
原文标题:A comprehensive survey on cyber deception techniques to improve honeypot performance
原文作者:Amir javadpour, Forough ja"fari, Tarik Taleb, Mohammad Shojafar, Chafika Benzaid
原文链接:https://www.sciencedirect.com/science/article/pii/S0167404824000932?via%3Dihub
发表会议:Computers & Security
笔记作者:张琦驹@安全学术圈
主编:黄诚@安全学术圈
编辑:张贝宁@安全学术圈
1、引言
网络威胁(Cyber Threats)持续升级,以 Mirai 僵尸网络(Mirai Botnet)为例,其通过控制物联网(IoT)设备发起分布式拒绝服务攻击(DDoS),且变种不断优化恶意功能,导致僵尸网络数量翻倍,关键资产面临严重威胁。传统安全工具如防火墙(Firewall)、入侵检测系统(IDS)等存在局限:既难以检测零日漏洞(Zero-Day Vulnerabilities),也无法深度分析攻击者行为。 蜜罐(Honeypot)作为欺骗性工具,虽具备低误报率、可捕获攻击者行为的优势,但面临两大问题:一是专业攻击者(Professional Adversaries)通过指纹识别等手段绕过蜜罐;二是现有研究多聚焦单蜜罐,缺乏对蜜网(Honeynet,多蜜罐协作网络)欺骗技术的系统分类与统一评估模型,开发者与研究者难以横向对比选型。 为填补空白,本文围绕 “网络欺骗技术提升蜜罐性能” 展开综述,核心解决:蜜罐选型指标、单蜜罐 / 蜜网欺骗技术、蜜网数学建模等关键问题,为相关从业者提供从理论到实践的参考,推动蜜罐技术向主动防御升级。
2、蜜罐分类体系与有效性评估方法
蜜罐的合理选型与效果量化是其落地应用的核心前提。本文从 “场景适配” 角度构建蜜罐分类体系,明确不同类型蜜罐的核心特征与适用场景;同时建立多维度评估框架,结合实验验证确保蜜罐性能可衡量、可对比,为开发者提供 “选 - 评” 一体化参考。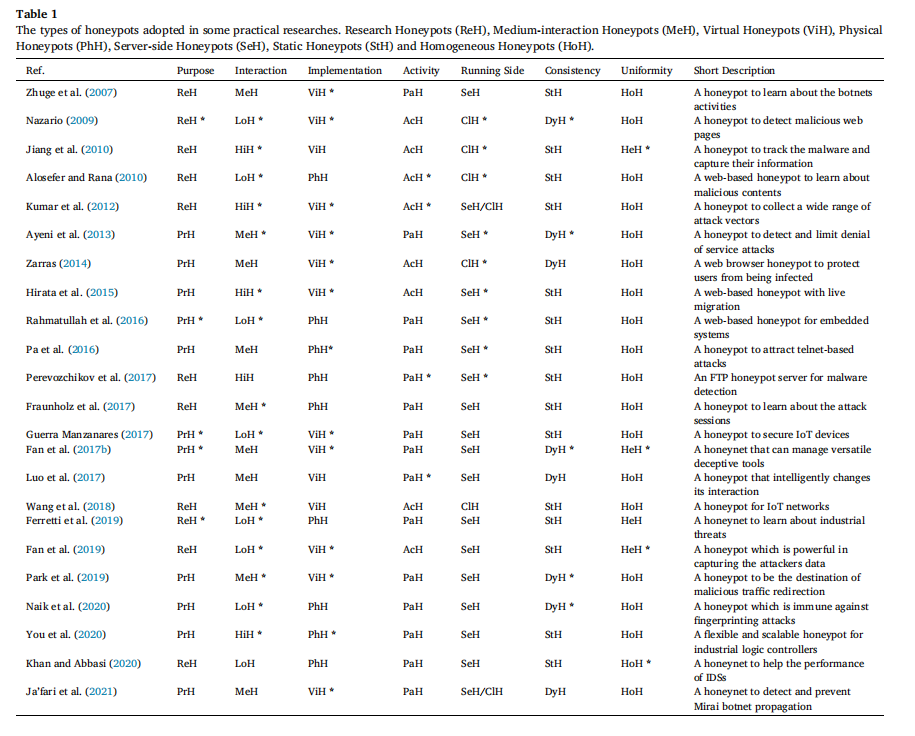
2.1 蜜罐分类体系:基于 7 大维度的场景化划分
论文通过 7 个核心维度对蜜罐进行系统分类,覆盖从技术实现到应用目标的全场景需求,且每个维度均配套实际研究案例(汇总于表 1),帮助开发者快速匹配场景与蜜罐类型。
按核心目的划分:分为研究型蜜罐(Research Honeypots, ReH)与生产型蜜罐(Production Honeypots, PrH)。前者以收集攻击数据、分析威胁模式为目标,如 Ferretti 等人(2019)设计的工业威胁研究蜜罐,需模拟完整工业控制场景,复杂度高;后者聚焦真实网络防护,如 Guerra Manzanares(2017)的物联网(IoT)保护蜜罐,部署维护简单,无需收集完整攻击数据。
按交互程度划分:涵盖高交互蜜罐(High-interaction Honeypots, HiH)、低交互蜜罐(Low-interaction Honeypots, LoH)与中交互蜜罐(Medium-interaction Honeypots, MeH)。HiH 如 You 等人(2020)的工业逻辑控制器蜜罐,模拟完整系统与服务,能捕获深度攻击行为但资源消耗大;LoH 如 Fan 等人(2019)的攻击者数据捕获蜜罐,仅模拟关键服务,易部署且风险低;MeH 如 Fraunholz 等人(2017)的 Telnet/SSH 服务模拟蜜罐,平衡交互深度与资源成本。
按实现方式划分:包括物理蜜罐(Physical Honeypots, PhH)与虚拟蜜罐(Virtual Honeypots, ViH)。PhH 如 IoTPOT(Pa 等人,2016),基于独立硬件部署,安全性高但成本昂贵;ViH 如 HoneyIo4(Guerra Manzanares,2017),可在单物理服务器上部署多个,低成本且易扩展。
按活动状态划分:分为被动蜜罐(Passive Honeypots, PaH)与主动蜜罐(Active Honeypots, AcH)。PaH 如 Perevozchikov 等人(2017)的 FTP 恶意软件检测蜜罐,仅等待攻击者连接;AcH 如 Kumar 等人(2012)的攻击向量收集蜜罐,通过伪造脆弱服务主动吸引攻击者。
按运行端划分:分为服务器端蜜罐(Server-side Honeypots, SeH)与客户端蜜罐(Client-side Honeypots, ClH)。SeH 如 Pa 等人(2016)的 Telnet 攻击吸引蜜罐,用于检测恶意客户端;ClH 如 Zarras(2014)的恶意网页检测蜜罐,伪装成浏览器识别恶意服务器。
按一致性划分:包括静态蜜罐(Static Honeypots, StH)与动态蜜罐(Dynamic Honeypots, DyH)。StH 如 ThingPot(Wang 等人,2018),配置固定易被识别;DyH 如 Naik 等人(2020)的抗指纹攻击蜜罐,可自适应网络变化调整行为。
按统一性划分:分为同构蜜罐(Homogeneous Honeypots, HoH)与异构蜜罐(Heterogeneous Honeypots, HeH)。HoH 如 Khan 等人(2020)的入侵检测系统(IDS)辅助蜜网,采用单一诱饵类型;HeH 如 Fan 等人(2019)的多类型诱饵蜜网,通过多样化诱饵提升检测能力。
为进一步指导选型,论文提出 6 个功能指标(Implementation Cost, ImCo;Design Complexity, DeCo;Compromising Risk, CoRi;Collected Data, CoDa;Deception Power, DePo;Handled Connections, HaCo),并通过图 2 直观对比不同类型蜜罐在各指标上的优劣(如 HiH 的 CoDa、DePo 更高,但 ImCo、DeCo 也更高;LoH 则相反),帮助开发者根据资源约束与安全目标决策。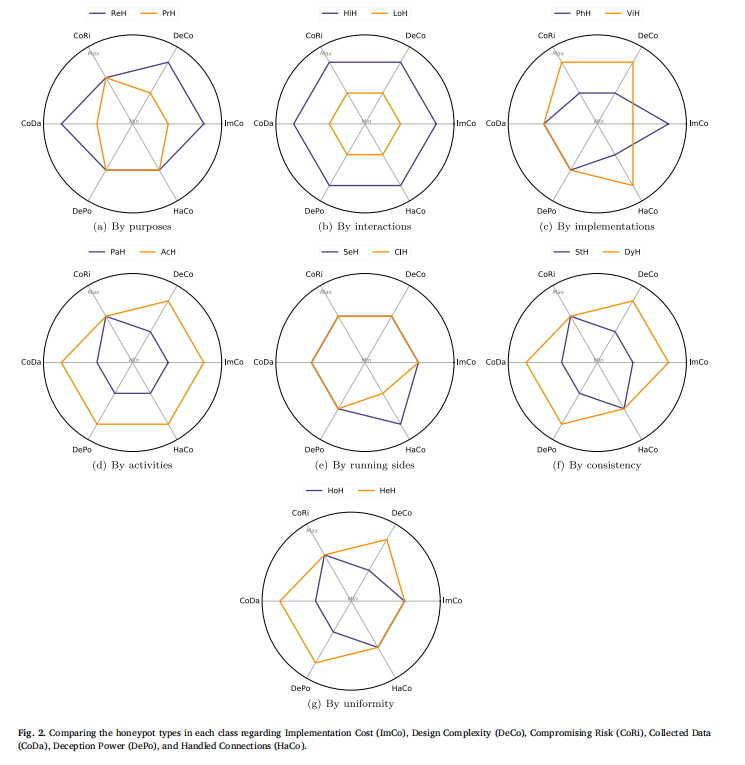
2.2 蜜罐有效性评估方法:从技术指标到实验验证
论文构建 “技术指标 + 红队实验 + 模拟验证” 的三层评估框架,确保蜜罐性能可量化、可复现,避免传统评估 “重定性轻定量” 的缺陷。
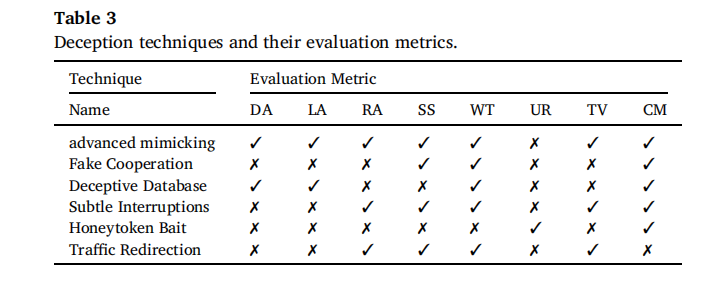
核心评估指标:针对单蜜罐,提出 7 个关键指标(Difference Amount, DA;Launched Attacks, LA;Returned Adversaries, RA;Second Session, SS;Wasted Time, WT;Using Ration, UR;Traffic Volume, TV;Confusion Matrix, CM)。其中 DA 衡量蜜罐与真实系统的差异度(如服务响应差异),LA 统计攻击次数,WT 记录攻击者耗时,UR 计算蜜令牌使用率,CM(混淆矩阵)区分真实攻击者与误判(蜜罐的 False Positive, FP 接近零);针对蜜网,补充 “攻击成功率”“恶意软件传播抑制率” 等指标,如通过计算攻击者突破蜜网的概率评估整体防御效果。
红队实验验证:参考 Ferguson-Walter 等人(2021)的研究,通过 130 名专业红队成员开展受控网络渗透测试,模拟真实攻击者的动机与策略。实验对比 “仅部署诱饵”“诱饵 + 明确欺骗告知”“无欺骗(对照组)” 三种场景,结果显示 “诱饵 + 明确欺骗告知” 对攻击者行为的干预效果最显著 —— 攻击者的攻击进度延缓 30% 以上,且更易暴露战术,证明欺骗技术的实际价值。
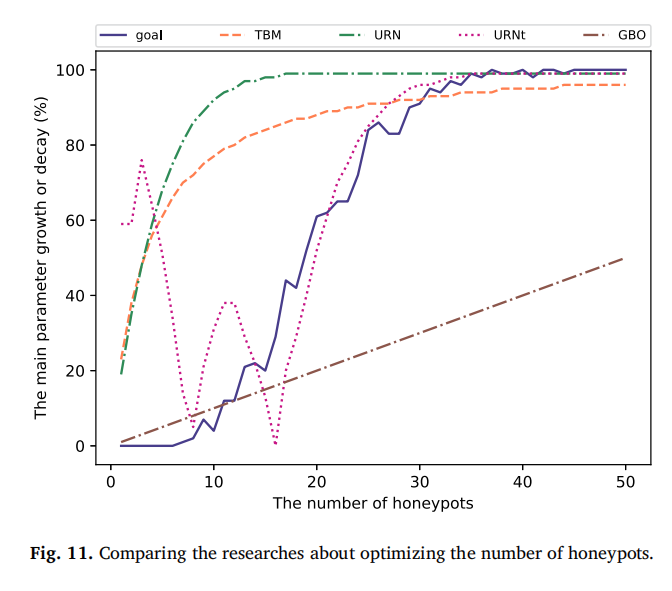
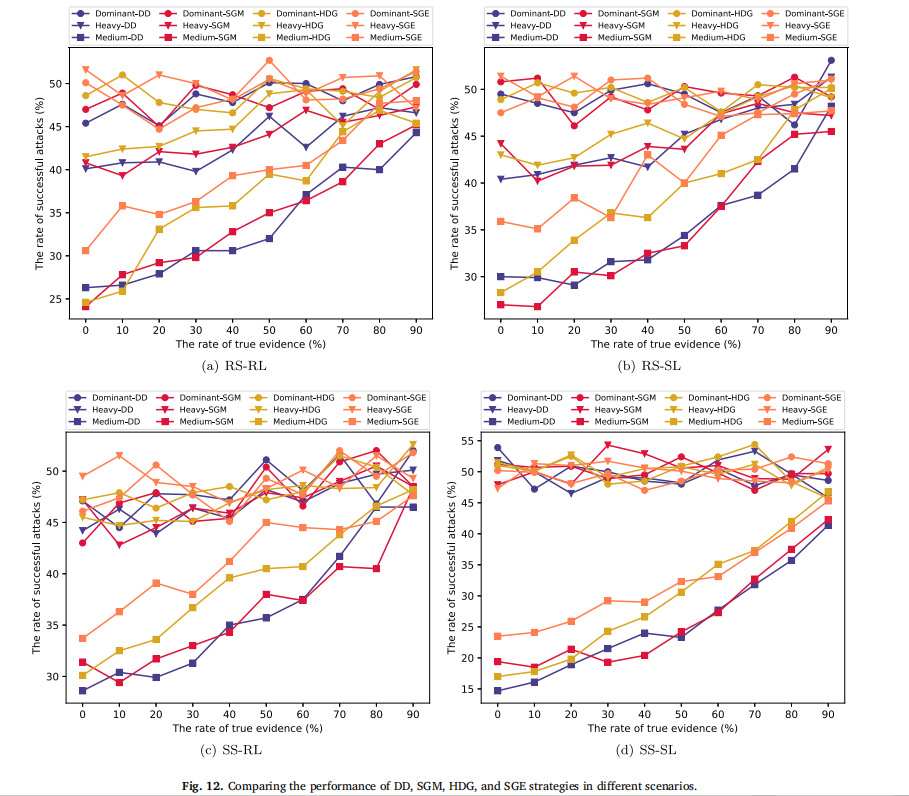
模拟场景验证:论文采用 Python 构建多组模拟实验,验证核心技术效果。例如,在 “蜜罐数量优化” 场景中(图 11,论文中 Fig. 11),对比 TBM、URN、URNt、GBO 四种模型在 100 节点网络中的表现,结果显示 URNt 模型(考虑蜜罐连接阈值)的攻击者成功攻击率比其他模型低 15%-20%;在 “蜜罐动态化” 场景中(图 12,论文中 Fig. 12),测试 DD、SGM、HDG、SGE 四种技术在 “随机扫描 - 随机部署”“顺序扫描 - 顺序部署” 等场景的效果,发现 DD 与 SGM 模型的攻击者误判率比 HDG、SGE 高 10%-18%,更适合多数网络环境。
3、单蜜罐的欺骗技术
单蜜罐是蜜网防御的基础单元,其核心价值在于通过精准欺骗吸引攻击者、收集攻击数据。论文系统梳理了 6 类提升单蜜罐性能的欺骗技术,每类技术均围绕 “降低识别概率、延长交互时间、提升数据质量” 设计。
3.1 高级模拟(Advanced Mimicking):提升蜜罐真实感
 高级模拟通过 “复刻真实系统特征 + 伪造高吸引力漏洞”,让蜜罐在外观与功能上接近真实资产,避免被攻击者指纹识别,其核心逻辑与场景如图 5 所示,主要包含两大方向:
高级模拟通过 “复刻真实系统特征 + 伪造高吸引力漏洞”,让蜜罐在外观与功能上接近真实资产,避免被攻击者指纹识别,其核心逻辑与场景如图 5 所示,主要包含两大方向:
完美模仿真实系统:从细节层面复刻真实系统的响应特征,消除蜜罐 “指纹”。例如,Dahbul 等人(2017)通过向 HoneyD、Dionaea 等主流蜜罐发送指纹探测请求,发现 “开放端口监控不足、时间戳异常、脚本配置缺陷” 是蜜罐被识别的关键,因此建议优化蜜罐的端口响应、同步真实系统时间戳、修改默认脚本;Naik 等人(2020)则聚焦 TCP/IP 协议头细节,强调模拟真实系统时需精准匹配 TCP 窗口大小、IP 生存时间(Time to Live, TTL)等字段,避免因协议特征异常暴露身份;Chen 和 Buford(2009)还设计可被搜索引擎爬取的蜜罐数据库系统,让蜜罐在网络探测中呈现 “真实可发现” 的特征,进一步提升可信度。
伪造吸引性漏洞:针对攻击者关注的高价值漏洞或服务,主动注入仿真脆弱点。Shumakov 等人(2017)通过分析 4 个网站的攻击数据,发现 PHP 和 MySQL 服务是攻击者的主要目标,因此建议在蜜罐中部署这两类服务替代低吸引力服务;Perevozchikov 等人(2017)则通过 FTP 和 MySQL 数据库服务吸引攻击者,收集恶意软件样本;Huang 等人(2020)更进一步,提出自动生成 “可利用数据库漏洞” 的方法,让蜜罐的漏洞特征更符合真实攻击场景,提升对专业攻击者的吸引力。 该技术的评估核心是 “欺骗差异度(Difference Amount, DA)”—— 即蜜罐与真实系统的响应差异,DA 越低说明真实感越强;同时结合 “攻击次数(Launched Attacks, LA)”“回访次数(Returned Adversaries, RA)” 衡量吸引力,如吸引性漏洞可显著提升 LA 与 RA(表 3)。
3.2 虚假协作(Fake Cooperation):延长攻击者交互
 虚假协作通过 “假装被攻陷 + 协助攻击者行动”,让攻击者误以为攻击成功,从而延长交互时间、暴露更多战术,其场景逻辑如图 6 所示,分为两种核心模式:
虚假协作通过 “假装被攻陷 + 协助攻击者行动”,让攻击者误以为攻击成功,从而延长交互时间、暴露更多战术,其场景逻辑如图 6 所示,分为两种核心模式:
展示攻击成功:模拟攻击生效的假象,如系统崩溃、数据泄露等。Chen 和 Buford(2009)设计的 SQL 注入欺骗数据库,在检测到攻击者注入行为后,会假装被攻陷并返回伪造的敏感数据(如虚假用户密码),让攻击者误以为获取了真实信息;Wagener 等人(2009)则通过双人博弈模型,计算 “蜜罐假装被攻陷的安全阈值”—— 在确保自身不被滥用的前提下,选择合适时机展示攻击成功,平衡欺骗效果与安全风险。
假装协助攻击者:模拟被攻击者控制的 “傀儡主机”,配合其恶意行动。Zhuge 等人(2007)的 HoneyBot 蜜罐,伪装成被僵尸网络感染的主机,模仿僵尸节点的通信行为(如向僵尸主控端报告虚假设备信息);Jiang 等人(2010)的僵尸网络追踪工具,通过模拟僵尸节点与其他成员的交互,收集僵尸网络的命令结构与传播逻辑;Hayatle 等人(2012)还通过贝叶斯博弈模型优化协作策略,让蜜罐在 “服从命令” 与 “避免暴露” 间找到平衡,提升攻击者对蜜罐的信任度。 该技术的关键评估指标是 “攻击者耗时(Wasted Time, WT)” 与 “二次会话数(Second Session, SS)”—— 虚假协作越逼真,WT 越长,攻击者发起 SS 的概率越高(表 3 )。
3.4 细微干扰(Subtle Interruptions):消耗攻击者资源
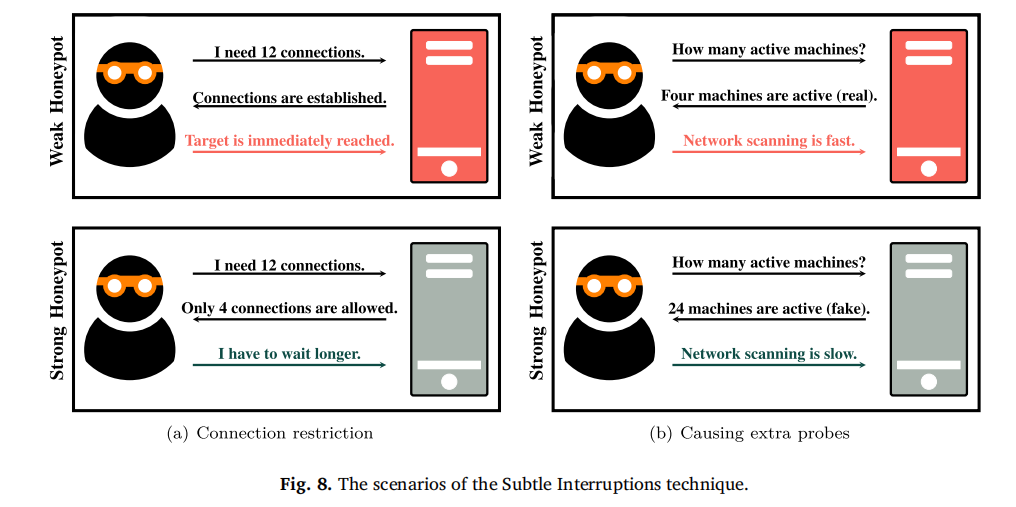 细微干扰通过 “限制连接 + 增加探测成本”,延缓攻击者进度、消耗其时间与资源,同时避免因干扰过度暴露蜜罐身份,其场景如图 8 所示,主要包含两种手段:
细微干扰通过 “限制连接 + 增加探测成本”,延缓攻击者进度、消耗其时间与资源,同时避免因干扰过度暴露蜜罐身份,其场景如图 8 所示,主要包含两种手段:
连接限制:控制攻击者的连接效率。Dantu 等人(2007)通过限制感染主机的新连接数,减缓恶意软件传播速度;Sun 等人(2017)则限制蜜罐的连接队列长度,让攻击者的请求排队等待,延长攻击周期,同时这种 “缓慢响应” 可伪装成系统负载过高,降低攻击者怀疑。
引发额外探测:扩大攻击者的目标范围,增加无效操作。Gjermundrød 和 Dionysiou(2015)的 CloudHoneyCY 蜜罐开放所有端口,对攻击者的端口扫描返回混乱响应,迫使攻击者花费更多时间排查有效端口;Shakarian 等人(2014)在网络中添加 “干扰集群”(连接的诱饵节点),让网络拓扑看起来更复杂;Achleitner 等人(2017)则通过虚拟拓扑技术,构建需要长时间扫描的网络结构,进一步消耗攻击者资源;Pauna 等人(2018)、Suratkar 等人(2021)还通过强化学习让蜜罐自主学习 “如何交互能最大化攻击者耗时”,提升干扰的智能性。 该技术的评估指标包括 “二次会话数(SS)”“攻击者耗时(WT)” 与 “流量体积(Traffic Volume, TV)”—— 干扰越隐蔽有效,SS 越低(攻击者不愿重复尝试),WT 越长,TV 也因额外探测而增加(表 3 )。
3.5 蜜令牌诱饵(Honeytoken Bait):追踪攻击者行为
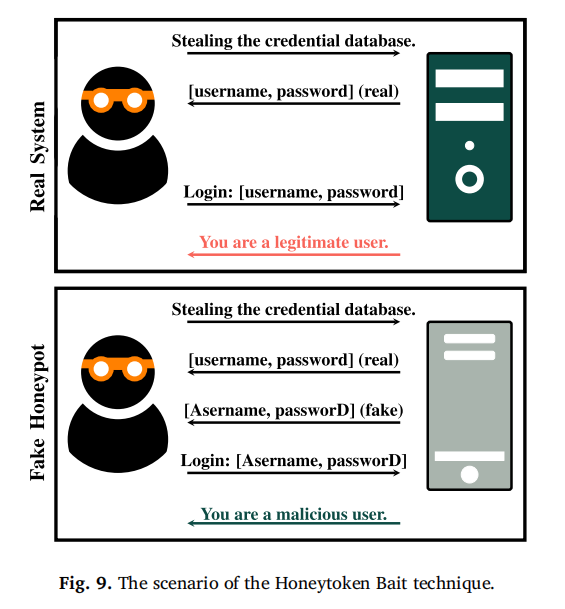 蜜令牌是 “无真实价值但可追踪的虚假信息”,通过 “生成高仿真令牌 + 部署追踪机制”,定位攻击者身份与行动轨迹,其场景如图 9 所示,分为两大环节:
蜜令牌是 “无真实价值但可追踪的虚假信息”,通过 “生成高仿真令牌 + 部署追踪机制”,定位攻击者身份与行动轨迹,其场景如图 9 所示,分为两大环节:
蜜令牌生成:确保令牌与真实信息相似,不被识破。Juels 和 Rivest(2013)通过 “修改真实密码首字符 + 末尾添加额外字符” 生成 “蜜词(Honeywords)”,如将 “password” 改为 “qassword123”;Bercovitch 等人(2011)的 HoneyGen 工具会为每个蜜令牌计算 “相似度评分”,确保其与真实数据的差异度低于攻击者识别阈值;Suryawanshi 等人(2017)则通过 “大小写转换” 生成蜜令牌(如 “Password” 改为 “pAssWord”),保留原密码的意义特征;Erguler(2016)强调生成算法需 “扁平化”,让蜜令牌符合人类设置习惯,避免因格式异常暴露。
蜜令牌使用与追踪:部署触发机制捕获攻击者使用行为。Wegerer 和 Tjoa(2016)在 MySQL 蜜罐数据库中嵌入被动 / 主动蜜令牌,被动令牌用于追踪内部攻击者(如员工泄露数据),主动令牌用于定位外部攻击者;Bowen 等人(2009)的 D³ 系统为蜜令牌添加 “信标(Beacon)”,一旦被使用就会向系统发送 “时间 + 位置” 信息;Park 和 Stolfo(2012)则将蜜令牌嵌入 Java 源代码,当攻击者编译或执行时触发警报;Ja’fari 等人(2021)还通过蜜令牌分析僵尸网络成员间的关联,还原攻击组织架构。 该技术的核心评估指标是 “使用率(Using Ration, UR)”—— 即访问蜜令牌的攻击者中实际使用的比例,UR 越高说明令牌设计越成功;同时结合 “混淆矩阵(CM)” 验证追踪准确性(表 3 )。
3.6 流量重定向(Traffic Redirection):优化攻击捕获
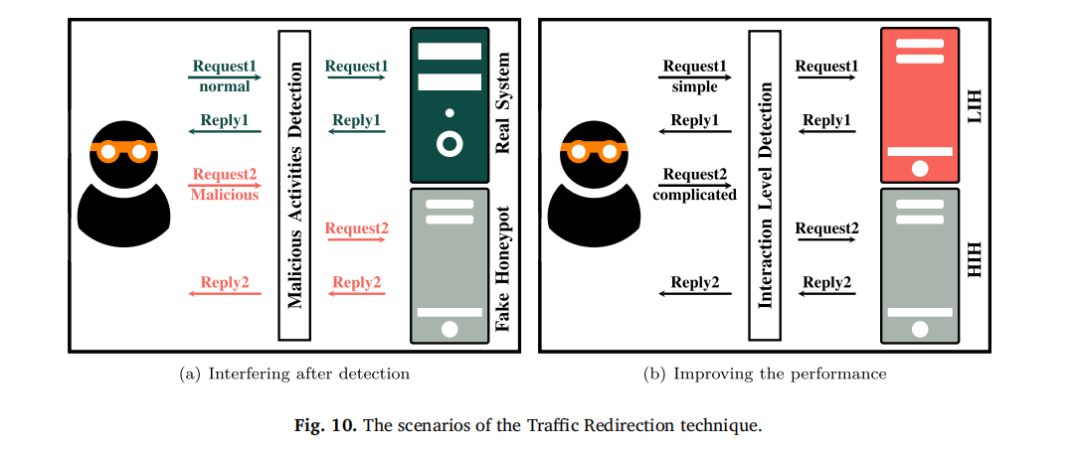 流量重定向通过 “将恶意流量导入蜜罐”,集中捕获攻击行为、保护真实资产,其场景逻辑如图 10 所示,主要分为两种应用场景:
流量重定向通过 “将恶意流量导入蜜罐”,集中捕获攻击行为、保护真实资产,其场景逻辑如图 10 所示,主要分为两种应用场景:
检测后干预:在识别恶意流量后引导至蜜罐。La 等人(2016)通过入侵检测系统(IDS)识别恶意流量,结合信号博弈模型决定 “是否重定向”,确保重定向策略的收益最大化;Selvaraj 等人(2016)将 IDS 检测到的攻击流量重定向至虚假数据库蜜罐,避免真实数据被攻击;Park 等人(2019)在软件定义网络(Software-Defined Network, SDN)中部署动态蜜罐(DVNH),作为恶意流量的重定向目标;Ja’fari 等人(2021)则通过前端蜜罐识别僵尸网络 loader 后,将其流量重定向至后端高交互蜜罐,深入收集攻击数据。
性能优化:根据攻击强度分配蜜罐资源。Wang 和 Wu(2019)将 “强攻击”(如复杂漏洞利用)重定向至高交互蜜罐,“弱攻击”(如端口扫描)重定向至低交互蜜罐,平衡数据质量与资源消耗;Fan 和 Fernández(2017)通过 Snort IDS 筛选 “高价值攻击场景”(如疑似零日攻击),将其导入专用蜜罐,提升关键威胁的数据收集效率。 该技术主要通过 “攻击者耗时(WT)” 与 “流量体积(TV)” 评估 —— 重定向越精准,WT 越长(攻击者在蜜罐中停留更久),TV 也因恶意流量集中而增加(表 3 )。
4、蜜网的欺骗技术与数学建模
蜜网(Honeynet)作为多蜜罐协作的欺骗网络,其核心价值在于通过 “协同策略优化” 提升整体防御效果。论文围绕 “如何通过蜜罐协作增强欺骗能力” 展开,将蜜网欺骗技术归纳为 5 大核心方向,并创新性提出通用数学模型,实现不同蜜网方案的统一评估与对比,为复杂网络场景的蜜网部署提供理论与实践支撑。
4.1 蜜网的欺骗技术方向
论文通过梳理近 20 年蜜网研究,将其欺骗技术按 “优化目标” 分为 5 类,每类技术均配套核心模型、实现逻辑与模拟验证,明确不同场景下的最优技术选择。
4.1.1 优化蜜罐数量:平衡防御效果与资源成本
蜜罐数量过多会增加部署成本且易暴露欺骗意图,过少则无法有效吸引攻击者。论文提出 3 类核心模型,通过量化 “攻击者成本 - 防御收益” 确定最优蜜罐数量:
TBM 模型(Tolerance-Based Model):由 Rowe 等人(2007)提出,基于 “攻击者成本容忍阈值” 计算最优数量。模型假设攻击者会放弃 “攻击成本超过预期收益” 的目标,通过计算攻击者的最大可接受成本(mc),再通过推导最优蜜罐数量(oh)—— 核心是让蜜网的攻击成本高于攻击者容忍阈值。例如,当真实主机为 80 台时,可算出 oh=15 台,此时攻击者的攻击成本超出 mc,大概率放弃攻击。
URN/URNt 模型:Crouse(2012)的 URN 模型将蜜网类比 “urn 抽样”,蜜罐(h)、脆弱主机(r)、安全主机(z)对应不同颜色的珠子,攻击者攻击 ma 台主机的 “成功概率”(至少攻击 1 台脆弱主机)通过计算;Crouse 等人(2015)的 URNt 模型进一步加入 “攻击者可接受的蜜罐连接阈值(ah)”,通过修正成功概率,更贴合真实场景(攻击者会容忍少量蜜罐连接)。
GBO 模型(Game-Based Optimizer):Fraunholz 和 Schotten(2018b)基于斯塔克尔伯格博弈(Stackelberg Competition)设计,分 “无探测攻击” 与 “有探测攻击” 两种场景。无探测场景下,通过计算最小蜜罐数量(oh=r×abᵣ/dc),使攻击者 “攻击收益 = 不攻击收益”,迫使其放弃攻击;有探测场景下,通过线性方程量化探测 - 攻击成本,结合启发式算法找到最优数量。 为验证效果,论文在 100 节点网络中模拟对比 4 种模型(TBM、URN、URNt、GBO),结果如图 11 所示:URNt 模型的攻击者成功攻击率最低(当 h=20 时,成功率仅 25%),因该模型考虑了 “蜜罐连接阈值” 这一关键现实因素,比忽略此因素的 TBM、GBO 更贴合攻击者行为逻辑。
4.1.2 蜜罐多样化:降低 “单一类型被识别” 风险
若蜜网中蜜罐类型统一(如同为低交互蜜罐),攻击者识破一个后会批量识别所有,降低欺骗效果。论文通过 4 类模型实现蜜罐多样化优化:
HSG/HSGp 模型:Píbil 等人(2012)提出,HSG 模型为每个主机(真实 / 蜜罐)分配 “重要性数值”(如数据库服务器重要性高于普通终端),通过零和博弈(Zero-Sum Game)让防御者部署不同类型蜜罐(匹配不同重要性),提升攻击者误判概率;HSGp 模型进一步支持 “攻击者探测流程”,假设攻击者仅能探测有限主机,通过纳什均衡(Nash Equilibrium)找到防御者的最优部署策略。
DHG/DHGu 模型:Durkota 等人(2015a)的 DHG 模型限制蜜罐类型为 “有限集合”(如仅高 / 中交互),通过攻击图分析攻击者的最优路径,结合斯塔克尔伯格均衡(Stackelberg Equilibrium)部署多样化蜜罐;DHGu 模型(2015b)假设 “攻击者未知蜜罐类型”,更贴近真实场景,通过通用和博弈(General-Sum Game)计算防御者的最优类型组合,并给出效用函数的上界公式。
DHD 模型:Sarr 等人(2020)针对 “蜜罐检测攻击” 设计,通过零和博弈让防御者部署多样化蜜罐(如低交互 + 高交互),攻击者需支付对应类型的检测成本(如检测高交互蜜罐成本更高)。模型建议 “随机分布不同类型蜜罐”,使攻击者即使识破一种,也无法批量识别其他,实验显示该策略可降低蜜罐整体检测率 30% 以上。
4.1.3 蜜罐定位:覆盖攻击路径关键节点
蜜罐位置直接影响 “能否拦截攻击链”,论文通过 2 类模型优化定位策略,核心是 “将蜜罐部署在攻击者必经的攻击路径上”:
POSG 模型:Anwar 等人(2019)将蜜罐定位建模为 “零和随机博弈”,防御者与攻击者均知晓攻击图(Attack Graph),但攻击者未知蜜罐位置、防御者未知攻击者已利用的漏洞。防御者每步可在攻击图边缘部署 1 个蜜罐或不部署,攻击者选择主机攻击;模型通过部分可观测马尔可夫决策过程(POMDP)算法找到最优定位,确保蜜罐能拦截攻击者的关键推进步骤。
POSGm 模型:Anwar 等人(2020)对 POSG 的扩展,支持 “多蜜罐同时部署”。模型先通过线性方程计算 “部署 1 个蜜罐的收益”(如拦截攻击的概率 × 防御收益),再通过 “渐进算法” 遍历所有可能的定位组合,选择收益最高的组合(如在攻击图的 3 个关键分支各部署 1 个高交互蜜罐)。实验显示,POSGm 比 POSG 的攻击拦截率提升 20%-25%,因多蜜罐能覆盖更多攻击路径。
4.1.4 蜜罐动态化:避免静态特征被识别
静态蜜罐的固定配置(如端口响应、服务版本)易被攻击者指纹识别,论文通过 6 类模型实现蜜罐行为动态调整:
DD 模型(Delay-Delay):Cai 等人(2009)针对 “蜜罐地址连续分布” 场景设计,防御者对攻击者的探测 “持续说谎”(如蜜罐伪装成真实主机),直至说谎次数达阈值。模型建议 “优先对高频探测的 IP 说谎”,延长攻击者识别时间,实验显示该策略可使攻击者的蜜罐识别时间从 10 分钟延长至 45 分钟。
SGM/SGMd 模型:Carroll 和 Grosu(2011)的 SGM 模型(Signaling Game Model)假设蜜罐地址随机分布,防御者对探测的响应为 “h(蜜罐)” 或 “r(真实主机)”,通过判断最优响应(如当 h/(h+r+z)≤pcₕ/(acᵣ+cc) 时,始终响应 “r”);Çeker 等人(2016)的 SGMd 模型聚焦 DDoS 攻击,通过区分 “真实主机” 与 “蜜罐” 的响应策略(如真实主机在 srᵣ≥(acᵣ"-rc)/srᵣ" 时说真话),确保 DDoS 流量被引导至蜜罐。
SGE 模型(Signaling Game with Evidence):Pawlick 等人(2018)考虑 “攻击者会收集证据验证响应真实性”(如通过异常系统调用判断蜜罐),将蜜网分为 “主导态(h 或 r 接近 0)”“密集态(h<r 或 r
强化学习模型:Limouchi 和 Mahgoub(2021)的 BRL 模型(Bayesian Reinforcement Learning)通过 “恶意邻居数量” 动态切换蜜罐行为 —— 当恶意邻居 > 2 时,蜜罐保持高交互;否则伪装成真实主机,实验显示该策略的欺骗成功率达 82%;Huang 和 Zhu(2019)的 MDRL 模型(Markov Decision-based Reinforcement Learning)通过半马尔可夫决策过程,让蜜罐自主选择 “ eject 连接、记录信息、低交互、高交互”4 种行为,适配不同攻击强度。
4.2 蜜网通用数学模型
现有蜜网研究多采用独立模型,难以横向对比。论文创新性提出蜜网通用模型 (H={N,S,C,B}),将不同蜜网技术的核心参数统一,实现 “模型可对比、效果可量化”。
4.2.1 模型参数拆解
模型通过 4 个集合覆盖蜜网的 “网络特征、策略细节、成本、收益”,所有参数定义汇总于表 4:
网络特征集合 (N={h,r,z,D})::
h:蜜罐数量;r:脆弱真实主机数量;z:安全真实主机数量;
D:主机度数列表((d_i)为第i台主机的连接数,(d_{max})为最大度数),用于描述拓扑结构。
**策略细节集合 (S={ma,ah,sr_h,sr_r,ar_a,sr_h",sr_r",ar_a",oh})**:
ma:攻击者最大攻击次数;ah:攻击者可接受的蜜罐连接数;
(sr_h/sr_r):蜜罐 / 真实主机的服务率;(ar_a):攻击者攻击率;
(sr_h"/sr_r"/ar_a"):优化后的服务率 / 攻击率衰减系数(如策略调整后,sr_h 从 100% 降至 50%,则 sr_h"=0.5);
oh:防御者的最优蜜罐数量。
**成本集合 (C={pc_h,pc_r,ac_h,ac_r,pc_h",pc_r",ac_h",ac_r",cc,dc,rc,mc})**:
(pc_h/pc_r):攻击者探测蜜罐 / 真实主机的成本;(ac_h/ac_r):攻击者攻击蜜罐 / 真实主机的成本;
(pc_h"/pc_r"/ac_h"/ac_r"):防御者对应探测 / 攻击的成本(如蜜罐被攻击后,防御者的响应成本);
cc:攻击者被蜜罐捕获的成本;dc:防御者部署 1 个蜜罐的成本;rc:防御者响应攻击的成本;mc:攻击者最大可接受成本。
收益集合 (B={ab_h,ab_r})。
4.2.2 模型核心作用
统一评估标准:不同蜜网技术可转化为模型参数的调整,如 “蜜罐多样化” 对应 “增加 h 的类型维度,调整 ac_h(不同类型蜜罐的攻击成本不同)”,“拓扑塑造” 对应 “修改 D(主机度数列表)”,通过对比 “攻击者成功概率”“防御成本收益比” 等指标,可量化不同技术的效果。
指导部署决策:例如,通过模型计算 “当 h=20、r=50、z=30 时,oh=18,mc=150”,防御者可根据此结果部署 18 个蜜罐,确保攻击成本超过攻击者的 mc,迫使其放弃攻击。
5、总结
本文针对网络威胁(如 Mirai 僵尸网络变种)持续升级、传统安全工具难以检测零日攻击与深度分析攻击者行为,且现有蜜罐研究存在 “单蜜罐技术零散、蜜网缺乏系统分类与统一评估模型” 的核心问题,围绕 “通过网络欺骗技术提升蜜罐性能” 展开综述,填补了相关领域空白。
论文核心结论如下:其一,构建了蜜罐 7 维度分类体系(从目的、交互程度等维度划分,如研究型 ReH、高交互 HiH)与 6 大功能指标(如实现成本 ImCo、欺骗能力 DePo),清晰界定不同蜜罐的适用场景,解决了 “蜜罐如何选型” 的问题;其二,梳理出单蜜罐 6 类欺骗技术(高级模拟、虚假协作、欺骗性数据库等),明确每类技术的实现逻辑与评估标准(如用 DA 衡量真实感、WT 衡量攻击者耗时),有效提升单蜜罐的隐蔽性与数据收集能力;其三,将蜜网欺骗技术归为 5 类优化方向(数量优化、多样化、定位、动态化、拓扑塑造),并提出通用数学模型统一评估不同方案,验证出 URNt 模型(蜜罐数量优化)、高指数无标度拓扑(抑制恶意软件传播)为最优策略;其四,通过多场景模拟与红队实验,证实相关技术可延缓攻击者进度 30% 以上,具备实际应用价值。
从实践来看,研究为开发者提供了 “场景 - 技术” 适配指南(如资源有限场景优先选择低交互蜜罐),为网络安全防护提供了可落地的方案;未来可进一步探索 SDN/5G 环境专用蜜罐、机器学习驱动的动态欺骗策略,推动蜜罐技术从 “被动诱饵” 向 “主动防御体系” 升级,强化对 evolving 网络威胁的抵御能力。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
