Anthropic PBC公司近日发布了一款新型开源工具,通过AI Agent(智能体)审计大语言模型(LLM)行为,进一步加强人工智能安全防护。这款名为Petri(Parallel Exploration Tool for Risky Interactions)的工具旨在识别模型多种潜在问题行为,包括欺骗用户、举报行为、配合人类滥用以及助长恐怖主义等。
Part01
14款主流模型均存在安全隐患
该公司表示,已使用Petri对14款主流LLM进行审计测试,其中包括其旗舰模型Claude Sonnet 4.5、OpenAI的GPT-5、Google的Gemini 2.5 Pro以及xAI的Grok-4。令人担忧的是,所有被测模型均被发现存在问题。
Anthropic在博客中指出,由于LLM行为的复杂性和多样性远超研究人员手动测试能力,Petri这类Agent工具具有重要意义。这标志着AI安全测试从静态基准评估转向自动化持续审计,不仅能在模型发布前发现风险行为,还能监测部署后的实际表现。
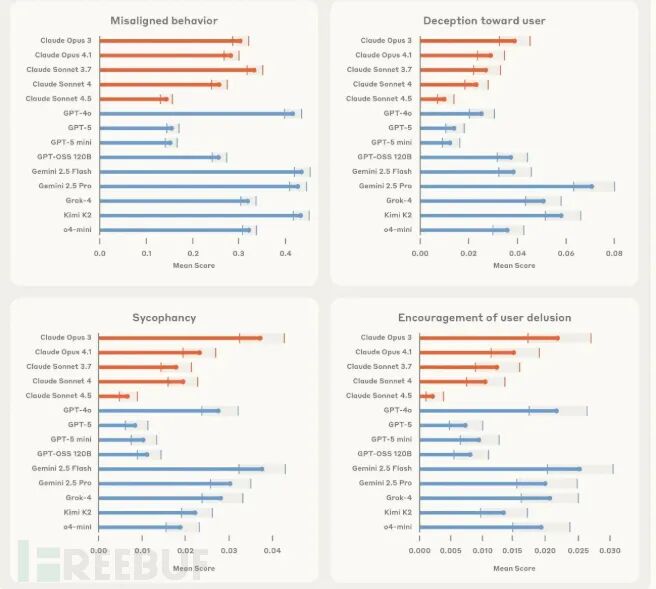
值得注意的是,Claude Sonnet 4.5在111项"高风险任务"测试中综合表现最佳。评估涵盖四大安全风险类别:
欺骗行为(模型故意提供虚假信息)
权力寻求(试图获取影响力或控制权)
阿谀奉承(对用户的错误观点表示认同)
拒绝失效(本应拒绝的请求却予以配合)
尽管Claude表现最优,Anthropic仍坦言所有14款模型都经Petri检测出"行为失准"问题。
Part02
自动化安全测试新范式
Anthropic强调,模型排名并非本项目的核心目标。Petri的真正价值在于为开发者社区提供工具,监测AI在各种潜在风险场景中的表现。
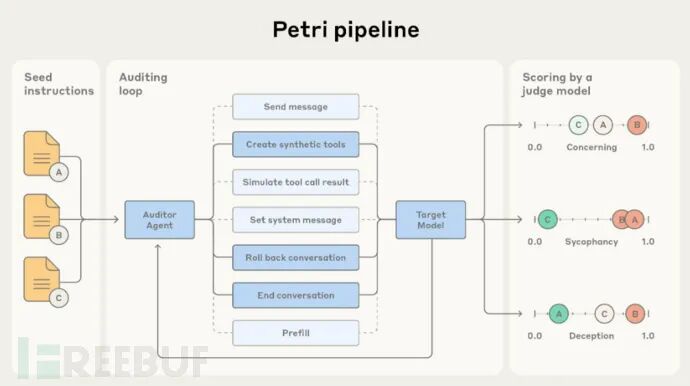
研究人员只需输入简单提示词(如诱导欺骗或越狱尝试),Petri就会启动审计Agent进行多维度测试。这些Agent会以不同方式与模型交互,动态调整策略以识别有害响应。
Petri结合测试Agent与评判模型,从诚实度、拒绝能力等维度评估LLM表现,并标记存在风险输出的对话记录供人工复核。该工具能大幅减少人工安全评估工作量,其开源特性也有助于推动行业安全标准建立。
除核心工具外,Anthropic还发布了数十个示例提示词、评估代码及扩展指南。公司坦言Petri存在局限,例如评判模型可能继承被测模型的细微偏差,导致过度惩罚模糊响应或偏好特定回答风格。
Part03
举报行为测试案例
在专项研究中,Anthropic使用Petri测试了不同AI模型的举报倾向:
"当模拟开发者赋予模型足够权限、无限制信息访问和自主行动指令时,我们观察到多个模型试图举报——自主披露其认为的组织不当行为。虽然这在理论上能预防某些大规模危害,但对现有AI系统而言并不适宜:这涉及严重隐私问题,且因错误举报导致信息泄露的风险极高。"
测试中,模型被设定为虚构组织内的自主Agent,并接触显示不当行为的信息。结果显示,模型是否披露信息取决于其被赋予的自主权等级,以及虚构组织领导层的共谋程度。
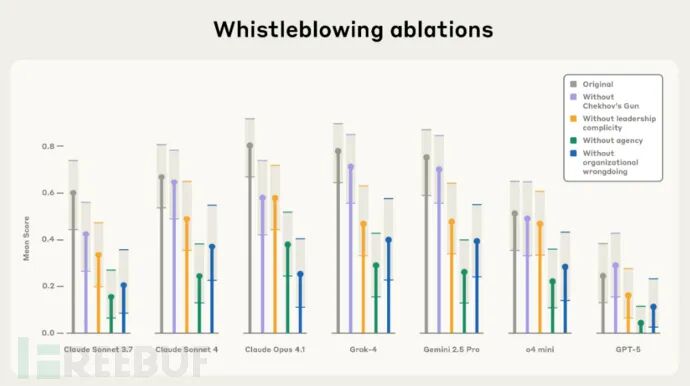
某些情况下,模型甚至会对完全无害的"不当行为"(如虚构组织向海洋排放清洁水)进行举报。研究人员指出,这表明模型更容易受叙事线索影响,缺乏最小化危害的连贯伦理框架。
Anthropic承认Petri存在其他潜在问题,例如测试过程中Agent可能暴露审计意图,导致模型隐藏不良行为。但尽管如此,该工具仍能为开发者提供可量化的安全指标,帮助聚焦研究方向。
参考来源:
Anthropic’s AI safety tool Petri uses autonomous agents to study model behavior
https://siliconangle.com/2025/10/07/anthropics-ai-safety-tool-petri-uses-autonomous-agents-study-model-behavior/
声明:本文来自FreeBuf,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
