作者简介:鲍明广,中通快递安全研发工程师,目前负责中通安全风控领域的开发和机器学习在安全领域的应用,专注于数据科学、机器学习和大数据数据栈的应用。
1 背景
随着信息技术的高速发展,信息安全问题已经成为最受关注的焦点之一,而帐号安全又是引发企业安全问题的起始点,往往危害巨大。中通作为一家集快递、物流、电商等业务于一体的大型集团公司,在内部,每天有几十万员工在使用各类信息系统, 帐号管理难度非常大,存在大量的帐号违规行为,如帐号共用、混用、借用等,特别是部分高权限的用户帐号,一旦发生意外可能导致不可估量的损失。在外部,帐号安全领域的问题也频频发生,比如帐号爆破、撞库、帐号被盗、弱密码等,这些都时刻要求我们建立一个更加可靠的帐号安全体系。
2 帐号登录特点
中通帐号登录的方式相对丰富,帐号登录设备类型即为常见的终端(见图1), 内部不同的应用允许登录的方式可能不同。

图1.登陆方式和设备类型
下面简单介绍其中几种登录方式:
- 静态密码登录:内部仅少量特殊应用允许使用静态密码登录。
- 数字动态码登录: 内部全部应用允许使用中通宝盒动态码登录。
- session登录: web应用在sso已登录情况下的直接通过。
- 二维码/推送登录: web以及原生应用使用中通宝盒登录。
终端设备类型是常见的四种: web、iOS、Android和windows客户端,内部部分应用提供windows客户端。
3 帐号风控架构
帐号风控主要包括三个模块(如图2所示):设备指纹、异地登录检测、用户登录行为分析。设备指纹模块主要用于对用户设备进行跟踪,检验用户是否在其常用设备上登录。异地登录检测模块用来判断用户是否在其常在地登录,这里我们对用户登录地点进行精细分析以便作为帐号安全判断的重要参考依据。用户登录行为分析模块主要用来做用户帐号登录画像以识别异常登录情形。
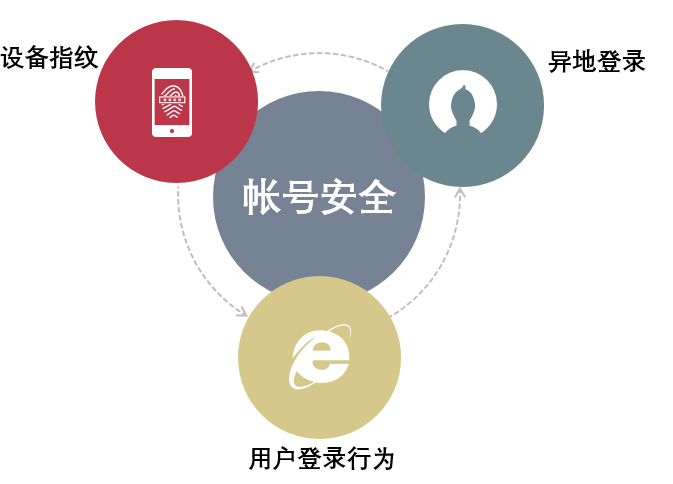
图2.帐号风控模块
3.1 设备指纹模块
设备指纹作为用户识别的一种技术手段已有很长的一段发展历史,从获取数据的手段来说主要包括主动式、被动式和混合的方式。主动式的方法是通过SDK(App)/JS主动收集设备特征信息,根据算法生成唯一的设备指纹ID。这种方式的优点是准确率相对较高,但因隐私和安全性而受限制,而且随着时间的推移,在数据隐私安全保护越来越严格的大趋势下限制可能会越来越多。该方式的另一个缺点是不能跨app和浏览器识别,而且相关设备数据易被篡改。
被动式的方法是基于通信OSI协议栈、网络状态特征等识别(数据报文),结合机器学习算法来对设备进行跟踪和标记。该方式仅收集用户允许的公开信息,存在技术壁垒,部分领域准确率较高,但从业界实践来看,其准确度受到时间维度限制。
混合式的方法在识别率、应用场景和对抗性三方面平衡了主动式和被动式的方法。
由于登录设备类型不同,所以相关设备指纹采集维度也各不相同,下面对浏览器、iOS、Android类型分别阐述。图3展示了浏览器相关追踪技术的历史发展过程。

图3. 浏览器指纹技术
1.0时代核心技术是服务器在客户端设置标识。evercookie将cookie等信息通过多种机制保存到系统多个地方,即使用户清除某处的cookie,依然能够获取其他地方的数据从而进行恢复。
2.0 技术单浏览器指纹。Canvas指纹利用相同的HTML5 canvas元素绘制操作,在不同操作系统、不同浏览器上,产生的图片内容不完全相同。在支持canva的浏览器中,可以使用基于OpenGL ES 2.0的api在canvas中进行2D和3D渲染。WebGL用着色器绘制出一个对象并把该图像转换成base64编码,并枚举出WebGL的性能和扩张添加到base64编码中。目前WebGL基本是一个相对稳定的标准;现阶段除了opera不支持以外,各主流浏览器的新版本都是支持的。2.0时代还有很多综合类指数指纹,原理就是采集很多数据字段生成指纹。比较知名的项目如图3所示。
2.5 时代增加了os和硬件级的特征,这类特征在跨浏览器上更可靠稳定。比如Graphic Card、CPU、Audio Context等。值得一提的是HTML5 AudioContext API可提供一个音频播放的实时频域和时域分析来创建音频可视化。方法如下(如图4):首先用OscilatorNode生成音频信息流(三角波),AnalyserNode进行FFT变换,转换成频域,计算SHA1值作为指纹,音频输出到音频设备之前进行清除,用户无感知;然后用OscilatorNode生成音频信息流(正弦波)DynamicsCompressorNode(调节声音信号处理模块)进行动态压缩处理,计算MD5值。和canvas原理很相似,频域在不同浏览器中是不同的,该特征受到浏览器的影响因而不能完全反映出声卡特征,适用于单浏览器指纹;但峰值和它们对应的频率,在跨浏览器上是相对稳定的。然后将峰值和对应的频率映射成一个列表来作为浏览器特征。事实上我们在查找设备指纹相关专利的时候的确也有利用audio做设备指纹的。
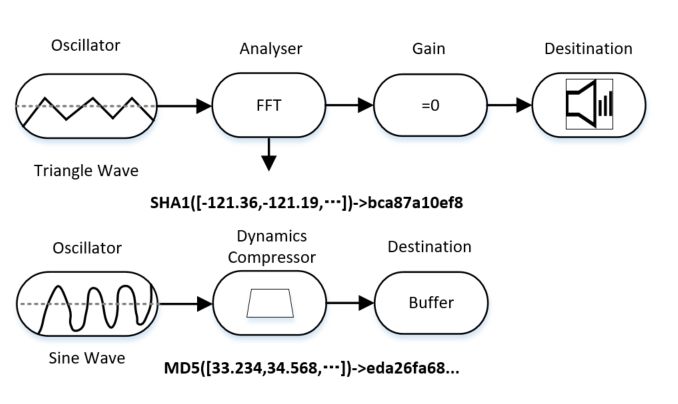
图4. AudioContext指纹
3.0 时代UnifyID从用户无意识的日常行为中收集数据,包括走路的方式、所在的地方、周围的设备等,结合机器学习方法,提取出每个人独一无二的特征进行身份识别,实现安全性和用户体验的平衡。
在web端我们结合了1.0-2.5时代的特点,基于Fingerprintjs2利用js采取多维度的浏览器设备数据,如OS信息、Platform、Timezone、Language、Screen_x、Screen_y、位置信息、浏览器WebGL(Hash后)、EverCookie 、Java_Enabled、FileSystem_Access、Popup_blocker(是否开启窗口拦截器)、User-agent、Plugins Count、Cookie Enabled、Canvas、Plugins and plugins version等信息。
在iOS端我们采集了MAC、IDFA(identifier For Identifier)、IDFV(identifier For Vendor)等信息。
在Android端我们采集了Deviceid(Android系统为开发者提供的用于标识手机设备的串号,根据不同的手机设备返回IMEI,MEID或者ESN码)、IMEI (国际移动设备识别码)、MEID/ESN (CDMA)、MAC ADDRESS(wifi or 蓝牙)、Sim Serial Number(ICCID)、IMSI(国际移动用户识别码)、ANDROID_ID等信息。值得一提的是仍然有方法可以拿到端上的MAC地址,如果能够拿到MAC地址则可以将其作为一个非常稳定的信息。
Windows客户端由于是自有的客户端,我们会采集内部生成的唯一标识符。
我们会在用户初始登录的时候在多个位置植入一个唯一标识符,后面用户实时登录的时候我们会去做唯一标识符匹配,如果匹配成功则目标设备选取成功;否则我们要去用户历史设备指纹库去匹配相关信息以召回相关指纹信息,由于相关维度信息变动可能频繁,我们利用一种指纹相似性模型计算相似度程度是否大于阈值(具体流程见图5)。
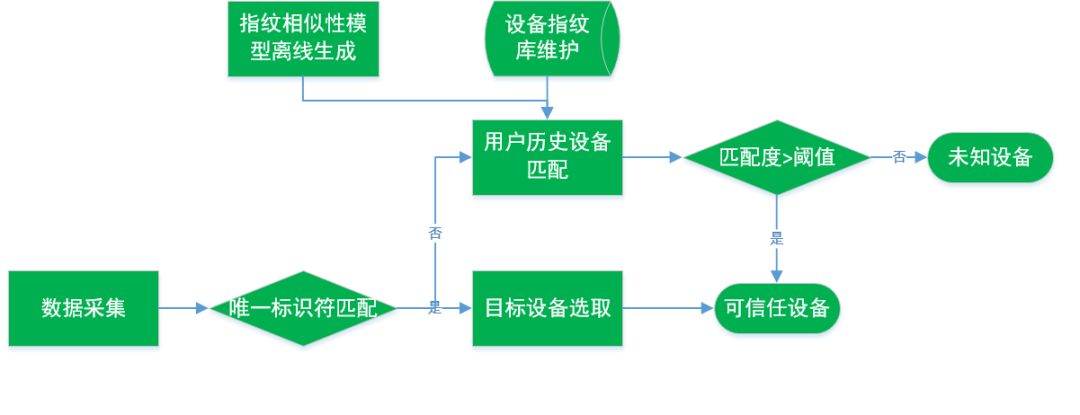
图5. 设备指纹匹配流程
下面介绍指纹相似性模型离线生成计算的算法,主要基于局部敏感哈希(Locality Sensitive Hashing,LSH)算法, 其是谷歌用来衡量文本相似度的一种算法。它的主要作用就是从海量的数据中挖掘出相似的数据,可以具体应用到文本相似度检测、网页搜索等领域,由于其对局部的变动不敏感所以可以用来应对设备维度的微小变化而保持较小变动(某种程度上这也是个文本相似度检测的问题,采集的数据维度变动前后文本相似性)。

图6. simhash算法原理
算法的具体原理可以参考谷歌的原始论文,这里我们将浏览器指纹采集的各个维度看做feature,然后根据各个feature的重要性赋予weight 最后生成fingerprint。算法结果的稳定性和weight关联很大,weight越大的变动对最终的算法结果的影响越大。按照作者Charikar在论文中阐述的,64位simhash,海明距离在3以内的文本都可以认为是近重复文本。当然,具体数值可以结合具体业务以及经验值来确定。
3.2 用户异地登录检测模块
用户异地登录的检测基于用户常在地位置的计算,然后每次实时和其常在地比较,常在地位置的计算可以归为地理位置聚类问题。目前聚类的方法很多,我们用户常在地检测主要选取了基于密度的DBSCAN算法和基于划分的Kmeans算法结合来处理。
1. 基于划分的Kmeans算法
一种典型的划分聚类算法,它用一个聚类的中心来代表一个簇,即在迭代过程中选择的聚点不一定是聚类中的一个点。其目的是使各个簇(共k个)中的数据点与所在簇质心的误差平方和SSE(Sum of Squared Error)达到最小,这也是评价Kmeans算法最后聚类效果的评价标准。
2. 基于密度的DBSCAN算法
全称Density-based spatial clustering of applications with noise, DBSCAN是具有过滤噪声作用的基于密度的空间聚类算法,可以根据用户指定的参数radius(邻域半径)和minPts(密度域值),对数据集合进行自动聚类。其最大的特点就是算法本身可以自己决定聚类的数量而不像Kmeans算法需要人工指定聚类的数目,可以发现任意形状的类簇,同时可以过滤噪声点和低密度区域。
在DBSCAN算法中将数据点分为一下三类:
核心点:在半径eps内含有超过minPts数目的点
边界点:在半径eps内点的数量小于minPts,但是落在核心点的邻域内
噪音点:既不是核心点也不是边界点的点
这里有两个模型超参数,一个是半径eps,另一个是指定的数目minPts。
算法的过程描述如下:
输入:初始数据集合、邻域半径(radius)和密度域值(minPts)
建立聚类集合:分别以每个对象为考察对象判断其是否为核心对象,如果是核心对象则建立聚类集合
合并集合:根据密度相连的原则合并聚类集合
输出:输出整理合并达到密度域值要求的集合
由于Kmeans算法对数据噪声特别敏感,而DBSCAN算法输出的结果是一个个类簇,因此可以根据用户过去一段时间登录或者主动上报地理位置时采集的经纬度信息,先应用DBSCAN算法计算出用户数据的相关类簇,然后在此基础上对形成的一个个类簇再次应用Kmeans(设k=1)找出类簇中心,作为最终的用户常在地。图7即为根据该算法过程得到的结果,图中红色的小点是用户历史地理位置,其构成一个集群(DBSCAN算法已过滤掉偶然在某地登录时产生的噪音点),黑色五角星位置是Kmeans算法在集群上进行k=1的聚类时得到的中心,其代表该集群,即为一个用户常在登录地理位置,同一个用户可能有多个登录常在地。
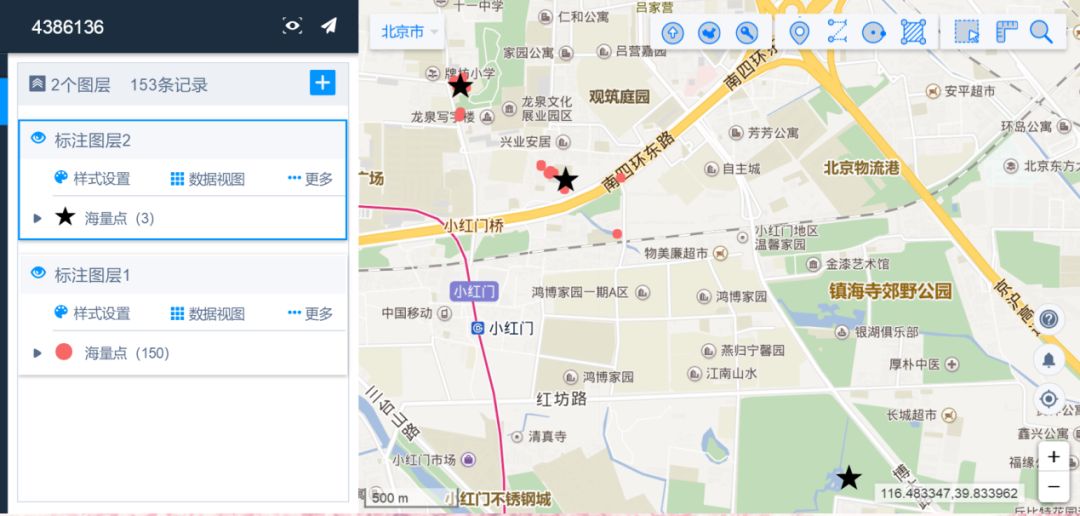
图7. 某用户常在地结果展示
3.3 用户登录行为分析模块
用户登录行为分析模块,我们着眼于用户行为的模式,然后应用算法和统计分析来检测那些模式中有意义的登录异常,目前我们分析模块主要包括用户登录频率、ip登录频率、是否换手机号、是否修改密码、登录时间和方式的分布、登录失败次数等信息(如图8所示)。
我们会给予每个维度一定分数,当其偏离该用户历史行为模式的时候我们会基于其相应惩罚。用户历史行为特征我们通过spark离线计算出来存储到redis缓存以做相应实时计算。
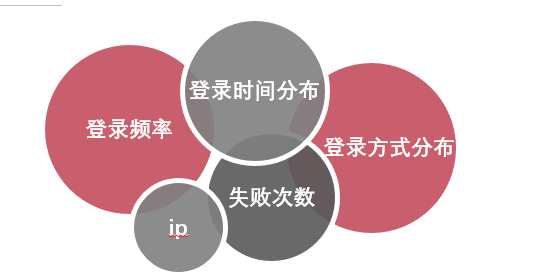
图8. 用户行为分析维度信息
4 工程实践
我们工程实践分为两部分,实时和离线计算,主要的计算架构如图9所示。
实时部分用户登录信息数据实时写入kafka以待帐号风控检测,经过spark streaming实时计算用户设备指纹维度、异地登录检测维度、用户行为分析维度的得分,然后返回最终风控结果。
离线部分会实时用flume从kafka中把所有登录信息拉去到hdfs以备离线分析计算使用。
利用spark、hive进行相关特征和模型的计算存到mysql、redis、hive中以供后续分析。jupyter notebook、zepplin、hue等提供了方便的交互式分析工具,可以更方便的探索数据、发现异常。另外由于离线特征计算需要每隔一段时间更新一次,且我们的场景相对简单,采用了azkaban作为调度工具。
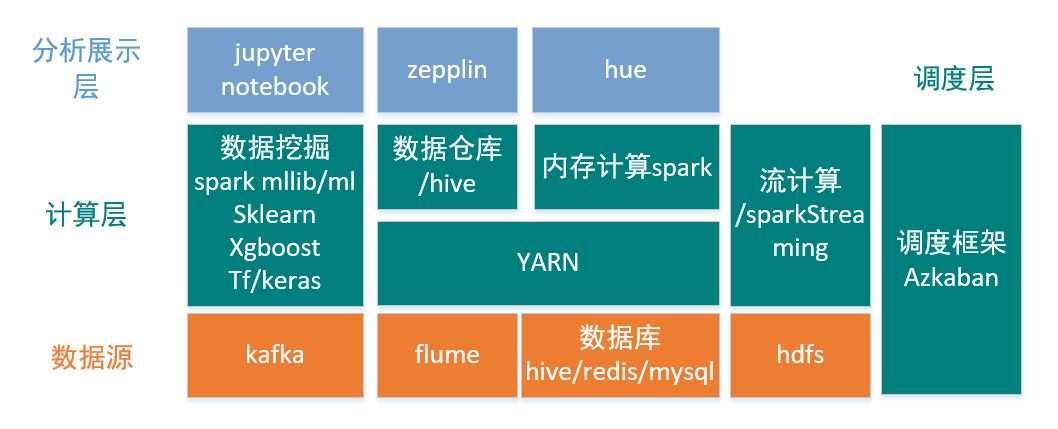
图9. 计算架构图
5 总结和展望
总体来说,我们帐号风控综合了多个维度信息,利用信息采集、大数据和算法的优势保障用户帐号安全。 值得一提的是在做该项目时,我们利用过机器学习技术进行异常流量检测,而且取得了不错的结果,由于考虑到异常流量对我们的最终的帐号安全没有影响且缺乏真实环境中的标签数据,故而这项工作会单独进行深入研究,主要思路有传统的机器学习方式和深度学习的方式。
传统的机器学习方式会通过特征工程的方式提取一些特征,这里应用到异常流量检测里面有基于char的n-gram、tf-idf等,然后将特征放入传统机器学习模型比如LR、Xgboost、SVM以及一些组合模型中,利用这种思路我们在搜集到的100w+(4w+的黑样本)的异常流量样本中得到99.9%的测试准确率和0.92+的auc,但由于众所周知的泛化原因,该成果在真实环境的表现可能没有这么好,因为两者的数据分布可能是有差异的。深度学习的思路我们也尝试了CNN和RNN的模型。CNN做异常流量分析思路来源于CNN做文本分类。RNN做异常流量检测的思路主要是可以把异常流量的payload看成一个字符序列,RNN天然适合对序列建模。我们初步实验结果是深度学习模型没有传统机器学习模型效果好,当然模型还是可以调优的。安全领域应用机器学习很多场景下也需要有标签数据的支持,怎么摆脱对大量标签数据的依赖是机器学习领域正在热门研究的问题,期望这方面我们会有越来越多的突破。
参考资料:
- Charikar(2002).Similarity estimation techniques from rounding algorithms.
- M Ester.A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise
- Yoon Kim. Convolutional Neural Networks for Sentence Classification
团队介绍
中通信息安全团队是一个年轻、向上、踏实以及为梦想而奋斗的大家庭,我们的目标是构建一个基于海量数据的全自动信息安全智能感知响应系统及管理运营平台。我们致力于支撑中通快递集团生态链全线业务(快递、快运、电商、传媒、金融、航空等)的安全发展。我们的技术栈紧跟业界发展,前有 React、Vue,后到 Golang、Hadoop、Spark、TiDB、AI 等。全球日均件量最大快递公司的数据规模也将是一个非常大的挑战。我们关注的方向除了国内一线互联网公司外,也关注 Google、Facebook、Amazon 等在基础安全、数据安全等方面的实践。
声明:本文来自中通安全应急响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
