基本信息
原文标题:MirrorFuzz: Leveraging LLM and Shared Bugs for Deep Learning Framework APIs Fuzzing
原文作者:Shiwen Ou, Yuwei Li, Lu Yu, Chengkun Wei, Tingke Wen, Qiangpu Chen, Yu Chen, Haizhi Tang, Zulie Pan
作者单位:国防科技大学电子工程学院(Hefei, China)、浙江大学计算机科学与技术学院(Hangzhou, China)
关键词:深度学习框架、安全性、共享漏洞、API模糊测试、自动化测试、大语言模型、漏洞检测
原文链接:https://arxiv.org/pdf/2510.15690
开源代码:https://github.com/MirrorFuzz/MirrorFuzz
论文要点
论文简介:MirrorFuzz聚焦于深度学习(DL)框架API层面的安全性自动测试。该工具提出了一种结合利用大语言模型(LLM)和“共享漏洞”现象的新型API模糊测试方法。论文通过实证分析表明,主流深度学习框架(如TensorFlow、PyTorch等)中的大量API存在设计和实现的共性,由此导致同类甚至同源的缺陷可在不同API之间、甚或不同框架间复现和传播。MirrorFuzz设计了全流程自动化的Bug挖掘系统,依赖LLM提取与解析历史漏洞报告、自动匹配相似API、合成可触发类似漏洞的测试用例,并在四大主流框架上取得了显著的漏洞覆盖与发现效果。
实验证实MirrorFuzz能够发现大量之前未知的安全漏洞,极大提升了代码覆盖率和Bug检测能力,多项新发现已获官方确认和修复。MirrorFuzz的提出为深度学习基础设施级安全保障提供了全新的研究视角与强有力的工具支撑。
研究目的:本研究旨在解决深度学习框架在API层面长期存在、高危且易被忽视的安全漏洞自动发现难题。随着DL框架广泛应用于医疗、金融、自动驾驶等关键领域,底层实现的API一旦出现缺陷,将严重危及上层应用的可靠性与安全性。现有模糊测试方法大多关注模型级别或仅面向孤立API进行测试,难以覆盖框架内部及跨框架的“同质化”漏洞传播现象。
MirrorFuzz的出发点在于:主流DL框架API高度同构,相似API间极可能因算法实现、参数设计一致而共享漏洞。如何自动识别历史漏洞涉及API、准确匹配潜在受影响的相似API,并快速生成可迁移的测试用例,进而在多个框架间实现早期高效的共享漏洞发现,成为MirrorFuzz的根本研究目标。此外,该工具还力图充分挖掘LLM在代码语义理解与智能生成方面的优势,降低测试样例迁移与合成难度,推动DL基础设施安全检测的自动化、智能化水平。
研究贡献:
揭示了深度学习主流框架内部及框架之间大量API在功能和参数层面的高度相似性,以及这种相似性导致的“共享漏洞”现象——即一个API的缺陷极有可能同步存在于其他相似API之中。
设计并实现了MirrorFuzz——首个系统性复用LLM与共享漏洞机制的自动化API模糊测试工具。MirrorFuzz能够自动识别并分析历史API漏洞报告、聚合与之相关的相似API、组合Bug数据引导LLM合成高命中率测试用例,极大提升漏洞检测效率。
在TensorFlow、PyTorch、OneFlow、Jittor等四大主流DL框架上系统评测MirrorFuzz,累计发现315个漏洞,其中262个为新发现,同时有80个漏洞被官方修复,52个获取了权威CVE/CNVD编号,突显了工具的实际价值与影响力。
MirrorFuzz在API覆盖率和代码覆盖率上实现了较现有SOTA测试工具如TENSORSCOPE、TitanFuzz、Orion等的显著提升,例如在TensorFlow和PyTorch平台分别提升39.92%和98.20%,同时展示了跨框架“Bug扩散”现象与防御新视角。
引言
深度学习(Deep Learning, DL)技术近年来被广泛应用于医疗、教育、金融、自动驾驶等关键行业,支撑了智能感知与决策的许多核心场景。其底层基础——深度学习框架(如TensorFlow、PyTorch等)作为AI生态的基础设施,被曝存在多种安全隐患。近期大量研究指出,DL框架中的漏洞可以“反向感染”其上层应用,导致性能劣化、结果错误乃至内存损坏等严重问题。这类风险正随着DL落地场景的复杂化与框架生态的日益庞大而加速扩散,凸显出基础层安全保障的必要性与紧迫性。
当前行业对于DL框架Bug检测主要集中于两类技术路线:一是“模型级Fuzzing”,通过构造完整的DL模型并采用差分测试揭示底层Bug,但受限于模型结构本身,仅能覆盖少数API;二是“API级Fuzzing”,则直接生成不同API的调用序列,既拓宽了API覆盖面,又提升了测试效率,因而成为主流研究方向。近年来,大语言模型(LLM)的快速发展也被引入到这一领域,如自动合成API调用、语义理解Bug报告等,进一步推动了测试自动化进程。
然而,现有多数技术方案普遍忽略了DL框架内部及之间大量API设计上的共性。实际上,这些框架在架构、操作、参数与命名等层面高度雷同,导致同类Bug极易发生在多个API(甚至多框架)之间。这一“共享漏洞”现象,不仅关系到单个框架的安全,还可能造成跨生态的脆弱性扩散,但却长期缺乏系统研究与有效应对机制。如何自动挖掘历史Bug报告中“高风险API”,高效匹配与之同质的潜在受害API,并合成针对性的测试用例,实现跨框架层面的预警和早发现,成为DL安全保障的技术突破口。
在此背景下,本文提出MirrorFuzz,一个自动化、智能化的DL框架API模糊测试工具,首创性地将LLM与“共享漏洞”理论深度融合,实现Bug报告自动理解、相似API高效匹配与测试用例智能迁移等关键功能。MirrorFuzz不仅显著提升了检测能力,更为后续框架开发与维护提供了可复用的安全保障思路与工具基础。
研究背景与问题阐述
深度学习框架为构建各类DL模型与应用提供了核心基础,拥有丰富的API集合以支持张量计算、自动微分、高效的数据处理及训练流程等功能。开发者通过调用这些API,完成模型设计、训练与推理。然而,随着API数量与复杂性的指数增长,各类安全漏洞和实现缺陷层出不穷,严重影响了DL框架及其承载应用的整体可靠性。
以往Bug检测方法主要包括模型级Fuzzing和API级Fuzzing。模型级方法通过构造完整DL模型对比不同后端(如不同框架或计算设备)在执行同一模型时的行为差异,用于发现异常。然而,该方法难以涵盖框架内的大量API,且常因数值精度损失等误差而漏检。API级Fuzzing则聚焦于API层面的调用序列,能够无需构建复杂模型,直接检测更广泛的API集合,因而更适用于实际框架的高效测试。与此同时,大语言模型(如CodeLlama、Qwen2.5-Coder等)以其强大的代码理解与生成能力,迅速成为自动化测试领域的重要支撑,支持高质量语义解析与用例生成。
论文通过大量案例剖析发现:主流DL框架诸如TensorFlow、PyTorch、OneFlow、Jittor等在API设计、参数命名、功能实现上存在高度相似性,这不仅体现在与ONNX等标准兼容的趋势上,更源于通用算法原理与代码复用。这种相似性导致API间可能共享逻辑漏洞,即当某一API在某一参数配置下(如stride=0或padding非法)触发崩溃,该缺陷极易“镜像”到同类API,甚至跨框架同步存在。实际实验中,无论是算子功能相似(如不同的池化API),还是参数设计一致(如不同API都包含stride参数),都可出现Bug的广泛传播。而修复单一API的问题并不能保证同类API无恙,反映出目前Bug修复的被动性与局限性。
在此现状下,如何解决以下核心难题成为推进领域进步的关键:(1)如何高效、自动化地抽取历史Bug报告中涉及的真实高风险API及其触发条件?(2)如何准确匹配和识别框架内外具有功能或参数同质性的潜在受威胁API?(3)如何合成高质量、能最大程度迁移Bug语义的测试用例,从而在更广范围内实现早期Bug发现与防御?这些问题构成了MirrorFuzz设计的根本驱动与创新点所在。
MirrorFuzz方法框架
MirrorFuzz围绕“共享漏洞”的自动化利用和挖掘,设计了包含Buggy API识别、相似API匹配、测试用例智能合成三个主要流程模块的完整测试框架。该系统的核心逻辑在于通过对历史Bug报告的深入语义分析,识别出高风险API与其易触发参数组合;随后,自动化地挖掘和聚合功能或参数同质的API群体,为潜在共享漏洞的传播链建立数据基础;最后,借助LLM强大的代码理解与生成能力,将历史Bug触发条件迁移、变换至目标API,生成覆盖率高、迁移性强、语法与语义合理的测试用例,实现对共享漏洞的早发现和快速定位。具体流程与技术如下:
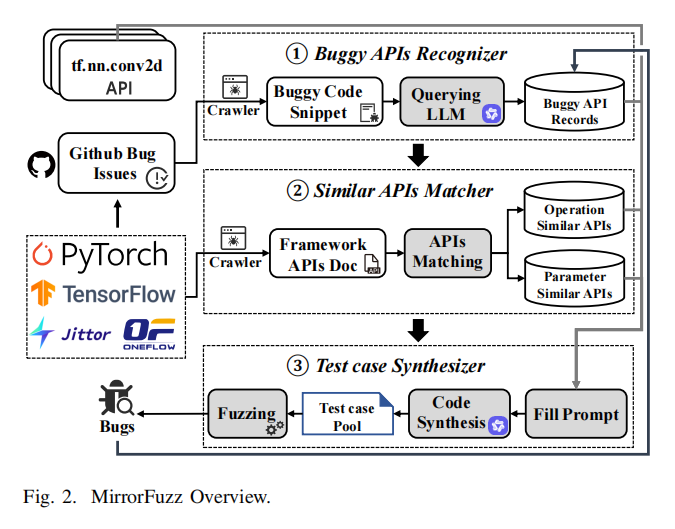
首先,MirrorFuzz借助定制化的网络爬虫与关键字过滤策略,自动从Github等托管平台采集API Bug报告。系统采用精准的正则表达式与多语言关键字表,充分过滤非Bug类issue,并通过解析Markdown代码块、云开发平台脚本等多源信息,抽取得到与Bug强相关的代码片段、标题、内容等结构化数据。
在Buggy API识别阶段,MirrorFuzz创新性地采用LLM以Chain-of-Thought few-shot prompt优化,指导大模型在多轮推理中识别最核心的致Bug API及触发参数。针对API命名不规范、描述歧义或格式不一的难题,系统结合Levenshtein距离等算法将LLM输出标准化为完整API签名,并回填原文信息进一步验证,提高准确率。
进入相似API匹配阶段,MirrorFuzz利用API元数据(包括名称、参数列表、文档注释等),分别对“功能相似API”与“参数相似API”两大类进行匹配。功能相似API指在不同(或同一)框架中实现类似操作、预期输出相近的API,如卷积、池化等操作;参数相似API则为参数结构高度一致但功能不完全相同的API(如不同类型的输入数据处理API,但都包含stride参数)。系统融合TF-IDF文本相似度与M3-embedding语义嵌入双重机制,采用Top-K+自适应阈值联合优化,缓解不同框架文档风格、命名约定不一带来的匹配误差,有效提升跨框架相似API检测效果。
在测试用例生成与迁移阶段,MirrorFuzz高效调用本地化部署的大语言模型(如Qwen2.5-Coder),将历史Bug数据、相似API元信息及特定生成提示(Prompt)一并输入,自动合成可用于新API的测试样例。该过程不仅要求生成的用例符合新API的参数、类型、逻辑等约束,还要可以最大概率复现乃至扩展源Bug的触发机制。对于生成用例执行失败或异常的情况,系统自动触发错误修复机制,持续请求LLM根据异常信息自适应修正,大幅度提升用例整体有效率。最终,多轮优先级排序与参数变异操作,确保测试样例在形式多样性与漏洞触发率之间高效均衡。
MirrorFuzz还内置了完善的Fuzzing执行与回溯模块,能够动态监控崩溃、异常终止、内存越界等事件,并及时将新发现的Bug自动纳入历史Bug数据库,形成持续自增强的“Bug知识循环”,从而不断扩大可复用于未来测试的攻击面和样本库。
效果评估
MirrorFuzz的实验评估旨在全面验证其Bug识别的准确性、相似API匹配的有效性、测试用例合成能力与最终Bug发现效率。在实验设置上,论文选取了TensorFlow(2.16、2.17、nightly)、PyTorch(2.3.0、nightly)、OneFlow(0.9、1.0)、Jittor(1.3.9.5、1.3.9.10)等行业主流深度学习框架作为测试对象。系统依赖Qwen2.5-Coder、CodeGemma、CodeLlama等多种主流大语言模型本地部署,以评估不同模型在多任务上的效果。同时,实验环境选择了高配服务器,保证了Fuzzing大规模高效运行的可行性。
基线对比方案包括TENSORSCOPE、TitanFuzz、Orion、MoCo等当前SOTA的API级及模型级模糊测试工具,涵盖了自动化测试、历史Bug驱动、文档引导、LLM合成等主要代表性技术路线。镜像Fuzz在对比中不仅采用与基线一致或兼容的DL框架版本,还在控制所有测试时间、用例数等变量的基础上,深入比较API覆盖率、代码行覆盖率、单位测试时间内发现唯一漏洞数量、用例有效率、已知/未知漏洞命中率等多维指标,确保评估的科学性与可比性。
具体而言,API场景覆盖率通过framework内部API总数/已测试API数量进行统计,代码行覆盖率由coverage.py工具自动分析每次测试所触达的实际代码行数,直接反映检测广度。漏洞发现能力则采用三重标准:检测到的Bug总数、开发者官方确认数、已修复数,进一步细分为越界、崩溃、断言失败、框架内部异常等类型。新增地,MirrorFuzz还统计了通过“共享漏洞”机制实现跨框架漏洞传播检测的成功案例,并跟踪各主流框架新旧版本间Bug扩散路径。此外,系统对Buggy API识别与相似API匹配开展了人工标准集交叉检验与消融实验,严格验证了创新模块的实际场景表现。
最后,为考察真实工程影响与行业认可度,所有新发现高危漏洞均通过官方通道报告反馈对应框架团队,跟踪调试、修复进度与CVE/CNVD编号申请结果,进一步佐证创新工具的可推广价值。
结果分析
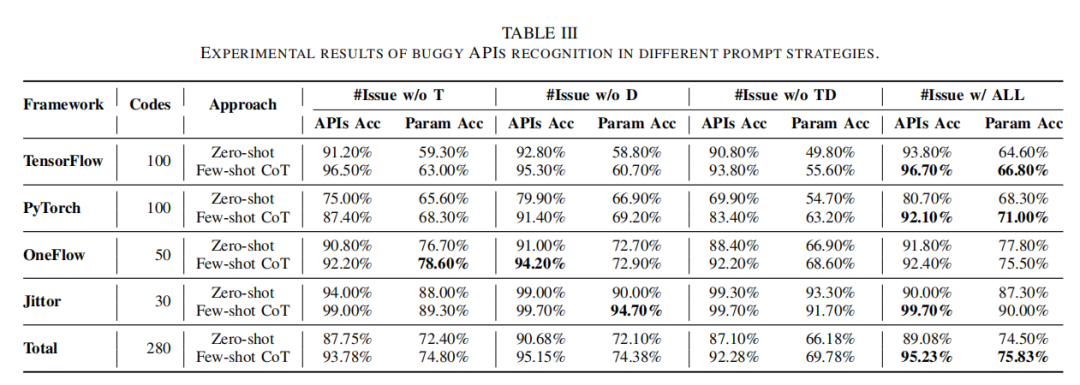
MirrorFuzz在大规模复杂实验中展现了远超以往工作的洞察能力与实用效果。首先,在API Buggy识别任务上,借助few-shot CoT引导的LLM,MirrorFuzz在人工标注的280条多框架历史Bug报告上API识别准确率高达95.23%,关键参数识别准确率达75.83%,明显优于传统静态、基于正则匹配等方法。
在相似API识别与匹配方面,通过多维度语义建模与Top-K+阈值双重筛选,MirrorFuzz在四大框架共人工标注的596对API样本上,跨框架和框架内相似API覆盖率均超86%。分析框架文档与函数实现可见,TensorFlow与PyTorch、OneFlow/Jittor间存在大量功能与参数“重叠区域”,为共享漏洞传播提供了现实温床。
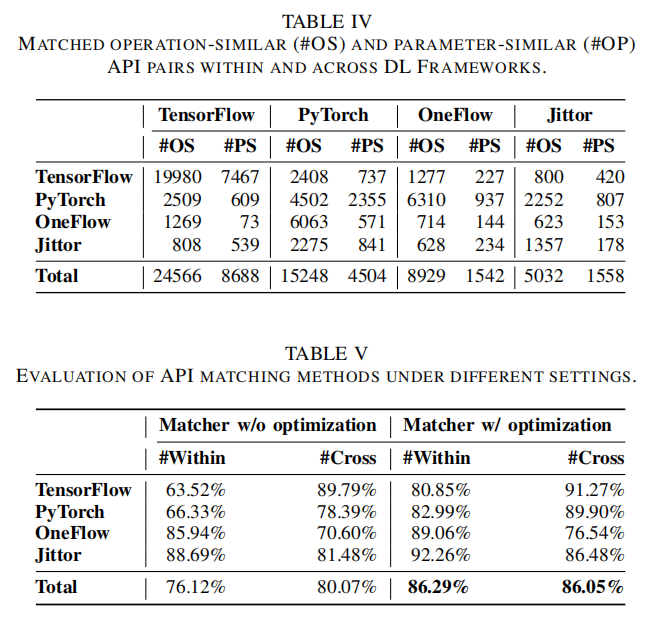
在Bug发现实效上,MirrorFuzz合计检测出315个真实漏洞,其中262个为新发现,经开发者反馈确认180个,80个已修复,52个获得CNVD官方编号。漏洞类型涵盖内存越界、空指针解引用、堆/栈溢出等安全高危,以及框架内部断言、编译失败等特殊机制。具体案例中,包括PyTorch已有API Conv2d的0-stride崩溃Bug,MirrorFuzz能基于功能相似性快速推断出量化版(如Quantized.ConvReLU、Conv)存在完全同质漏洞,填补了长期以来“一处修复,处处受益”假设的漏洞。
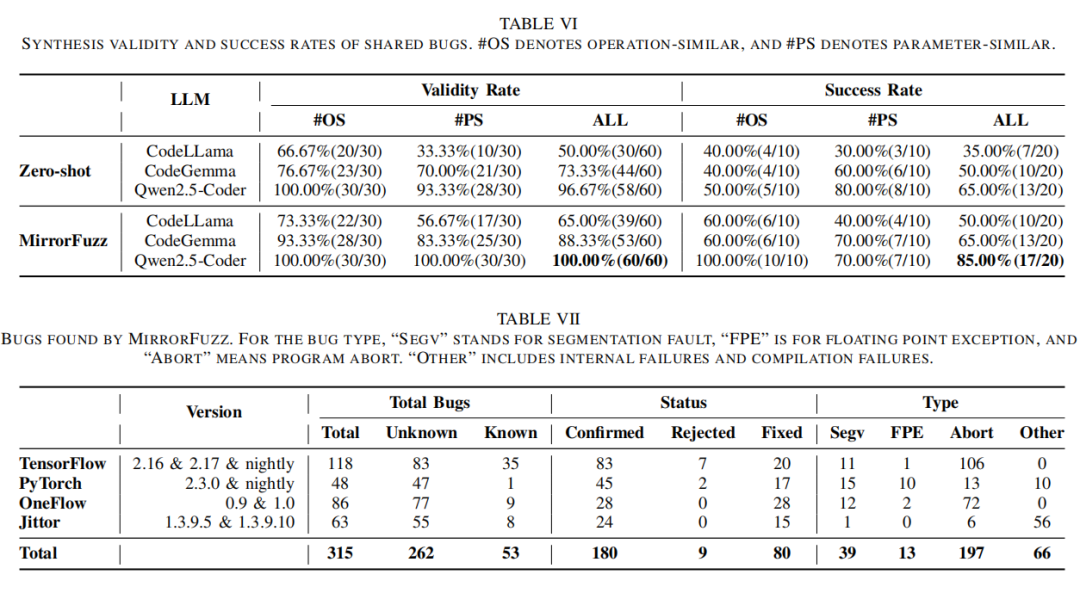
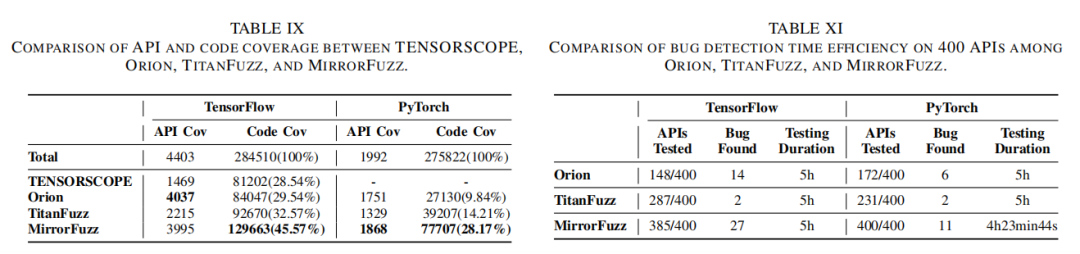
进一步,MirrorFuzz在API与代码覆盖率上分别以45.57%和28.17%(TensorFlow)高于所有对照方法,在PyTorch上也获得最大增幅(98.20%提升)。Bug检测时效性方面,镜像Fuzz在等时段内可对全部API测试并实现最多新漏洞发现,表现出共享漏洞机制和测试用例迁移的独特增益。
Bug传播路径溯源分析中,绝大多数新Bug的写法与触发参数与源API极其相似,部分Bug甚至在逻辑实现上一模一样,但长期因代码分支、文档疏忽未被发现。更为重要的是,OneFlow、Jittor等次主流框架的Bug同样能够“反向”影响主流框架,展现出跨生态共同防御的必要性。此外,大量功能相似API(如不同子模块池化、卷积、padding等)与参数相似API(如多个API共同包含stride、padding、kernel_size等),都成为MirrorFuzz高命中新Bug的主要突破口,显示系统性、可复制拓展的行业价值。
论文结论
本文针对深度学习框架API层面长期普遍存在、危害巨大的“共享漏洞”现象,提出了MirrorFuzz——基于大模型推理、历史Bug知识复用与相似API自动聚类的全流程API模糊测试工具。MirrorFuzz首次实现了基于Bug报告的自动化高风险API识别、功能与参数同质API群体高效聚合与用例合成迁移,有效补齐了现有Fuzzer在跨API、跨框架漏洞覆盖上的诸多不足。实验证明,MirrorFuzz能够在主流DL框架中发现大规模新增高危Bug,代码与API覆盖率远超现有方法,推动了行业安全防御理念从“单点孤立”向“体系化共享”跃迁。
当前,MirrorFuzz虽已实现初步自动化,但在API匹配参数阈值自适应、用例覆盖范围及新型未知Bug挖掘等方面仍有提升空间。未来,研究团队计划深化LLM智能辅助能力,引入更加鲁棒的多Agent机制,并系统探索Bug类型拓展与隐式安全属性建模,持续驱动深度学习基础设施的安全升级。MirrorFuzz的发布,不仅补强了深度学习底层安全短板,更为全行业提供了可复用的安全保障范式和技术支撑。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
