基本信息
原文标题:MultiPhishGuard: An LLM-based Multi-Agent System for Phishing Email Detection
原文作者:Yinuo Xue, Eric Spero, Yun Sing Koh, Giovanni Russello
作者单位:University of Auckland, Auckland, New Zealand
关键词:钓鱼邮件检测,大语言模型,多智能体系统,强化学习,对抗训练
原文链接:https://arxiv.org/abs/2505.23803
开源代码:暂无
论文要点
论文简介:该论文提出了MultiPhishGuard,一种面向钓鱼邮件检测任务的、基于大语言模型(LLM)、多智能体协作的检测系统。论文针对日益复杂且多变的钓鱼邮件攻击现状,指明传统基于规则和拒绝列表(denylist)方法难以跟上攻击策略演化的步伐,导致检测准确率不高。
基于机器学习的新方法虽已提升性能,但仍对新型伪装和未见攻击手法适应不佳。MultiPhishGuard创新性地将多种专门化的LLM智能体(包括文本、URL、元数据、对抗生成和解释简化智能体)集成于统一系统,借助Proximal Policy Optimization(PPO)强化学习算法动态调整各智能体决策权重。此外,系统设计了对抗训练模块,利用对抗智能体生成贴近现实且难以识别的变种邮件,实现系统的自我进化和稳健性提升。
实验证明,MultiPhishGuard在多个公共数据集上显著优于主流的单智能体、Chain-of-Thoughts和RoBERTa-base等方法,具有极高的检测准确率及良好的可解释性,为钓鱼邮件检测提供了新的技术路径和理论支撑。
研究目的:本研究旨在解决当前钓鱼邮件检测中亟需突破的核心瓶颈。传统方法面对攻击策略的持续进化(如社交工程、域名欺骗、动态URL混淆等)已难以胜任,且容易产生较高假阳性和假阴性。现有深度学习与LLM方案虽能捕捉部分上下文语义特征,但大多仅聚焦于单一模态,且缺乏透明、可解释的判决依据,也较难适应新出现的高级钓鱼手法(如AI生成式钓鱼)。
因此,作者提出设计一种具备多模态集成、动态权重自适应、对抗鲁棒性与结果可解释性的全新检测体系,能够从邮件文本、URL、元数据等多源信息协同判别,并通过对抗训练持续演进模型抵御未知威胁。此外,考虑实际应用的用户信任构建,系统特设易于理解的解释生成机制,使安全分析人员与普通用户皆能掌握检测结论的依据,提升整体邮件安全防护能力。
研究贡献:
论文主要贡献体现在如下四个方面:
1. 提出MultiPhishGuard系统——首个集成多种基于LLM的智能体(文本、URL、元数据分析),实现多模态协同的钓鱼邮件检测框架,并公开代码,助力结果复现;
2. 在体系中引入对抗智能体,生成巧妙的钓鱼和合法邮件变种,加强模型抵抗新型对抗手法、提升检测鲁棒性;
3. 设计解释简化智能体,将多智能体复杂推理过程融合并转化为清晰、非技术化的解释输出,便于用户理解和信任模型判决;
4. 在六个公开数据集上系统评估模型,实测F1分数高达95.88%,在多种真实场景中均优于现有主流方法,有力证明了框架的通用性与有效性。
引言
钓鱼攻击作为网络安全领域最具持久性和破坏性的威胁之一,长期以来都是数据泄露和经济损失的主要根源。根据APWG组织及Verizon等最新报告,仅2024年第三季度全球已观测到近百万起钓鱼事件,且攻击手法不断进化,从早期单纯欺骗逐步演化为社会工程、鱼叉式攻击甚至基于人工智能的自动生成欺骗内容。许多攻击能够绕过传统垃圾邮件过滤器,成为引发重大数据泄露事件的首要入口。最新形势要求钓鱼邮件检测系统具备高度的适应性和鲁棒性,以持续应对复杂多变的威胁态势。
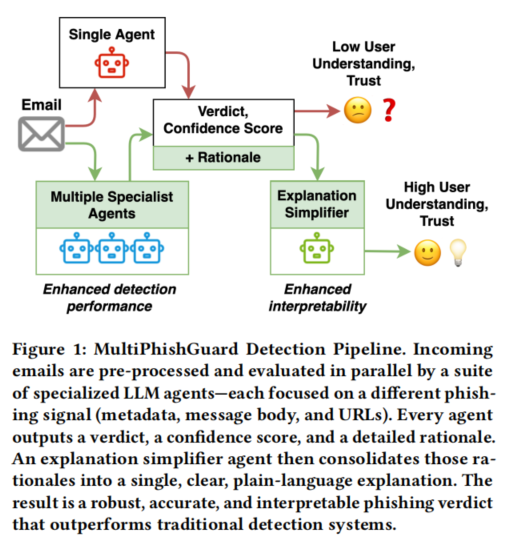
传统上,钓鱼检测多数依赖规则引擎和拒绝列表机制,诸如黑名单或签名匹配,但经历过度依赖静态特征,难以应对域名伪造、URL混淆等策略,导致灵活性和适应性明显不足。随着机器学习和深度学习的涌现,研究者已开发出能自动学习复杂文本和结构模式的模型(如BERT等预训练语言模型),一定程度上提升了检测准确率,但大多只关注邮件的文本或URL,不易扩展至元数据等其他关键模态,而且“黑盒”性质造成决策过程难以解释,降低了实际应用中的透明性和用户信任。部分基于大语言模型(LLM)的单智能体体系展现了对多样、细粒度钓鱼特征的自然理解优势,但同样存在“仅给出二元输出、推理过程不透明、适应性欠佳”等瓶颈。
本文基于上述现状,提出采用多智能体协作机制,整合文本、URL和元数据三大模态分析,同时在系统层面引入强化学习,以实现针对具体邮件特征的动态权重调整,有效缓解误报漏报问题。为进一步提升系统的攻防对抗能力,MultiPhishGuard特设对抗智能体,迭代生成各类隐蔽变种,强化整体鲁棒性。为满足普适可用性的解释需求,还设计了专门的解释简化智能体,将各分析结果合成为形式简洁、普适易懂的最终解释。因此,MultiPhishGuard不仅在架构和技术机制上追求攻击面全覆盖,更兼顾用户侧的可解释性和信任培育,以适应日益复杂和动态演变的电子邮件钓鱼威胁场景。
相关工作与理论基础
钓鱼邮件检测领域经历了从早期基于启发式规则和拒绝列表到机器学习和深度学习方法的变革。最初的工作多依赖固定规则、黑名单和签名匹配,这些手段易于实现但难以跟上攻击者创新手法,诸如域名仿冒、URL动态混淆、社会工程攻击等,令检测系统频繁失效。
随着机器学习发展,研究者采用特征提取(如TF-IDF等)及决策树、随机森林等传统分类算法,对邮件的文本模式进行自动识别。进入深度学习时代,BERT等预训练模型通过上下文建模,显著提升了对复杂文本的钓鱼识别准确率,但大多聚焦于单一文本模态,并未充分融合URL、元数据等多维信息。与此同时,部分研究者尝试引入神经网络自动提取多层次语义和结构特征,以期突破静态特征局限,但这些模型普遍缺乏对多模态信息的集成处理,且依然难以适应高级攻击的新变体。
强化学习在智能决策系统中展现了强大的自适应能力,能够基于环境反馈动态优化参数。Proximal Policy Optimization(PPO)等现代RL算法为多智能体协同策略分配提供了稳定高效的理论支持。本文正是将RL机制引入多智能体系统,实现每轮针对邮件特征自动调整子系统权重,从而增强决策的自适应性和鲁棒性。
对抗训练则是提升机器学习模型安全性和抗攻击能力的重要手段。通过生成并引入对抗样本,能够有效揭示模型弱点,促进检测系统对现实复杂场景的泛化和鲁棒性提升。本文在架构中引入专门的对抗智能体,借助LLM的语言生成能力,创造拟态性极强的钓鱼与合法邮件变种,进一步提升模型的攻防能力。
解释性与可解释性则是近年来机器学习系统落地的重要方向。法规合规(如GDPR)对决策透明性提出了严格要求,模型输出需为用户和安全分析师所理解。本文设计解释简化智能体,将多智能体复杂推理输出整合为简明、清晰、易于理解的解释,平衡模型判别深度与用户可用性之间的矛盾。
多智能体系统最早用于解决大规模、复杂问题的子任务分解与协同决策,有效促进了专业分工与集成优化。LLM赋能下的多智能体系统已在复杂任务中的分工协作、大规模主题分析等方面崭露头角,体现出在多模态、智能分布决策领域的独特优势。作者正是基于这一趋势,提出将多智能体架构迁移至钓鱼邮件检测领域。
MultiPhishGuard方法框架与实现
MultiPhishGuard采用LLM为核心的多智能体架构,系统性整合文本、URL和元数据三大专用分析智能体,并引入对抗训练机制以及解释简化智能体,实现动态、适应性强且具备判决透明度的钓鱼邮件检测。整体方法框架如下:
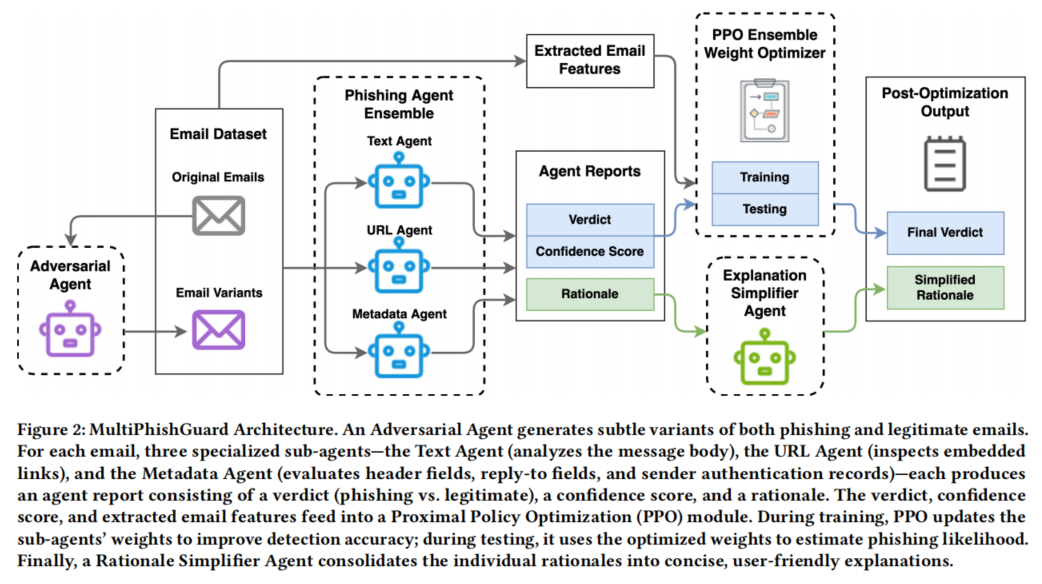
首先,系统对邮件进行预处理后,分别输入至文本、URL和元数据三种智能体。文本分析智能体使用定制化Prompt,聚焦于文本内容的异常语言模式、钓鱼关键词及其他潜在恶意信号,对其给出判决标签、置信度和详细推理理由。URL智能体则专注于所有邮件中的链接,分析其是否存在域名伪装、短链接、重定向等可疑特征,输出判决与解析。元数据智能体负责检查邮件头部(如发件人认证SPF/DKIM/DMARC、回复地址、Header异常等)是否存在伪造及异常,辅助检测高阶欺骗策略。各个智能体均以明确分工、独立判别的方式输出结构化结果。
在决策融合层,MultiPhishGuard引入基于PPO的强化学习模块,对每一封邮件根据其特征(如URL数量、钓鱼关键词、发件人信誉等)动态调整三大智能体的权重值。该模块将所有判决与置信度作为输入,实时学习最优权重分配方案,以最大化检测准确率并兼顾误报率与漏报率,实现自适应决策优化。权重训练采用PPO算法,以分类准确度为奖励信号,确保优化过程的稳定和高效。
为增强模型鲁棒性,对抗训练模块引入Adversarial Agent——基于GPT-4o的强大生成模型,负责持续生成伪装巧妙(如同义替换、句式变换、内容删改、同形异义字符替换等多种策略)且能规避既有检测模型的钓鱼/合法邮件变种。每轮对抗样本均输入至主检测模型,若模型误判,则作为“难点样本”增强训练。此生成-判别-反馈循环持续进行,促进模型攻防能力共同提升,有效应对现实场景中不断升级的钓鱼策略。
解释简化智能体承担着将多模态推理结论转化为明白易懂、无技术门槛的综合解释任务。系统聚合各子智能体的理由,并经专用Prompt约束,去除冗余技术细节和术语,以通俗语言为用户解释何种特征导致邮件被判为钓鱼或合法。同时,支持专家模式可输出更详细的技术性反馈。此功能为用户普及安全意识、提升系统可用性和建立信任提供了坚实基础。
整个框架的各环节采用模块化设计,核心组件基于AutoGen平台实现,均支持JSON等结构化输出格式,利于系统整合和后续分析,以及便于复现和拓展应用场景。
实验设计与评估指标
论文在六个流行公开邮件数据集上对MultiPhishGuard进行了系统评估,分别包括Nazario phishing corpus、Enron-Spam、TREC 2007、CEAS 2008、Nigerian Fraud和SpamAssassin等。这些数据集覆盖近年大量真实及模拟钓鱼和合法邮件样本,为多场景下模型泛化能力和鲁棒性测试提供了坚实基础。总体实验数据样本分布约为979封钓鱼邮件和3000封合法邮件,按1:3比例,充分衡量系统在实际不均衡环境下的检测性能。
评测指标采用业界标准,包括召回率(Recall)、准确率(Accuracy)、精确率(Precision)、F1分数、真负率(TNR)、假正率(FPR)、假负率(FNR)等。召回指标衡量系统漏报(未识别钓鱼)风险,准确率与精确率关注系统整体和对实战场景的准确判定。F1分数则综合考虑误报/漏报平衡。多指标交叉考察,确保模型在实际部署中的安全性和用户体验。
为衡量解释输出的可读性与一致性,特别引入Perplexity(困惑度)、Topic Coherence(主题一致性)和Flesch Reading Ease Score(易读性评分)等自动化语言评价指标,辅以人工专家与用户多轮对照实验,通过ROUGE分数和余弦相似度比对系统与专家给出的解释准确度。这一设计不仅重视模型“判别能力”,同样聚焦模型解释性的科学量化,有力促进了透明AI的实际落地。
除主实验外,论文还涵盖多种对比实验方案(如Chain-of-Thought prompting、单智能体模型、RoBERTa-base),并全面展开消融实验(去除URL、元数据智能体、对抗智能体、解释器、静态与动态权重对比)和McNemar’s检验,以多角度、多维度严密验证各模块对整体性能的实际贡献和提升效果。
实验结果与分析
实验结果显示,MultiPhishGuard在整体检测任务上达到极佳性能。在全量样本(近4000封邮件)测试中,其召回率高达99.80%,准确率达到97.89%,F1分数95.88%,并将假阳性率控制在2.73%,假阴性仅为0.20%。相比Chain-of-Thoughts方法、单智能体LLM、RoBERTa-base等主流基线(后者F1分数仅为78.45%-91.89%,假正率高达17.47%-20.47%),MultiPhishGuard在所有主指标上具有全面领先优势。
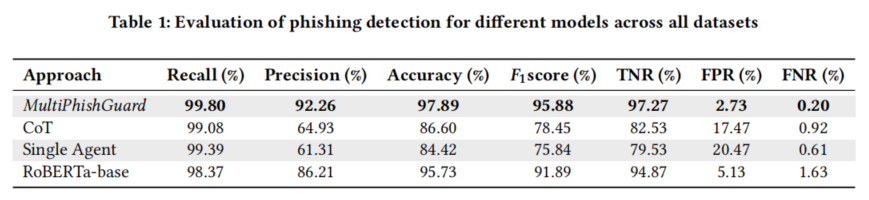
模型的多模态集成和动态权重机制极大改善了误判和漏判问题。尤其是在应对混合、隐蔽性强的钓鱼技巧(如URL伪装、元数据欺骗)时,通过结构化决策机制提升了系统面向复杂邮件体的泛化性和适应力。
消融实验揭示,去除URL分析智能体将造成检测准确度显著下降,说明URL模态在钓鱼邮件判别中作用突出。静态权重模式相比动态权重,表现同样有所回落,佐证强化学习驱动的自适应策略在复杂场景下的效能优势。对抗智能体缺失则导致系统对新型和拟态钓鱼邮件的鲁棒性下降,难以真实应对“攻防演进”的现实需求。元数据智能体的去除,也会令系统对复杂伪装策略失守于漏洞。
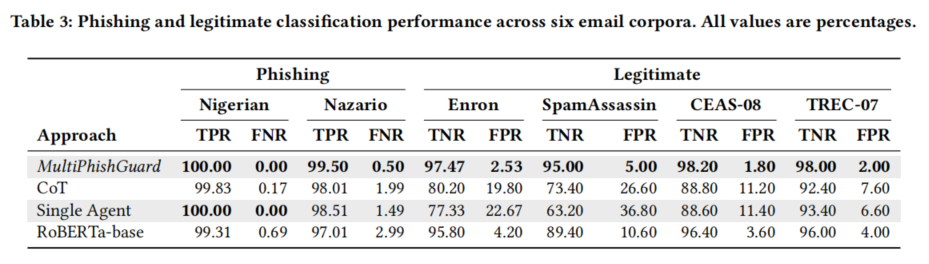
在解释可读性方面,多智能体+专用解释器的体系能生成语义流畅(困惑度低至25)、主题一致性好(coherence 0.35)、易读性高(FRES得分41)的判决理由,远优于Chain-of-Thoughts及单体解释(FRES仅21-27)。通过专家人工标注与系统输出的ROUGE-1和余弦相似度对比,MultiPhishGuard能更好地捕捉专家分析核心要素(ROUGE-1达0.59,Cosine达0.82),且解释内容既能复现关键判断逻辑,也能针对性指出诸如不规范署名、异常链接、欺骗性头信息等易被人类忽视的重要信号,突显其在辅助实际邮件安全分析与培训中的价值。
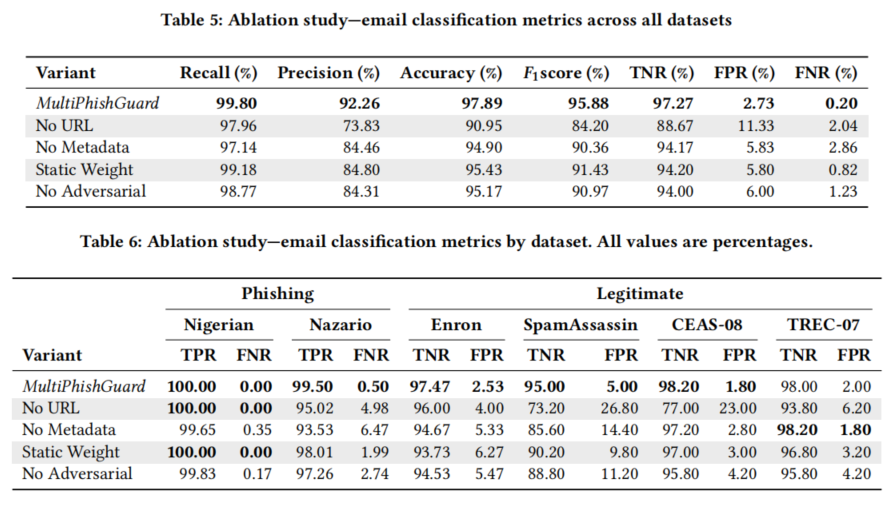
此外,McNemar’s检验在多组对比与消融实验中均显示MultiPhishGuard显著减少误判与漏报,稳定性、普适性和安全性再度得到量化支撑。专家和普通用户反馈的可解读性质量分析也证明了解释简化智能体对用户理解体验的提升。
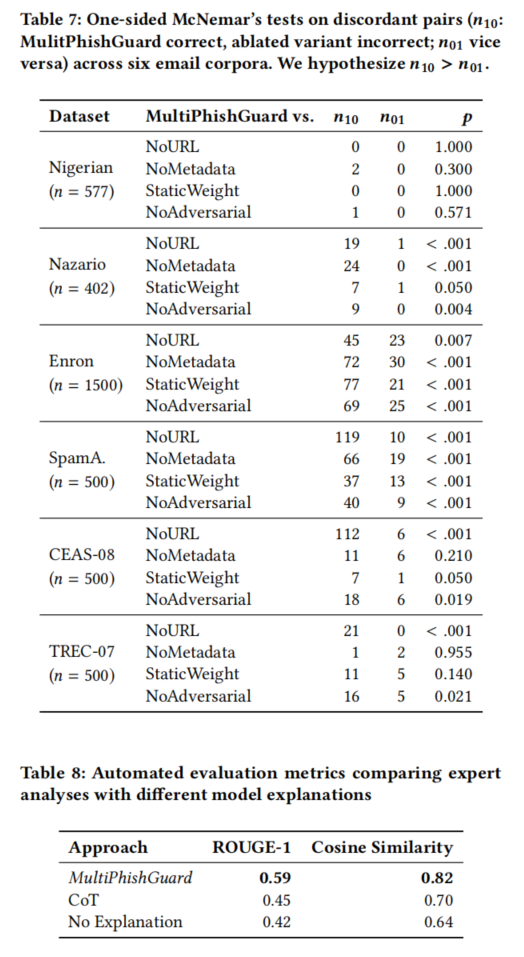
总之,MultiPhishGuard在系统融合度、检测精度、对抗鲁棒性与解释性方面均取得了突破性进展,有效回答了论文在引言提出的关键科学与应用问题。
论文结论
论文总结认为,MultiPhishGuard创新性地整合LLM基础上的多智能体架构、动态权重调节机制与对抗样本训练,实现了检测准确性与结果可解释性的统一突破。实测数据显示,该系统在实际复杂环境下检测表现优异,显著提升了钓鱼邮件拦截能力,并在多模态集成、透明性与信任建立、可持续自进化等核心层面均具备国际领先优势。论文也坦诚指出当前主要限制:如解释性效果缺乏细粒度的标注数据作为严格对标,仅能通过可读性等间接指标衡量;以及高质量开放数据集、对标代码资源有限。
未来研究可深化更多模态集成(如附件、行为特征)、提升专家模式解释能力、扩展高质量对比评测,进一步推广多智能体+LLM架构在网络安全其他领域(如恶意网站检测、APT溯源中的应用)。此外,论文强调伦理与安全风险,严格控制对抗样本生成过程,规避潜在的邮件仿冒和攻击行为落地。
总体来看,MultiPhishGuard为建立可扩展、可解释、可持续演进的下一代邮件安全防御体系提供了坚实理论和实证基础,代表着LLM与多智能体架构在真实世界安全领域的前沿探索和实践路径。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
