
原文标题:Untangle: Multi-Layer Web Server Fingerprinting
原文作者:Cem Topcuoglu,Kaan Onarlioglu,Bahruz Jabiyev,Engin Kirda原文链接:https://dx.doi.org/10.14722/ndss.2024.24497发表会议:NDSS笔记作者:李智宇@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、背景介绍
在现代互联网中,Web 应用程序通常部署在多层代理服务器之后。由于现有的指纹识别技术没有分层服务器的概念,针对分层架构的差异攻击日益凸显。因此,本文提出了首个通过利用多层 Web 服务器之间 HTTP 处理差异来进行指纹识别的方法,并通过一个名为 Untangle 的 HTTP 模糊测试工具进行实现,实验证明其能够以高精度对三层架构进行指纹识别。
差异攻击是指当流量路径上的多个服务器对相同的HTTP 报文的处理方式不一致时,攻击者可能会滥用这种差异实施恶意操作,例如:HTTP 请求走私、Web 缓存投毒、Web 缓存欺骗和 HTTP2 协议降级漏洞利用。
Web 服务器指纹识别是安全测试、漏洞管理和网络可观测性中的一项标准实践。现有的指纹识别工具通过一组有效和无效的请求来探测目标,分析响应以获取服务器的特征,例如响应头的特定排序或独特错误。
模糊测试是一种自动化的软件测试技术,通过生成或变异输入数据并将其注入目标系统,以触发异常行为,从而发现潜在缺陷。差分模糊测试是模糊测试的一种变体,其核心思想是向多个系统发送相同的输入,通过对比其行为差异来发现潜在的错误。
2、方案设计
2.1 多层指纹识别方法
假设存在一个行为库,该行为库提供两个函数 Behavior 和 Match:
Behavior(request, server) → {Error, Pass, Other} 。该函数指示给定服务器在收到请求时的行为,Error 代表服务器以错误响应,Pass 代表服务器转发请求且未做任何修改,Other 包括在转发之前请求被修改,以及由终端源服务器处理并成功响应的情况。
Match(response) → {server ∈ Servers, Unknown} 。 该函数将给定的错误响应映射到唯一服务器。
指纹识别的过程分为 3 个阶段:
2.1.1 有序采集指纹
该阶段的核心思想是通过递进式错误响应探测实现多层架构的服务器指纹识别。具体流程为:从空列表开始,针对每一层构造特定探测请求,该请求需满足如下两个条件。
对所有未识别的服务器 s 满足 Behavior(request, s) → Error;
对所有已识别的服务器 s 满足 Behavior(request, s) → Pass。
通过向目标发送此类请求,可获取到下一待识别层的错误响应,将其与已知服务器技术进行匹配并将结果添加至有序列表 Ordered。该过程循环迭代,直至所有层均被识别。
2.1.2 无序采集指纹
由于行为库实际上可能并不完整,故该阶段旨在对剩余层中的服务器进行指纹识别,其具体流程与阶段 1 类似:从阶段 1 构建的有序列表开始,构造满足两个条件的探测请求。
对未识别的服务器 s 满足 Behavior(request, s) ∈ {Error, Pass};
对已识别的服务器 s 满足 Behavior(request, s) → Pass。
通过触发未识别服务器的错误响应,将响应特征与已知服务器技术进行匹配,由于没有任何关于层放置的信息,将结果添加到无序集合 Unordered 中。
2.1.3 完善排序
最后一个阶段根据所识别服务器的正确位置,将 Unordered 中的条目移动到 Ordered 中。其具体流程是:用满足以下两个条件的请求探测目标。
对所有 Ordered 中的 s 满足 Behavior(requests, s) → Pass;
对所有 Unordered 中的 s 满足 Behavior(request, s) → Error。
这保证了从 Unordered 中最靠近客户端的服务器得到错误响应,经过分析匹配将被指纹识别的服务器移至 Ordered,然后重复该过程。
2.2 通过模糊测试建立行为库
生成和改变 HTTP 请求。研究者使用了差分 HTTP 模糊测试器 T-Reqs 作为基础,并修改了 其语法和变异能力,设计了 3 个分别针对 HTTP 请求的请求行、头部和正文的模糊测试实验。
模糊器配置为最多应用 2 个字符变异,并使用了 40 个方法名,8 个不同的请求 URI,一个包含 66 个标准头部名称和 1142 个非标准头部名称的头部池。最终该实验在请求行突变实验中生成了 2,029,592 个唯一请求,在头部突变实验中生成了 1,753,955 个,在正文突变实验中生成了 497,292 个。
下图分别展示了实验中使用的 HTTP 请求、头部和正文(蓝色表示应用字符突变的部分,棕色表示特定值):



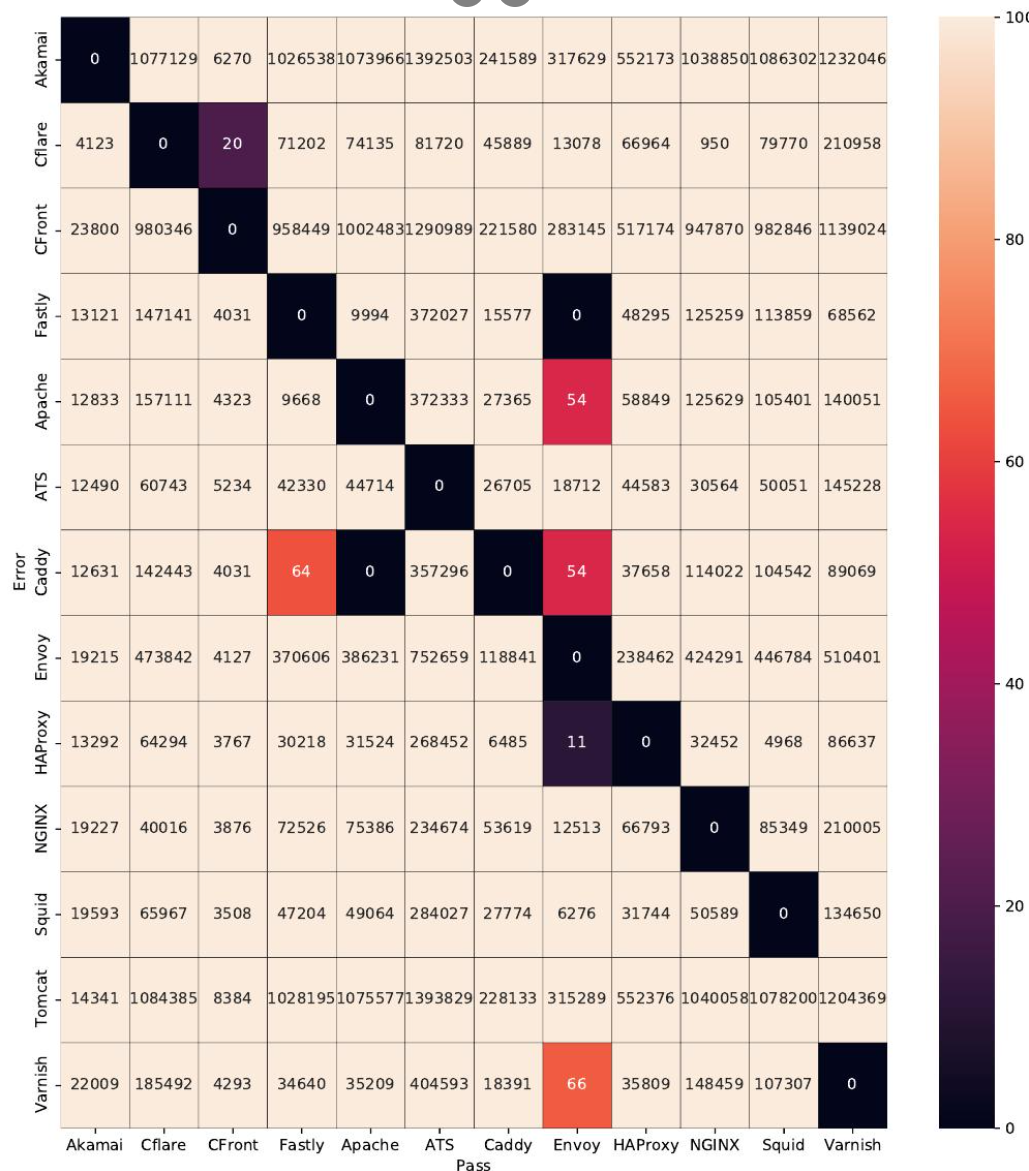
发现差异和错误。研究者使用上述生成的请求对实验范围内的 13 台服务器进行了测试,对于每个请求,得到了每个服务器的相应行为以及各自的错误响应。下图所展示的引发服务器对之间差异的请求数量(X 轴表示完整转发请求的服务器,Y 轴表示返回错误的服务器)表明:模糊测试能够提供一个丰富的行为库并捕获绝大多数服务器对之间的差异。
2.3 错误与服务器匹配
Untangle 的最后一个实现细节在于确定一种将错误响应与服务器进行匹配的分析策略。Untangle 通过计算 Jaccard 相似度得分将响应与行为库中最相似的条目进行匹配。研究者使用了两种方案进行相似度比较:计算整个响应消息的相似度; 分别计算完整响应、错误代码和主体数据三个部分的相似度。为了进一步提升准确性,研究者额外检查了 5 个 CDN 响应头作为补充特征。最后通过两种方式执行基于相似性的服务器匹配:第一种是选择最佳匹配;第二种通过使用相似度阈值进行匹配,若相似度得分小于等于阈值,被探测的服务器将被标记为未知。
3、实验评估
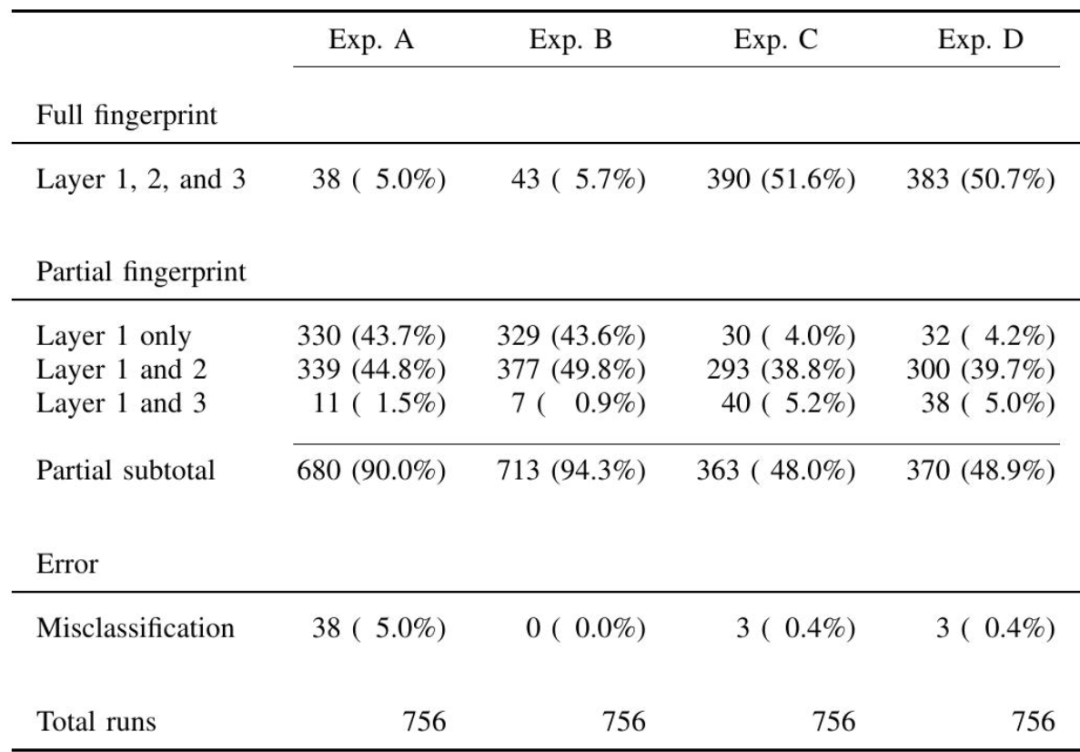
指纹识别准确率。使用 Untangle 对之前提到的 13 台服务器进行测试,共进行 4 次实验,每次实验共产生 756 次指纹识别,每次测试有完整指纹识别、部分指纹识别和错误识别三种结果。
实验 A:配置 Untangle 仅执行阶段 1,使用整个响应消息计算相似度得分并选择最佳匹配,未对静态标头进行检查。
实验 B:配置 Untangle 仅执行阶段 1,使用完整响应、错误代码和主体数据计算相似度得分,选择最佳匹配并对静态 CDN 标头进行检查。
实验 C:在实验 B 的配置基础上,Untangle 执行所有 3 个阶段。
实验 D:在实验 C 的配置基础上,所有阶段均使用相似度阈值。
下表展示了该准确性实验的结果汇总。结果表明,实验 A 的配置可以 100% 检测到第 1 层,但随着层数增加,识别准确率显著下降。实验 C 在引入阶段 2 和 3 后,第 2 和 3 层的检测结果激增至 683 个和 390 个,显著提高了完整指纹识别率。而实验 D 在第 3 层准确率略有降低,这是由于阈值匹配会覆盖一些已经匹配成功的案例。
未知服务器准确度。为了模拟 Untangle 在存在未知服务器情况下的表现,共进行 13 次实验,每次实验会从行为库中移除与某个服务器对应的所有条目。实验结果显示,Untangle 在大多数情况下能正确将其标记为未知,但在特定服务器间(如 Envoy 与 Caddy、Cloudflare 与 NGINX)会出现混淆。最终在共 2286 个排列中产生了 185 个错误分类。
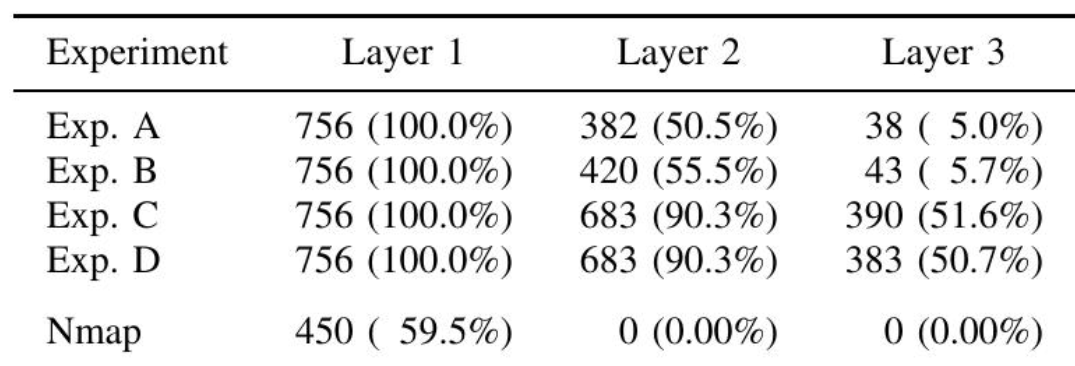
对比 Untangle 与 Nmap。由于 Nmap 没有分层服务器的概念,此实验仅对第 1 层进行检测。在隔离状态下 Nmap 能够识别出 13 个服务器中的 9 个并出现错误分类,而 Untangle 能检测到所有服务器并没有错误分类。下表展示了按层细分的准确率结果,在756 种排列组合中,Nmap 仅正确检测到 450 种排列组合中的第 1 层服务器。由此可见,Untangle 在单层服务器识别上优于 Nmap,并且是目前唯一能有效识别多层服务器架构的工具。
4、总结
本文提出了一种多层 Web 服务器指纹识别方法,通过利用 HTTP 处理差异,实现了对三层结构的精准指纹识别。与现有方案相比,Untangle 克服了传统工具在多层架构识别方面的固有缺陷。尽管该方法并不完善且存在依赖服务器差异的局限性,但实验证明其实际应用是可行的。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
