一、AI的进展回顾及在网络安全的应用
1.人工智能关键事件的回顾与展望
首先回顾一下笔者眼中人工智能史上重要的的事件。
◆ 20世纪50年代,人工智能和图灵测试就已经提出,但可能受限于计算能力似乎一直进展缓慢。直到1997年,IBM深蓝战胜卡斯帕罗夫,标志着AI在复杂策略游戏领域的进展,其实从现在来看,算法也并没有多复杂。
◆ 2010年开始,深度学习技术兴起。2012年AlexNet首次应用于图像分类任务ImageNet竞赛中,取得了显著的成功,并且以极大的优势领先,进步远超前几年的比赛。标志着深度学习在图像处理领域的一个重要转折点,开启了深度学习热潮。训练AlexNet只使用了几个GPU,效果远不如的Google系统则用了上万个CPU。从此也开启了英伟达的泼天富贵之路。
◆ 2016年,DeepMind AlphaGo击败围棋世界冠军李世石,展示了强化学习在解决复杂策略问题上的潜力。从此,电脑成为围棋最高水平的尺度,人类上千年的积累比不上程序几个月的训练。
◆ 2017年,Google提出Transformer,其注意力机制成为NLP领域的新标准。2020年后,Transformer架构不仅限于文本处理,还被应用于图像识别、语音处理等多个领域,对于以后惊艳的GPT出现形成了核心而又深远的影响。
◆ 2020年,OpenAI发布GPT3,展示了惊人的生成能力和跨任务适应性,无需针对特定任务进行微调即可完成多种NLP任务,但在2020年的当时还未出圈,形成全社会的影响。
◆ 2022年,11月ChatGPT发布,真正开始破圈。人工智能的热潮开始汹涌,从此以后各种商业和开源模型如雨后春笋,相关的应用方兴未艾。
至于未来会怎么样,人工智能会不会产生意识,面对超级人工智能,我们和它会是什么样的关系?笔者推荐一本书《生命 3.0》。

从最乐观的人类超级智能伙伴,就象电影《HER》里面的那样,不仅能支持物质生产,还能提供情绪价值,照顾到生活的方方面面。

但这种超级智能的出现也隐藏着巨大的风险,目标上没有有效对齐的超级智能也极可能成为人类的终结者。

《生命3.0》这本书在第5章设想了几种可能性,但实话说,这几种设想也可能都是错的。另外说一句,这本书出版于2018年,里面写的事情最早发生于2015年,那个时候远没有到人工智能的iPhone时刻,可在那个时间点泰格马克那些人已经从深度学习神经网络的进展中意识到了人工智能的发展潜力。
2.人工智能在网络安全方面的应用
(1)前大模型时代
再说回网络安全,以下是一个国外研究机构的总结报告中的结论,对大模型前的机器学习/AI技术在网络安全领域的一些应用成果做了评估。
Machine Learning and Cybersecurity - HYPE AND REALITY
https://cset.georgetown.edu/wp-content/uploads/Machine-Learning-and-Cybersecurity.pdf

目前主要在恶意代码检测、入侵检测和垃圾邮件检测三方面,这些应用在2010年代已经比较成熟,也展现出了较好的效果。
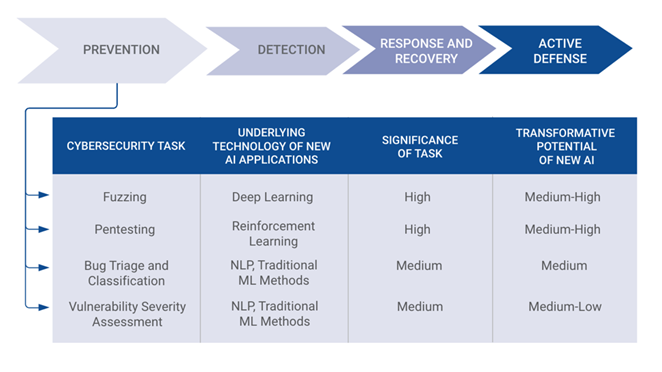
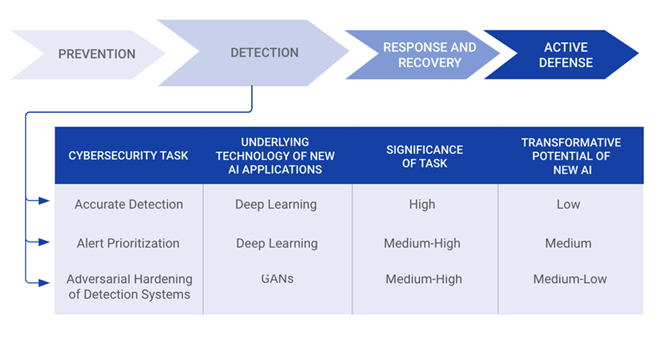
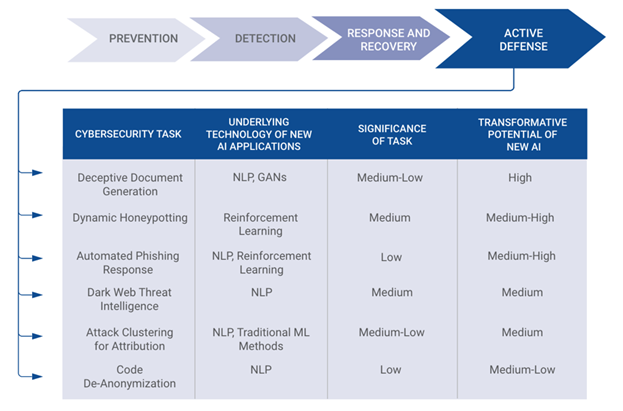
在网络防御的各主要环节中,包括深度学习、自然语言处理、强化学习、生成对抗网络等技术都被尝试过了,但从实际的影响来看,大都是中低级别的相对传统方法效果改进型的,并没有产生颠覆性的影响。
(2)大模型时代

在大模型出来之前,基于机器学习的处理系统也经常被描绘成一个大脑的样子,但那些系统其实只能完成非常特定的任务,不具备通用性,只有真正结合了通用知识和推理能力的模型才有资格以大脑的样子呈现。这里我们列了一些大模型在网络安全方面可以有所作为的方向:
◆ 威胁检测与分类,涉及恶意代码的检测和分析、钓鱼邮件的识别、访问异常行为的判断,可以得到比传统机器学习及AI更好的效果。
◆ 威胁响应与决策支持,规则生成,自动化脚本与分派任务,告警降嗓,交互式操作支持,大模型具备各类安全工具平台相关的脚本和规则知识,比如IDS系统Snort、文件扫描引擎Yara,可以根据来自各种报告的相对高层次的自然语言的技术性描述生成各类检测规则和脚本,以及可加载处置设备的策略文本,对于信心度高的规划可以自动使能,有些关键操作可能还需要人的审核。
◆ 威胁情报收集、处理及输出,关于威胁行为体、攻击手法及IOC信息的产出,用于构建问答式知识库的核心技术。
◆ 漏洞信息整合,利用大模型强大的代码理解和构建能力挖掘和分析软件中的漏洞,协助开发漏洞利用POC也是可能的。
◆ 应急响应与事后分析,根据响应过程中收集到的事实和技术信息自动生成事件报告,这些可以极大减少人工工作量。
◆ 教育和培训,生成安全最佳实践、模拟攻击场景和提供答案解释。
所有与文本和图像分析和处理的工作都是大模型的强项和可以充分挖掘的能力,在威胁情报方面的应用正是大模型的擅长方向。
接下来,我们通过一些测试来看看。
二、威胁情报运营各环节及AI技术的应用概览
首先简单介绍一下奇安信威胁情报运营的基本流程,这本质上是一个数据驱动的过程,从多个源头做数据采集,经过一系列清洗、分类、检测、关联、结构化等过程处理以后,形成数据或服务输出给安全检测产品和相应的威胁分析响应人员。
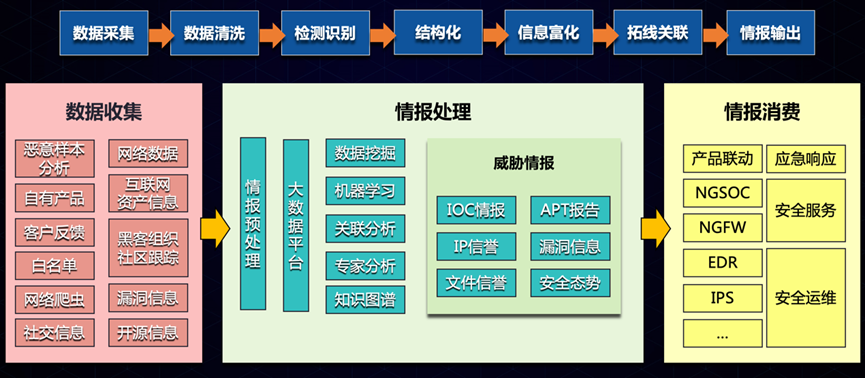
在网络威胁情报的运营生产过程中,包括大模型在内的AI技术在流程的各个环节加以合理运用能极大提升运营的效率与效果。
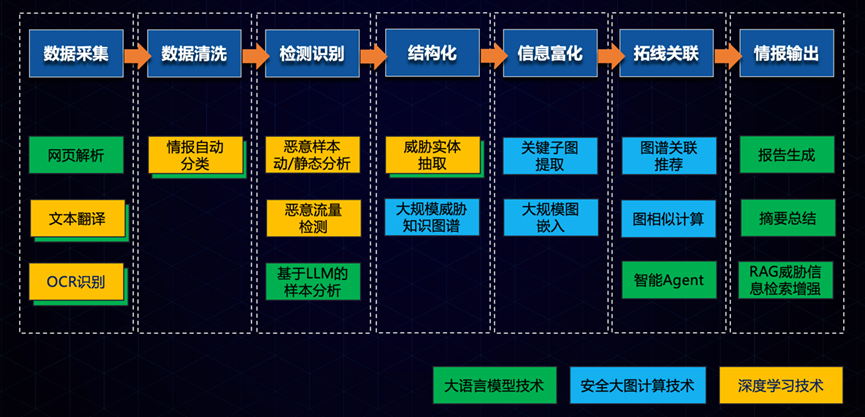
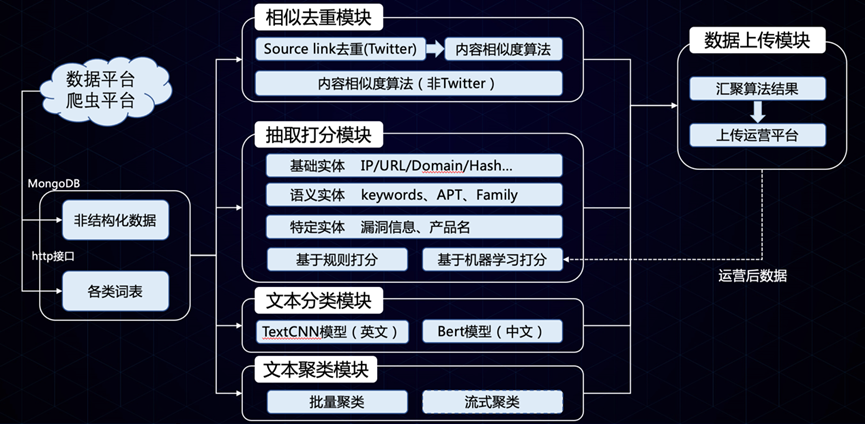
上图展示了奇安信威胁情报运营的主要环节及相应AI技术应用情况,这是多年累积的结果,传统的机器学习的技术早已应用,在大模型技术出现以后有些能力被取代或加强。
首先,从数据采集开始。在这个阶段,我们的目标是从各种来源收集尽可能多的数据并进行快速而准确地分类和提取。这里需要执行网页解析、文本翻译和OCR识别等操作。几乎在获取的同时对信息进行分类,去除噪声和无关数据。运用自然语言处理技术,特别是利用大模型进行语义标签的自动分类和智能分析,从而完成精确的多维度的信息分类,据此可以进入不同的处理子流程。其中,大语言模型发挥其在数据分析方面的核心优势。它们能够理解和处理大量非结构化的文本及音视频数据,并从中提取我们需要的关键信息。
然后是检测识别。这一阶段的目标是对文件样本与网络流量等元数据执行检测,进行威胁判定,标记恶意实体,这是威胁情报运营过程中核心环节,安全厂商的能力所在。本阶段使用了比较成熟的机器学习算法和深度学习技术,实现恶意样本的标定和恶意网络攻击的识别,收集其相关的威胁情报工件数据。
接下来,我们会对收集到的威胁元数据进一步结构化,综合利用自然语言处理技术、大模型技术以及大规模威胁知识图谱的构建,提取精准的威胁实体并建立多类型的关联。
在结构化之后,我们进入信息富化的阶段。这一步骤涉及到关键子图的提取和大规模图嵌入,从其他源补充更多的关联信息。通过这些方法,我们可以揭示出隐藏在数据背后的模式和联系。
实体信息富化以后做进一步的拓线关联。我们利用智能Agent和图相似计算来推荐可能的相关恶意实体和事件。这使得我们能够建立一个完整的威胁图景,并挖掘出更多潜在的威胁对象实体。
最后,我们生成报告并对情报进行摘要总结。这一步依赖于大语言模型的技术,它们能够生成简洁且易于理解的报告并给出结论,基于公开和内部信息构建安全知识库,为威胁分析和应急响应人员提供信息支持。
这就是整个网络威胁情报生产及运营的过程。通过结合大语言模型、安全大数据计算技术和深度学习技术的综合应用实现威胁情报的快速发现和输出。
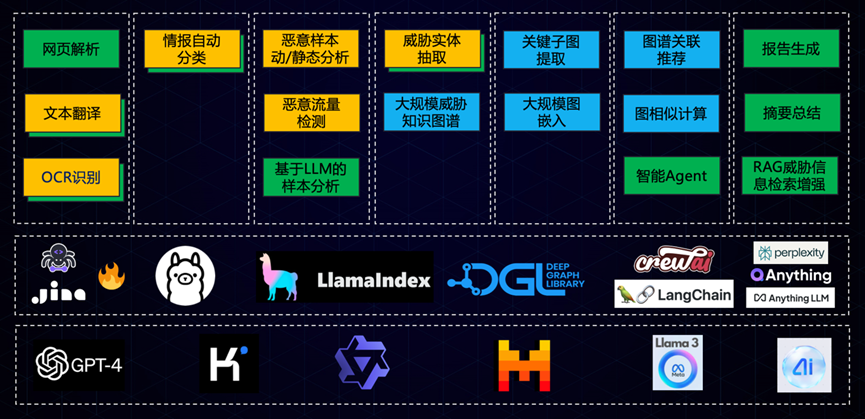
在测试和应用AI技术的过程中我们的用到了一些工具,底层的当然是一些基础的大模型,比如最强大的来自OpenAI公司的闭源模型GPT4,国内比较流行的口碑较好,测试下来效果也确实不错的Kimi和通义千问,还有能力与GPT4可以媲美的开源模型Llama3,Mistral也是一个性能与能力平衡得较好的模型,当然包括奇安信自研的安全大模型QAX-GPT,安全相关的知识与能力更优。
基础模型的能力通过Web界面和API可以直接被使用,做文本分类、模式识别和信息提取。在此之上,有各种应用程序,做数据获取比如ScrapeGraphAI和Jina;各类支持开发框架,比如Ollama、LlamaIndex、LangChain、DIFY;组合起来开发实现很强功能的智能体应用,目前非常好用搜索增强平台,比如Perplexity及国内的秘塔;各类本地RAG工具,比如QAnything、AnythingLLM等。整个基于AI大模型的生态已经快速建立起来。
三、情报运营各环节AI技术的测试应用及体会
1.网页解析
威胁情报的运营开始于信息的收集,来自各种Web页面的开源内容是收集的主要目标。
利用大模型极其强大的文本分析能力,可以方便地实现网页的处理,ScapeGraphAI工具就是这样一个集成了大模型文本分析能力的网页内容爬取工具。这里是一个使用其爬取Mitre网站的APT组织信息页面并转化为结构化数据的例子。
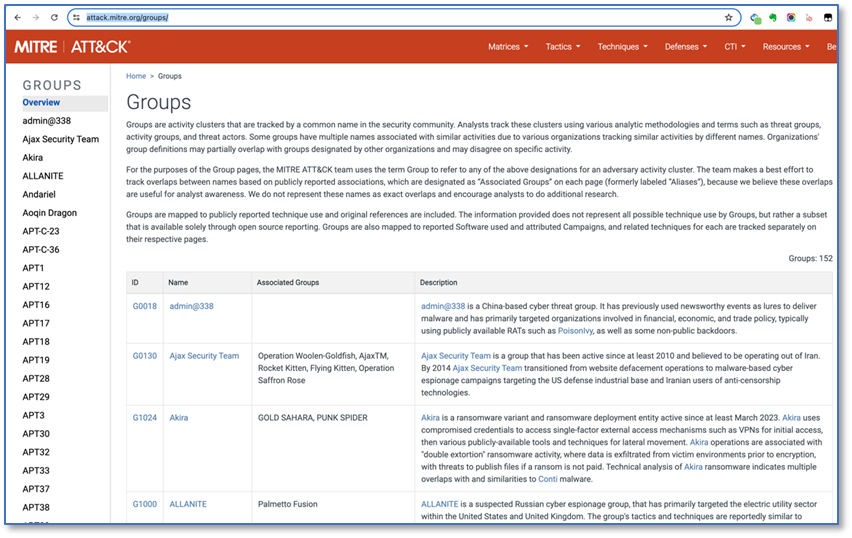
工具充分利用了大模型理解抽象指令和页面解析的能力,处理复杂页面不需要再专门写适配的解析代码,只要描述要求即可,当前这个例子核心AI能力使用了本地部署的llama3模型,其实就当前的任务而言都不需要能力这么强的模型,用更轻量级的Mistral就可以了。
另一个非常有用的工具是jina.ai,这是一个非常方便的把网页内容精减成Markdown格式文本的工具,目前可以免费使用,使用频率上有点限制。它会获取网页,自动去除掉包括广告在内的无关信息,输出一个Markdown格式的文档,这些内容可以被后续的大模型应用所消费。
比如给jina.ai指定下面这样的一个威胁行为体的介绍网页:
https://unit42.paloaltonetworks.com/cve-2024-3400/
jina.ai会输出如下的Markdown文档:
https://r.jina.ai/https://unit42.paloaltonetworks.com/cve-2024-3400/
使用方式非常简单,只要在要处理的网页链接前添加”https://r.jina.ai/”即可。
小结
● 利用大模型的能力进行网页爬取、解析及结构化目前还处于概念验证阶段,实用系统需要较强的工程化能力和强大的算力支持。
● 用于处理复杂网页较为合适,简单网页杀鸡用牛刀。
● 获取页面内容最好用jina这样的核心信息提取服务,后续大模型处理时既可以减少非相关信息的干扰,又能减少Token的消耗。
● 输出后续用于大模型的精减格式化数据非常有用,数据通过API以结构化的方式交换加速成为主流,将来Web页面被人眼访问的比例会越来越低,Web可能慢慢走向消亡。
2.文本翻译
获取到的文本可能是多语言的,当然主要是英文,需要尽可能准确地转换为中文,毕竟我们是中国的安全厂商,接下来看看大模型对于翻译问题最终解决。
例子是一个安全厂商Blog发布的关于某个APT组织活动的介绍文章。我们重点关注两处可以体现翻译能力差距的地方。
1、compromises
2、high-profile

https://www.welivesecurity.com/en/eset-research/moon-backdoors-lunar-landing-diplomatic-missions/
compromise最合适的翻译应该是失陷或侵入,high-profile比较好的翻译应该高关注度、高知名度实体。
没有大模型加持的翻译甚至做到文本通顺都有问题,就象Google Translate那样。
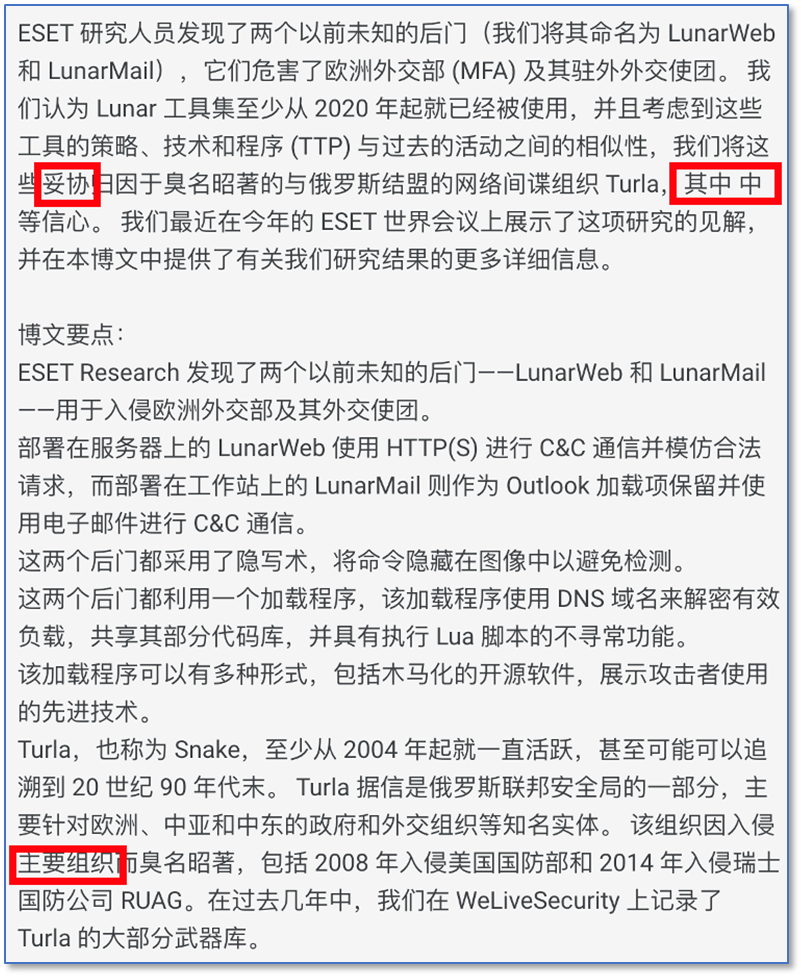
Google Translate,Pormpt:翻译如下文本到中文
GPT4翻译得比较通顺,但对我们关注的概念处理上还谈不上完全正确。

GPT4-1,Pormpt:翻译如下文本到中文
GPT4改进提示词以后的表现有所改善,但Kimi看起来翻译得最贴切。
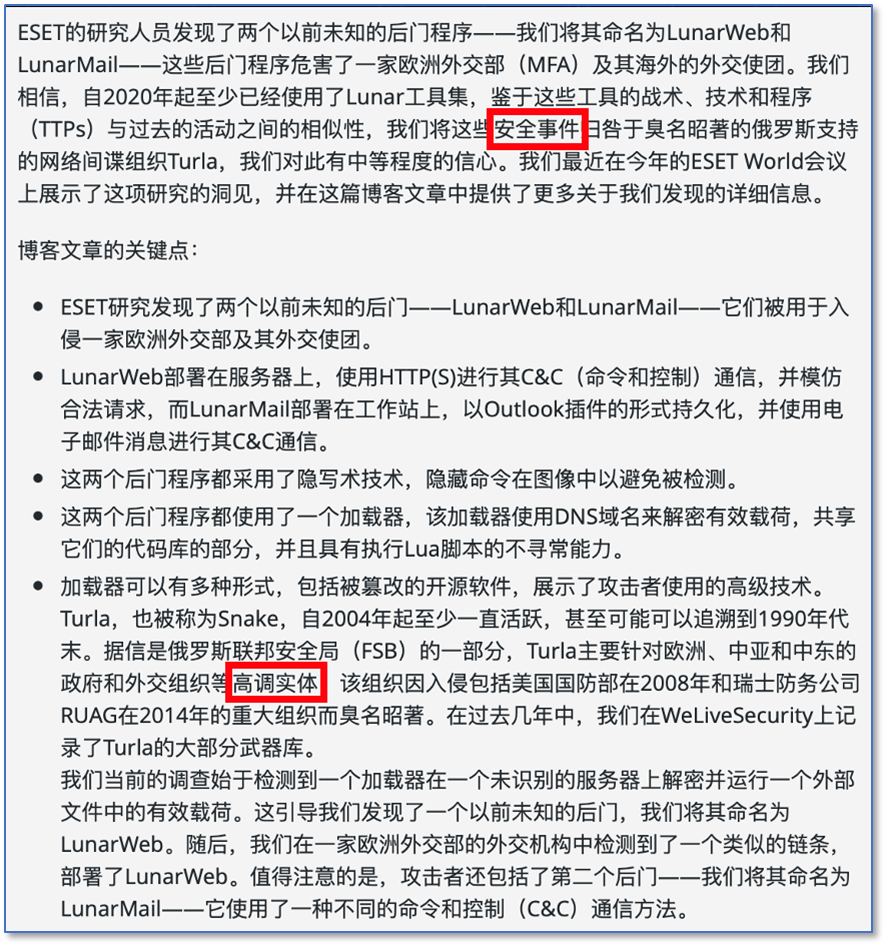
GPT4-2,Prompt:在网络安全语境下,翻译如下文本到中文

Kimi,Prompt:翻译如下文本到中文
小结
● 基于大模型技术的翻译水平碾压传统的翻译技术,大模型对于多语言的掌握已经远超一般的人类,在技术文档的翻译方面代工基本上已经可有可无。
● 就翻译中文的需求而言,中文的大模型翻译效果上优于哪怕是最好的国外大模型,在这点上国内原厂的大模型确实还有些优势。
3.OCR识别
情报信息的来源除了现成的文本,图像视频也应该是另一个重要来源,在这个领域我们也应该积极获取数据,所以OCR的技术也是必备的,而这方面也是大模型所擅长。
这是一个扫描版的SANS培训材料,虽然为PDF文档,但文档的每页都是一张独立的图片。我们尝试通过OCR技术提取图片中的文本与格式。

SANS - 578.4 - Analysis and Dissemination of Intelligence (SANS).pdf
市面上已经有不少基于深度学习的OCR工具,这里展示的Surya工具只是其中一个,对于文档的处理已经比较完善,识别完成以后保持与图像完全一致的观感(右边是源文档页图片,左边是识别后的文本)。但从情报分析需求来看,下面我们来看看大模型在OCR功能上的表现。

用大模型执行识别任务,先尝试GPT4 vision模型,Prompt:
You are provided with one image (see uploaded file). You need directly extract text from image. You need feedback me the extracted text. Keep the paragraph structure from the original image. Remove extra new line characters and keep one new line between each paragraph.
从识别以后输出的格式看,GPT4并没有百分之百的还原,忽略了部分它认为不重要的信息,还会对格式有一些自己的改动,注意上面那7个条目的编号,PPT页脚的内容被忽略了。

GPT4-vision的识别结果
通义千问内容还原度相当高,没有什么自己额外的发挥,包括PPT页的页脚都翻译并呈现了,对段落进行了智能识别与重整。

通义千问的识别结果
Kimi识别出了几乎所有文本内容,但在输出格式上做得很不好,甚至有点错乱,段落的回车位置却严格按照原图,没有做智能化的处理。
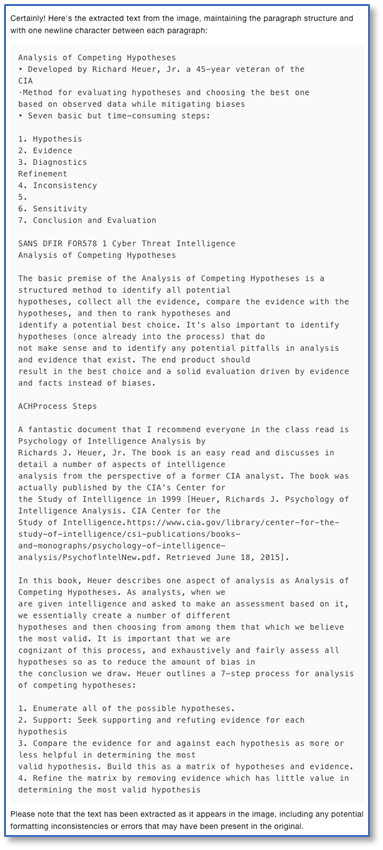
Kimi的识别结果
总体来看通义千问的输出效果最好。
换到对于视频中的文字识别场景,我们先用GPT4 vision处理,Prompt:
You are provided with one image (see uploaded file). You need directly extract text from image. You need feedback me the extracted text.

电影《剑鱼行动》中的场景
可以看到它准确地识别出了核心内容,还自动分割了区域,并给出了自己的看法。

GPT4的识别输出
让Kimi和通义千问来识别一下同样这个图片,结果:通义千问只识别出了部分内容,Kimi识别出了里面大多数文字,但看起来并没有理解里面的内容。但智能化的分析理解就一定好吗?看下面的例子。

这是某年参加的一个安全会议上拍的演讲题目,拍得不清楚不是因为离得远,而是屏幕分辨率实在不高,让GPT来处理这个内容识别。

GPT4的识别输出
注意PPT标题部分,出现了幻觉!大模型知识内置的好处在于能自动弥补上下文,甚至基于此做更深入的研判,但坏处是随意发挥造成误导。对于质量较差的图片,其输出的结果不能完全信任。
通义千问对于这个图片的内容识别比GPT4准确得多:
通义千问的识别输出
小结
● 对于一般印刷文本的识别上,基于神经网络的AI技术已经能够非常准确地完成任务。
● 由于大模型具备的理解能力,它不仅仅简单识别其中包含的文本,还能对场景做出判断,理解其中的意义,对文本的呈现会选择合适的方式,甚至利用模型内部的知识做补齐(不一定好事情)。
● 涉及中文的处理最好还是用国内的大模型,比如通义千问。
大模型的智能可以是你的福音,但也可能成为你的毒药,严肃使用识别出来的信息需要进一步验证。
4.情报自动分类-传统神经网络方法
每天从数千个源收集到数以万计的文本以后,不可能由人工去挨个查看,需要有自动化的系统批量对文本做属性判定并在后续提取关键信息。
在大模型技术前,奇安信人工智能研究院就已经使用神经网络做文本分类,监督式的学习,核心用到了Bert模型。
之前的这个技术流程可以实现分类的粗分类,包括的属性有:是否安全相关、是否安全漏洞相关、 是否恶意软件相关、是否网络犯罪相关、是否APT相关等,效果基本可以接受,能力已经加入了我们的威胁情报运营流程。
然后,大模型出现了,现在的技术都能分辨说话的情绪倾向,高兴还是沮丧,用来分类文本是否与安全相关更是轻而易举。这里的是Kimi对一个网页内容研判的例子,Kimi总结了网页的内容并准确地判定文章与网络安全无关。
https://www.theverge.com/2024/5/20/24161253/scarlett-johansson-openai-altman-legal-action

Kimi的分类判定
另一个介绍Mac平台恶意代码的文章,Kimi非常轻松地对文章内容做的总结和判断。
https://www.intego.com/mac-security-blog/intego-discovers-new-cuckoo-mac-malware-mimicking-homebrew/

Kimi的分类和总结
但是,Kimi对于某些具体的安全属性判定存在问题。文章安全漏洞应该是不相关的,与具体的网络犯罪也不相关,说明Kimi在这些问题的处理上存在缺陷,模型的能力并不完美。

那么我们来试一下其他的模型,Llama3对于我们关心的几个问题是否判定是正确的,体现Llama3有更准确的内在知识。

Llama3模型的属性判定
通义千问与Llama3的判断完全一致,而且正确,在这方面要比Kimi强。

通义千问的属性判定
小结
● 自然语言处理上,大模型对传统NLP形成碾压式优势,以前非常麻烦的流程设计实现,现在你需要提要求就行了。
● 各个模型对情报分类及其他任务上表现还是有区别的,需要仔细评估擅长点,根据不同的任务选择合适的模型,资源丰富的话可以同时使用,采用投票机制。
● 以上这些例子其实只是充分体现了大模型的在文本和图像处理上通用能力,跟具体的安全业务紧密度不太高,下面的任务就与安全领域关系密切了。
5.样本分析
恶意代码分析是整个威胁情报生产过程中的重要环节。绝大多数的文件分析是通过动静态的扫描分析引擎处理的,但对于某些新文件对象可能需要人工的介入,这也会是威胁分配中最耗费时间的环节。如果能让包括大模型大内的AI技术帮助提升分析效率,可以取得非常好的效果。
下面是我们的一些尝试。
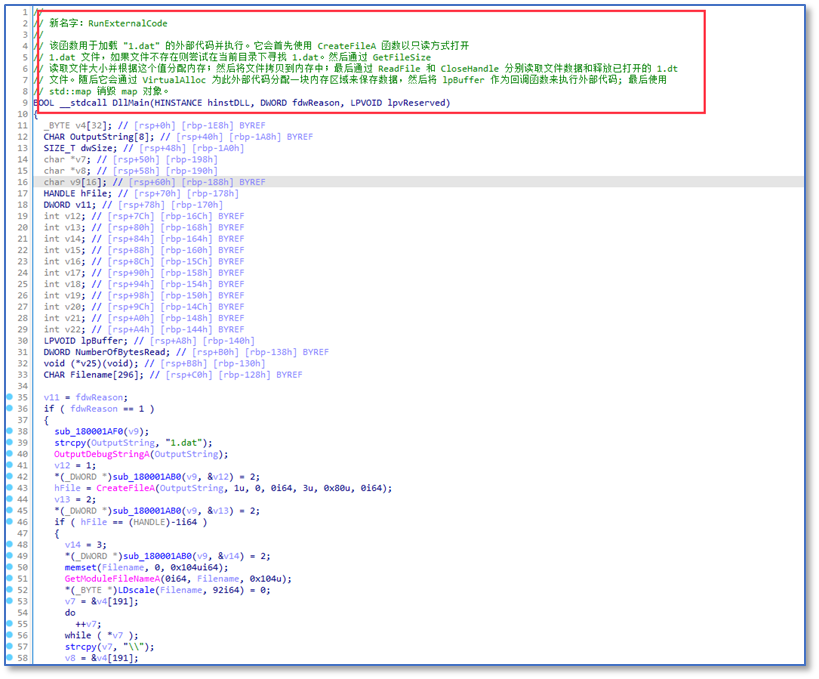
大模型最早的代码分析协助以IDA插件的方式出现,它可以解析IDA中的函数,理解其功能给出可以描述性的函数名。这里是恶意程序分析二进制程序的反汇编代码中一个例子,另外,大模型分析脚本代码,哪怕是混淆后的,也非常得心应手。
前一阵子Google发布了一篇博客文章,介绍其Gemini大模型在分析恶意代码方面的亮眼表现。Gemini 1.5 Pro提供了一次性100万Token的处理能力,分析反汇编和反编译的代码文本,一个中等规模的可执行文件处理时间仅为30-40秒,可以判断是否恶意并给出相应的参考信息,生成相当有用的报告。

From Assistant to Analyst: The Power of Gemini 1.5 Pro for Malware Analysis
https://cloud.google.com/blog/topics/threat-intelligence/gemini-for-malware-analysis
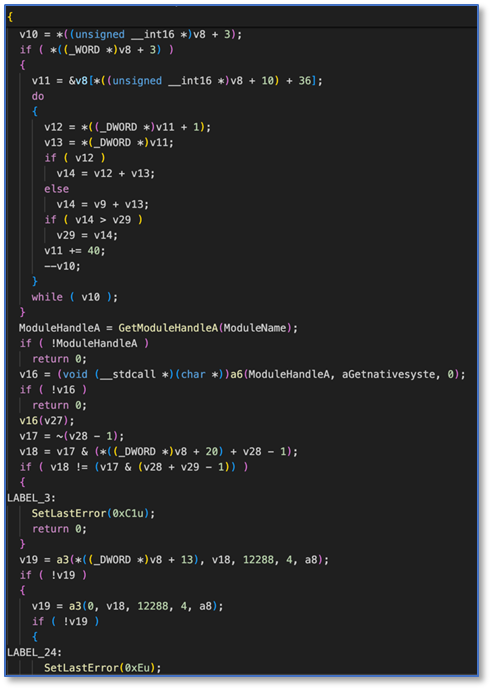
文章中提到了两个样本例子,一个是WannaCry勒索蠕虫病毒的变种,另一个是在VirusTotal 0检出的恶意文件。我们找到那两个样本用IDA生成了对应的反编译C代码。
WannaCry勒索蠕虫样本变种
反编译C代码247K
ed01ebfbc9eb5bbea545af4d01bf5f1071661840480439c6e5babe8e080e41aa_diskpart.c
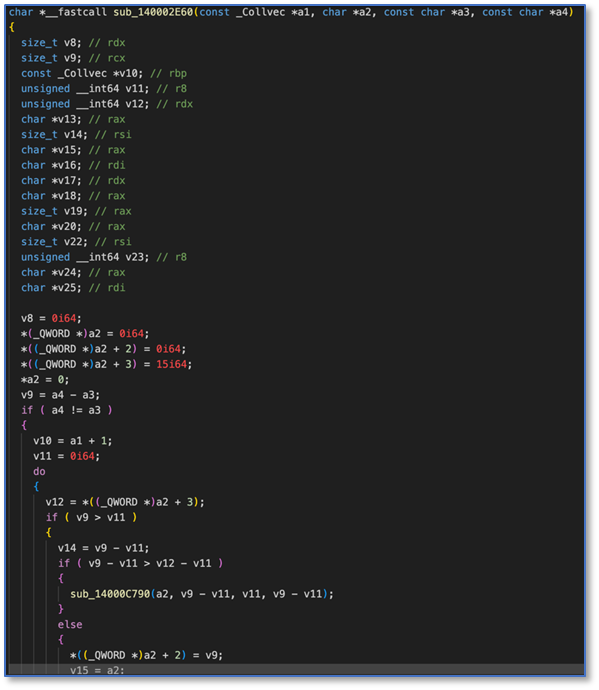
VirusTotal 0检出恶意样本
反编译C代码357K
719b44d93ab39b4fe6113825349addfe5bd411b4d25081916561f9c403599e50_medui.c
下面测试一下其他我们能得到的大模型对于这两个样本的检测分析结果,Prompt直接翻译自Google文章里对应的英文:
充当恶意软件分析师,彻底检查反编译的可执行代码。有条不紊地分解每个步骤,重点关注理解底层逻辑和目标。您的任务是编写详细的摘要,分析代码的行为,查明任何恶意功能。从判定(良性或恶意)开始,然后是活动列表,包括 IOC 列表、创建的文件、注册表项、互斥体、网络活动等。
下面是几个模型对于WannaCry勒索蠕虫变种样本分析结果:

Kimi_1

通义千问_1
Kimi与千问的分析结果表现大体相当,Kimi对于安全方面的信息收集与解读稍好,千问跟随指令的能力更强些,两者都通过模型内部的知识判定样本与WannaCry有关,毕竟那是2017年的事情了。
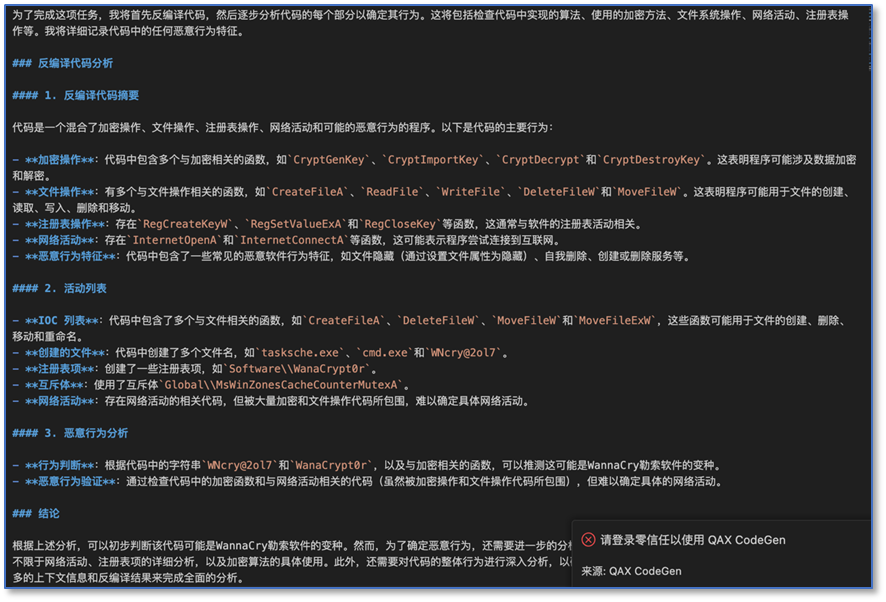
QAX-GPT安全大模型_1
奇安信的安全大模型也分析得到了类似的结果,各个模型都通过发现可疑的加密的操作判断样本偏恶意,内置的知识也提示与WannaCry有关。
第二个VirusTotal上的多病毒引擎的0检出样本对大模型是个高难度的考验,这里是Kimi和千问的表现。

Kimi_2

通义千问_2
总体来看结果并不让人满意,Kimi虽然判定为恶意,但并没有给出靠谱的理由,千问就直接判定来非恶意,不奇怪,毕竟这两个只是并没有根据安全分析需求做过调整的通用模型。之前对于第一个WannaCry变种样本的判定很可能更多依赖已经学习到老知识。
来看一下奇安信安全大模型的分析结果,做出了准确的恶意性判定,并且给出了合理的依据。
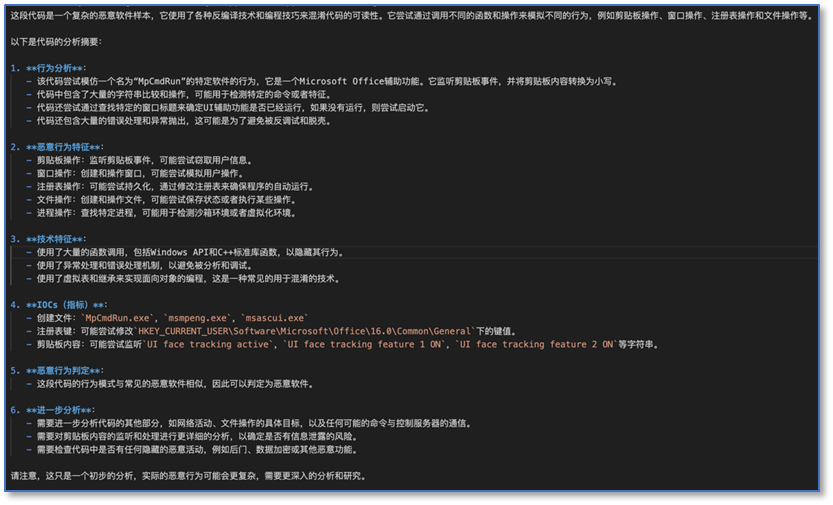
QAX-GPT安全大模型_2
把Google Gemini模型的结果再拿回来做下对比:

Gemini Pro
剪贴板监控、查找进程、大量的字符串操作这些疑似恶意的行为两个模型都发现了,奇安信的模型还发现了查找窗口这种明显恶意的操作,IOC获取方面各有千秋。
小结
● 从分析能力上看,即便是没有专门为恶意代码分析做过优化的通用模型也表现出了一定的恶意代码描述能力,但还远远不够,经过安全分析能力调校的模型会有好得多的表现。
● 上下文窗口的大小非常重要,直接影响一次性处理代码块的大小,影响分析的完整性,从而影响分析的准确度,但目前开放可用的大模型可能由于资源限制大多只能提供最大128K的上下文的窗口,需要通过一些技术方案来解决这个问题。
6.威胁实体抽取
从非结构化的文档里抽取威胁元素实体及关系,这是威胁情报信息收集的关键环节。每天,我们从开源渠道能获取到大量的文章,描述各类新近的攻击活动,包含工具、过程、手法及IOC信息,我们需要自动化的手段来高效完整地提取关注的内容。
以前,比较成熟的方法是基于神经网络的自然语言处理,模型的训练需要海量的数据,算法的开发应用需要相当专业的人员,使用还是比较麻烦,现在有了大模型要方便很多了。
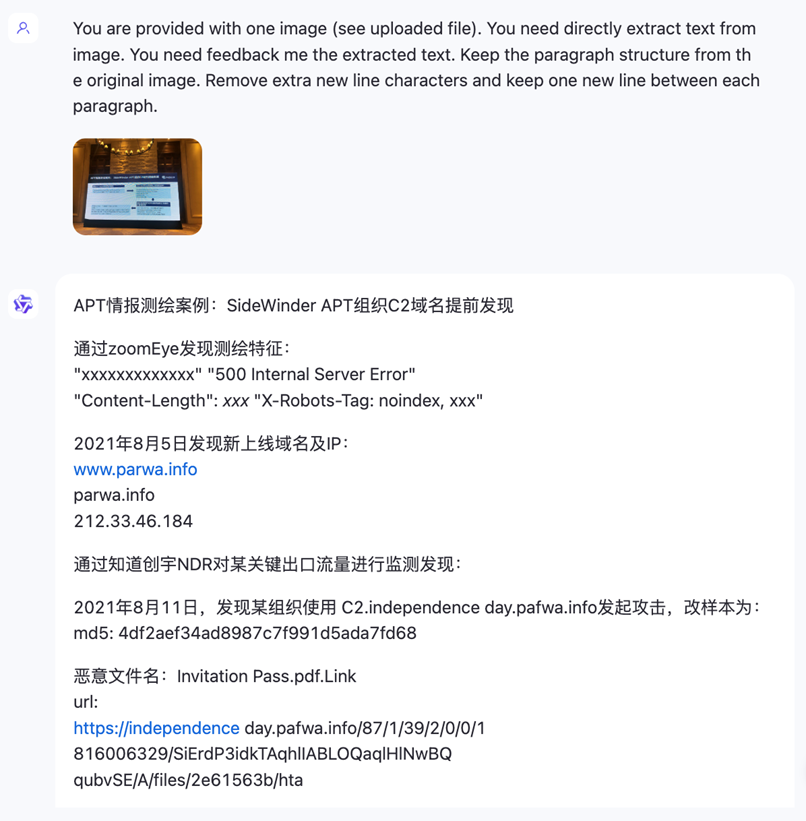
一个威胁行为体活动的文章
现在大多数的威胁活动分析文章会把IOC统一以相对结构化地呈现放在文章末尾。例子里的这个文章包含的IOC类型非常丰富。
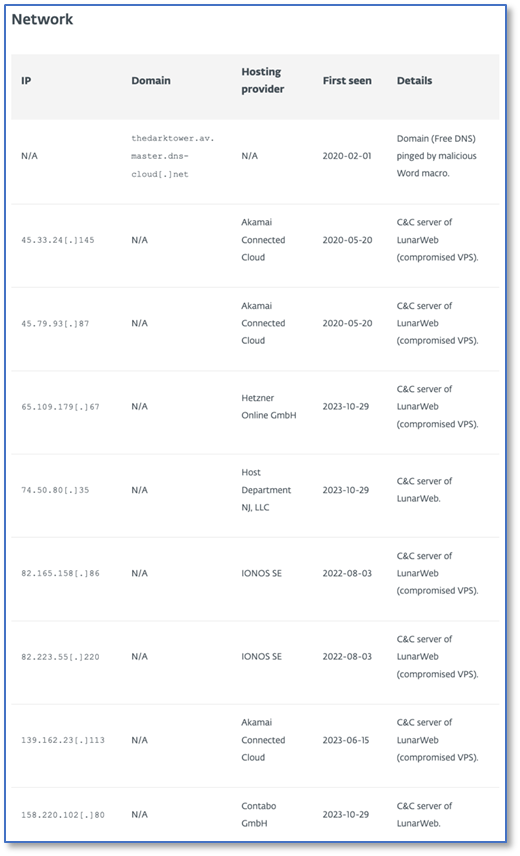
IP列表
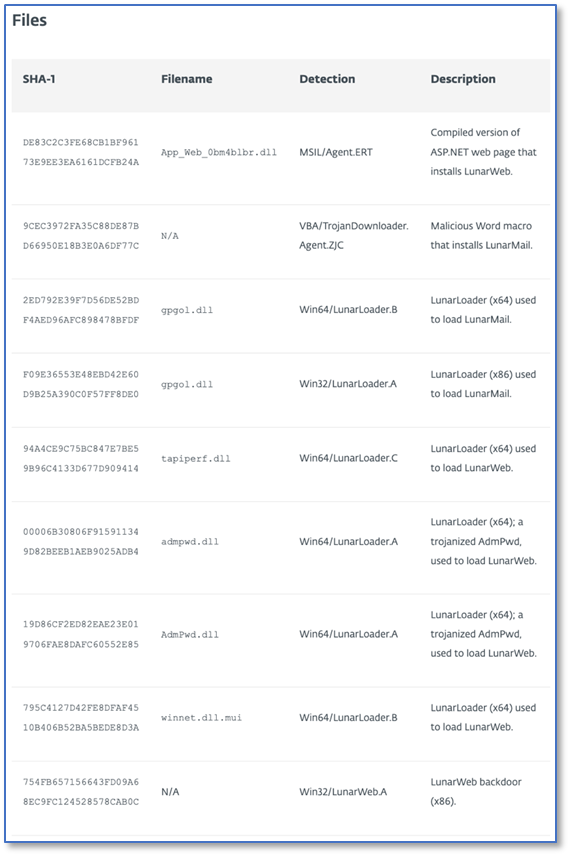
文件Hash列表
我们可以构造Prompt来让大模型来干活,Prompt的设计是一个反复测试优化的过程,根据反馈的结果提要求加限制,最终得到我们想要的信息与格式:
假设你是一位网络安全专家,下面以3个单引号包含的网页链接是一个网络攻击活动的报告,请从中提取如下这些信息。
1. 发布这个报告的厂商。
2. 攻击者的名称,包括可能的别名。
3. 遭受攻击的目标。
4. 攻击目标的行业,需要尽可能详尽。
5. 攻击发生的起始和结束时间。
6. 攻击者所使用的网络基础设施,包括:IP、域名、文件Hash、URL、数字证书、注册表项。
7. 攻击者所使用的软件或工具,需要尽可能详尽。
8. 攻击者所使用的恶意代码家族,需要尽可能详尽。
9. 攻击者所使用的硬件。
10. 攻击者所使用的攻击手法,添加手法对应的ATT&CK技术点ID
11. 如果有相关的信息的话,生成相应的流量检测规则和文件检测规则。
12. 攻击者所使用的安全漏洞,包括ID或漏洞名。
输出中不能包含文本中不存在的对象。
以JSON对象的形式给出结果,全部使用英文字符集,不存在或未知的值设置为空,以方便拷贝的代码格式输出。
‘’"
https://www.welivesecurity.com/en/eset-research/moon-backdoors-lunar-landing-diplomatic-missions/
‘’’
我们调用了Llama3模型执行这个抽取任务,结果看起来很不错,在这个案例里TTP和IOC信息抽取得很完整,而且自动去除了混淆(比如IP字串中的方括号)。
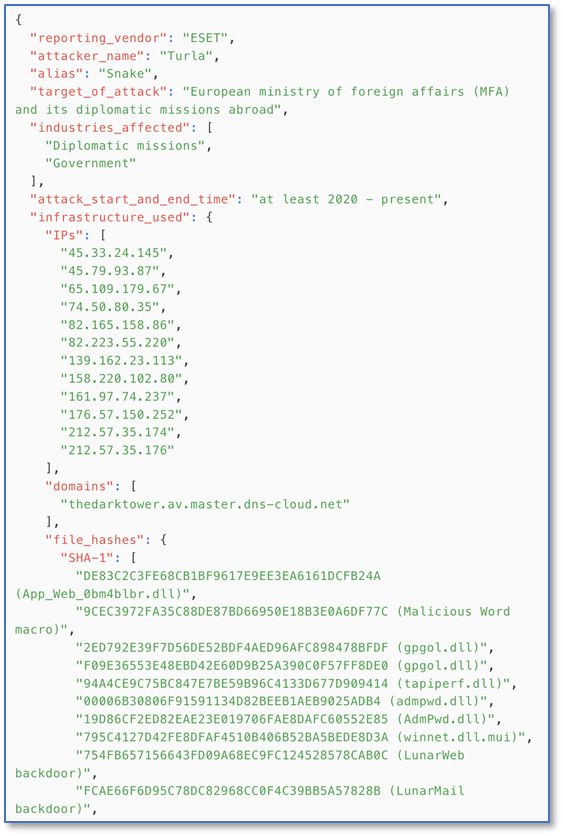
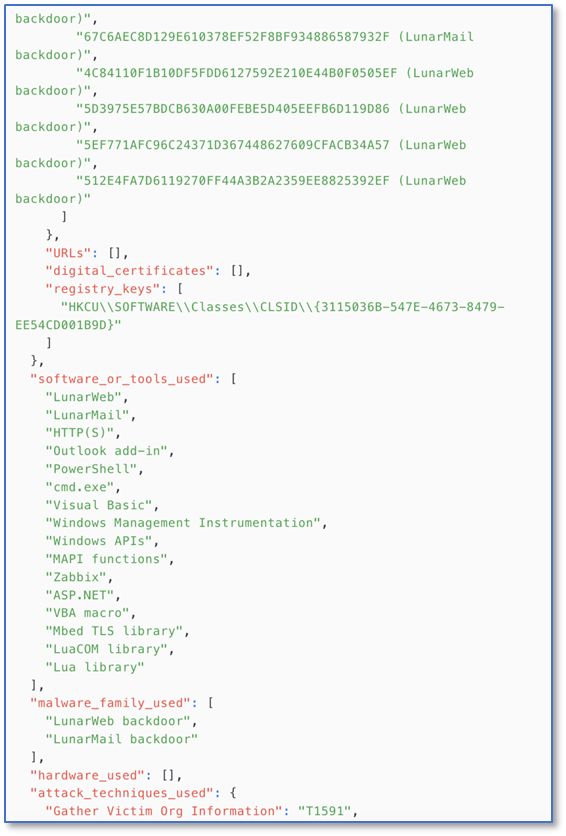
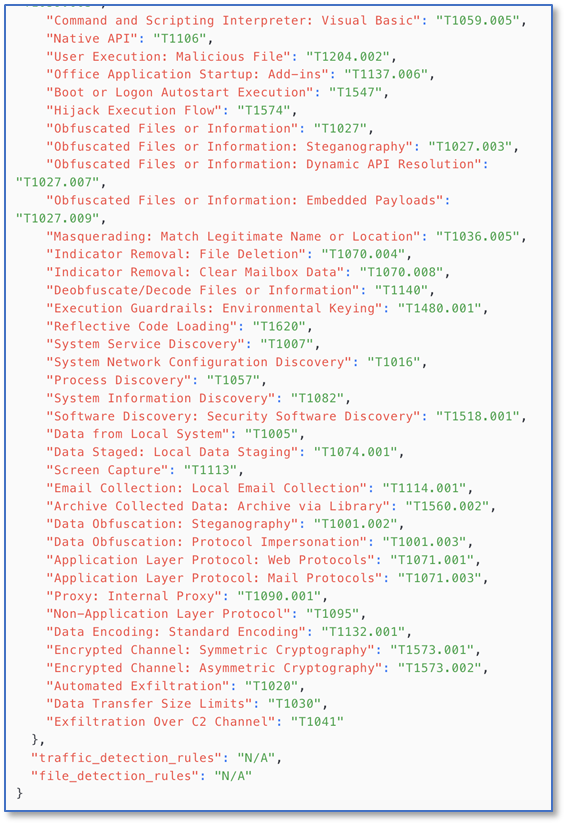
输出的信息需要保持字段和结构的一致,这可以通过给出样例的方式来约定,聪明一些的大模型会严格按给定的样例来输出。

如上面这样,Prompt在原来的基础上增加了输出样式的指定,Llama3这样级别的模型完全可以正确处理。
小结
● 输出样式如果没有明确的示例会非常随机。
● 数据提取不能保证完整,因为有Token窗口限制,并且不一定每次保持一致。
● 虽然有明确要求,但还是可能出现幻觉,后续如要严肃使用需要加入校验环节。
● 模型平台具备处理网页链接的能力会非常方便,而且可能节约Token量。
● 对于链接的爬取不是非常稳定,可能由于网络原因爬取失败。
7.大规模威胁知识图谱的构建和应用
威胁情报的生产涉及海量的多类型数据的分析,典型的有IP、域名、文件Hash、URL、数字证书、邮箱地址等,这些实体之间从安全分析的角度可以被组织成知识图谱。构建完成以后可以作为后台被用来支持各种应用,比如自动化的关联性检索,交互式的实体探索,基于机器学习的图相似分析。
目前,在这个方向上我们还没使用到大模型,但在学术圈已经有了些尝试,以后有可能应用到工业界。
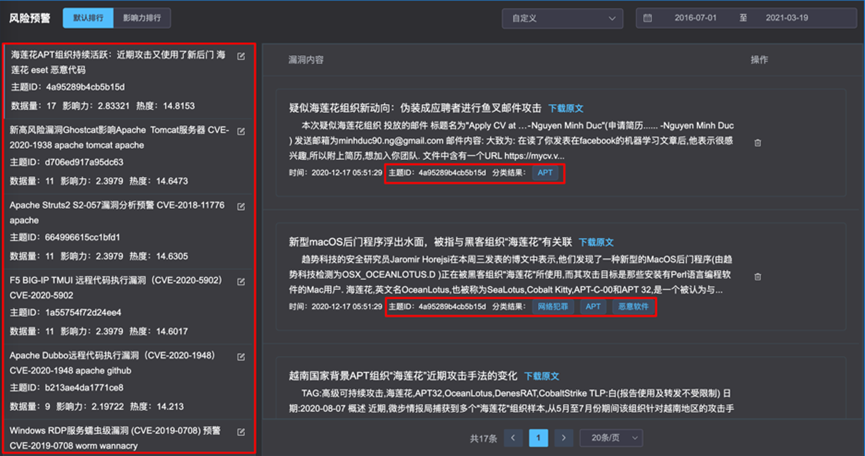
基于已知恶意节点,在我们的数据视野范围内拓展发现在更多的恶意节点,这是我们威胁情报运营中的一个非常核心的需求。利用威胁实体知识图谱,结合机器学习实现可疑的恶意节点推荐是目前我们一个比较成功的实践。
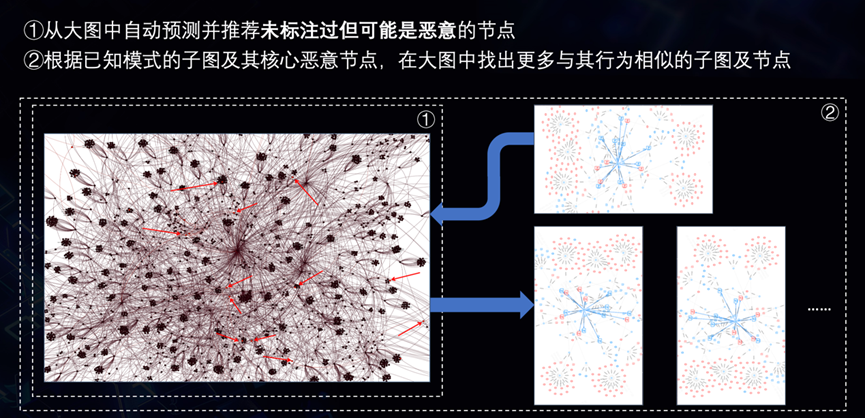
为此,构建了一个目前规模已经达到百亿节点与边的图数据库,节点类型超过20种,经过子图提取和图嵌入训练,图神经网络训练,通过模型输出推荐的疑似恶意节点。
我们构建了一个目前规模已经达到百亿节点与边的图数据库,节点类型超过20种,经过子图提取和图嵌入训练,图神经网络训练,通过模型输出推荐的疑似恶意节点。

基于图谱的推荐已经形成稳定的情报运营流程,每日控制推荐100个未知黑节点提交人工确认,准确率超50%。看起来准确率不高?运营的核心要点在于根据可投入的人工验证资源多少控制每日绝对输出量,只要绝对数量可以做到日清,50%的准确率是完全可接受的。
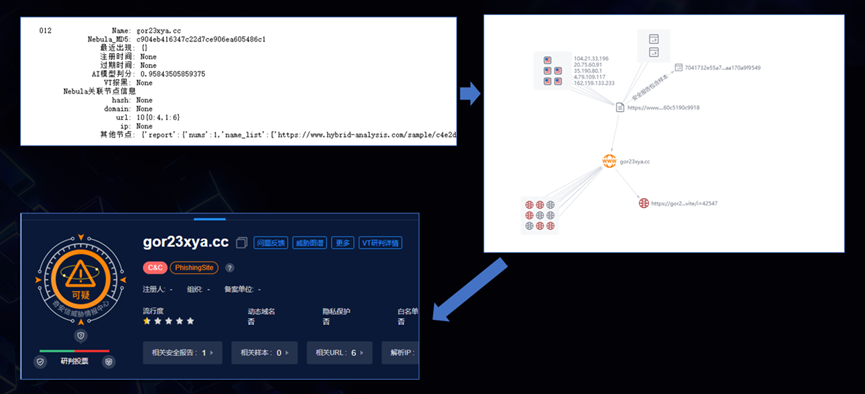
一个推荐系统输出的可疑,最终确认恶意的例子
8.智能Agent
以上各环节中采用的AI及大模型技术主要用于一些单个的点。接下来我们说一下,当前最热的基于大模型的智能体技术。
要完成一个相对复杂的任务,需要把各个流程串联起来,目前已经出现大量的Agent,在安全方面的应用只是其中一个小角而已。下面这个问答应用就是奇安信内部一个比较大的Agent项目,界面上看起来简单,但后台的流程其实相当复杂,从意图识别,安全检测过滤,到后台各类数据源的对接,要实现好的反馈效果与性能,需要大量的工程化设计与测试调试。
https://qgpt.qianxin.com/chat
目前,我们还在探索其他威胁分析类的场景。在Agent方向,我们可以做的事情还很多,比如情报的更自动化的关联分析。

10.报告生成
威胁情报生产出来以后,除了将数据提供给检测类设备消费,还有给安全人员看的。
在这方面,模型的文本总结和摘要能力可以被充分利用起来。奇安信的Alpha平台上对于一个域名的研判页面,罗列了各类维度的信息。
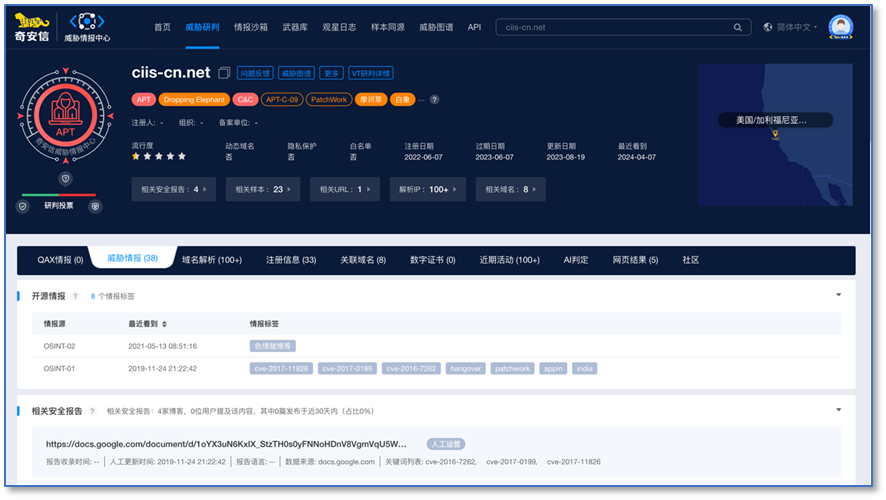
其实这样的信息陈列对一般的用户来说结论还不够直接。生成一个人读的总结报告是更友好的界面,怎么做最容易?
最简单的方案,整合一个数据接口出来,包含了一系列结构化的核心信息,前面定制一个Prompt,交给大模型整合生成总结就行了,本质上一个最简化的RAG,结果远好于一般的安全分析人员人工撰写。
Prompt加部分数据的例子:
“假设你是一个网络安全专家,以下这个json对象是关于一个网站域名(data.whois_abstract.domain)相关的情况。首先,请输出域名相关的基本信息,包括:注册信息(data.domain_attribute.createdate,data.domain_attribute.updatedate,expiratedate),是否为动态域名(data.domain_attribute.is_dynamic),是否为白名单域名(data.domain_attribute.in_whitelist),当前绑定过的域名(data.subdomain.examples),当前的标签信息(data.domain_tag.examples)。
然后,请基于如下这些维度信息对域名是否倾向于恶意做判定:
⁃ 标签信息(data.domain_tag.examples)
⁃ 域名属性(data.domain_attribute.malicious)
⁃ 域名相关的文件样本(data.domain_try_connect.examples)
是否恶意的结论写在输出的前部,并给出相应的理由。如果存在域名相关的文件样本(data.domain_try_connect.examples),请罗列出来详细的信息。最后,给出相关的参考资料链接(data.report.examples),展示具体链接文本,并下载解析链接对应的内容并做总结。 不要提json里的具体字段名。请全部用中文答复。
{
"status": 10000,
"message": "执行成功",
"data": {
"domain_attribute": {
"popular": "",
"createdate": "2022-06-07 15:10:40",
"updatedate": "2023-08-19 19:03:10",
"expiratedate": "2023-06-07 15:10:40",
"last_seen": "2024-03-21 19:07:20",
"is_dynamic": false,
“
我们来看看各个模型对于一个域名进行总结的输出表现,它们的输入从Prompt到数据都是完全一样的。

Kimi
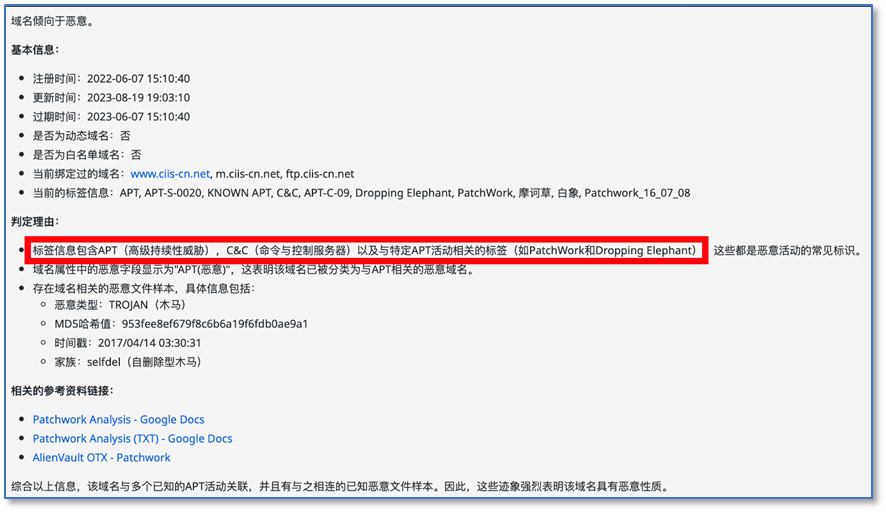
GPT-4
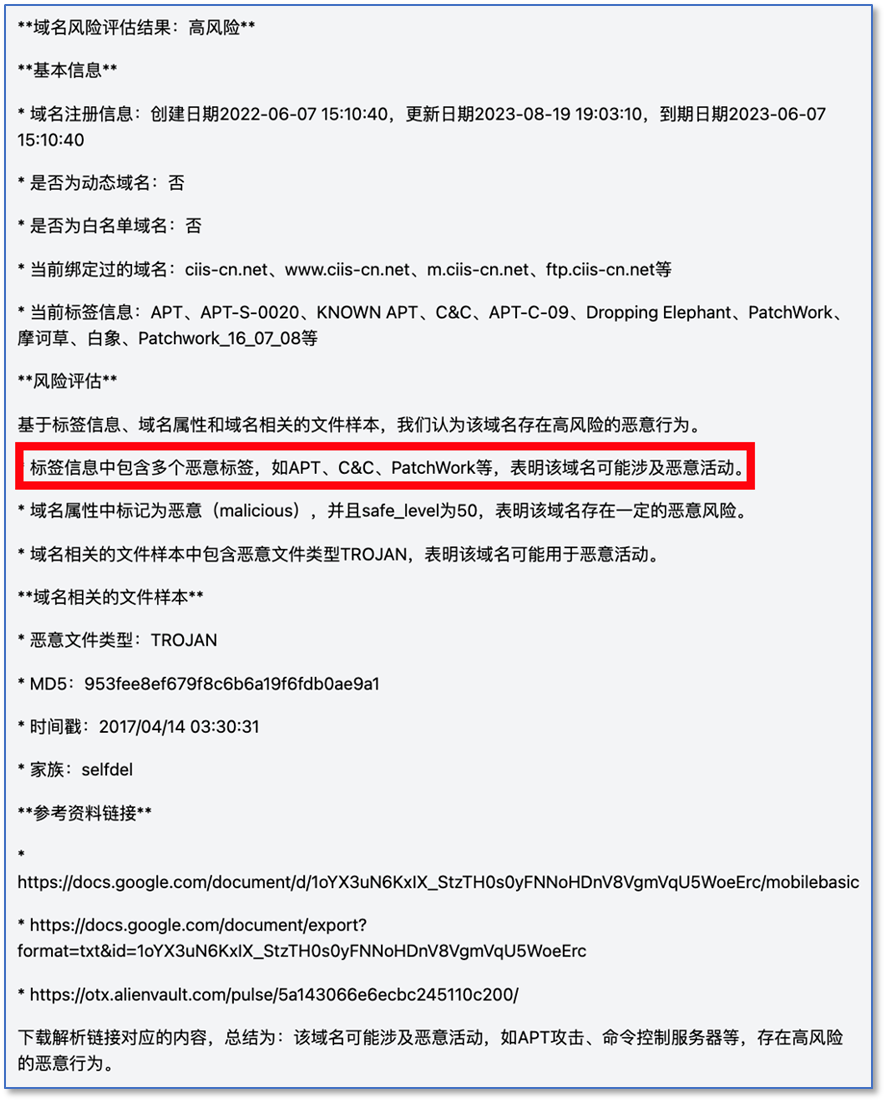
Llama3 70B
结果看起来差不多?其实,从一些细节可以显示模型在安全分析方面一些能力区别。在判定理由部分,Kimi只是简单罗列了发现的标签;Llama3则能把真正影响判定结果的标签给挑出来,显然GPT4更强。GPT4还能对标签做出分类,理解APT C&C是什么意思,哪些标签是APT组织名,这是模型内置知识与推理能力的综合体现。
另一个文件样本的沙箱日志的例子。在行为活动的结构化数据前添加一个简单的Prompt,交给大模型总结,我们可以对其自动生成人读报告。
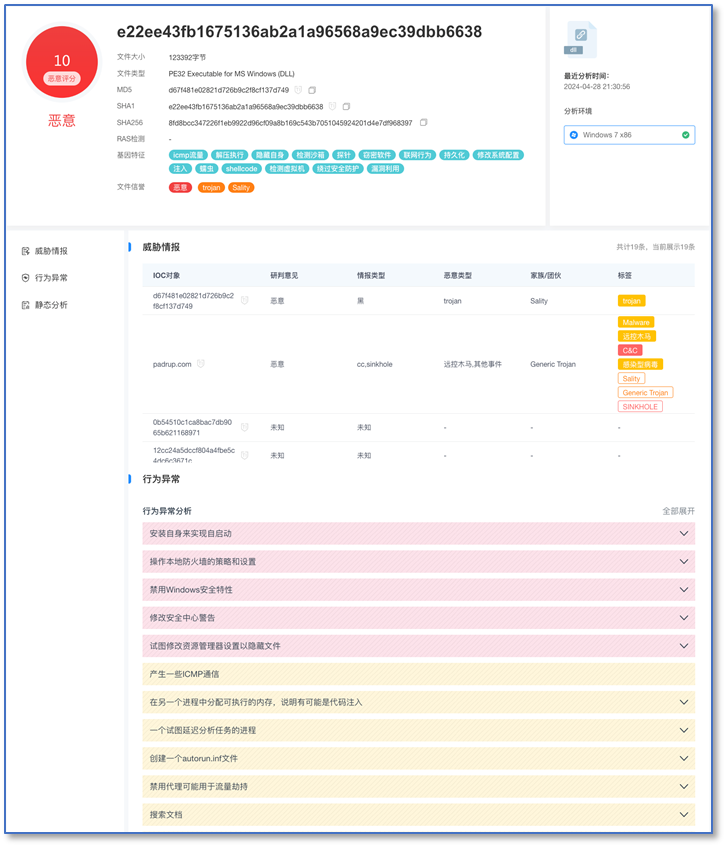
一个样本的沙箱行为展示
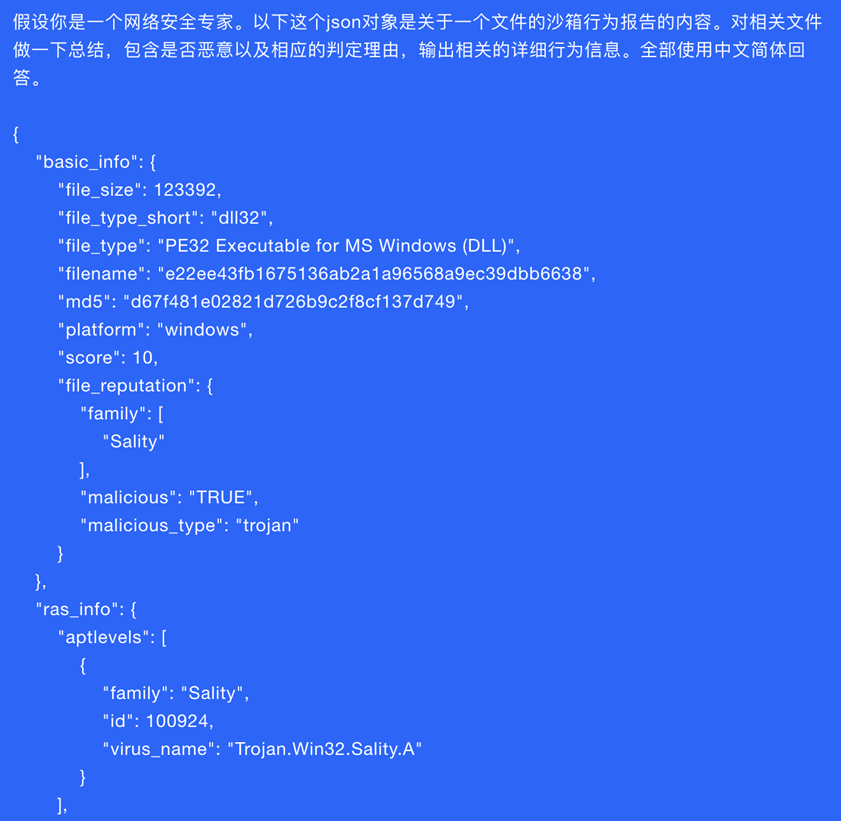
对应的Prompt及数据
与域名分析报告类似,给定部分样本的关键信息以后, 大模型自动生成人读的报告质量基本可用。

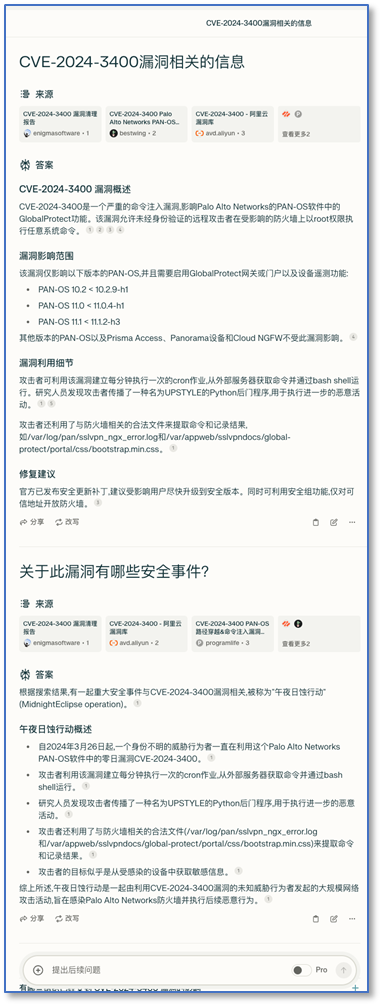
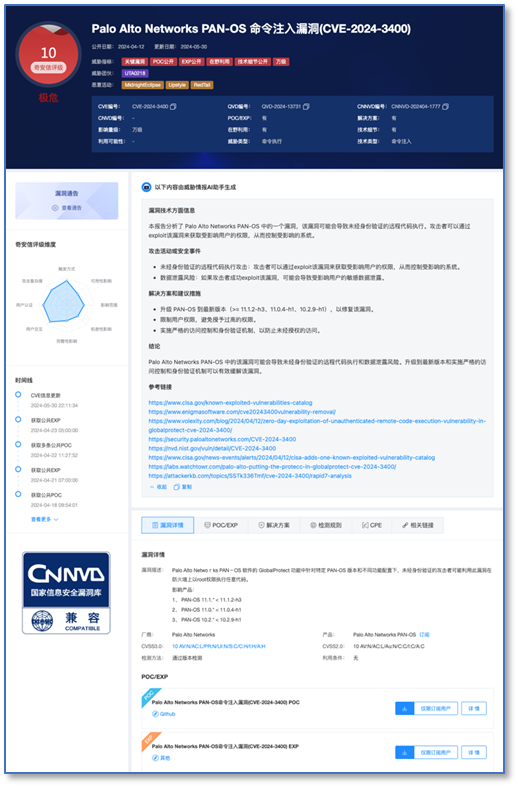
对于漏洞信息,我们也可以更方便地基于多源信息进行总结,整合了搜索最新信息与AI总结能力的新搜索引擎,对传统漏洞库是降维打击般的存在。国外的应用有Perplexity,国内的则有秘塔,也有一些开源项目也实现了类似的功能,甚至可以本地部署,缺点是调用搜索API成本并不低,也不能大规模地对外提供服务。
除了总结一些技术层面的描述,还可以通过搜索整理相关的安全事件,提示漏洞在现实世界里所导致的实际风险,对用户采取应对措施的优先级排序非常有指导意义。

秘塔
https://metaso.cn/
Perplexity
https://www.perplexity.ai/
其实,使用Kimi处理漏洞相关的参考信息链接也能达到类似效果。当然,漏洞相关的结构化关键信息还是需要的,通过API集成到组织内部的漏洞运营流程里。

简单的Prompt加上相关的网页链接

Kimi会爬取链接的内容并做总结输出
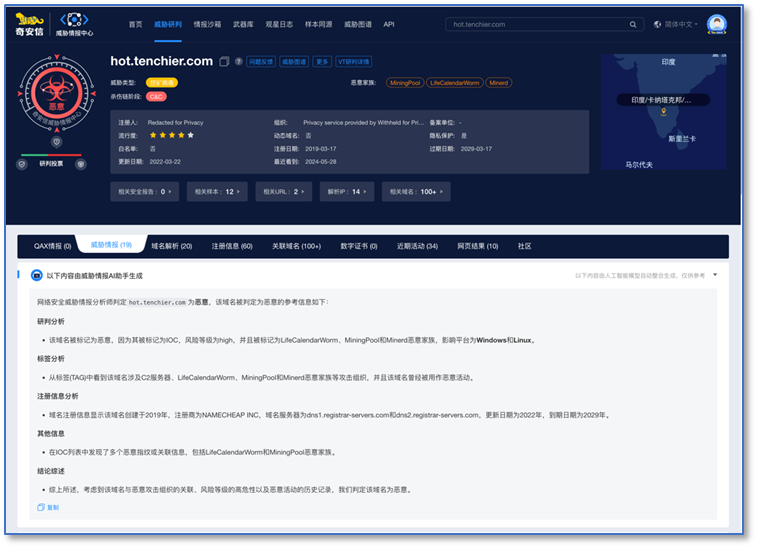
我们已经将上述这些对威胁实体的大模型总结,集成到奇安信的Alpha威胁研判分析平台,这对用户的使用体验是个很大的提升。从现在开始,用户只要登录访问奇安信威胁分析研判平台,直接就能看到集成的AI总结。
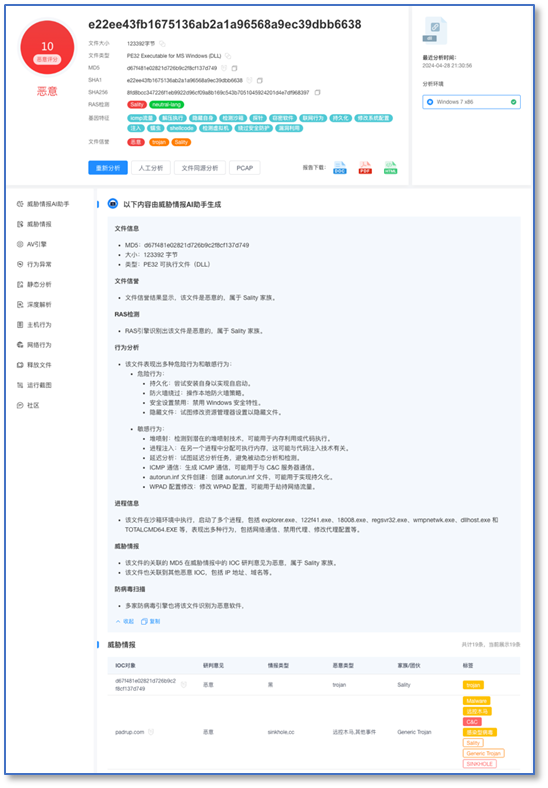
11.RAG威胁信息检索增强
最后,说一下目前也非常热门的RAG,这是结合大模型的生成能力与本地或新近内容提供诸如问答服务的系统,通过外挂知识的方式解决私有数据和实时新信息的检索,这个能力在网络安全领域也是真实的需求。
事实上,大模型在安全检测和分析系统中的最早应用,比如SOC、NDR等系统,其核心就是本地的RAG系统,为用户提供自然语言的问答接口,大模型分析用户需求的任务类型,基于模型自身的知识或转化为内部各类数据源的查询获取相关信息,最后,大模型对用于答复的信息生成人读的答复,这也是加强安全设备使用检验的最基本应用。
在威胁情报运营输出方向,我们也做了些实践。这里的例子是尝试把一个国外的威胁百科网站转化本地可问答查阅的系统。
Malpedia是一个网络威胁信息的百科,包含15000多个文章的链接,提供链接下载。可以尝试将其指向的内容RAG化,支持基于自然语言的搜索和关联。
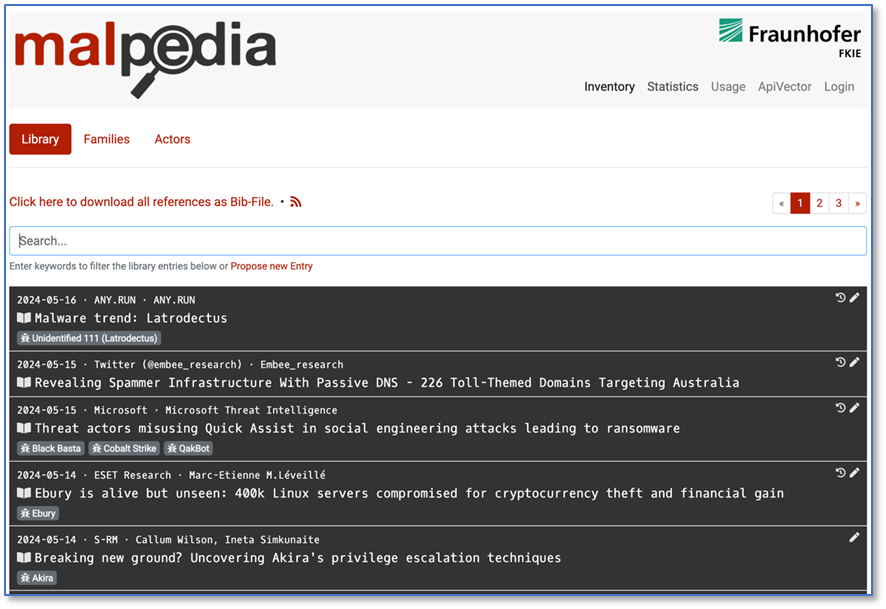
https://malpedia.caad.fkie.fraunhofer.de/library
我们尝试了QAnything工具,把从链接指向的内容通过jina.ai平台爬取下来导入本地知识库,但可能限于机器的性能,效果并不太理想。
不过,目前类似的RAG工具越来越多,也越来越成熟。如果我们采用更好的硬件,配合更完善的软件,应该可以得到非常好的结果,这也是迟早的事。
四、实践总结
1.大模型作为通用智力引擎几乎可以赋能所有的任务,组织需要在内部和外部构建这样的智力基础设施。本地部署需要一定的硬件资源投入,主要应对处理私有数据的场景,效费比未必高;如果只是处理公开非敏感数据,建议直接使用各大模型厂商的云端服务,效果可以,费用其实也不高。
2.大模型技术可以极大提升安全分析及威胁情报运营的效率,降低运营流程开发人员的能力要求,以较小的人工投入获得更好的结果,在各环节中综合使用AI技术可以提升50%的效率。
3.长上下文窗口能力很关键,对于文本内容的总结、恶意代码的分析、漏洞的挖掘、RAG功能有决定性的影响,需要持续开发相关的技术。
4.大模型自身的能力强弱会极大影响提示词工程和产品化的工作量,背后的道理很简单,让聪明人干活你只要给出目标,不需要指导怎么做,但对能力不强的下属你甚至得指导具体的执行步骤。
各个大模型在不同的任务中各有擅长的表现,目前还没发现全能的模型同时满足我们的所有需求:
◆ Kimi的中文总结与指令跟随能力强,上下文Token空间大,能直接处理链接爬取,通义千问综合能力差不多。
◆ GPT4的知识和推理能力最强,中文处理尚可。
◆ llama3推理能力接近GPT4,中文处理能力差(原始模型),但最大的优势作为开源模型可本地部署。
◆ 特定的安全分析任务,比如恶意代码分析、攻击检测,通用模型的能力还是不够,需要专用的安全分析模型。
基于大模型技术的各类包装应用,RAG、LangChain、DIFY、Agent等等风起云涌,很多时候并不需要自己开发,直接使用改进即可。
本地RAG系统涉及很多工程细节及原始数据的质量,要出好的效果比较有挑战。
警惕幻觉,哪怕是RAG和基于限定内容的总结,也可能出现,基于GenAI的判定对外执行操作需非常谨慎。
关于作者
汪列军 虎符智库专家 关注恶意代码分析、APT攻击事件与团伙的跟踪与挖掘,实现安全威胁情报的运营与产品化。
声明:本文来自虎符智库,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
