
原文标题:Towards Fine-Grained Webpage Fingerprinting at Scale
原文作者:Xiyuan Zhao, Xinhao Deng, Qi Li, Yunpeng Liu, Zhuotao Liu, Kun Sun, Ke Xu原文链接:https://doi.org/10.1145/3658644.3690211发表会议:CCS笔记作者:宋坤书@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、研究背景
洋葱路由(Tor)通过随机选择的多个中继进行多层加密为用户提供在线隐私保护,但仍易受到网站指纹识别(Website Fingerprinting, WF)攻击。WF攻击通过分析网站独特的流量模式(如数据包大小、时间戳和方向)来识别用户访问的网站。尽管已有大量研究提出复杂模型来提取网站流量特征,但它们主要聚焦于识别网站本身,对更精细的网页指纹识别(WebPage Fingerprinting, WPF)支持较弱。在多标签网页浏览场景下,网页间细微差异难以捕捉,会导致这些模型的分类性能的显著下降。
为解决上述问题,本文提出了Oscar框架,一种面向多标签网页浏览场景的精细化网页指纹识别方法。Oscar的核心思想在于利用度量学习重构特征空间,使相同网页的流量聚类、不同网页的流量分离,从而捕捉网页间的微小差异。该方法通过双重数据增强机制提升样本多样性,并采用代理与样本联合的多标签度量学习损失来缓解类别崩溃问题。最终,Oscar借助k-NN分类器在大规模网页集合下实现了高效、准确的网页识别。
2、Oscar框架设计
Oscar是一个基于度量学习的网页指纹识别系统,它通过数据增强、特征转换和网页识别这三个模块,有效地识别出Tor用户访问的具体网页,实现对匿名通信的攻击。Oscar的设计结构图如下:
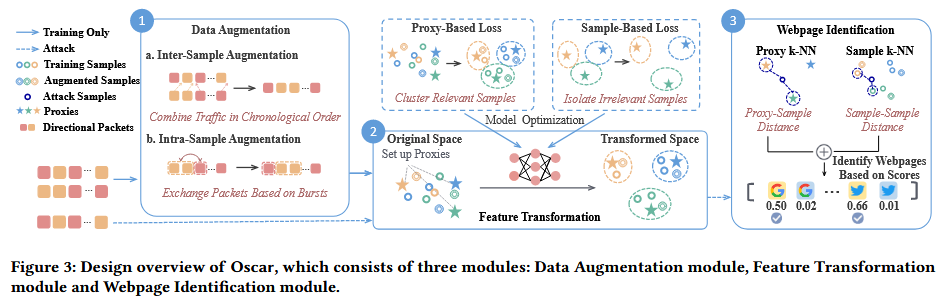
2.1 数据增强模块
数据增强模块旨在提升系统在多标签网页访问下的泛化能力,主要通过样本间增强(Inter-Sample Augmentation)和样本内增强(Intra-Sample Augmentation)两种方式来模拟更复杂的网页混合流量,以模拟真实世界中用户同时访问多个网页的情况。数据增强模块中的两个操作如下图:
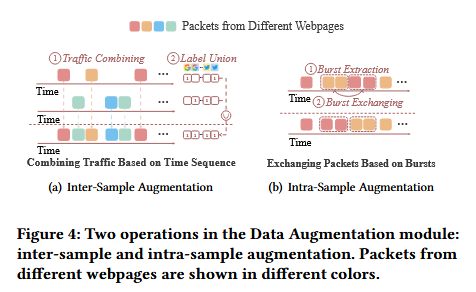
样本间增强:随着并行访问网页数量的增加,不同组合带来的流量模式差异也显著加大。样本间增强方法通过将两个不同样本的流量按时间顺序融合,构造新的流量序列及其联合标签。这种操作模拟了用户在多个标签页中并行访问多个网页时,不同网页流量混合在一起的现象。
样本内增强:在单个样本内部打乱其部分流量顺序,以应对相同网页组合下,由于Tor多路复用机制而产生的动态包排序问题。样本内增强方法以突发(burst)为单位进行交换操作,设置合理的交换比例,在维持原始语义不变的同时引入适度扰动,从而增强模型对数据包排序变动的鲁棒性。
这两种增强方法基于多标签网页访问场景的特点,从“网页组合多样性”和“数据包顺序随机性”两个维度增加了样本多样性,使Oscar具备了更强的泛化能力。
2.2 特征转换模块
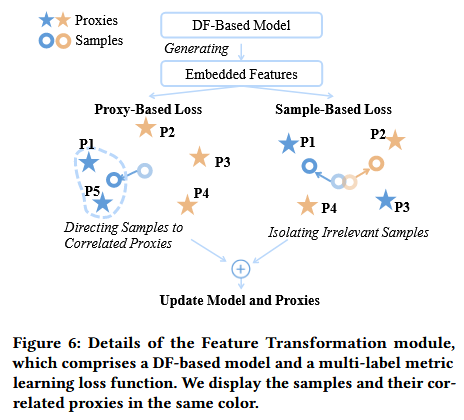
为了解决在多标签网页访问下网页流量混淆的问题,Oscar设计了特征转换模块,通过多标签度量学习对流量特征进行变换,使同一网页的流量在嵌入空间中聚集,不同网页的流量彼此分离。由于解决传统的度量学习方法无法适应多标签场景,Oscar引入了多标签度量学习方法来更有效地区分混合网页流量。特征转换模块由特征转换模型和多标签度量学习损失函数两部分组成,其结构如下图:
2.2.1 特征转换模型
特征转换模型选用基于CNN的DF(Deep fingerprinting)模型[1]作为特征转换模型,利用其平移不变性强、特征提取能力强的优势来适应标签混合的流量结构。本文使用的DF模型包括四个卷积块和一个线性嵌入层,用于将原始流量序列映射到低维嵌入空间。
2.2.2 多标签度量学习损失函数
损失函数采用代理损失(proxy-based loss)与样本损失(sample-based loss)结合的方法,同时实现对同类网页流量的聚类和对不同网页流量的分离。
代理损失:通过为每个网页设定一个可学习的代理向量(proxy),并动态调整其在特征空间中的位置。训练过程中,若某个样本包含某网页的标签,则该样本与该网页的代理构成正向对,模型会拉近它们之间的距离;反之,则构成负向对。对于负向对,只有其相似度低于设定的边界值(margin)时才会计算其损失值,相似度高于margin的损失值设置为0。通过计算代理损失可以确保样本围绕其代理收敛,从而提取出更清晰、分离性更强的网页访问模式。
样本损失:由于代理损失可能会无意中将不相关网页的流量拉近,导致发生“位置重叠”,Oscar引入了样本损失作为补充,以进一步区分无标签重叠的样本对。首先要筛选出不共享任何标签的样本对(即互为“无关网页”),然后计算它们的余弦相似度,若相似度高于设定的margin,才会计算其损失,否则损失值为0。通过计算样本损失有效强化了网页间的判别边界,从而进一步提升网页分类的准确性。
总体而言,代理损失确保了标签相同类型样本的聚类,而样本损失强化了标签的界限。特征转换模块将流量嵌入到新的特征空间,并利用多标签度量学习损失函数聚类和分离流量样本,为后续分类任务提供了清晰可分的特征表示。
2.3 网页识别模块
为解决多标签网页流量中的样本漂移和特征混杂问题,Oscar系统引入了双k-NN分类器架构,构建了一个基于代理的k-NN和一个基于样本的k-NN,以增强其多标签网页识别的性能。网页识别模块结构如下图:
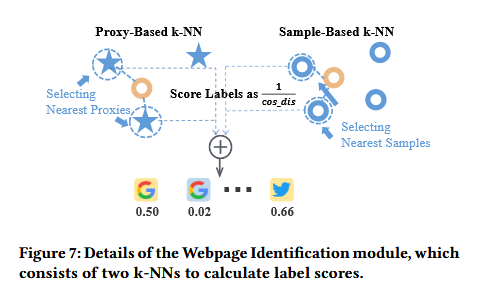
其中,代理k-NN基于目标样本与代理样本间的距离实现分类,它会检索最近的b个代理样本,并根据检索到的代理样本与目标样本的余弦距离计算网页标签得分;而样本k-NN则检索最近的b个样本,也是根据检索到的样本与目标样本的余弦距离计算网页标签得分。两者的得分最终按比例加权融合,得到各个网页标签的最终得分。系统根据设定好的阈值 τ 判断目标样本对应的网页标签,输出识别结果。
3、实验设置
在实现方面,Oscar原型使用Torch 1.9.0和Python 3.8实现,并通过随机搜索确定最优超参数。为了增强模型对网页特征的学习能力,在数据增强模块中设定5%的交换比例以维持流量模式不被破坏;特征变换模块中,将样本损失权重设置为较高值(例如β=4.5),以适应多标签网页的场景;网页识别模块则通过调整阈值 τ 以优化F1分数。
在数据集方面,本文自建了两个真实世界的多标签网页指纹数据集:封闭世界数据集CW和开放世界数据集OW。CW数据集包含从Alexa Top 20000中选取的1000个有效网页,每种网页访问组合采集10个样本;OW数据集则包含来自9236个不同网站的非监控网页,混合了监控和非监控网页浏览行为,每个访问包含2–5个网页访问场景,训练集、验证集和测试集采用来自不同非监控网页的流量。
此外,实验对比了Oscar与DF、k-FP、Tik-Tok、NetCLR、BAPM和TMWF这六种主流网站指纹攻击方法,充分验证了其在多标签网页访问场景下的有效性。
4、实验结果评估
本文采用Recall@k和AP@k这两个多标签分类指标对模型性能进行评估。Recall@k是指模型预测的前k个网页中,实际访问网页被正确预测出来的比例;而AP@k是Precision@k的平均值,它用于衡量预测正确的网页在前k个结果中所占的比例。本文对每个样本单独计算Recall@k和AP@k,取其平均作为整体评估结果。
4.1 封闭世界中的WPF攻击
本文评估了封闭世界环境下Oscar在识别已知网页方面的性能,使用自建的CW数据集,按8:1:1比例划分为训练集、验证集和测试集,利用增强的训练集训练特征转换模型,并在验证集上微调参数,最终使用训练好的模型对测试集中的样本进行转换,并基于更新后的代理和转换后的训练样本实现网页识别。与现有方法相比,Oscar在多标签分类指标Recall@k与AP@k上均取得最优结果,特别是在 Recall@30和AP@5上均超过0.73,显著优于其他方法。在Recall@5上,Oscar相比于k-FP、NetCLR、DF、Tik-Tok、BAPM和TMWF分别提高了110.2%、170.8%、46.1%、47.9%、132.6%和24.0%。封闭世界中的实验结果对比如下图:
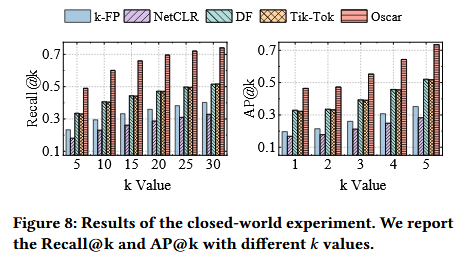
4.2 开放世界中的WPF攻击
在开放世界设定中,攻击者只能获取部分网页的样本,而测试集则包含未知的网页。为模拟现实中仅部分敏感网页被监控的场景,本文将CW和OW数据集混合,保持监控和非监控网页样本数量平衡。监控网页仍按网页区分类别,而所有非监控网页统一视为一类,样本标签仍是多标签的,样本标签的数量也是动态的。实验结果表明,Oscar在Recall@30和AP@5上分别保持在约0.7和0.67,较其他方法平均提升63.5%和72.0%。尽管面临大量未监控网页干扰,Oscar仍展现出强大的识别能力。开放世界中实验结果对比如下图:
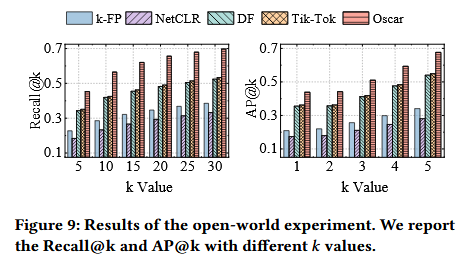
4.3 不同网页规模下的WPF攻击
在不同规模的网页数量下(700至1000个),Oscar始终表现出优越的性能,AP@5均值保持在0.72以上,明显优于现有方法(最高不足0.58);随着网页数量增加,其Recall@5和AP@5分别下降2.76%和4.41%,表现出良好的稳定性和可扩展性。这说明其在原始特征空间难以区分的情况下仍能实现准确识别,具备在大规模实际攻击场景中应用的潜力。不同网页规模下的实验结果对比如下图:
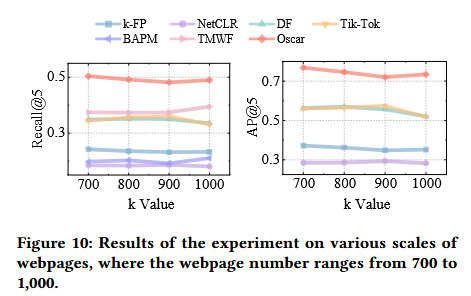
5、本文贡献
提出了一种细粒度多标签网页指纹识别攻击方法Oscar,首次实现了在多标签环境下对混淆流量中网页的准确识别;
设计了适用于多标签流量的数据增强策略,提升了模型在真实环境中的泛化能力;
构建了融合代理损失和样本损失的多标签度量学习方法,有效分离不同网页的混淆流量特征;
构建了首个包含1000个监控网页和9000多个非监控网页的多标签网页流量数据集,并在封闭世界和开放世界下验证了Oscar的性能。
参考文献:
[1] Payap Sirinam, Mohsen Imani, Marc Juarez, and Matthew Wright. 2018. Deep fingerprinting: Undermining website fingerprinting defenses with deep learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. 1928–1943.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
