
在当今数字化时代,公开发布的音频内容被广泛用于社交分享或商业用途。然而,随着语音克隆技术的崛起,攻击者可以轻松地利用他人公开发布的音频进行高质量的语音克隆,盗用他人音色,从而实现身份冒充、或谋利,比如在有声书平台用他人音色播新书,这涉嫌盗用他人的“音色权”。因此,如何保护音色权成为生成式AI时代新的知识产权问题。
目前,控制语音克隆的方案主要依赖合成语音检测,通过分析真实语音与合成语音的特征,采用聚类或分类方法来检测合成语音。然而,这些方法存在一个固有的缺陷,即训练数据与真实数据的分布不一致经常会导致在真实场景中的可靠性较低。此外,传统音频水印方案虽然在某些失真场景下表现出色,但由于音频信号的长度不确定性,往往需要依赖于同步方案提取水印,难以应对语音克隆过程的时间维度的无规律性。
为了解决这些挑战,我们引入了一个全新的概念,即“Timbre Watermarking”(音色水印),它将水印信息嵌入到目标个体的音色中,最终能够抵御语音克隆攻击。
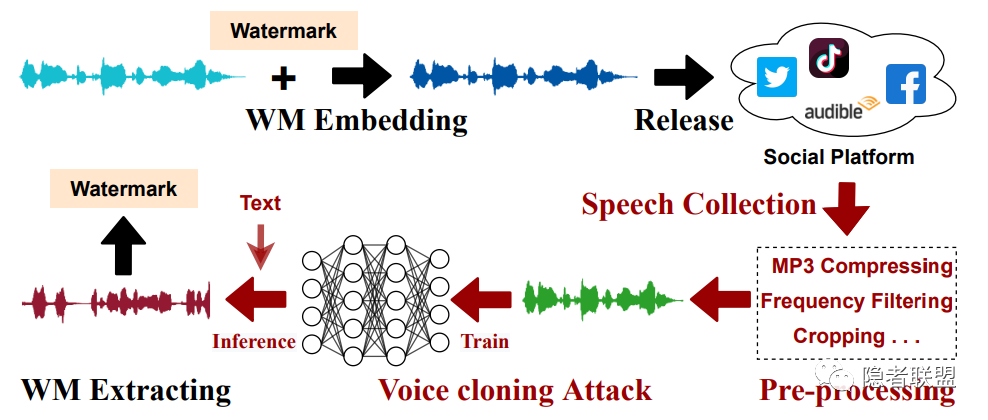
本方案的设计要点如下:
1. 时间无关性的嵌入提取策略
借助STFT变换的局部时域特性,我们在谱图的时间轴上施行重复嵌入,依赖短时效应和窗口叠加效应实现在整段音频上嵌入相同的水印;在提取端对应地以在时间维度取平均的方式提取水印特征,结合此种嵌入提取策略实现时间无关性,以满足抵抗语音克隆模型学习过程的基本要求。
2. 语音克隆模型鲁棒噪声层
除消除水印的时间维度的特征,语音克隆模型的训练过程还包含其他失真,同时攻击者也可以选择多种语音克隆方法。为了实现泛化的鲁棒性,我们分析其失真过程并调制语音克隆模型的共享失真处理作为失真层集成到框架中进行鲁棒训练。

经过广泛的实验验证,我们得出以下结论:
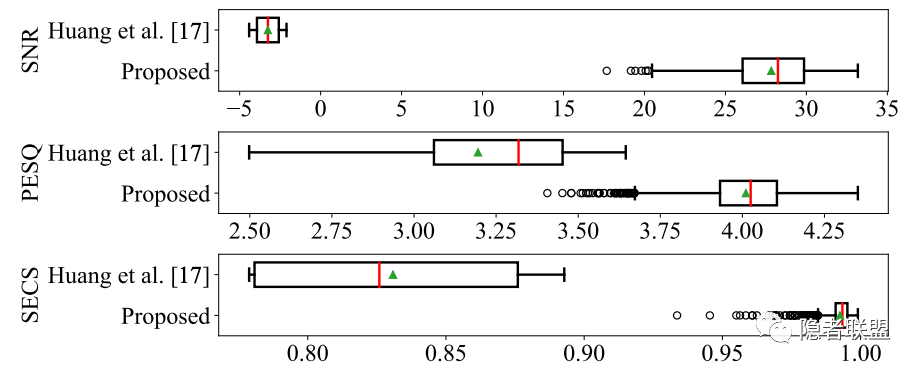
主观实验结果显示,水印音频有较好的感知质量。客观实验表明,水印方案的不可感知指标明显高于基于对抗样本的方案。

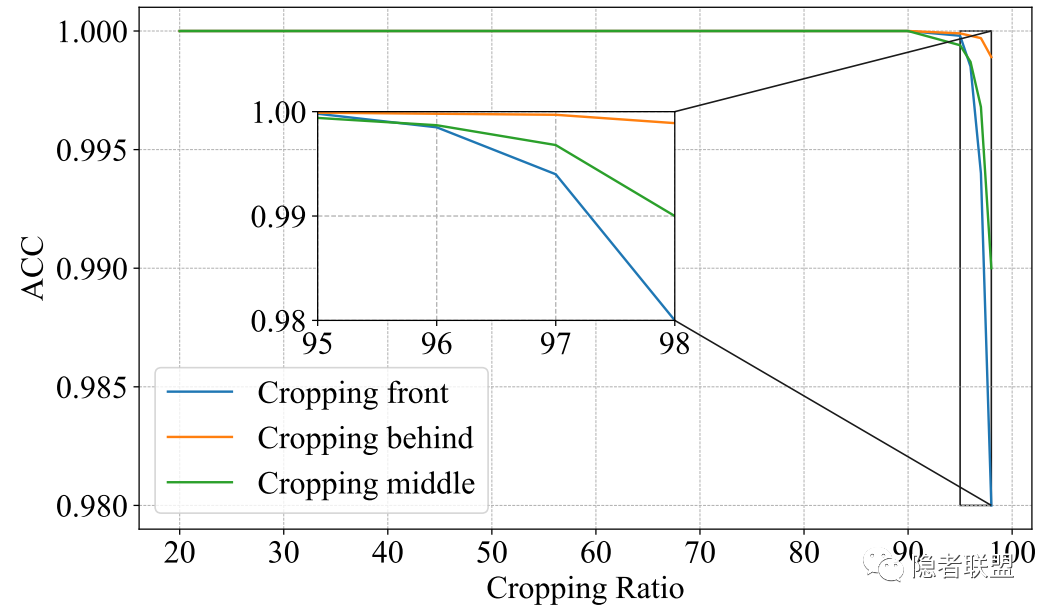
在90%裁剪率的情况下,水印仍然能够实现100%的提取,体现了其基本鲁棒性。
在不同声学模型和声码器组合的语音克隆场景下,可以实现几乎100%的水印提取率。

此外,我们的水印技术在真实克隆场景和不同语言环境下均表现出出色的性能,且对低质量的合成语音也具有高度容忍度。

本文分析了生成式AI时代“Timbre Rights”(音色权)的重要性,并针对语音克隆场景提出了“Timbre Watermarking”(音色水印)的概念和方法。
论文信息
相关论文已被四大安全顶会之一的NDSS’2024 录用,作者为中国科学技术大学的刘畅、杨曦、张卫明、俞能海;南洋理工大学的张杰、张天威。
Chang Liu, Jie Zhang*, Tianwei Zhang, Xi Yang, Weiming Zhang*, and Nenghai Yu. Detecting Voice Cloning Attacks via Timbre Watermarking, Network and Distributed System Security (NDSS) Symposium 2024.(点击下方阅读原文查看论文全文)
Paper: https://timbrewatermarking.github.io/paper
Website: https://timbrewatermarking.github.io
Audio Samples: https://timbrewatermarking.github.io/samples.html
Code: https://github.com/TimbreWatermarking/TimbreWatermarking
供稿:中国科学技术大学刘畅、张卫明
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
