
原文标题:Robust Detection of Malicious Encrypted Traffic via Contrastive Learning
原文作者:Meng Shen, Jinhe Wu, Ke Ye, Ke Xu, Gang Xiong, Liehuang Zhu原文链接:https://ieeexplore.ieee.org/abstract/document/10964328发表期刊:IEEE TIFS, vol. 20, pp. 4228-4242, 2025笔记作者:张彬@安全学术圈主编:黄诚@安全学术圈
1、引言
流量加密被广泛用于保护通信隐私,但攻击者也越来越多地利用它来隐藏恶意活动。现有的恶意加密流量检测方法依赖于大量标注样本进行训练,限制了它们对新型攻击的快速响应能力。此外,这些方法还容易受到流量混淆策略(如注入虚假数据包)的影响。本文提出了一种基于对比学习的恶意加密流量鲁棒检测方法——SmartDetector。
本文首先提出了一种新颖的流量表示方式,称为语义属性矩阵(Semantic Attribute Matrix, SAM),该表示能够有效区分恶意流量和良性流量。同时,本文设计了一种数据增强方法,用于生成多样化的流量样本,从而使检测模型在面对不同的流量混淆策略时更加鲁棒。此外,本文提出了一种恶意加密流量分类器:该分类器首先通过对比学习在未标注数据上进行预训练,以学习深层特征表示;然后使用有监督分类器对模型进行微调,即使仅有少量标注样本,也能实现精确检测。
为了评估SmartDetector的性能,本文在五个公开数据集上进行了实验。结果表明,SmartDetector在多个场景下均优于当前最先进的(SOTA)方法。具体而言,在混淆恶意流量检测场景中,SmartDetector 的 F1 分数和 AUC 均超过 93%,相较 SOTA 方法分别平均提升了 19.84% 和 18.17%。
2、威胁模型
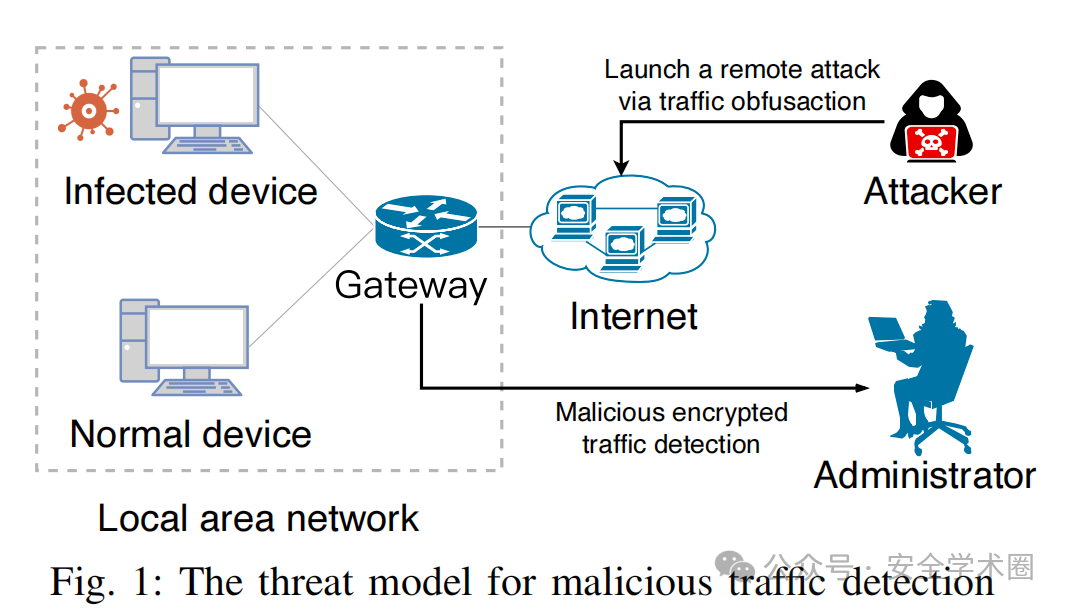
在恶意流量检测的场景中,通常存在两种角色:网络管理员和攻击者。如图 1 所示,攻击者会对位于本地局域网(LAN)中的设备发起远程攻击。
攻击者的能力 :本文假设攻击者可以对流量中的数据包进行操控以逃避检测,例如插入虚假数据包或引入延迟。
网络管理员的能力 :管理员具备通过网络网关监控加密流量的能力,但他们无法解密任何单个数据包。管理员可以持续收集流量数据,用于区分恶意流量和正常流量。然而,他们无法预知攻击者可能发起的攻击类型或恶意软件种类,也没有关于攻击者所采用的具体流量混淆方法的先验信息。
3、本文方法
3.1 语义属性矩阵
本文分析了三个公开数据集CIC-IDS-2017、CIC-DDos-2019和DoHBrw-2020中的恶意流量和良性流量特征的分布。如图2所示,恶意流量和良性流量在三个特征上表现出显著的分布差异。这些特征包括数据包长度(Packet Length)、下行/上行比率(Down/Up Ratio)以及到达间隔时间(Inter-Arrival Time,IAT)。
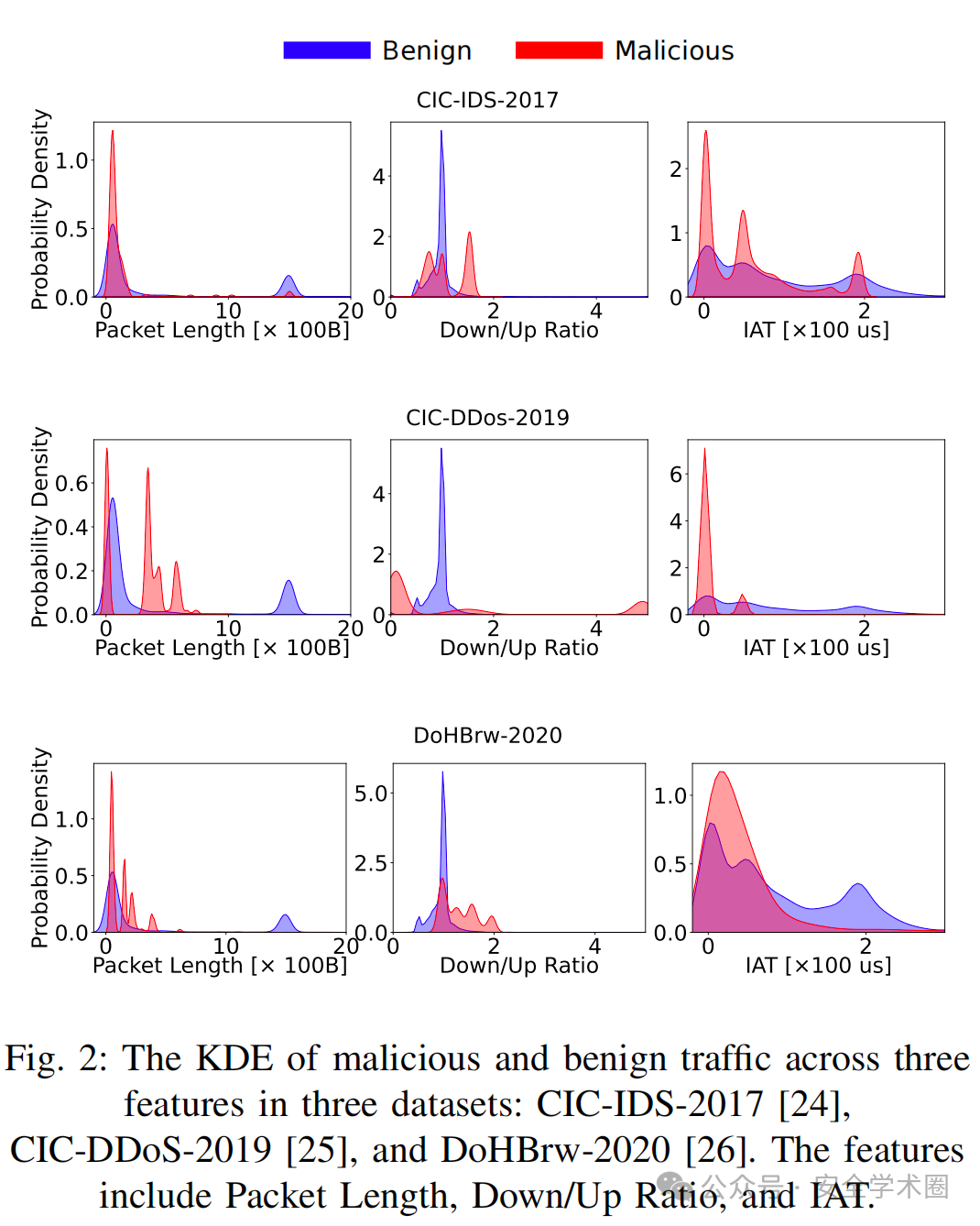
数据包长度 (Packet Length): 良性流量的数据包长度分布更为分散,这是由于良性流量包含多种通信模式和应用程序行为,导致其数据包大小种类较多。恶意流量的分布则更集中,比如在SYN Flood攻击中,数据包通常较小,并在数据包长度上表现出相似的模式。
下行/上行比率(Down/Up Ratio): 它表示每条流量中下行数据包与上行数据包的比例。良性流量通常具有接近 1:1 的上下行比例,因为客户端与服务器之间的通信在数据交换方面通常是双向平衡的。相比之下,恶意流量的上下行比例分布更为分散,可能出现极高或极低的情况。例如在带宽消耗攻击中,攻击者会向受害者发送大量数据,而受害者仅返回极少的响应数据。
到达间隔时间(IAT): 良性流量的分布往往相对平滑,而恶意流量的IAT通常集中在某些特定的峰值附近。例如,CIC-DDoS-2019数据集表现出极小的IAT,这是因为DDoS攻击会在短时间内向目标发送大量数据包以耗尽其资源。
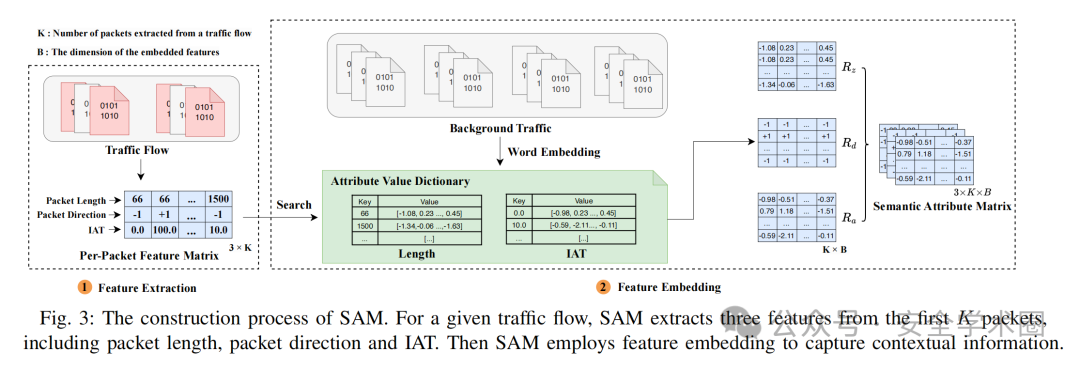
基于上述分析,本文提取了每个数据包的长度、方向和到达间隔时间特征,这些特征可通过特征嵌入进一步挖掘流量中的上下文语义信息。例如,相同类型的恶意流量会生成不同长度的数据包序列,这些序列可能在特征空间中距离较远,但它们在语义上相似并表现出相同的攻击行为。以DoS攻击为例,攻击者常使用不同用户代理发送大量HTTP请求,导致头部大小变化,从而影响数据包长度。
综上,SAM首先从每个数据包中提取长度、方向和到达间隔时间特征,然后再利用词嵌入来提取流量中的上下文语义信息,其构造过程如图3所示。
3.2 SmartDetector的整体框架
SmartDetector包括两个模块,分别为流量数据增强模块和恶意流量分类器模块,其框架图如图4所示。
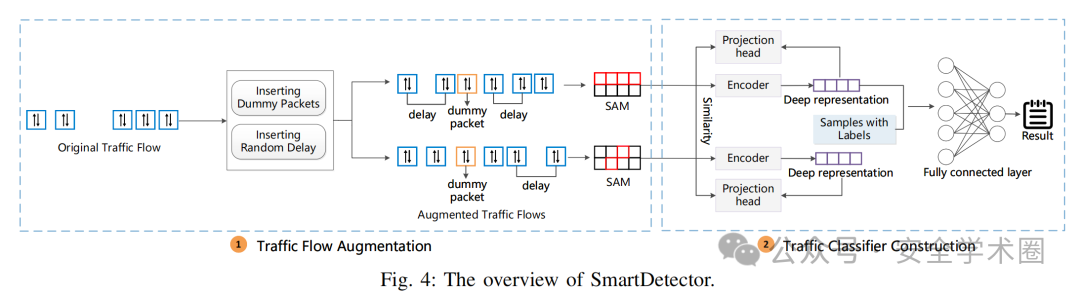
3.2.1 流量数据增强
在恶意流量检测场景中,一些攻击者可能会采用各种混淆策略,例如插入虚假数据包、改变数据包速率和向每个数据包中注入噪声以逃避检测。这些策略会显著改变原始流量的特征,使得现有的检测系统难以识别出恶意行为。为了增强检测系统对抗规避攻击的鲁棒性,本文提出了一种数据增强框架,用于模拟攻击者不同的混淆策略。与以往主要关注模拟网络条件变化的研究不同,本文的框架专门针对对抗性混淆策略进行模拟。
3.2.2 恶意流量分类器
为了实现恶意流量检测,本文使用对比学习来构建编码器。对比学习是一种无监督学习方法,其核心在于学习正样本之间的共同特征,并区分负样本之间的差异。训练过程可以分为两个步骤: 预训练和微调。
预训练: 用未标记的流量样本来训练对比学习模型。该模型由编码器和投影头(projection head)组成。编码器负责学习深度表示(deep representation),并将其作为投影头的输入。模型的输出在正样本对之间趋于相似,在负样本对之间趋于不同。
微调: 使用带有标签的流量样本来学习如何区分良性流量和恶意流量。有监督分类模型的输入是编码器的输出。基于此前学到的深度表示,有监督分类模型仅需少量样本即可实现较高的分类准确率。
4、评估
4.1 实验设置
本文在五个公开数据集上进行了评估,包括CIC-IDS-2017 ( )、CIC-DDoS-2019 ( )、DoHBrw-2020 ( )、USTC-TFC ( )和CIC-IoV-2024 ( )。
4.2 小样本检测场景
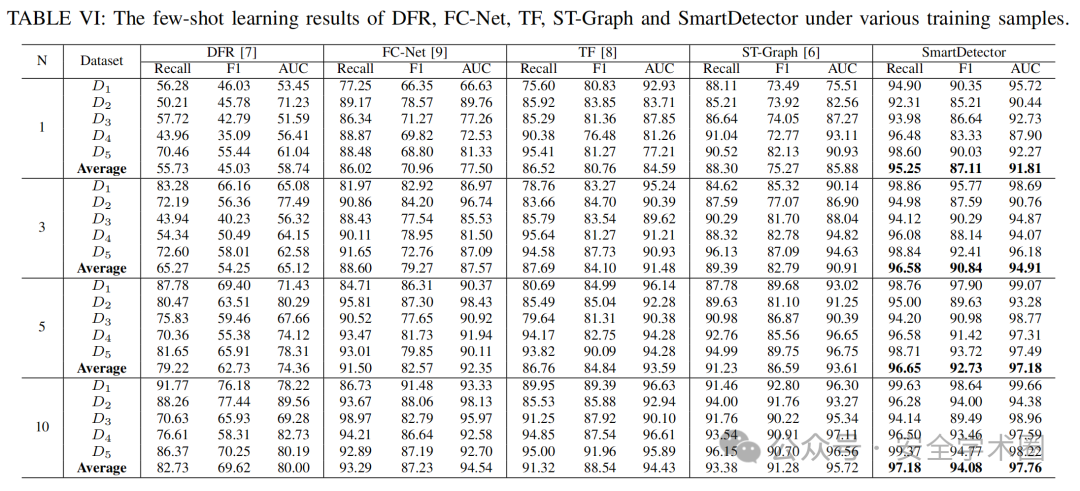
在此设置下,数据集中良性流量和恶意流量样本的比例保持不变(即基线比例为 4:1),仅改变用于模型微调的样本数量。为了观察不同方法在不同样本数量下的检测性能,本文设每类使用的样本数为 ,取值分别为 1、3、5 和 10。
实验结果如表 VI 所示,SmartDetctor在不同的数据集和不同的样本数量下的检测效果均优于现有方法。
4.3 混淆恶意流量检测场景
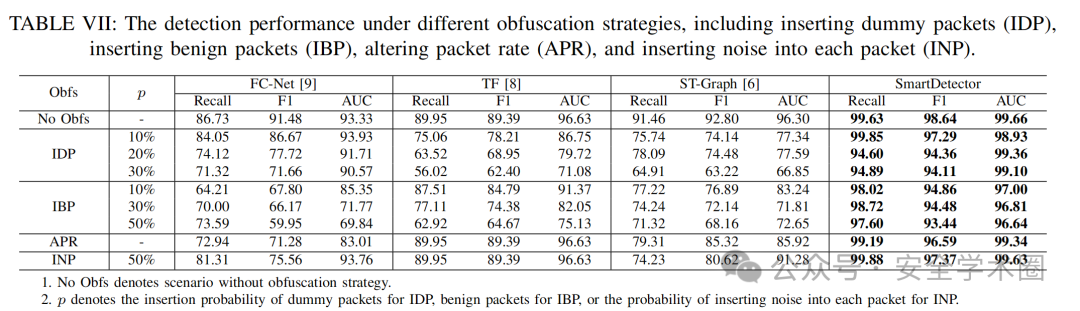
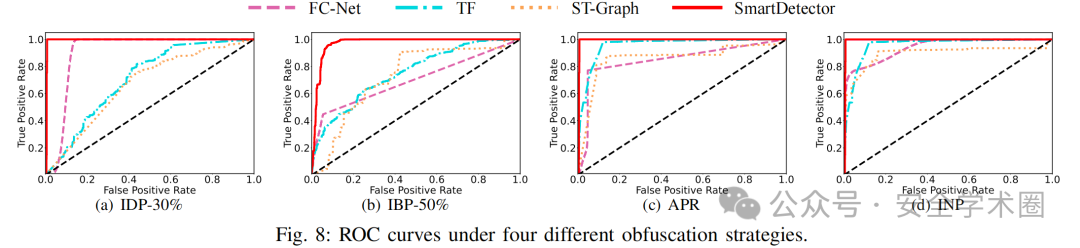
在此设置下,本文考虑攻击者可采用以下四种混淆策略:插入虚假数据包、插入良性数据包、调整数据包速率、以及向每个数据包中注入噪声。本文将模型微调所使用的样本数量设为 10,四种混淆策略下的实验结果如表 VII 和图 8 所示。
SmartDetector 在不同混淆策略下的检测效果显著优于现有方法。SmartDetector 的 F1 分数和 AUC 均超过 93%,相比当前最先进的方法,平均提升了 19.84% 和 18.17%。
5、总结
本文提出了 SmartDetector,一种基于对比学习的恶意加密流量鲁棒检测方法。本文从每个数据包中提取了数据包长度、方向和到达间隔时间。通过特征嵌入,原始数据包序列被转换为有意义的向量表示。本文提出了流量数据增强方法来生成增强样本,基于这些增强样本,可以在无标签流量数据上训练特征提取模型,随后仅需少量有标签的流量样本进行微调,即可实现鲁棒的恶意流量检测。实验结果表明,SmartDetector 在小样本检测和混淆恶意流量检测场景均显著优于现有方法。
团队介绍
北京理工大学网络空间安全学院祝烈煌教授、沈蒙教授团队长期致力于网络加密流量智能分析技术研究,在加密应用识别、异常流量检测、智能算法对抗等方面,取得了一系列原创性成果,论文发表于ACM CCS、IEEE S&P、USENIX Security和IEEE TIFS、IEEE JSAC等国际会议和期刊,并与网络安全头部企业开展合作,成果广泛应用于网络态势感知、加密恶意流量检测等领域,获得2024年中国电子学会科技进步一等奖。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
