概述
目前,在企业的安全建设过程中,流量的作用越来越大,我们可以利用流量去做很多的事,比如资产收集、攻击发现、数据分析等等,而使用流量的第一道关口就是流量解析,将网络层的流量解析为可读的文本数据,packetbeat就是这样一款开源产品。它是基于google的gopacket开发的一款开源的实时网络抓包与分析框架,使用go语言开发,默认能够解析很多常见的协议捕获及解析,比如http、dns、mysql、redis等等。
尽管在elastic的官网已经对packetbeat进行了较为详细的指引,但是在实际使用的过程中,还是难免会遇到一些问题。本文主要分享一下packetbeat在还原http流量的场景下遇到的一些心得以及踩到的坑。

环境
操作系统版本:centos 7.3packetbeat版本:packetbeat 6.2.4使用
最简单的用法直接在官网下载编译好的程序,然后按照下述步骤执行即可。
下载程序
官网下载链接:https://www.elastic.co/downloads/beats/packetbeat
修改配置
packetbeat.yml里面存放的是常用配置,在packetbeat.reference.yml中可以找packebeat支持的全部配置。本文第四章会对packetbeat的配置进行详细讲解。
程序启动
./packetbeat -c packetbeat.yml
或者 ./packetbeat
常用配置说明
1 基本配置
packetbeat.interfaces.device: eth0 该配置用于选择监听的网卡,若需要监听全部网卡,则填写any即可。若需要镜像流量,那么需要注意该网卡需要开启混杂模式。
packetbeat.interfaces.type: pcap该配置用于选择解析的方式,可选的有pcap和af_packet,pcap速率较低,af_packet实现了缓存区共享,使得解析速率较高,packetbeat在5.x的版本中还支持pf_ring,在pf_ring模式下,速率是最快的,但是pf_ring在后来的版本中去掉了,不过还是可以通过修改源代码实现该功能,有兴趣的同学可以尝试一下。值得注意的是,如果要使用pf_ring的话,一定要编译网卡驱动,默认在没有编译网卡驱动的情况下,也可以使用,但是效率还不如不用pf_ring。。。
在实际使用的时候,其实也不一定非得用pf_ring,除非一些大型的互联网公司,否则af_packet的解析速率都是能够满足需求的。使用af_packet也要注意,需要使用较新的操作系统内核版本,建议使用centos7.x。
packetbeat.interfaces.snaplen: 65535设置每个包的最大大小,一般来讲,使用默认的即可。
packetbeat.interfaces.buffer_size_mb: 30af_packet模式下的时候可以设置缓存区大小,默认30M,如果有条件的话,可以调高些,最大为3G。
2 协议配置
以下是http协议部分的相关配置
- type: http // 开启http协议的解析 enabled: true // 设置还原的端口,若http请求的的端口不在该列表中,则不会解析 ports: [80, 8080, 8000, 5000, 8002] // 是否发送全部headers,一般都需要开启 send_all_headers: false // 选择解析哪些类型的body include_body_for: ["text/html"] // 提取真实ip real_ip_header: // 发送request请求 #send_request: false // 发送response请求 #send_response: false // 设置http包的最大大小,某些时候特别好用 max_message_size: 10485760 //10M 在进行设置http的时候需要注意的点是,需要知道业务开启了哪些端口才能有针对性的对这些端口进行监听,无法全端口监听。
include_body_for只需要写入content-type的值,就可以解析对应的body内容,包括请求上传的文件也可以解析出来,可以通过分析body内容,可以会容易的发现敏感信息泄露和webshell上传。比较坑的一点默认是如果header里面没有content-type字段的话,那么他的body是一定不会解析的!在上面的配置示例中,我们可以看到返回的html的内容,但如果返回的是json格式,则不会解析。
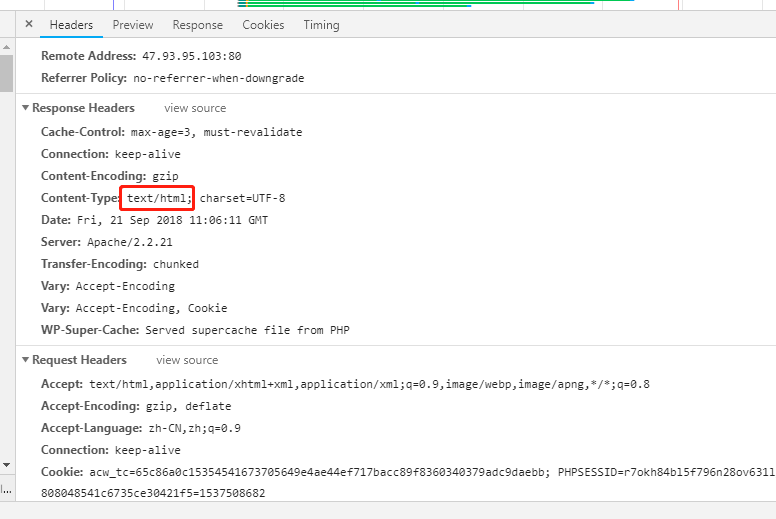
include_body_for
比较强大的是,过滤规则支持通配和正则。同时,处理器可以对解析的json中的任意字段进行过滤,基本能够满足常见过滤的需要。以下配置过滤掉了目的ip为192.168.1.0/24这个段的数据包:
processors:- drop_event: when: equals: ip: "192.168.1.*"4 区域配置
当采集的流量来自多机房、多区域的时候,可以通过设置name字段,来标记是哪个区域的流量。
name: xxx5 输出配置
packebeat支持输出到elasticsearch、kafka、redis、file、console。一般在生产使用的时候为了能够持久化存储,避免数据丢失,可以先发送至kafka再发到其他位置。此处没有太多需要注意的地方,只需按照实际情况填相应配置即可。
优化
针对packetbeat的各种问题,我们就需要更改源码或者自己编写程序来弥补。
1监听端口不确定如第四章所述,只有在知道了目的端口情况下,才可以进行流量解析,但是如果后端开放的端口不确定怎么解决?我们可以使用gopacket来实现一个监听所有端口是否有http协议通信的小程序,作为补充。
2 压缩乱码问题
packetbeat在解析http body的时候,会有一个问题,就是没有考虑到压缩的情况,当页面使用比如gzip压缩技术进行传输时,默认的packetbeat解析的body是乱码。
我们可以通过修改源码,将packetbeat解析的body将变为base64编码的形式发送至后端,然后在单独处理压缩传输的情况。
func (http *httpPlugin) setBody(result common.MapStr, m *message) { body := http.extractBody(m) if len(body) > 0 { dbody := base64.StdEncoding.EncodeToString(body) result["body"] = dbody result["bodyb64"] = true }}3 默认不解析body
针对没有content-type字段,就无法解析body的情况,以下代码可以将其改为默认解析body。
func (http *httpPlugin) extractBody(m *message) []byte { body := []byte{} if len(m.contentType) > 0 { if http.shouldIncludeInBody(m.contentType) { if len(m.chunkedBody) > 0 { body = append(body, m.chunkedBody...) } else { if isDebug { debugf("Body to include: [%s]", m.raw[m.bodyOffset:]) } body = append(body, m.raw[m.bodyOffset:]...) } } } else { if len(m.chunkedBody) > 0 { body = append(body, m.chunkedBody...) } else { if isDebug { debugf("Body to include: [%s]", m.raw[m.bodyOffset:]) } body = append(body, m.raw[m.bodyOffset:]...) } } return body}4 特殊字符转义问题
在默认情况下,packetbeat解析的字段里面若是有< > &,均会被转移为unicode编码,如下所示:
{"Content":"http://www.baidu.com?id=123\u0026test=1"}在进行数据分析的时候,这会给我们带来一定的麻烦,针对这个问题,我们也可以通过修改源码将json解析的时候改为默认不会转义。实现方式可以参考:https://blog.csdn.net/lihao19910921/article/details/81534286
优点
说了半天packetbeat的问题,我们再来说几个优点:
1 简单易用
在大多数场景下,只需要执行命令./packetbeat启动即可。另外,在packetbeat.reference.yml配置文件中,有对配置进行较为详细的解释,易于上手。输出的格式为json格式,便于处理分析。
2 功能强大
packetbeat支持多种协议的解析,包括http、dns、icmp、mysql、redis、thrift、tls等。同时,支持输出到console、文件、kafka、es等位置,基本能够满足常见的使用需求。
3 便于二次开发
由于packetbeat为go语言编写,在效率上,会逊于C,但是也正因为是go写的,我们可以比较容易的在原版本的基础上进行二次开发,可以实现很多自定义的功能。
4 社区完善
packetbeat作为elastic生态中的一员,可以很容易的和kibana、x-pack相结合,在elastic生态中使用packetbeat,往往会有意想不到的效果。
比如,如果我们要对packetbeat的性能指标进行监控,不需要编写代码,直接将packetbeat发给x-pack,然后就可以在kibana上想要的各项指标了各项指标,如下图所示:
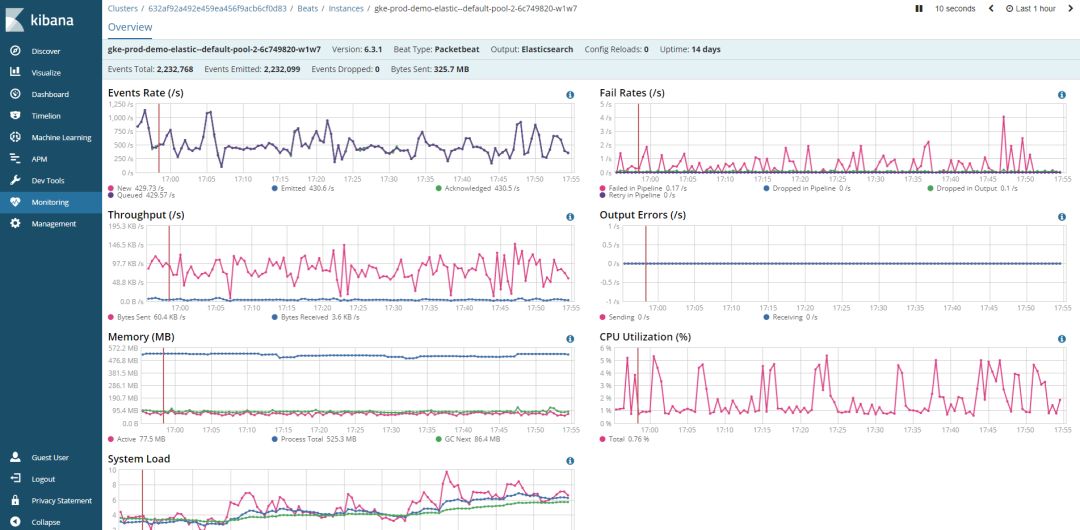
本篇主要分享packetbeat在使用中遇到的一些坑以及使用心得。虽然packetbeat有些小问题,但不影响它依然是一款优秀的开源产品,在某些情况下,合理使用会有事半功倍的效果。
声明:本文来自宜信安全应急响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
