
原文标题:CKGFuzzer: LLM-Based Fuzz Driver Generation Enhanced By Code Knowledge Graph
原文作者:徐晗翔,马威(共同第一作者),周婷,赵彦杰(通讯作者),陈凯,胡强,刘杨,王浩宇
作者单位:华中科技大学Security PRIDE团队(Security, Privacy, and Dependability in Emerging Software Systems),新加坡管理大学,东京大学,南洋理工大学
原文地址:https://arxiv.org/abs/2411.11532 已被CCF-A类会议ICSE 2025, Industry Challenge Track接收,并获得Best Paper Award
通讯作者主页:https://yanjiezhao96.github.io/
研究背景
模糊测试是发掘软件漏洞、提升软件可靠性的关键技术。然而,传统模糊测试依赖于手动编写的fuzz driver,这一过程不仅耗时,且在面对复杂软件系统时易遗漏测试场景,从而限制了测试效率与效果。
近年来,大型语言模型 (LLM) 在代码生成方面表现出显著潜力,为自动化fuzz driver 生成带来了新的机遇。尽管已有研究利用 LLM 自动生成fuzz driver (例如 PromptFuzz),但这些方法面临显著挑战。首先,LLM往往缺乏对代码库深层上下文及复杂API交互的全面理解。要生成有效的fuzz driver,不仅需要理解单个函数,更要把握多个API间的调用关系和特定使用场景,这要求对系统代码行为有深刻洞察。其次,生成高质量的fuzz driver需要大量关于目标库的外部知识,例如API的具体用法、约束条件、预期输入/输出以及依赖关系,而这些知识通常散布在代码库各处、文档或隐式约定中。LLM有限的上下文窗口(context length)难以容纳如此庞大的信息量,导致其无法获取生成高质量driver 所需的全面信息。因此,仅依赖LLM自身的内部知识和有限的输入提示,难以保证所生成driver的质量与代码覆盖率。此外,有效的输入种子生成与精确的崩溃原因分析,同样是当前自动化fuzzing流程中需要解决的关键技术挑战。
研究的核心问题在于:如何克服LLM在理解代码全局上下文和获取必要外部知识方面的局限(如上下文长度限制和对外部知识的依赖),从而有效利用其代码生成能力,自动化地生成高质量、高覆盖率的fuzz driver,并构建完整的端到端自动化模糊测试流程。
方法框架
为应对上述挑战,本文提出了 CKGFuzzer,一种基于代码知识图谱(CKG)增强的检索增强生成(RAG)和Multi-LLMs系统的自动化模糊测试方法。
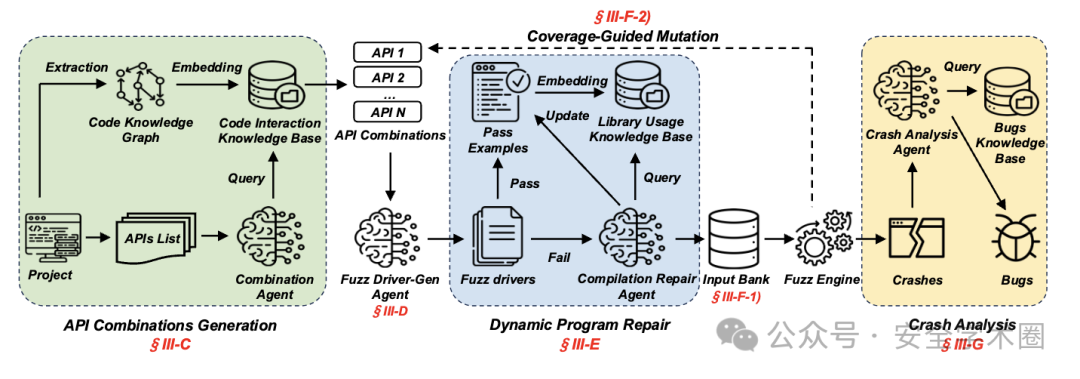
代码知识图谱构建
通过静态分析工具 (如 Tree-sitter, CodeQL) 及过程间程序分析,从目标代码库提取函数、文件结构、调用关系等信息。
结合LLM生成的代码摘要与API文档,构建包含代码实体(节点)及其交互、调用关系(边)的知识图谱。
代码知识图谱为LLM提供了执行任务所需的丰富代码上下文信息。
LLM驱动的自动化Fuzzing流程
输入种子初始化: 基于对fuzz driver数据流的分析,运用LLM 生成高质量的初始输入种子。
覆盖率引导的变异: 监控代码覆盖率,当覆盖增长停滞时,识别低覆盖区域的API,并指导LLM对当前API组合进行变异,以探索新的执行路径。

API 组合生成:通过查询CKG,基于函数调用关系和功能相似性,智能选取相关的API组合作为fuzz driver的测试目标。

Fuzz Driver生成:利用LLM结合角色提示 (role-prompt) 策略及CKG提供的上下文,为选定的API组合生成fuzz driver代码。
动态程序修复:鉴于LLM生成的代码常含编译错误,本文设计了一个基于RAG的修复智能体,利用包含正确API用法(源自OSS-Fuzz样本,头文件和库测试程序) 且动态更新的知识库,自动修正fuzz driver中的编译错误。
模糊测试循环:
崩溃分析:采用LLM的链式思考推理能力,并结合CWE漏洞知识库,自动分析fuzzing 过程中产生的程序崩溃,区分API误用与库本身缺陷。
CKGFuzzer实现了从fuzz driver生成、修复、种子初始化、变异到崩溃分析的自动化流程。
实验结果
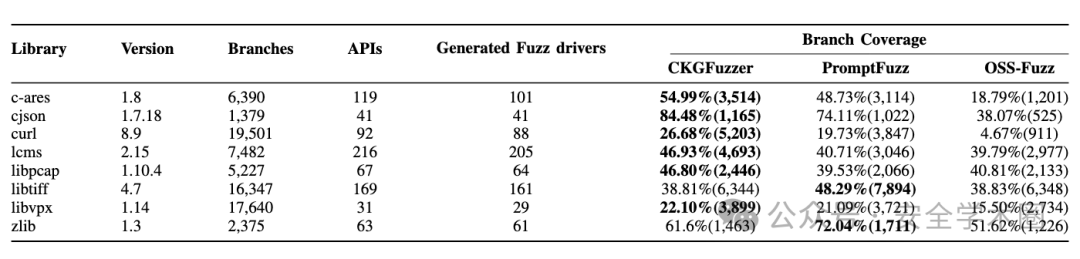
本文在8个广泛使用的开源C语言库上对CKGFuzzer进行了评估,并与现有代表性技术(OSS-Fuzz, PromptFuzz)进行了比较。
代码覆盖率(RQ1):在8个目标库中,CKGFuzzer在6个库上取得了最高的代码覆盖率。相较于基线方法,CKGFuzzer平均将代码覆盖率提升了8.73%。
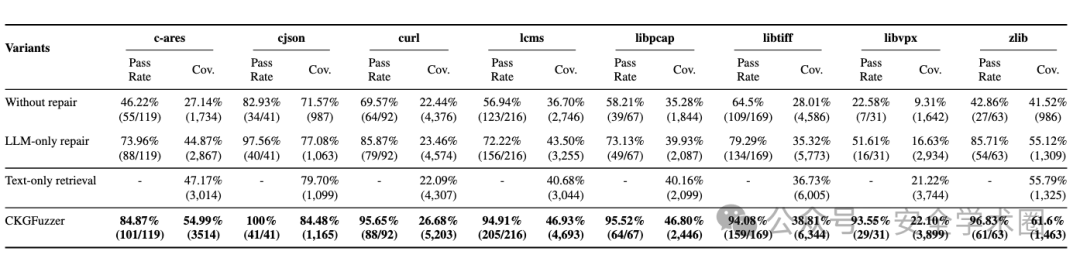
组件有效性(RQ2):
CKG的作用:基于CKG的API组合生成策略显著优于仅依赖文本信息的检索方法。
动态修复的有效性:动态修复模块将fuzz driver的编译成功率从 57.39%(无修复)提升至93.99%,显著优于仅依赖LLM的修复(77.19%),并对提升最终覆盖率有积极作用。
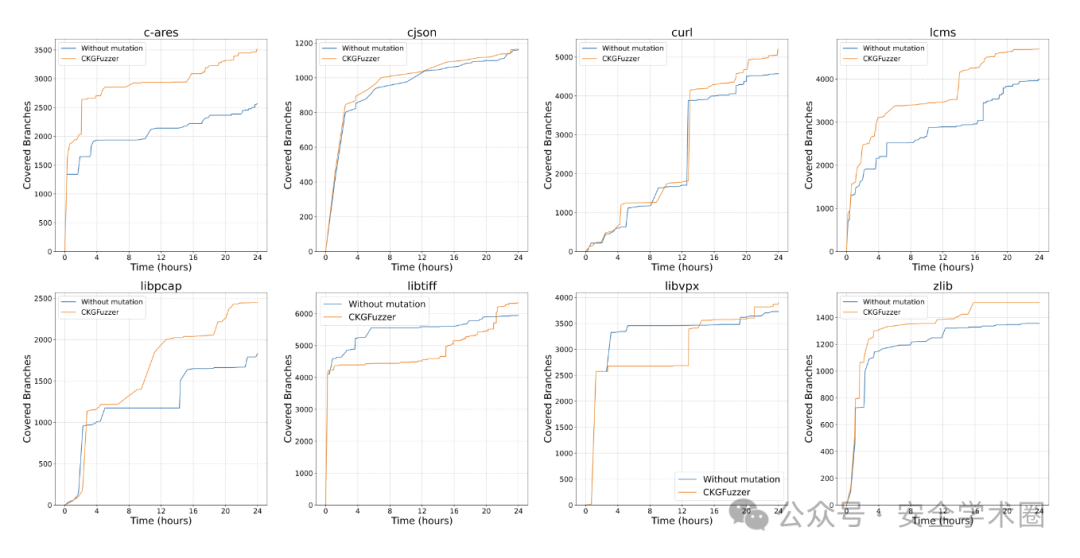
覆盖率引导变异的有效性:在大多数目标库上,该变异策略能够有效提升代码覆盖率。
崩溃分析能力(RQ3): CKGFuzzer自动分析了199个独特的程序崩溃,并准确识别出其中168个是由API误用导致的。该模块将崩溃分类所需的人工审查工作量减少了84.4%。CKGFuzzer成功检测到11个真实Bug,其中9个为先前未报告的新缺陷。


总结
本文针对传统模糊测试中手动编写fuzz driver低效以及现有LLM方法难以理解复杂代码上下文和获取外部知识的挑战,提出了一种基于CKG增强的大型语言模型模糊测试驱动程序生成框架CKGFuzzer。该框架将fuzz driver创建视为代码生成任务,利用从代码库构建的CKG为LLM提供丰富的结构化信息,并通过多智能体系统自动化执行 fuzz driver生成、动态程序修复、覆盖率引导的API组合变异以及崩溃分析等关键步骤。实验结果表明,CKGFuzzer相较于现有技术能显著提升代码覆盖率,大幅减少崩溃分析的人工审查工作量(减少84.4%),并成功发掘了多个真实软件缺陷,验证了该方法在提升自动化模糊测试效率与效果方面的潜力。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
