
本文整理自 Streamlio 核心创始人翟佳在 QCon2018 北京站的演讲,在本次演讲中,翟佳介绍了 Apache Pulsar 的架构、特性和其生态系统的组成,并展示了 Apache Pulsar 在消息、计算和存储三个方面进行的协调、抽象和统一。
Messaging:Pulsar 对 pub/sub 和 queue 两种模式提供统一的支持,同时保证了一致性,高性能和易扩展性。
Computing:Pulsar 内部的 Pulsar-Functions 提供了 Stream-native 的轻量级计算框架,保证了数据的即时流式处理。
Storage:Pulsar 借助 Apache BookKeeper 提供了以 segment 为中心的存储架构,保证了存储的性能,持久性和弹性。
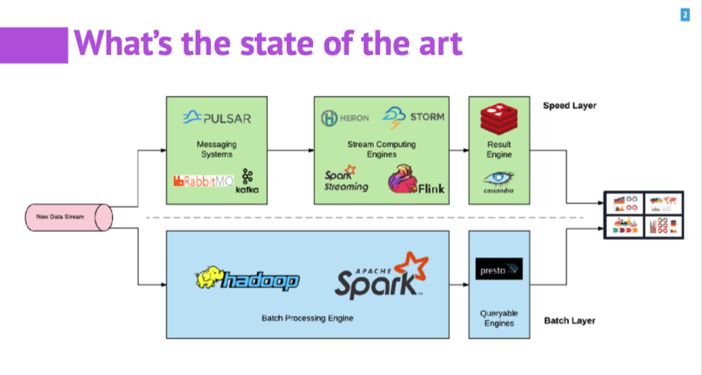
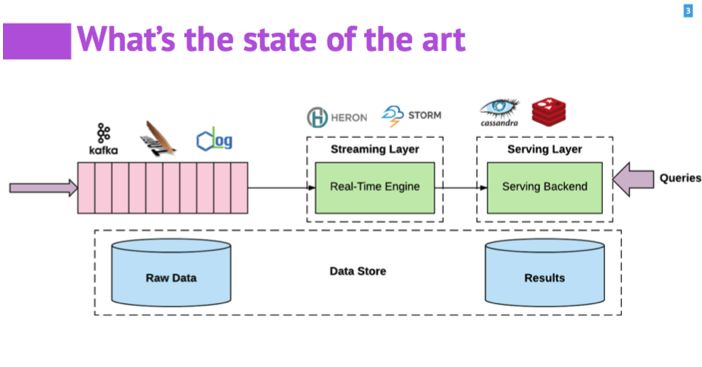
实时数据处理在刚刚兴起的时候,一般企业会采用λ架构,维护两套系统:一套用来处理实时的数据;另一套用 batch 的方式处理历史数据。两套系统带来了资源的冗余占用和维护的不便。
为了消除冗余,逐渐演化出κ架构,使用一套系统来满足实时数据处理和历史数据处理的需求。
不管是λ架构还是κ架构,在实时处理的系统中,系统的核心由消息、计算和存储三个子系统组成,比如消息系统有 Kafka、RabbitMQ、Flume 等;计算系统有 Spark Streaming、Flink、Heron 等;存储系统有各种分布式的文件系统,DB、K/V store 等。 由于三个部分中,每个部分都有相应的不同产品,三个部分之间也相互分隔和独立很少关联,这带来了一些问题,比如需要更多人力维护,部署复杂,调优难度大,监管难,数据丢失风险大等等。

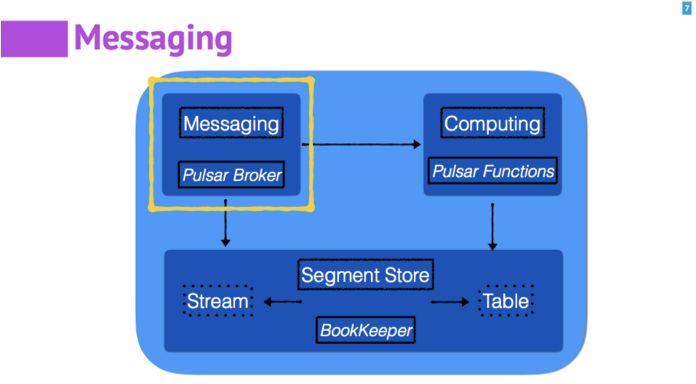
面对消息,存储和计算三个部分分隔的现状,Apache Pulsar 在这三个方面进行了很好的协调、抽象和统一。 具体到 Apache Pulsar 内部,消息部分由 Pulsar Broker 来负责;存储部分使用了 Apache BookKeeper,计算部分由 Pulsar Functions 来负责。

Apache Pulsar 是 2016 年 yahoo 开源的下一代大规模分布式消息系统,目前在 Apache 基金会下孵化。在 Yahoo 的生产环境中大规模部署并使用了近 4 年,服务于 Mail、Finance、Sports、 Flickr、 the Gemini Ads platform、 Sherpa 以及 Yahoo 的 KV 存储等,在 Yahoo 全球 8 个数据中心之间维护了全联通的复制,并包含了 200 多万个 Topics。
Apache Pulsar 有几个明显区别于其他消息系统的特点:
优秀的数据持久性和顺序性。每一条消息都提供了全局唯一的 ID,多副本,并都是在实时刷盘后再返回给用户。
统一的消费模型: 支持 Stream(如 Kafka)和 Queue(如 RabbitMQ)两种消费模型, 支持 exclusive、failover 和 shared 三种消费模式。
灵活的扩展性: 节点扩展的线性和瞬时完成,在扩展中不会有数据的拷贝和迁移。
高吞吐低延迟,在实时刷盘的前提下,依然提供了高带宽(180 万 messages/ 秒)和低延迟(5ms at 99%)。
除了这些特性,Apache Pulsar 也具备了优秀的企业级特性,比如多机房互联互备(Geo-replication),多租户等。
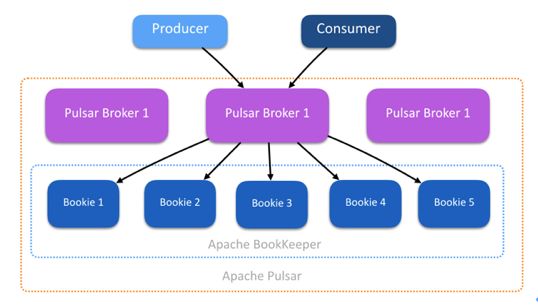
Apache Pulsar 在架构上最明显的优势是采用了消息服务和消息存储分层的策略。它包括了无状态的消息服务层(broker 节点)和消息存储层(BookKeeper 中 Bookie 是基本的存储节点)。这为系统带来了极好的扩展性和健壮性。
在消息服务层和存储层,系统所关注的内容是不一样的: 在服务层更多的是对 Producer 和 Consumer 的支持,更关注用户接口和消息的服务质量,需要更好的 CPU 和网络带宽来支持消息的扇入扇出。存储层更关注磁盘 IOPS 和存储容量,负责数据的持久化等。
分层的架构带为服务和存储两层都带来了线性、瞬时的扩展性。如果需要增加和支持更多的 Producer 和 Consumer,只用对 broker 进行 Scale。如果存储空间紧张,或者想要消息的时间保持的时间更长,可以单独增加存储节点 Bookie。
在服务层中,broker 不会有相关的数据被持久化保存,是无状态的。对 Topic 的服务可以很容易地迁移。如果 broker 失效,可以很容易地将 topic 迁移到健康的 broker。
在存储层(Bookie)也是一样。每个 topic 的数据被打散并均匀 partition 到多个 segment,每个 segment 的数据又被分散存储在 Bookie 集群中。当想增加容量的时候,只需要添加新的 Bookie,数据会优先选择刚加入的 Bookie。
同样当 broker 被 overloaded,添加新的 broker 之后,负载会被均衡地分配到新添加的 broker 之上。
介绍完 Apache Pulsar 的总体架构和特性,下面会从消息、存储和计算三个方面分别介绍 Apache Pulsar 的设计理念,各层内部以及各层之间的协调、抽象和统一。

Apache Pulsar 面向用户的也是最简单的三个概念: 主题 Topic、生产者 Producer 和消费者 Consumer。 Topic 是消息的一个通道和载体; Producer 产生数据并向 Topic 这个通道中发送数据; Consumer 从 Topic 中获取并消费数据。

在 Apache Pulsar 中提供了对 Namespace 的支持。Namespace 是 ApachePulsar 的多租户机制中重要的组成部分。在一个 Topic 的名字中,包含了:租户 (Tenant) ,命名空间(namespace)和 Topic 名字,这样就可以对所有的 topic 提供层级化的管理。
Tenant 代表系统里的租户。假设有一个 Pulsar 集群被多个组织共享,集群里的每个 Tenant 可以代表一个组织的团队、一个核心的功能或一个产品线。一个 Tenant 可以包含多个 namespace,一个 namespace 可以包含多个主题。
Tenant 是资源的隔离的单位。namespace 是资源使用和权限设置的单位,我们可以设置权限、调整复制选项、管理跨集群的数据复制、控制消息的过期时间等。namespace 下的 Topic 会继承 namespace 的配置。如果用户获取了 namespace 的写入权限就可以往 namespace 写入数据,如果要写入的 topic 不存在,就会创建该 topic。
为了支持异地多备,namespace 又分为两种,一种是本地的,只在集群内可见;一种是全局的,对多个集群可见。可以在不同的数据中心之间进行数据的交互和互备。
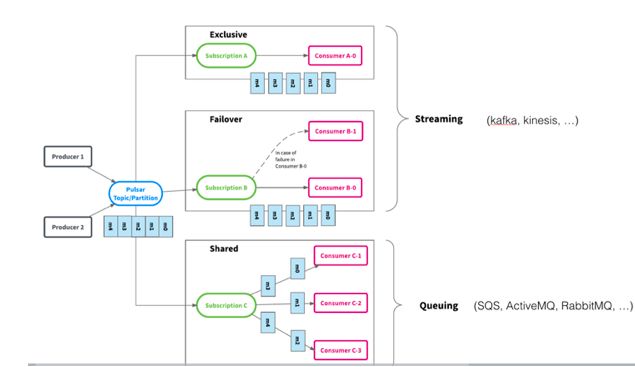
Apache Pulsar 的每个 namespace 可以包含多个 topic,而每个 topic 可以有多个生产者和订阅者。每个订阅者可以接受 topic 的所有的消息。为了给应用程序提供更大的灵活性,Apache Pulsar 通过增加一层 subscription 的抽象,提供了统一的消费模式。 消息的传递路径是 producer-topic-subscription-consumer。subscription 类似 Kafka 中 consumer group 的概念。
Apache Pulsar 支持 exclusive、failover 和 shared 三种订阅类型,它们可以共存在同一个 topic 上。数据虽然只写了一次,但是可以通过三种的消费方式被多次消费。
前两种 exclusive 和 failover,都是 Streaming 的模型,只有一个 consumer 来消费一个 topic partition 中的所有数据,都能保证严格的顺序。Kafka 和 Kinesis 也是这种消费模型(一个 consumer 消费一个 partition)。
Exclusive 是只能有一个 consumer 来消费一个 topic 中的数据,不允许其他的 consumer 加入;failover 是允许多个 consumer 和一个 subscription 关联,当 master consumer 失效后,可以有另外的 consumer 来接管成为新的 master。
第三种是 shared 的消费模式,它属于 Queue 的模式,常见的 RabbitMQ、ActiveMQ 均属于这种模式。如果三个 consumer 共同订阅同一个 subscription,每个 consumer 大概会消费这个 topic 中的三分之一的数据,如果想ß增加消费的带宽,只用单独增加 consumer 的数量而不需要改变 topic 和 partition,非常实用于一些 consumer 处理复杂度比较高的场景,比如视频,图片处理等。
除了这三种消费模式,Apache Pulsar 还提供了 reader 的 API 来读取消息,让用户可以更加灵活的控制和消费消息。
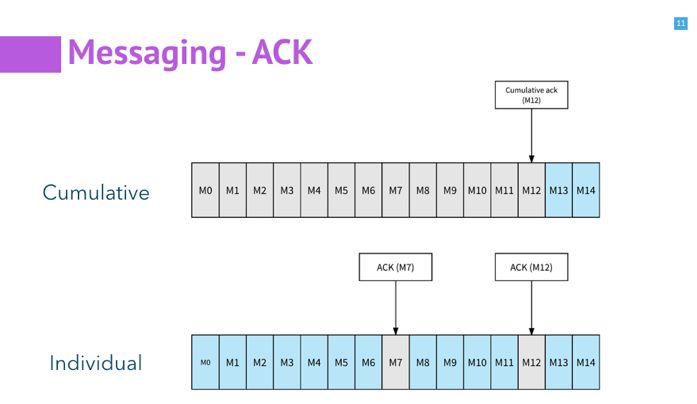
Apache Pulsar 提供了两种 ack 的机制: 累积(cumulative)模式和单条(individual)模式。
Ack 机制在在消息系统中是非常重要的。消息系统中的 broker 和 consumer 可能会出错或宕机,当有错误发生的时候,如果能够获取上次消费者消费的位置,然后从这个消费的位置再接着消费,这是非常有用的,这样可以避免丢失数据,避免把所有的处理过的数据再处理一遍。
一般通过 message acknowledgement、committing offset 来标记消息的消费情况。
Kafka 中通过 offset 来简单的管理 ack,记录一个 partition 的消费位置。
Pulsar 通过维护一个专门的数据结构 ManagedCursor 来管理 ack 的信息,每次 ack 的改变都会被持久化到硬盘中。
对于 cumulative 的 ack,在标记的消息之前,所有的数据都被消费过了;遇到出错的情况会从标记的位置再开始消费。
对于 individual 的消费模式,会单独标记已经被消费过的消息;遇到出错的情况,所有的未被标记 ack 的消息都会被重新发送。Individual 的 ack 模式主要支持 share 的消费模式。它是很有必要的,因为对一般的 share 的消费模式,都是单个的消息消费处理比较慢,所以才增加 consumer。单独的标记,能在出错的时候减少不必要的昂贵的处理。
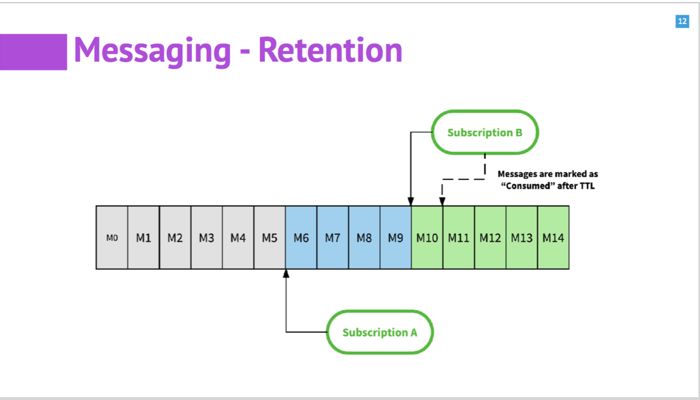
消息的 retention 策略,管理着消息什么时候被删除。 其他的系统大多是通过时间来控制。有可能时间到了,但消息没有被消费,也被删除了。
Apache Pulsar 中,提供了比较全面的 retention 策略。一般情况下,借助 ack 的信息,当所有 subscription 都消费了消息之后,消息才会删除。数据还可以额外的设置 retention period,即使都消费了也能再将消息保存一段时间。另外也支持 TTL 的模式。
对于留在 backlog 中的消息,Apache Pulsar 也提供了多种策略,包括 producer-request-hold、producer-exception、consumer-backlog-eviction 等。在 backlog 的 quota 达到时,供用户选择怎么处理新的消息和在 backlog 中的消息。
Apache Pulsar 的存储层

接下来我们来看一下 Apache Pulsar 的存储层,也就是 Apache BookKeeper。Apache BookKeeper 在 2011 年开源,并随后加入 Apache,成为 Apache 的顶级项目。BookKeeper 是分布式的是一个可扩展的、高可用、低延迟的专门为实时系统优化过的存储系统。更多系统可以参考 BookKeeper 的网站 https://bookkeeper.apache.org/ 和 github:https://github.com/apache/bookkeeper。
Apache BookKeeper 为 Pulsar 系统提供了一个以 Segment(BookKeeper ledger)为存储单元的存储服务。BookKeeper 的存储节点称作一个 Bookie。
BookKeeper 为 append-only 的写入模式提供了优化,通过独特的设计提供了高带宽和低延迟。
BookKeeper 提供了强一致性和顺序性。通过实时刷盘和多备份保证数据的持久性。顺序性通过记录本身携带的全局唯一顺序 ID 来保证的。这样对很多对顺序要求比较高的应用场景。
高可用是说数据会同时写入多个 bookie 上,如果 bookie 发生错误,即使只有一台包含数据的 bookie 可用,仍能为应用提供服务,在其他 bookie 恢复或有新的 bookie 加入后,会自动检查并补全所需要的数据备份。
IO 隔离,对于 Bookie 的读和写是分别发生在不同的磁盘上的。这样不依赖于文件系统和 pagecache 的设计,能保证即使有大量的读的同时,也能保证写的高带宽和低延迟;在大量的写入的同时,读请求的服务质量也能得到保证。这也是能保证多租户的一个关键。
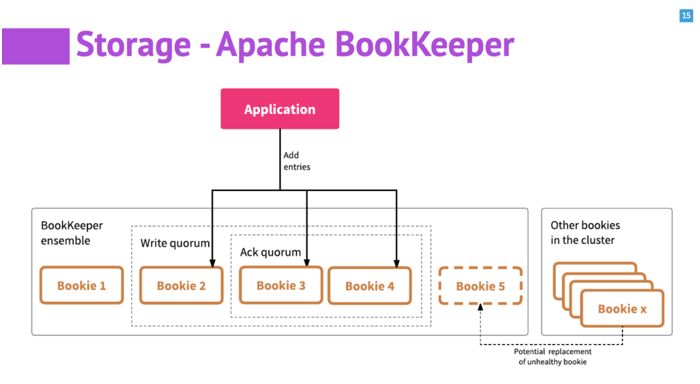
一个 BookKeeper 的集群由多个 Bookie 节点构成。每个 Bookie 负责具体的数据存储。当用户的 application 要使用 bk 的时候,会设定三个参数,ensemble size(用户要使用几台 bookie)、write quorum(写入的数据要保留几个备份)和 ack quorum(每次的写入操作,有几个成功后就返回)。Bookie 采用 quorum-vote 的模式,当写一条数据时,数据同时并发的写到所有的 write quorum 的 bookie 中,当指定的 ack quorum 返回后,bookie 认为写成功,返回。
当 ensemble 中有 bookie 出错,会从 cluster 中寻找其他可用的 bookie,进行替换。然后后台有 autorecovery 做数据的自动恢复,对用户透明。
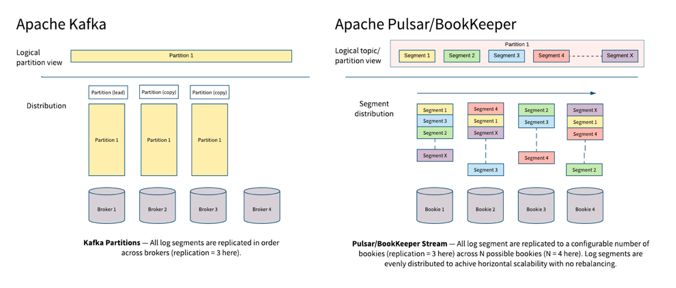
BookKeeper 的一个特性是存储是以 Segment(在 BookKeeper 内部被称作 ledger)为存储的基本单元。每个 Segment 甚至到每个消息的粒度,都会被均匀分散到 BookKeeper 的集群中。保证了数据和服务在多个 Bookie 上的均匀性。通过这张图,我们通过简单对比 Pulsar 和 Kafka 中的 partition 的存储过程,对 Pulsar 有一个更好的理解。
Pulsar 和 Kafka 都是基于 partition 的逻辑概念来做做 topic 的存储。最根本的不同是,Kafka 的物理存储也是以 partition 为单位的,每个 partition 必须作为一个整体(一个目录)被存储在某一个 broker 上。 而 Pulsar 的每个 partition 是以 segment 作为物理存储的单位,Pulsar 中的每个 partition 会再被打散并均匀分散到多个 bookie 节点中。
这样的一个直接的影响是,Kafka 的 partition 的大小,受制于单台 broker 的存储;而 Pulsar 的一个 partition 则可以利用整个集群的存储容量。
当 partition 的容量上限达到后,需要扩容的时候,如果现有的单台机器不能满足,Kafka 可能需要添加新的存储节点,将 partition 的数据搬移到更大的节点上。但是 Pulsar 只用添加新的 Bookie 存储节点,新加入的节点由于剩余的空间大,会被优先使用,更多的接收新的数据;而且其中不会涉及到任何的老的数据的拷贝和搬移。
Pulsar 在单个节点失败时也会体现同样的优势。如果 Pulsar 的服务节点 broker 失效,由于 broker 是无状态的,其他的 broker 可以很快的接管 topic,不会涉及 topic 数据的拷贝;如果存储节点 Bookie 失效,集群中其他的 Bookie 会从多个 Bookie 节点中并发读取数据,并对失效节点的数据自动进行数据的恢复,不会对前端的服务有影响。
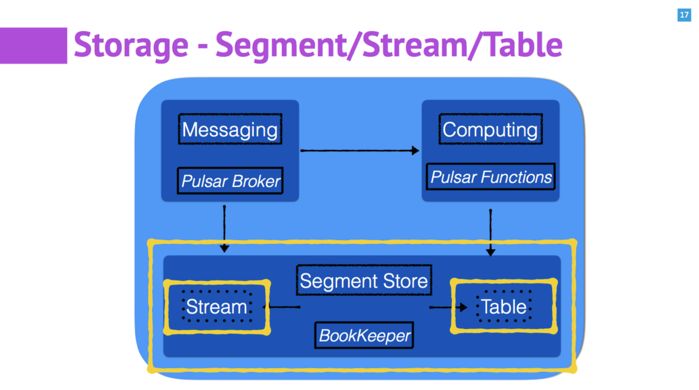
Apache BookKeeper 内部除了基础的的 Segment(ledger), 还提供了 Stream 和 Table 两种服务。 Segment 可以简单理解为一段复制日志。Stream 服务是通过一定的方式,将一组 Segment 按照顺序共同管理起来,这样就可以组成一个源源不断的流。进而,如果我们用 Stream 来作为一个 Table 的 change log,实现了一个简单的 K/V Store,也就是这里说的 Table 的服务。在实时处理的过程中,比如 Pulsar Functions 的处理过程中,需要使用 K/V 的 Table 来存取计算的中间状态。
通过在 BookKeeper 内部提供 Stream 和 Table 两种服务,可以很方便的满足在实时数据处理中的绝大部分的存储需求。
Apache Pulsar 的计算层
介绍完 Pulsar 中的消息和存储,下面我们来了解一下 Pulsar 中的计算部分 – Pulsar Functions。介绍一下 Pulsar Functions 的设计和实现。看看 Pulsar Functions 和其他的计算引擎不同的地方。
首先我们看一个计算引擎最本质的是要解决什么问题。 首先用户定了了一个计算的需求,也就是处理过程: f(x),一组输入数据通过 f(x)的计算,得到一组输出的结果。

基于本质问题,计算引擎经过了长期的发展。第一代的计算引擎,以 Storm 为代表的通过一个有向无环图(DAG)来完成一组计算,通常需要大量的代码编写工作。现在大部分的计算引擎都提供第二代的 API,即通过 DSL 的方式。第二代的 API 相比第一代更加的紧凑和方便,但是还是有些复杂,比如包含着大量的 map、flatmap 等。
我们发现,在实时数据的处理中,有大部分(60%——80%)的计算过程,本质上都是一些很简单的数据转换,比如 ETL/Reactive Services/Classification/Real-time Aggregation/Event Routing/Microservices 等等。

另外,云的兴起,带动了 serverless 的出现和兴盛,Serverless 为我们提供了一个很好的思路。serverless 提供的是 function 的 API,每一个事件触发一次 function,多个 function 可以通过组合的方式,完成比较复杂的逻辑。

基于这些原因,我们决定设计基于 Serverless 的,由消息来驱动的“Stream-native”的 Pulsar Functions。Pulsar Function 的一个特点是简单:给用户的接口简单;每个 Function 的实现也十分容易理解;提供多语言的接口(目前支持 Java 和 Python)。
另一个特点是 Stream-native: Pulsar Functions 的输入,输出和中间的 log 都以 Topic 和消息为中心。
Pulsar Functions 提供两种 API,第一种是 SDK less 的 API,用户不用依赖 Pulsar 的 sdk,只用实现 java.util.function.Function 的接口。第二种借助 Pulsar SDK 的 API,通过 Context 来和 Pulsar 交互和定制。

和 Pulsar 的管理一样,Pulsar Functions 也提供命令行和 Rest 两种方式。执行的参数包括输入的 topic,输出的 topic 和要执行的 Function 的名字。

我们可以举例说明一下 Pulsar Functions 适用的典型应用场景。

在边缘计算(Edge Computing)中,传感器会产生大量数据,而且数据会在边缘的本地节点上进行很多简单的处理,比如 Simple filtering, threshold detection, regex matching 等,另外边缘节点的计算资源有限。 Pulsar Functions 对这样的场景十分匹配。另外是在机器学习中。最开始的基础模型通过离线进行计算和训练。当训练完,上线后,每一个输入,都会匹配和应用模型,并对模型进行调整。这十分匹配 Pulsar Functions 的消息驱动的模式。另外模型本身也可以使用 BookKeeper 做存储,简化系统的部署。
这里 Pulsar Functions 的特性做一个总结。

首先,Pulsar Function 可以简单运行在 Pulsar 的 broker 里面,简化系统的部署。输入的 Topic 中的每一个消息都会触发对 Function 的执行。可以支持多个 Topic 作为输入。用户可以控制 Function 执行的各种语义:AtMostOnce 是当 Function 收到消息后就进行 ACK;AtLeastOnce 是在 Function 对消息处理完成后才进行 ACK;ExactlyOnce 是通过 Pulsar 内部实现的 deDup 的策略来实现。 Pulsar Functions 可以使用 BookKeeper 提供的 Stream 服务来做 Topic 的存储,使用提供的 Table 服务来做中间状态的存储,实现存储的统一,不需要部署其他的系统。这为系统的开发、测试、集成和运维带来了更多的便利。
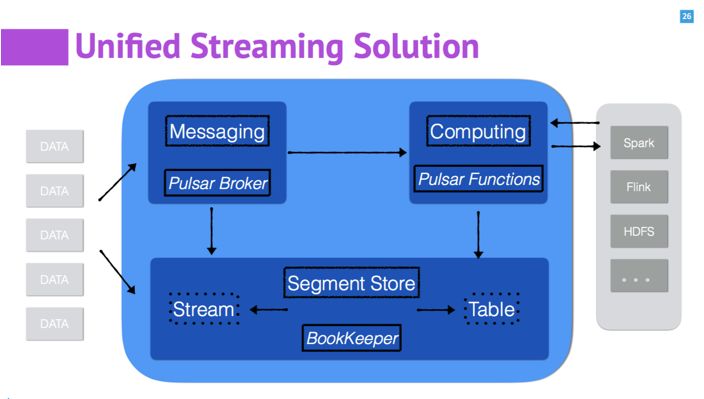
通过介绍 Pulsar 的消息,存储和计算三个部分,希望能让大家对 Pulsar 有更进一步的了解。在 Pulsar 的消息系统中,提供了基于 Stream 和 Queue 的统一的消费模式,提供了无状态的 Broker 来提升系统的扩展性和容错性。在存储系统 BookKeeper 中,提供了对 Stream 的存储和对 K/V Table 的存储的统一,满足了实时处理系统中对 topic 和状态的存储需求。 在计算部分,Pulsar Functions 中基于消息驱动(stream-native),可以计算和消息一种统一。
另外对于 Pulsar 系统和外部系统的互联(connector),可以看作是一种特殊的 Pulsar Functions。
这里的 Benchmark(https://github.com/openmessaging/openmessaging-benchmark)是我们和阿里一起起草的 openMessaging 项目的一部分。如果有时间和机器,欢迎大家自己验证一下。
这个 Benchmark 通过相同的配置,对 Apache Pulsar 和 Kafka 的带宽和延迟进行了简单的测试。


 最大吞吐量测试
最大吞吐量测试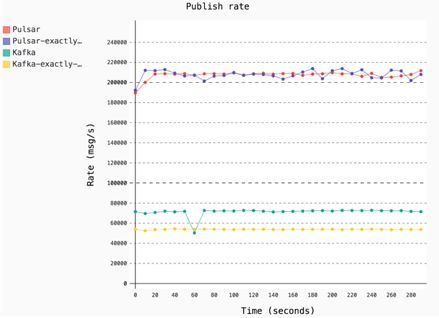
这个结果是分别测试了 Pulsar 和 Kafka 在一般模式和 Exactly-once 模式下的 Publish 带宽。
在 1KB 消息大小下,Pulsar 的一般模式和 Exactly-once 模式下的带宽都在 21 万条 / 秒左右;Kafka 在一般模式和 Exactly-once 模式下的带宽分别是 7 万多条 / 秒和 5 万多条 / 秒。
除了带宽数值的区别,另一方面是对 ExactlyOnce 的处理,Pulsar 通过自身的机制,几乎相对于一般的 模式在性能上没有区别。但是 Kafka 的两种模式会有较大的差别。
时延测试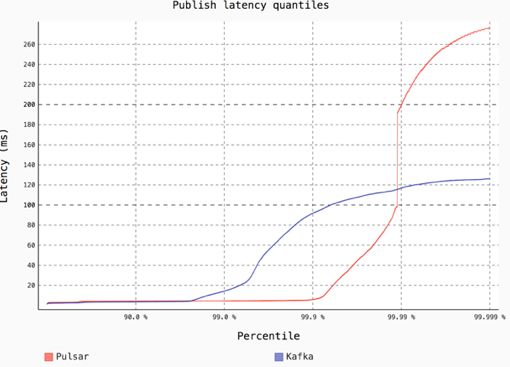
这个结果是 Pulsar 和 Kafka 在固定的 Public 带宽(50K/ 秒)下,各个百分位消息的发布时延。可以看出 Kafka 在不到 99% 的百分位,时延就开始大幅上升,但是 Pulsar 在 99.9% 的百分位以后,时延才开始上升。
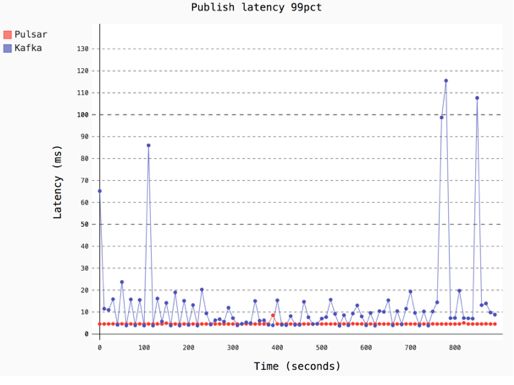
这个结果是从时间轴的角度来看 Pulsar 和 Kafka 的时延。先不关注时延的绝对数值,直观的感觉是 Pulsar 的时延更加稳定;Kafka 的时延会有很大的波动。 这和 Pulsar 中的内存和对 GC 的优化有直接的关系。Apache Pulsar 是一个新兴的下一代的消息系统,由于 Pulsar Functions 的加入,和底层 Apache BookKeeper 提供的 Table 服务的完善,现在可以认为 Apache Pulsar 是一个在消息、存储和计算三方面的统一的实时数据处理平台。
Apache Pulsar 有很多先进的理念、设计和抽象在里面。由于时间关系有很多的部分没能展开细讲。

Apache Pulsar 和 Apache BookKeeper 中也有越来越多的有意思的 feature 和功能正在进行,公司和社区也都期待大家的关注和加入。如果大家有更多的关于 Meetup 和 POC 等需求,或者在使用其他消息系统中遇到问题,可以通过 Slack Channel 和微信联系我们。
作者介绍
翟佳,Streamlio核心创始成员之一,毕业于中科院计算所,目前就职于一家下一代实时处理初创公司 Streamlio,是 Streamlio的核心创始成员之一。在此之前任职于 EMC,是北京 EMC实时处理平台的技术负责人。主要从事实时计算和分布式存储系统的相关开发,是开源项目 Apache BookKeeper PMC Member和 Committer,也在 Apache Pulsar, Distributedlog等项目中持续贡献代码。
声明:本文来自AI前线,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
