我们终于到了可达性探索之旅的终章。
在第一部分,我论述了可达性实际上仅关联展示可利用的漏洞。在第二部分,我通过比较运行时可达性和静态可达性得出结论:如果目标仅是修复可利用的漏洞,那么只有运行时可达性能助我们实现这一目标。
终极问题是:哪种类型的运行时可达性才是正确的?遗憾的是,许多厂商在市场上推出了 “可达性” 概念,但它们几乎总是指代不同的东西。在本文中,我们将探讨可达性类型的复杂性,并分析为何尽管没有万能的解决方案,但针对漏洞的函数级可达性仍是解决该问题的最佳整体方案
运行时可达性的多种形态

安全工程师们迫切希望找到方法,让漏洞报告中数以千计的误报漏洞消失不见。从新的 Linux 发行版(如无发行版镜像)到网络路径分析,再到漏洞影响半径评估,如今关于 “优先级排序” 的提议比以往任何时候都多。正如我在本可达性系列文章中一直论述的 —— 真正的目标是尽可能贴近 “漏洞可利用性”。企业只想投入资源修复那些实际可被利用的漏洞。
这种场景屡见不鲜:一个严重性分值 9.5 的新 CVE 发布后,网络安全社区立刻充斥着 “实际没那么严重” 的抱怨。遗憾的是,漏洞披露的性质决定了 CVE 基础评分只能基于最坏情况而非特定环境的实际场景。由于核心开源软件包存在于无数不同的使用场景中,大多数漏洞发现其实与你的具体环境完全无关。此外,安全研究人员通常需要通过非典型方式才能让漏洞利用(exploit)生效 —— 这正是他们证明漏洞存在的手段。
Log4j 1.x 版本中的三个关键漏洞(注意:并非针对 2.x 版本的 log4shell,而是旧版)就是一个简单例子。这三个漏洞均与 Log4J 包中严重的远程代码执行漏洞相关;然而,它们只能在 Apache Chainsaw 环境下被利用,该工具是 Log4J 的一个图形界面,供开发者查看日志。尽管 Log4J 被广泛部署,但通过 Apache Chainsaw 使用图形界面的情况则少见得多——尤其是在现代环境中。
该漏洞揭示了更普遍的漏洞生态系统中存在的以下问题:
许多严重的漏洞在大多数场景下并不适用
安全团队,甚至开发人员,都无法完全掌握他们使用或导入的每个库
对于大多数人来说,漏洞系统通常无法提供足够的数据来准确判断实际风险
许多工具未能充分区分操作系统漏洞(如 openSSH 包)与代码库漏洞(如 Log4J)
这些漏洞暴露出安全团队面临的诸多问题,但核心问题在于:调查一个漏洞所需的时间和人力,远超过发现它的成本。安全工程师面对漏洞的本能反应是尝试重现概念验证(PoC),以说服开发人员修复它,但面对成千上万的漏洞时,这种做法并不现实
运行时可达性为这一调查难题提供了解决方案:只向我展示在我的环境中实际可利用的漏洞。只有通过观察应用程序的运行状态,工具才能有效区分漏洞是否可被利用。尽管我在其他场合讨论过 “左移可达性” 的一些优势(例如它可以在生产环境部署前运行),但该技术的关键局限在于其最多只能停留在理论层面。例如,世界上最先进的左移可达性技术也无法告诉我是否真正在使用 Apache Chainsaw——只有监控运行时状态的工具才能判断开发人员是否在使用该图形界面。

在上一篇文章中,我们比较了静态可达性和运行时可达性,得出结论:静态可达性的优势在于可在生产环境部署前运行,但只有运行时可达性能告诉你实际可被利用的漏洞—— 从而更接近零误报的理想状态。根据我使用相关工具的经验,真正的运行时可达性结果一旦呈现,其价值令人无法忽视;遗憾的是,市场上充斥着大量过度简化的表述和错误的说法,例如:
❌❌ 所有 eBPF 代理都相同
❌ 包加载等同于可达性
❌ 包执行等同于可达性
❌显示服务是否面向网络(即是否可被网络访问)就是可达性
更令人困惑的是,不同漏洞实际上受不同类型可达性的影响程度大相径庭!下图展示了这一问题的复杂性,以及漏洞在特定环境中可能被利用或无法被利用的不同情形:
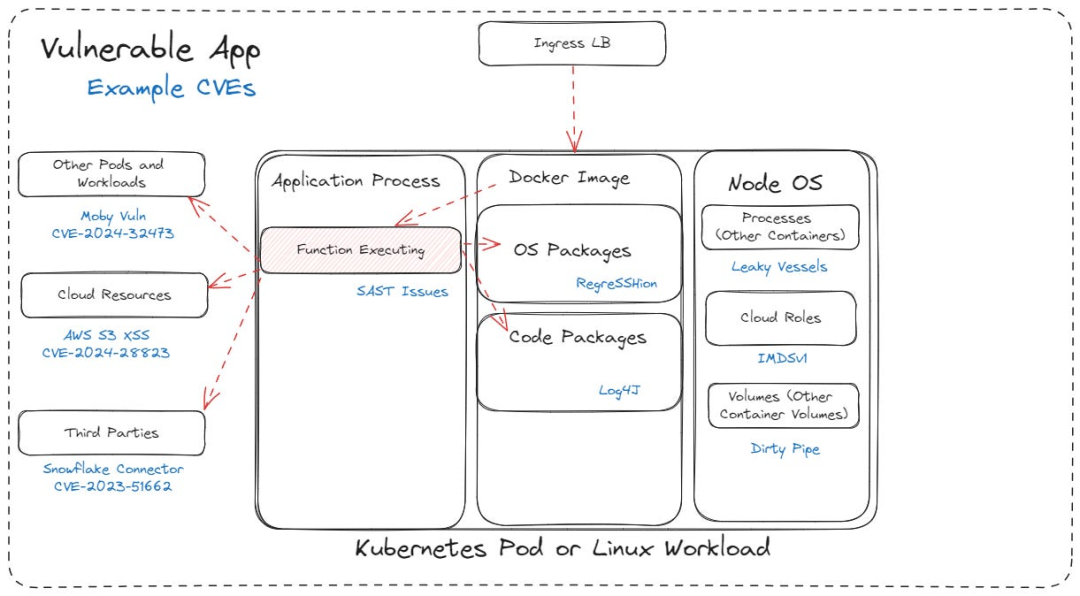
基于漏洞在工作负载中所处的位置,可能存在并可被利用的不同漏洞
这些被利用的漏洞各自存在于云环境和应用环境的不同层级中 —— 从第三方组件,到操作系统漏洞、应用程序漏洞,甚至云层面的漏洞,可见可达性绝非如此简单
在本文的接下来章节,我们将探讨不同运行时可达性解决方案的现状,以及它们的优缺点。
Runtime Reachability 的复杂性
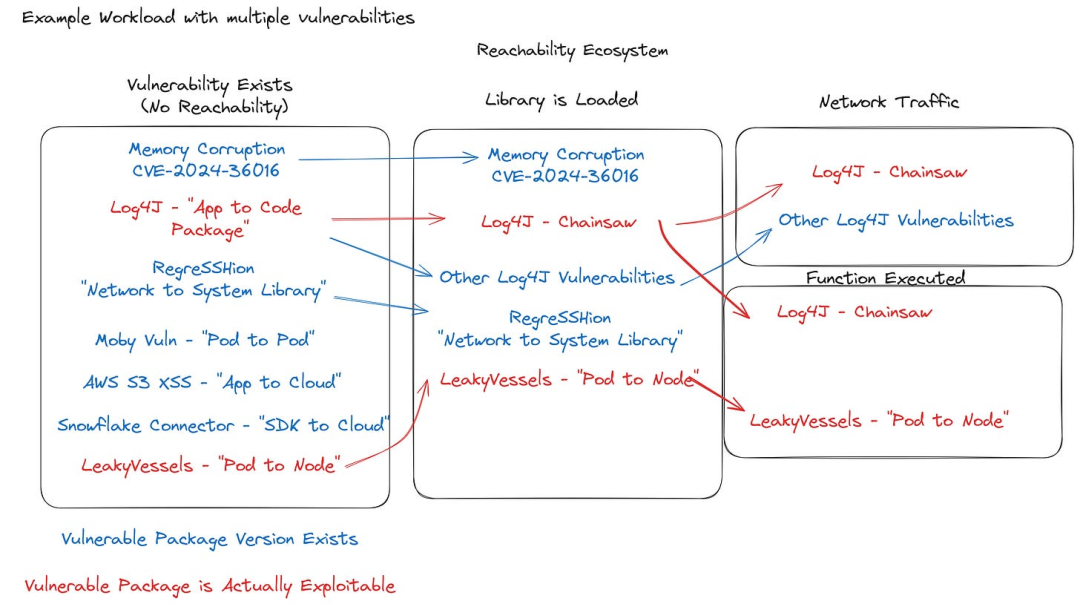
基于可达性类型的漏洞筛选 —— 红色表示实际可被利用的漏洞,蓝色表示误报
这张图内容很多,我们花点时间拆解一下。假设我们有一个用于查看 Java 日志的容器镜像,它同时也用于构建容器镜像 —— 由于团队里有几位 Java 开发者,他们会用 Chainsaw 查看构建过程中出错的日志,并且这个镜像暴露在 VPN 后的网络流量中。在此例中,我选取了 7 个 “近期热点” 漏洞,它们可能都被检测到存在于同一个工作负载中。然而实际情况是,只有两个漏洞是真正可被利用的(红色):Log4J(Chainsaw 相关)和 LeakyVessels。蓝色标记的是镜像中存在的不可利用漏洞(误报)。我们可以通过这个流程观察不同类型的可达性如何正确或错误地确定这些漏洞的优先级。
首先,通过检测库是否已加载,我们能正确过滤掉一部分误报。这是一种用于基本过滤的基线方法—— 如果某个组件未加载到内存中,那么它显然不会以可被主动利用的方式运行。值得注意的是,即使某个组件未加载,一旦攻击成功进入系统,相关组件也可能被迅速加载!
顺便提一下,目前有些工具用 “已执行”(executed)一词来区分 “已加载”(loaded),但在实践中这种区分往往并无太多实际意义。“已加载” 通常指共享库被映射到进程的内存空间,而 “已执行” 一般表示加载文件中的某些代码已实际运行
然而,我们需要强调高层级 “执行” 与 “函数级执行” 之间的巨大差异。函数级执行不仅关注访问了哪些文件,更会追踪代码中具体哪些函数正在被执行。这为漏洞优先级排序提供了极高的价值 —— 平均每个库包含成百上千个函数,而大多数漏洞利用仅针对某个特定函数。根据我的测试,函数级执行在降低误报优先级方面的价值是普通方法的 10 到 100 倍。。
网络可达性之所以值得关注,是因为它正确地优先处理了某些事项,但也错误地优先处理了一些本不该优先的事项,甚至可能错误地降低漏洞的优先级。总体而言,其有效性并不稳定。从直观层面看 —— 如果互联网无法访问某个服务,它显然不会被利用?但遗憾的是,设备、供应链和服务都以不同方式连接,无论它们是否连接互联网。许多攻击依赖供应链或下游服务,若过度依赖网络可达性,这些漏洞会被错误地掩盖。
一切皆可达,哪种适合我!?
虽然声称存在一种 “万能” 的可达性方案很有趣,但事实是,针对不同漏洞,你实际上需要综合运用所有类型的可达性分析。以最近的一个重大漏洞为例 ——Next.js 中间件身份验证绕过漏洞。简而言之,如果使用 Next.js 中间件进行身份验证,该漏洞会让你陷入风险。判断是否受影响的关键在于:“当 Next.js 应用使用中间件时,会调用 runMiddleware 函数,除主要功能外,该函数会获取 x-middleware-subrequest 标头的值,并据此决定是否应用中间件。”
通过我们的加载状态、函数执行、网络可达性模型:
加载状态或基本执行:Next.js 作为一个整体库加载,因此这种分析只能告诉你是否使用了 Next.js,但无法具体到中间件 —— 因此对优先级排序帮助不大,但至少不会出错。
网络可达性:这有助于我们确定修复的优先级,因为面向公网的 Next.js 应用显然比内部应用更关键;然而,除了区分是否为内网中的 Next.js 应用外,在其他方面对优先级排序帮助不大。
函数执行:这才是真正的优先级排序方法 —— 它不仅能告诉我们哪些工作负载正在加载 Next.js,还能确定哪些工作负载实际使用了中间件函数。。
虽然并非每个漏洞都遵循这些规律,但在实用性上显然存在这样的排序:函数级执行 > 已加载状态 > 网络可达性状态。那么,为什么不是所有厂商都采用函数级执行分析呢?

已加载状态分析法之所以被采用,是因为它简单易行。这种方法在降低漏洞优先级时始终有效—— 因为如果某个组件未被加载,它就绝对不可能成为初始攻击的目标。然而,它也会错误地提高某些漏洞的优先级,因为许多已加载的组件并未执行存在漏洞的函数。
网络可达性分析法之所以被采用,是因为它对安全人员来说直观易懂。这种方法有时有助于确定优先级,但也存在风险 ——它会错误地降低那些即便不直接接收互联网流量也可能正在执行的漏洞的优先级,尤其是供应链攻击场景。此外,在容器化微服务环境中,网络可达性分析往往不准确,因为服务间的流量未被纳入考量。
函数可见性是唯一能可靠确定漏洞优先级(无论是降低还是提高)的方法。如果存在漏洞的函数未被执行,那么该 CVE 就不可能成为初始攻击向量。同理,如果该函数正在执行,就表明存在被利用的可能性,绝对需要深入调查。其唯一缺陷在于,并非每个 CVE 都与特定函数相关。。
还有一件事:操作系统与代码库
我之前曾谈到过这一点,但我们讨论的所有内容既适用于代码库(如 Next.js),也适用于操作系统库(如 OpenSSH)。并非所有扫描工具都能检测到所有这些维度(加载状态、函数执行、网络可达性等),因此需要特别注意:我们讨论的内容普遍适用,但并非所有操作系统扫描工具都支持代码库分析,反之亦然。
值得向厂商询问他们支持哪些功能,但这里有一个通用指南:
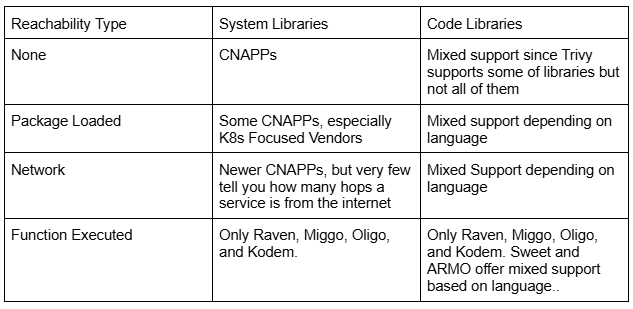
结论
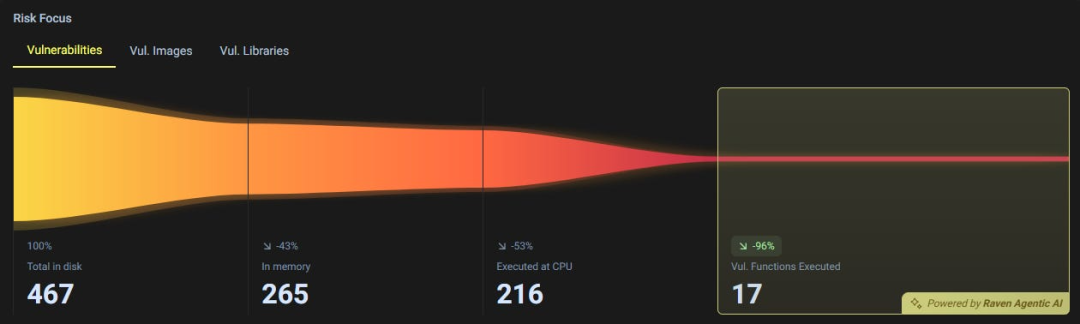
这 17 个漏洞中的每一个都既有趣又相关,这一点很奇妙。
刚才的内容信息量很大,所以这里有个简版总结:
并非所有运行时可达性都相同
实际上存在三种类型:加载状态、网络可达性和函数执行
根据漏洞类型的不同,每种方法各有优缺点,但函数级别分析迄今为止提供了最高的正向分析价值
最终,在运行时仅看到存在漏洞的执行中函数所带来的奇妙感觉,怎么强调都不为过。这些结果总是令人感兴趣,而这是我对大多数其他类型的扫描工具难以企及的评价。
原文链接:
https://substack.com/home/post/p-161260493
声明:本文来自安全喵喵站,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
