
原文标题:Profiling Tor Users with Unsupervised Learning Techniques
原文作者:Rafael Galvez, Marc Juarez, Claudia Diaz原文链接:https://homes.esat.kuleuven.be/~mjuarezm/index_files/pdf/infer16.pdf发表会议:International Workshop on Inference and Privacy in a Hyperconnected World笔记作者:宋坤书@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、研究背景
网站指纹识别(Website Fingerprinting, WF)是一种流量分析攻击,攻击者仅通过观察加密通信的流量特征推测用户访问的网站。Tor作为最流行的匿名通信网络,利用洋葱路由隐藏通信元数据。研究表明,某些WF攻击能有效地在Tor网络中识别用户访问的网站,从而破坏其匿名性。然而,传统WF攻击通常采用监督学习方法,将网站分类为不同类别,并使用已知网站的流量样本训练分类器,再对用户流量进行识别。
因此,传统WF攻击研究是基于“封闭世界假设”,即假设用户仅访问攻击者训练过的网站,这种假设有利于攻击者,但维护高质量的模型代价较高。且在“开放世界”场景下,传统WF攻击的分类准确率(accuracy)显著下降。本文提出了无监督学习方法,即攻击者不再预先训练分类器,而是利用聚类算法对相似流量进行分组,从而默认采用“开放世界”场景,无需维护网站模板数据库。此类攻击虽无法直接识别具体访问的网站,但可基于访问分布对用户进行行为画像。例如,攻击者可以对多个用户的流量模式进行聚类,识别具有相似行为的用户,从而辅助传统WF攻击,提高目标选择的效率。
2、研究方法
本文利用无监督学习技术,通过聚类算法在流量样本中识别相似模式,以实现对Tor用户的画像分析。而样本之间的相似性在很大程度上取决于选择用来表示它们的特征,因此,攻击的关键在于特征选择和聚类算法的选取。
2.1 特征选择
WF攻击使用的数据集通常是基于网络流量的时间、方向和数据包长度等特征构建的。研究表明,总传输量和流量突发等粗粒度特征是网站的独特特征。为了优化聚类效果,本文采用Panchenko等人提出的特征[1],该特征基于特定时间点的瞬时流量函数的值(即传入字节数减去传出字节数)。为了提取相同数量的特征,此处使用插值方法确保每条流量轨迹包含100个等距点,并在特征向量前添加总传入/传出字节数和数据包数,共计104维特征。这些特征易于可视化,便于评估聚类质量。
2.2聚类算法
基于密度的聚类算法适用于无法预知类别数量的场景,因此此类算法比K-means这种更为流行的算法更适合WF攻击。本文选取了OPTICS(Ordering Points To Identify the Clustering Structure)算法,该算法是DBSCAN的扩展,能够识别不同密度的任意形状簇。因为不同网站可能具有不同的数据更新频率,从而导致簇内密度差异,因此这一点非常重要。
OPTICS依赖两个参数:ε(邻近距离阈值)和minPts(最小聚类点数),通过计算每个样本与其minPts个最近邻居的距离排序,只要该距离小于ε的点。并识别高密度区域。距离大于ε点或不满足minPts条件的点被归类到噪声数据(rag bag)。最终聚类结果通过设定的邻近距离阈值ε′进行划分。
本文在小规模数据集上测试了三种距离度量方法:欧几里得距离(Euclidean)、曼哈顿距离(Manhattan)和共享最近邻 Jaccard距离(SNN Jaccard),本文使用ELKI(开源Java软件)执行OPTICS聚类算法并优化其参数。
3、实验设置
本研究的数据收集基于Wang等人的方法[2],选取了美国Alexa排行榜前100和前1,000的热门网站,并使用Tor浏览器进行自动化访问。为了减小数据陈旧性带来的影响,Alexa前100网站被分10批(每批访问4次),前1000网站分2批(每批访问10次)。实验仅访问网站主页,以与现有WF的研究保持一致,同时还排除了因CAPTCHA机制拦截或数据损坏的网站流量。
实验使用tor-browser-crawler(python模块)来模拟真实Tor用户的访问模式,Tor浏览器版本为5.5.5。实验主要使用非本地化Alexa网站版本,并假设目标用户处于相同的网络环境且使用类似设备。此外,实验通过启用和禁用入口守护节点(UseEntryGuards)分别进行数据采集,前者使用相同的入口节点,后者则从所有可用入口节点中挑选,用于模拟不同用户的访问行为。
4、实验结果
4.1 实验评估标准
因为实验中的样本标签是已知的,本研究使用外部评价标准评估聚类算法的质量。评估指标包括聚类同质性(同一簇内不应含有不同网站)、聚类完整性(同一网站的样本应尽量归于同一簇)、噪声处理(将噪声样本归入单独簇) 以及聚类大小与数量(较大簇中的小误差比大量小簇中的多个误差更可接受)。其中,前两项分别对应信息检索中的精确率(precision)和召回率(recall),后两项则有助于提高泛化能力,使攻击在实际环境中更具可行性。
本研究采用BCubed度量来计算精确率和召回率,以评估聚类的质量。其中,精确率表示同一簇中样本来自同一网站的概率,召回率表示不同网站样本落入不同簇的概率。此外,实验还计算了F1-score,用来衡量聚类的整体性能。
4.2 实验结果
实验设置了使用单个Guard节点和多个Guard节点两种场景,并分别计算评估指标。聚类参数包括最小聚类点数 (minPts)(范围 0 到每个网站的最大样本数)、密度阈值 (ε")(范围 0~1,最佳值为 0.1)以及距离度量(Euclidean, Manhattan和SNN Jaccard)。此外,实验使用min-max方法对数据集进行了归一化,因为在Panchenko等人的研究中归一化后SVM分类器的accuracy显著提高[1],同时聚类效果也有所改善。这是一个数据预处理步骤,仅依赖数据集本身,可以随时使用。
不同距离度量的比较(100和1000个网站):在100个网站的数据集中,评估了Euclidean、Manhattan和SNN Jaccard三种距离度量的聚类性能。其中,SNN Jaccard表现最佳(精确率为0.58,召回率为0.63),但整体准确率仍有限,攻击者仅能以一定概率推测用户访问的网站。扩展到1000个网站后,尽管特征维度较高,但Euclidean依然表现良好,这表明在特征间高度相关的情况下,维度灾难的影响较小,这与现有机器学习的研究结论一致。100个网站和1000个网站三种距离度量的聚类性能如下:

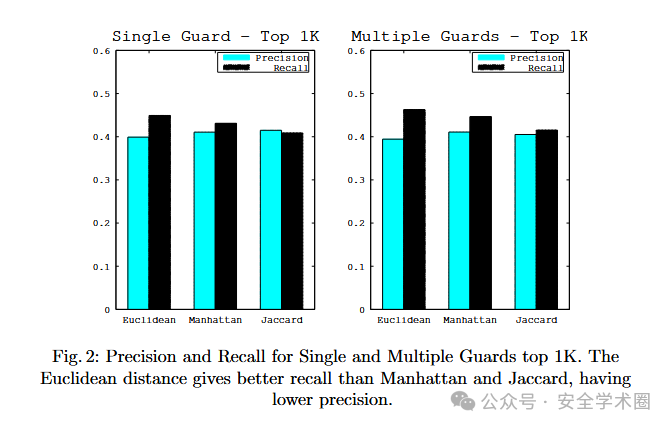
单个Guard节点与多个Guard节点:在1000个网站的数据集中,对使用单个Guard节点和多个Guard节点的数据集进行聚类分析,它们分别对应单个用户和多个用户访问行为。理论上,固定Guard节点可以降低方差,有利于分类,但实验结果显示,多个Guard节点反而在召回率上略有提升。这可能是由于数据采集的时间间隔或不同Guard节点位置导致的数据异质性,使得聚类算法能够更准确地划分不同类别。此外,位于相同网络用户使用不同Guard节点时,其聚类结果仍与使用单个Guard节点时相似,即本文的方法不仅可以将同一用户对同一玩网站的访问聚类到同一簇,也可以将不同用户对同一网站的访问正确分类。1000个网站时采用Euclidean的精确率和召回率如下:
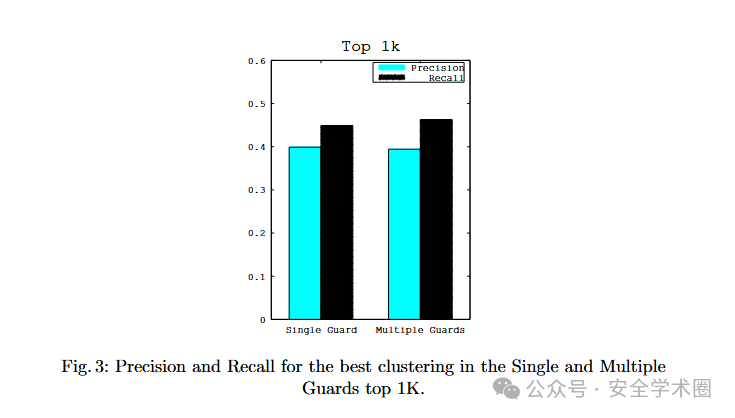
世界规模对聚类效果的影响:通过逐步扩展世界规模(从200个网站到1000个网站)分析聚类效果,单个Guard节点场景下F1-score单调下降,但降幅不显著。而在多个Guard节点场景下,F1-score几乎保持不变,但精确率和召回率随着世界规模波动。在中等规模时,多个Guard节点的精确率一直在提高且召回率一直在降低,而较大规模时则恰好相反。这是因为当rag bag样本比例较小时,OPTICS生成更多小簇,提高了精确率但降低了召回率;而随着世界规模进一步扩大,rag bag样本比例趋于稳定,OPTICS重新找到更好的簇,提高了整体聚类效果。本文认为,单个Guard节点和多个Guard节点的聚类结果差异可能与它们在同一类别样本之间的类内方差不同有关。不同世界规模的聚类效果评估如下:
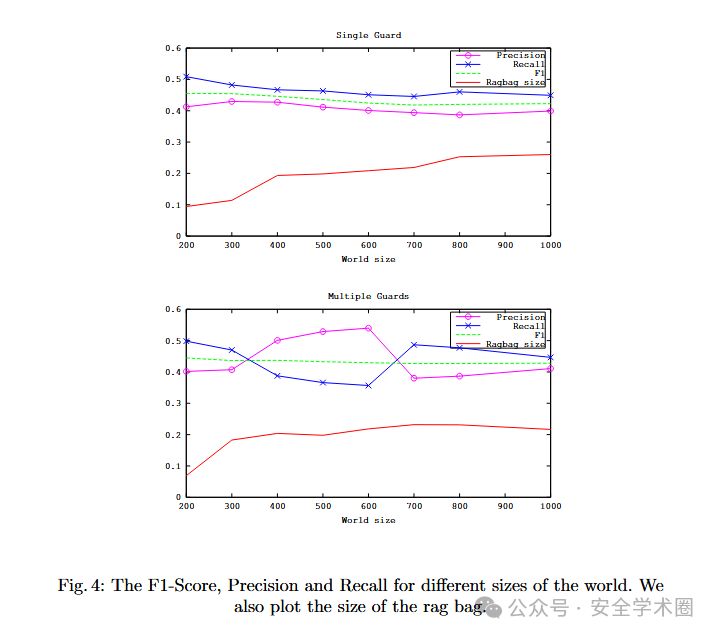
4.3 实验结果分析
聚类算法在无监督学习中比分类任务更具挑战性,因为聚类无法获取明确的对象类型信息,只能基于特征寻找模式。尽管Tor的目标是组织攻击者对用户浏览行为的推测,但攻击者通过聚类算法仍能以近50%的概率将不同用户的访问行为关联到同一网站,远高于随机猜测的成功率(不到0.0005%)。
现有的WF分类器在1000个网站数据集上的精确率和召回率为75%,而聚类算法的召回率接近50%,精确率约为40%。虽然聚类算法的表现不如现有的WF分类器,但聚类算法作为一种无监督方法,它可以在没有标签数据的情况下能够进行攻击,这意味着它在没有事先训练数据时进行有效的推断,具有一定的威胁性和更强的适应性。
此外,聚类评估时考虑了rag bag,但实际攻击者在构建用户画像时不需要使用rag bag,因此实际攻击的成功率可能高于测量值。实验结果表明,无论是单一用户还是用户群体,最佳聚类的参数是相同的,这表明该技术在不同场景中的适用性。
5、本文贡献
提出了一种基于聚类的无监督网站流量分析攻击:采用OPTICS算法并结合现有WF攻击特征,实现对Tor用户网页访问行为的自动归类。
在不同场景下评估了攻击的有效性:通过使用单个单个Guard节点和多个Guard节点分别模拟单用户和多用户的网页访问,结果表明本文提出的攻击方法不仅可以准确聚类单个用户访问,也可以将不同用户的访问正确聚类。
分析了世界规模对攻击性能的影响:实验表明在较大规模的网站时本文提出的方法仍能保持较稳定的攻击性能,表明该方法对Tor流量的隐私威胁具有现实可行性,并为未来更复杂的无监督攻击研究奠定基础。
参考文献:
[1]Panchenko, A., Lanze, F., Pennekamp, J., Engel, T., Zinnen, A., Henze, M., & Wehrle, K. (2016, February). Website Fingerprinting at Internet Scale. In NDSS (Vol. 1, p. 23477).
[2]Wang, T., & Goldberg, I. (2013, November). Improved website fingerprinting on tor. In Proceedings of the 12th ACM workshop on Workshop on privacy in the electronic society (pp. 201-212).
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
