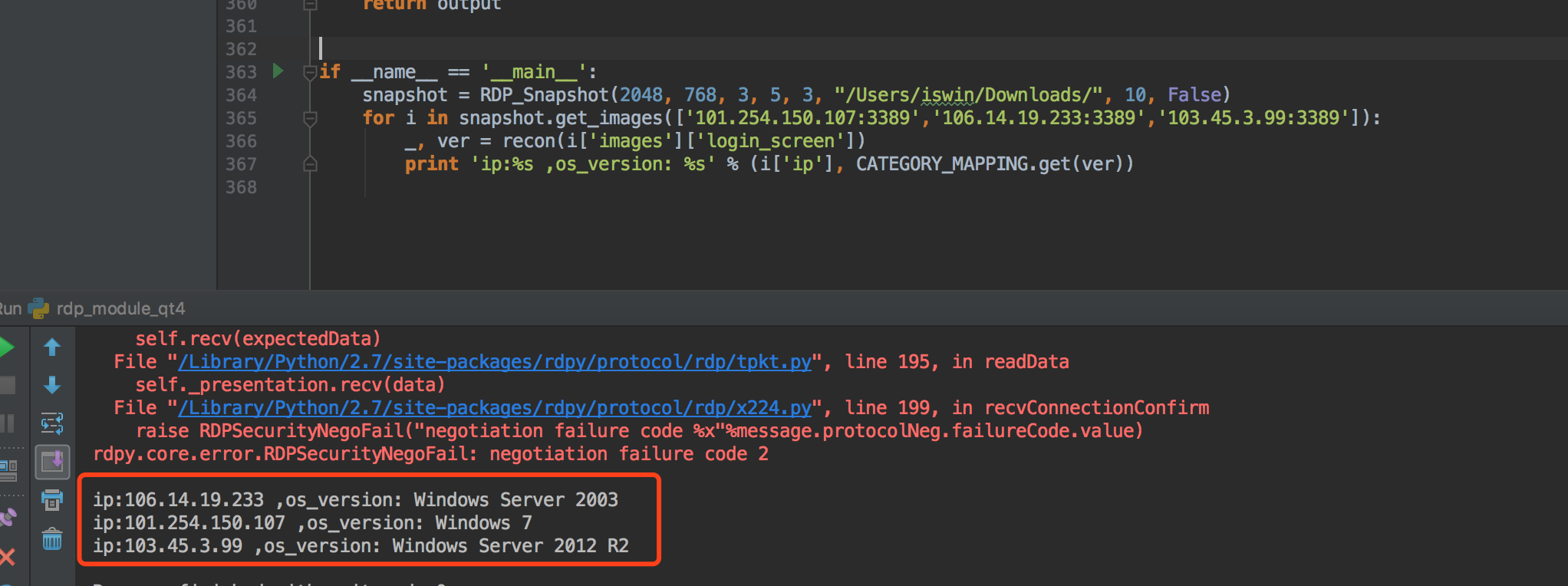
1. RDP后门检测
上面简单介绍了下RDP版本识别的一些内容,那么接下来将介绍下本文的重点内容,RDP版本识别实现的方式也比较多,而且效果比较好,利用的分析模型也都是大家平时都了解的。
关于RDP后门的识别,本文主要以shift后门为例,其它的放大镜之类的和shift原理类似.
我们从shodan上面的采样的结果来看,shift后门主要的几种形式,如下图
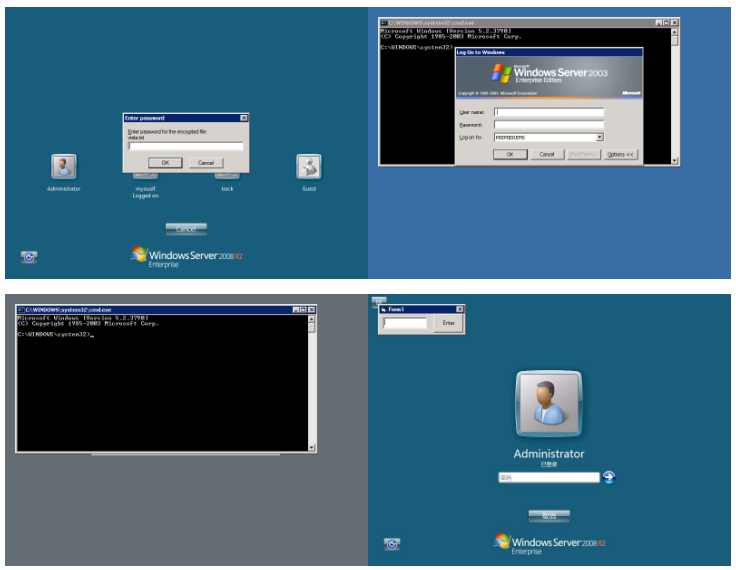
所以这里面面临的问题就是shift后门位置不固定,大小不一样,颜色不一样,不同版本的弹框也不一样。所以用图像识别、固定位置截图识别,或者说将图片二值化后看黑白区域所占的比例(cmd框黑色占比比较大),包括利用之前的SVM进行标记训练,都是不行的,识别效果太差了,例如shift框位置稍微变动下、大小稍微变动下,识别准确率就非常低。
在我们经过一段时间的调研之后,发现目标检测算法(Object Detection)比较适用于我们当前的项目,目标识别的算法主要有R-CNN、Faster-R-CNN、YOLO等,这个算法目前以被tensorflow、keras、Caffe等框架实现,关于目标检测算法的原理之类的,建议大家先从卷积神经网络(CNN)去看相关paper,本文也只是目标检测算法在安全上的一些应用的探索。
综合几个方面的因素,我们选择了YOLO-V2来进行样本训练和识别(目前最新版本是YOLO-V3,但是测试的时候老是有GPU内存不足的问题,调整了训练的batch_size还是不行,所以就回退到V2),YOLO主要是做目标识别以及实时图像目标识别,由于YOLO 是属于深度学习的范畴,最好你要有GPU的计算环境,否则用CPU来训练的时候会非常慢。
YOLO的使用大家可以参考作者的博客https://pjreddie.com/darknet/ ,这里有相关的原理Paper,当然还有一些训练好的模型可以直接用,安装过程就不详细解释了,包括GPU环境的编译,作者博客上都有详细的说明,YOLO是一个目标检测框架,作者提供了两种类型(PASCAL VOC、COCO)的数据集来进行模型的训练,我们可以根据这两种类型来定制自己的数据集来训练自己的模型,本文采用PASCAL VOC2007类型来指定自己的数据集,PASCAL VOC2007数据集的目录结构如下:

JPEGImages:包含了PASCAL VOC所提供的所有的图片信息。
Annotations:存放对应图片的xml格式的标签文件。
ImageSets:主要是Main目录下txt文件,存储训练样本的文件名(不带后缀)。
Labels:标记样本的类型等信息。
其它文件夹在YOLO中没有使用,感兴趣的自己去查下。
首先我们将shift后门的样本放在JPEGImages目录,按照如下编号进行保存
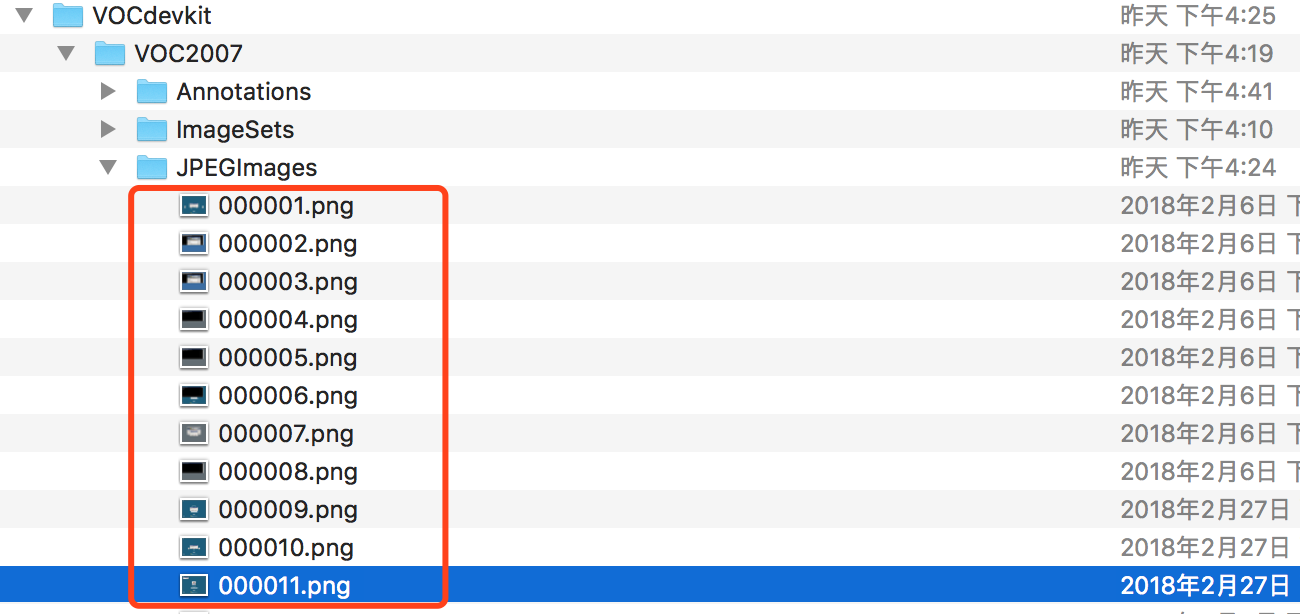
图片标记使用https://github.com/tzutalin/labelImg ,然后对每张图片进行标记,我们目前只有两个分类:normal_shift、shift_backdoor,例如
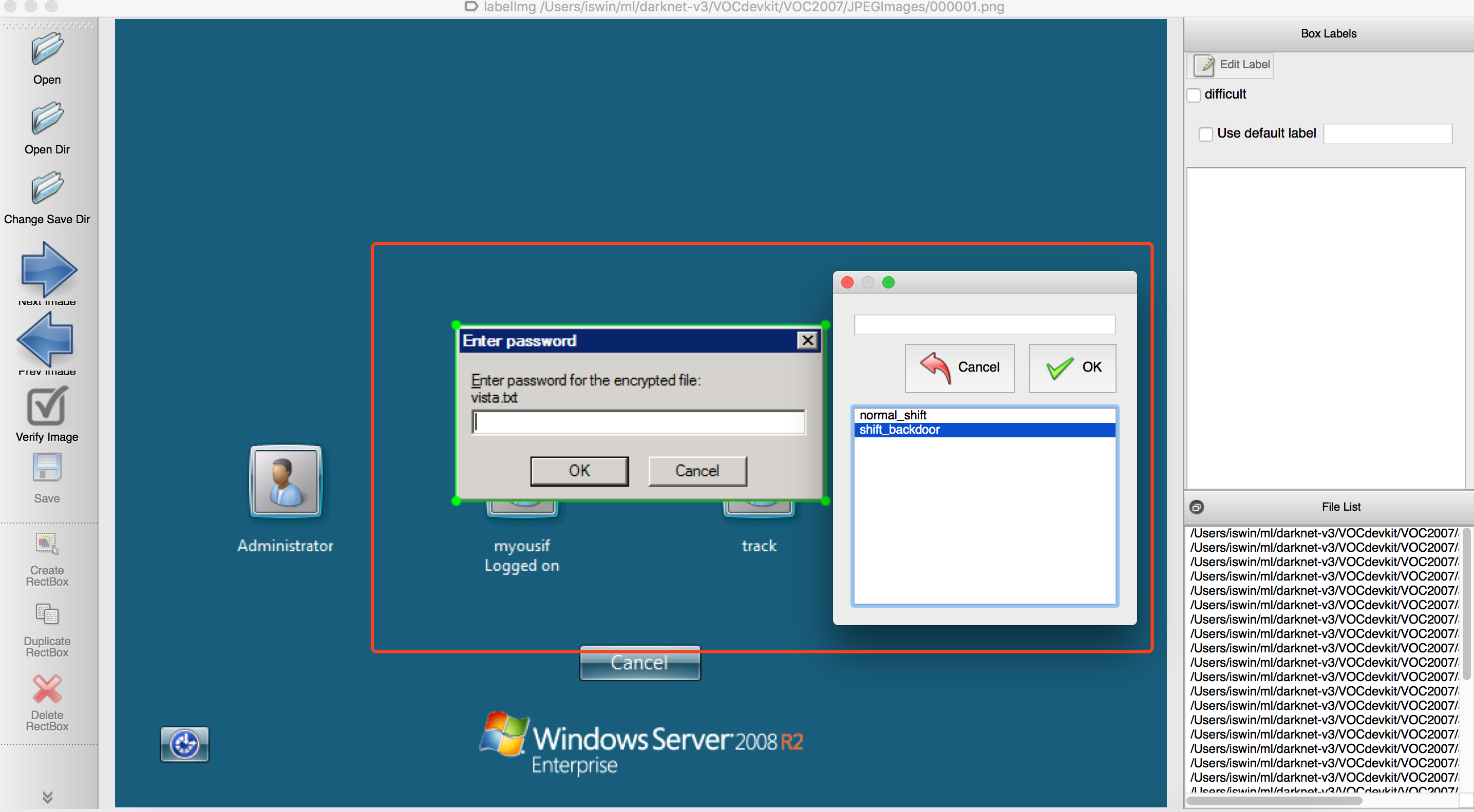
按照类似的方法将所有样本进行标记,然后用voc_label.py 将标记好的xml信息转换成相应格式的文件即可,这里这个工具在标注的xml文件中可能会出现width和height为0的情况,需要在标注后统一修正下图片的大小。
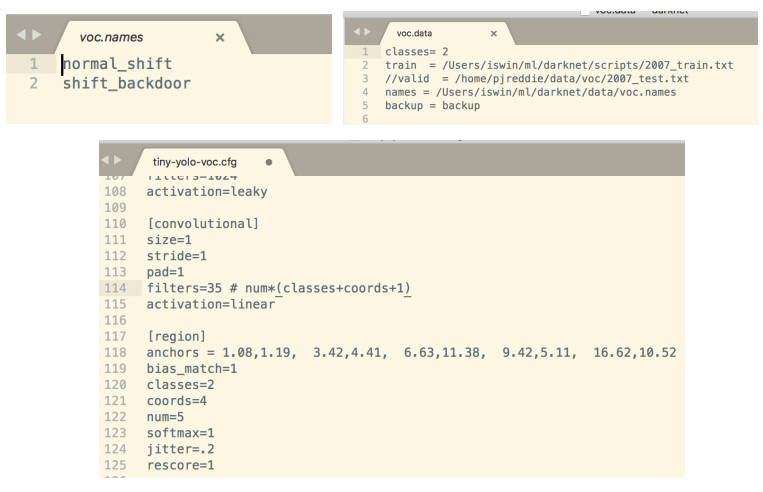
修改YOLO的训练的参数,这里主要涉及YOLO的三个文件cfg/voc.data、cfg/tiny-yolo-voc.cfg、data/voc.names,具体的参数信息大家可以根据自己的类别来设置,这里以两个类别为例子。
所有数据都准备好之后,我们就可以开始进行训练,先看看装备
注:训练的初始权重可以在作者博客进行下载。
./darknet detector train cfg/voc.data cfg/tiny-yolo-voc.cfg darknet19_448.conv.23 -gpus 0,1,2,3
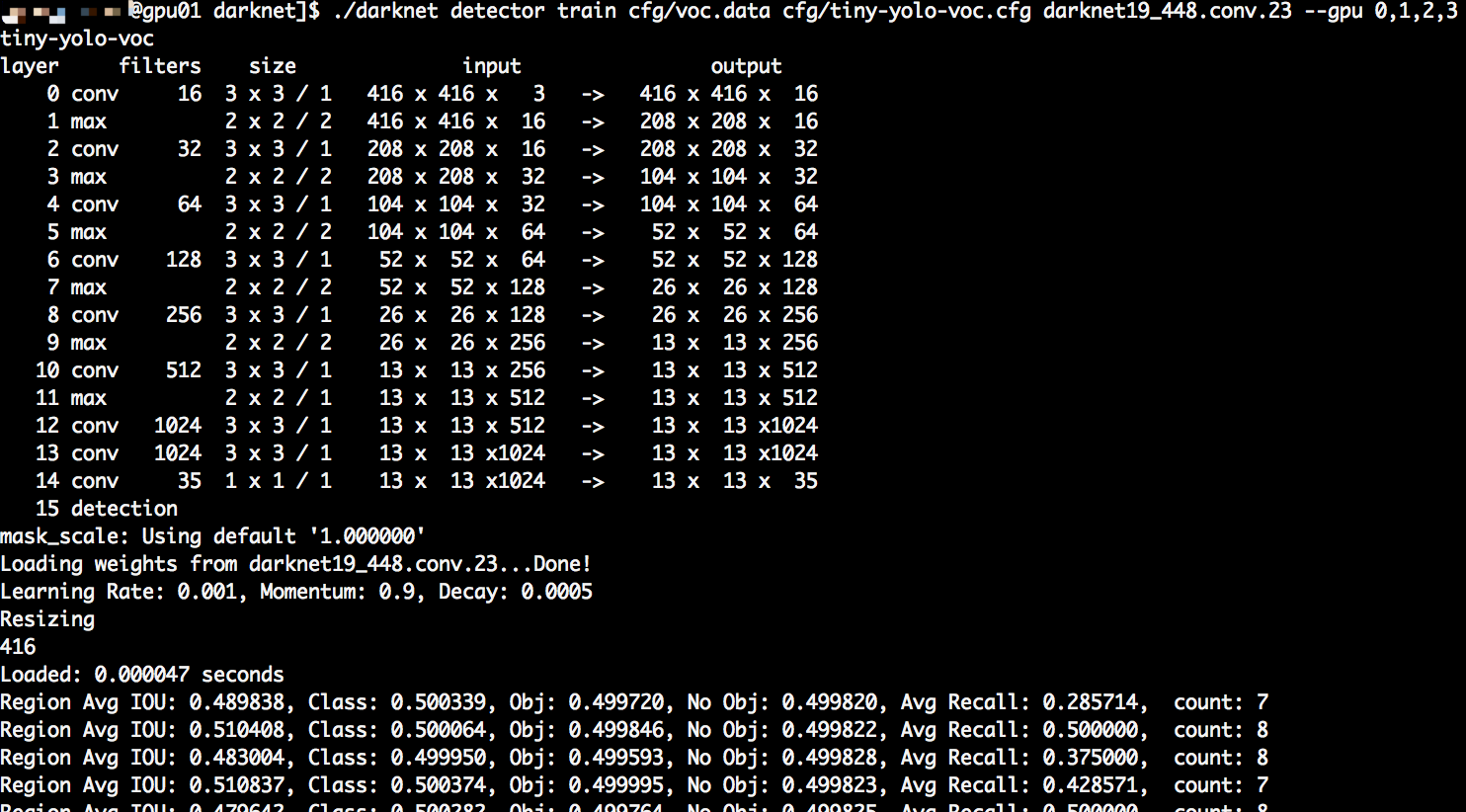
大约几个小时之后(CPU的话大概1周左右,看性能),经过40000多次迭代直至收敛,在backup目录下面会生成最终的权重文件:tiny-yolo-voc_final.weights,至此整个过程的标注和训练工作已经完成。
识别的话我们项目用的是python,这里直接用 pip install darknetpy ,然后将最终的权重文件以及相关的配置文件按照要求正常调用就行了。
我们看看最终效果:
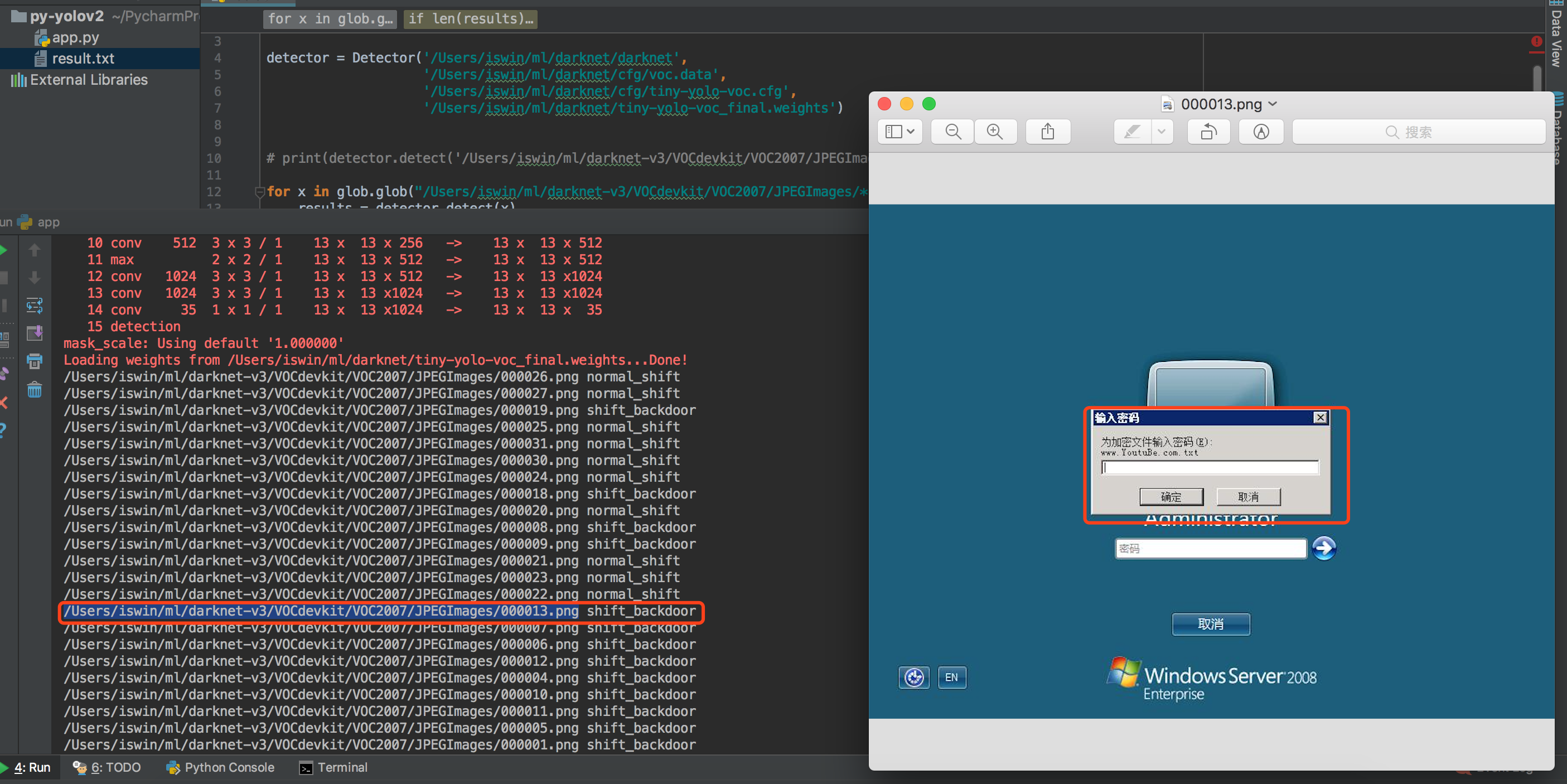
我们用于训练的图片大小是800*600,我们这里用2048*768的图片来进行识别看看准确率如何。

当然识别率这块还有很多可以提高的地方,比如训练的样本集、图片的进一步处理等。
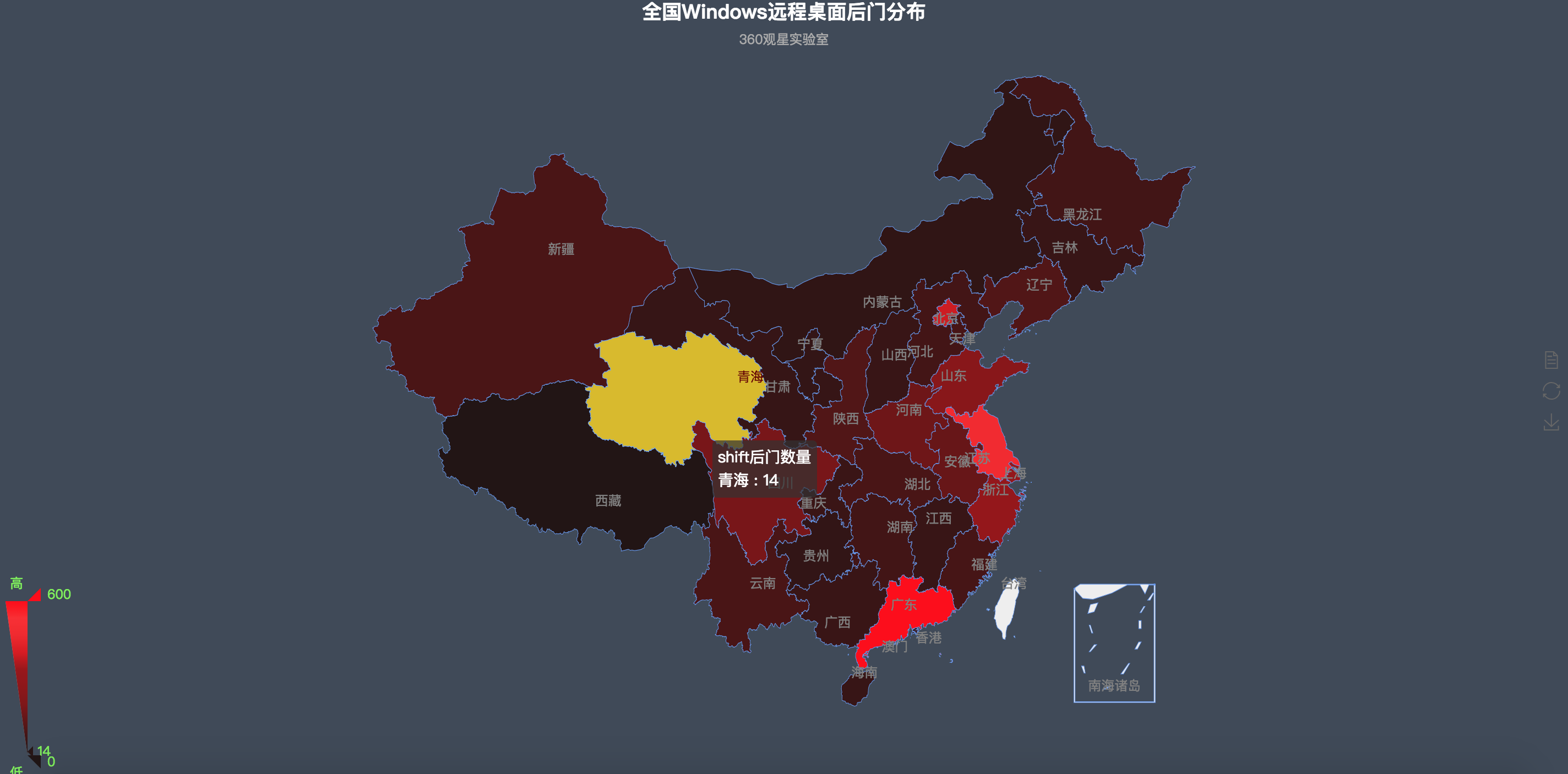
1. RDP版本、后门全国分布
我们对中国互联网侧暴露的130w(数据来源:https://opendata.rapid7.com/sonar.tcp/ )开放3389端口的IP进行了分析,确定Windows开放远程桌面的服务器大约为31W左右,通过对这31W的数据进行了分析研究,得出以下结论:

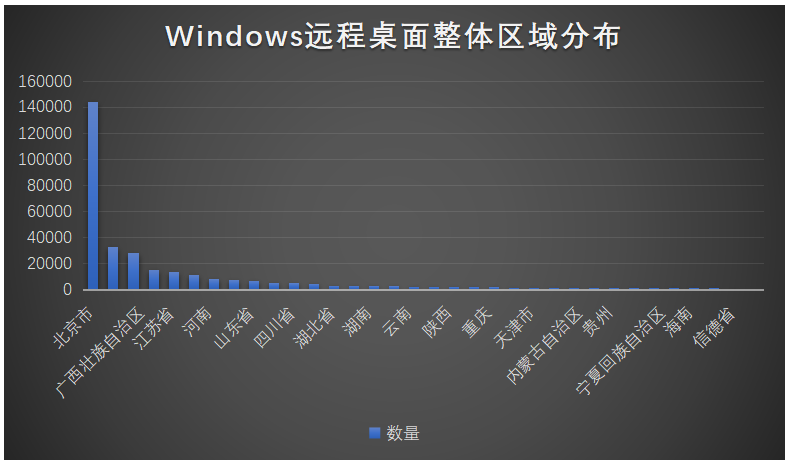
通过对31W开放的Windows远程桌面服务器进行分析识别,发现了4500+ Shift后门,具体的shift后门分布如下:
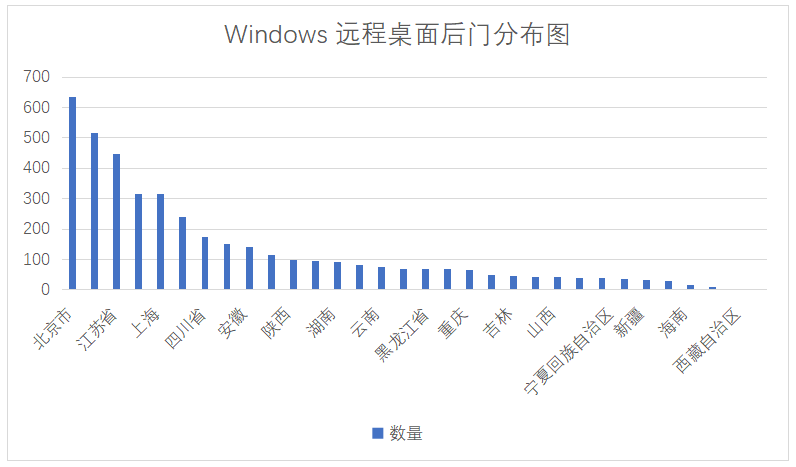
其中广东、江苏、北京、浙江、上海、山东是重灾区,具体数量如下:
1. 总结
Windows RDP 的后门变种是非常多的,本文提供的检测方式只是最基础的一种,这些后门也只是冰山一角。
对于那些非常隐蔽的后门的检测我们还在探索之中,作为一个服务于广大客户的厂商来说,大规模、自动化的安全检测还有很长一段路需要走,接下来我们也会结合新的技术去探索更具挑战的威胁检测。
当然如果你愿意同我们一起进行安全技术的研究和探索,请发送简历到 lab@360.net,我们期望你的加入。
2. 参考链接
1. https://pjreddie.com/darknet/yolo/
2. https://github.com/citronneur/rdpy
3. https://github.com/tzutalin/labelImg
4. https://github.com/rbgirshick/py-faster-rcnn
5. https://opendata.rapid7.com/sonar.tcp/
声明:本文来自360观星实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
