
原文标题:Set-level Guidance Attack: Boosting Adversarial Transferability of Vision-Language Pre-training Models
原文作者:Dong Lu , Zhiqiang Wang , Teng Wang , Weili Guan ,Hongchang Gao , Feng Zheng原文链接:https://ieeexplore.ieee.org/document/10376813发表会议:ICCV笔记作者:谢启亮@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、背景介绍
视觉语言预训练(VLP)模型在多模态任务中已显示出对对抗样本的脆弱性。此外,恶意对抗样本可以被刻意迁移以攻击其他黑盒模型。然而,现有的工作主要集中在研究白盒攻击。在实际应用中,关于受害者模型的信息是不可获取的,因此研究对抗样本在不同VLP模型间的迁移性更具实际意义。目前尚不清楚在一个源模型上生成的对抗数据是否能成功攻击另一个模型,这给VLP模型在真实世界应用中的部署带来了严重的安全风险。 本文首次研究了近期VLP模型的对抗迁移性。研究发现,与白盒设置下的强攻击性能相比,现有方法在迁移攻击中表现出低得多的迁移性。这种迁移性下降部分是由于跨模态交互的利用不足。特别地,与单模态学习不同,VLP模型严重依赖跨模态交互,并且多模态对齐是多对多的。 为了解决弱迁移性问题,本文提出了一种高迁移性的集合级指导攻击 (Set-level Guidance Attack, SGA),该方法彻底利用了模态间的交互,并结合了带有跨模态指导的保留对齐的增强方法。
2、相关工作
视觉语言预训练模型 (Vision-Language Pre-training Models, VLP): VLP旨在通过预训练大规模图文对来提升下游多模态任务的性能。大多数工作基于预训练的目标检测器和区域特征来学习视觉语言表示。近期,随着视觉Transformer (ViT) 的流行,一些工作提出使用ViT作为图像编码器,并将输入以端到端的方式转换为图像块。根据VLP架构,VLP模型可分为两类:融合型VLP模型(fused VLP models)和对齐型VLP模型(aligned VLP models)。例如,ALBEF和TCL首先利用独立的单模态编码器处理词元嵌入和视觉特征,然后使用多模态编码器处理图像和文本嵌入以输出融合的多模态嵌入。而CLIP等对齐型VLP模型仅拥有独立的图像和文本模态编码器。本文关注这两种流行的架构。
图文检索任务 (Image-Text Retrieval, ITR): ITR旨在给定一种模态的查询输入时,从图库数据库中检索相关的、排名靠前的另一种模态的实例。该任务可分为两个子任务:图像到文本检索 (TR) 和文本到图像检索 (IR)。对于ALBEF和TCL,会在单模态嵌入空间中计算所有图文对的语义相似度得分以选择top-k候选者,然后多模态编码器接收这些top-k候选者并计算图文匹配得分进行排序。对于CLIP,由于没有多模态编码器,最终的排序列表可以直接基于图像和文本模态嵌入空间中的相似度获得。
对抗迁移性 (Adversarial Transferability): 现有的对抗攻击可分为白盒攻击和黑盒攻击。在白盒设置中,目标模型完全可访问,但在黑盒设置中则不然。计算机视觉领域许多方法利用梯度信息进行白盒对抗攻击,如FGSM, PGD, C&W, MI。而在自然语言处理(NLP)领域,当前的攻击方法主要修改或替换输入文本的一些词元。在多模态视觉语言领域,Zhang等人[1]提出了一种针对下游任务中流行VLP模型的白盒多模态攻击方法。然而,由于实际应用中模型信息的不可获取性,白盒攻击是不现实的。此外,尚无相关工作系统性分析多模态攻击方法在VLP模型上的对抗迁移性。因此,本文主要关注生成能够在不同VLP模型间高度迁移的对抗样本。
3、对抗迁移性分析
本节对VLP模型进行实证研究,以评估现有方法的对抗迁移性。攻击多模态任务的一种常见方法是结合各个模态的单模态对抗攻击,例如,分离的单模态攻击 (Sep-Attack) 包括针对图像模态的PGD和针对文本模态的BERT-Attack。 观察结果 (图1和图2):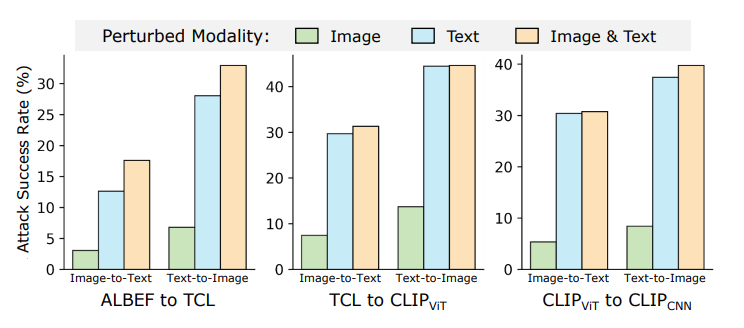
(图1:不同扰动模态在图文检索任务上的攻击成功率。使用Sep-Attack。) (图2:Sep-Attack(左)和Co-Attack(右)在图文检索任务中对白盒和黑盒模型的攻击成功率。)
同时攻击图像和文本模态的对抗迁移性始终优于仅攻击单一模态。 如图1所示,从ALBEF到TCL的对抗图像和文本的迁移攻击成功率远高于仅迁移对抗图像或文本。ALBEF和TCL都是融合型VLP模型。类似的观察也存在于以下情况:
(1) 源模型和目标模型是不同类型的VLP模型但具有相同的基础架构。
(2) 源模型和目标模型是相同类型的VLP模型但具有不同的基础架构。
在源模型上具有强攻击性能的对抗多模态数据(即对抗图像和文本),在迁移到目标模型时几乎无法保持相同的能力。 例如,如图2所示,即使ALBEF和TCL具有相同的模型架构,从ALBEF生成的对抗样本迁移到TCL时,攻击成功率也显著下降。这种现象在Sep-Attack和Co-Attack中都存在。
总而言之,如果所有模态同时受到攻击,攻击方法在黑盒设置中可以具有更强的迁移性。然而,即使允许同时扰动两个模态,现有方法仍然表现出低得多的迁移性。这表明具有更高迁移性的攻击应该被专门设计,而不是直接利用现有的白盒攻击方法。
4、方法论
本节提出了一种可迁移的多模态对抗攻击方法,称为集合级指导攻击 (Set-level Guidance Attack, SGA)。SGA旨在通过利用多模态交互并结合具有精心设计的跨模态指导的多样化保留对齐的模态间信息来增强VLP模型间的对抗迁移性。
为了提高多模态攻击的迁移性,首先对现有方法在黑盒设置中的不足之处进行了调查。通过对失败案例的系统分析(如表1所示),观察到大约一半的失败案例是由于图像存在多个匹配标题造成的。更具体地说,研究结果表明,虽然生成的对抗图像可能与源模型中的单个监督标题显著不同,但它很容易接近目标模型中的其他匹配标题,从而导致对齐可以被建模并最终导致攻击失败。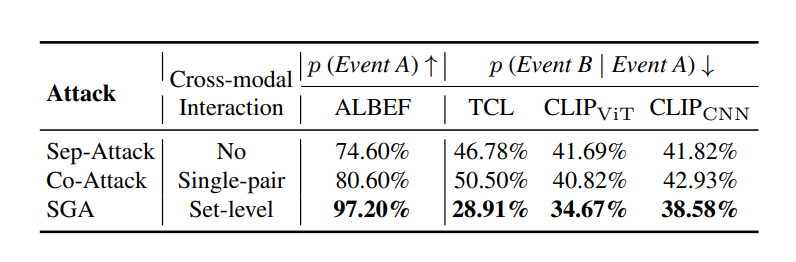 (表1:跨模态交互不足的对抗图像在迁移时可能更接近其他配对标题。)
(表1:跨模态交互不足的对抗图像在迁移时可能更接近其他配对标题。)
因此,为了在迁移到其他模型时保持对抗图像的攻击能力,考虑多个配对标题并将对抗图像推离所有配对标题至关重要,从而在迁移到其他黑盒模型时保留攻击能力。制作具有高迁移性的对抗文本也遵循类似的方法,同样可以从更多的配对图像中受益。集合级指导攻击 (SGA):
4.1 保留对齐的增强:
现有方法在生成对抗样本时,其利用的模态间信息不够多样化,这是一个关键限制。为了在生成可泛化的对抗样本时引入更多样性,SGA 提出了一种“集合级”的“保留对齐增强”策略。这种策略旨在扩展多模态的输入空间,同时确保不同模态间的内在对齐关系不被破坏。具体做法是,不再像以往那样只考虑单个的图像-文本对,而是将输入扩展到图像和标题的“集合”层面。对于每个输入的原始图像,会从数据集中挑选出多个最匹配的文本标题,形成一个增强的标题集合。同时,原始图像会被调整成多种不同的尺寸和尺度,并加入高斯噪声,从而基于尺度不变性的原理,得到一个多尺度的图像集合。最终,这个经过扩充的图像集合和标题集合将被用来生成对抗性的图像和文本数据。
4.2 跨模态指导:
跨模态之间的交互对于多模态任务的成功至关重要。为了更充分地利用前一步中经过增强的、保留了对齐关系的多模态输入集合,并进一步提升所生成对抗数据的迁移能力,SGA 采用了“跨模态指导”的策略。这种策略的核心是利用来自一个模态的配对信息作为监督信号,来指导另一个模态对抗样本的优化方向。通过这种方式,SGA 迭代地将不同模态的信息“推开”,从而扰乱它们之间的和谐交互,以产生更有效的扰动。一个显著的特点是,这样生成的对抗样本能够感知并响应来自多个不同指导源的梯度信息。
其具体流程是:首先,针对增强标题集合中的每一个标题,都生成相应的对抗性标题,构成一个对抗标题集合。在生成这些对抗标题时,会确保它们在嵌入空间中与原始图像不相似。然后,基于这个对抗标题集合,来生成对抗图像。在生成对抗图像的过程中,会鼓励所有由该对抗图像派生出的不同尺度的图像,在嵌入空间中都远离之前生成的那些对抗标题。最后,再根据这个新生成的对抗图像,来生成最终的对抗文本标题,并确保这个对抗文本标题在嵌入空间中也远离该对抗图像。
5、实验
实验设置:
数据集: 使用两个广泛使用的多模态数据集 Flickr30K 和 MSCOCO。Flickr30K 包含31783张图像,每张图像有五个相应的标题。类似地,MSCOCO 包含123287张图像,每张图像注释有大约五个标题。采用Karpathy划分进行实验评估。
VLP模型: 评估两种流行的VLP模型:融合型VLP(ALBEF, TCL)和对齐型VLP(CLIP)。ALBEF包含一个12层的视觉Transformer ViT-B/16和两个6层的Transformer分别用于图像编码器、文本编码器和多模态编码器。TCL使用与ALBEF相同的模型架构但预训练目标不同。对于对齐型VLP模型,选择评估CLIP。
对抗攻击设置: 为制作对抗图像,使用PGD,扰动边界 εv = 2/255,步长 α = 0.5/255,迭代次数 T = 10。为攻击文本模态,采用BERT-Attack,扰动边界 εt = 1,词表长度 W = 10。此外,通过将原始图像调整为五个尺度 {0.50, 0.75, 1.00, 1.25, 1.50}来扩大图像集。类似地,通过为数据集中每个图像增强最匹配的约五个标题对来扩大标题集。
评估指标: 使用攻击成功率(ASR)作为评估白盒和黑盒设置中对抗鲁棒性和迁移性的指标。ASR评估仅产生成功对抗样本的攻击百分比。更高的ASR表示更好的对抗迁移性。
迁移性分析 (表2):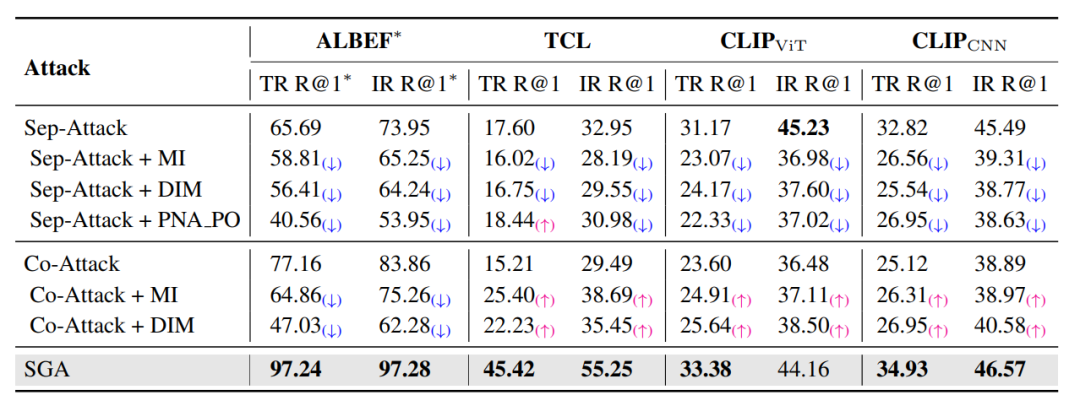 (表2:在图文检索任务中集成基于迁移的图像攻击的攻击成功率(%)。星号表示白盒攻击。)
(表2:在图文检索任务中集成基于迁移的图像攻击的攻击成功率(%)。星号表示白盒攻击。)
直观地研究了从未经模态学习中采用基于迁移的攻击来提高多模态学习中的迁移性。具体考虑了MI, DIM和PNA_PO。然而,如果跨模态交互和多模态学习中独特的多对多对齐没有被考虑,这种方法可能会出现问题。表2说明了结合基于迁移的图像攻击的多模态攻击方法在迁移性方面表现出最小的改进,同时损害了白盒性能。具体来说,当与MI集成时,Co-Attack在白盒设置中显著下降了12.3%,而在迁移性方面仅保持25.40%的ASR。然而,本文的SGA在白盒和黑盒设置中都表现出优越的性能。值得注意的是,Sep-Attack与基于迁移的攻击相结合不仅降低了白盒攻击的有效性,而且在几乎所有黑盒设置中都未能提高对抗迁移性。
实验结果 (表3):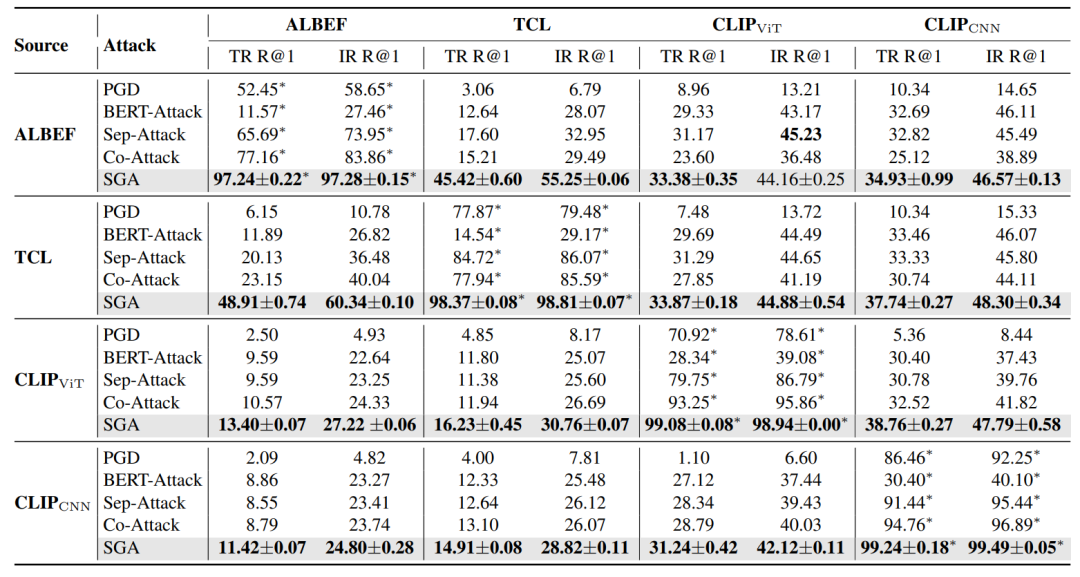 (表3:与最先进方法的图文检索比较。报告了IR和TR的R@1攻击成功率(%)。星号表示白盒攻击。)
(表3:与最先进方法的图文检索比较。报告了IR和TR的R@1攻击成功率(%)。星号表示白盒攻击。)
多模态融合模块: 首先研究具有不同融合模块的VLP模型。在所有黑盒设置中,SGA均优于现有的多模态攻击方法。具体来说,当源模型和目标模型类型相同时,SGA在对抗迁移性方面取得了显著改进。例如,当从ALBEF向TCL迁移对抗数据时,SGA的攻击成功率比Co-Attack高出约30%。此外,在源模型和目标模型类型不同的更具挑战性的场景中,SGA也以更高的攻击成功率超越了Co-Attack。
跨任务迁移性 (表4和表5):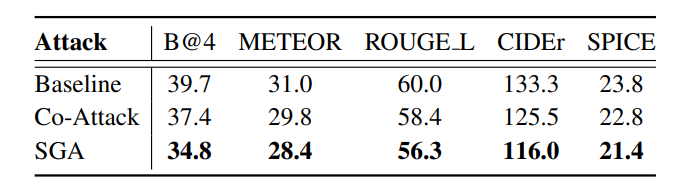 (表4:跨任务迁移性:ITR → IC。在MSCOCO上,从图文检索(ITR)生成的对抗数据攻击图像字幕(IC)。
(表4:跨任务迁移性:ITR → IC。在MSCOCO上,从图文检索(ITR)生成的对抗数据攻击图像字幕(IC)。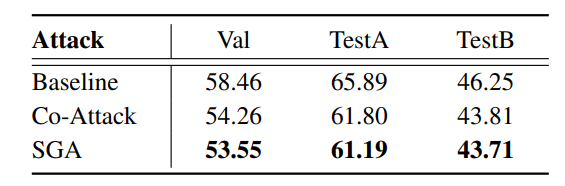 ) (表5:跨任务迁移性:ITR → VG。在RefCOCO+上,从图文检索(ITR)生成的对抗数据攻击视觉定位(VG)。)
) (表5:跨任务迁移性:ITR → VG。在RefCOCO+上,从图文检索(ITR)生成的对抗数据攻击视觉定位(VG)。)
在另外两个V+L任务上进行了广泛的实验:图像字幕(IC)和视觉定位(VG)。图像字幕: 使用源模型(ALBEF)和图文检索目标制作对抗图像,然后直接攻击目标模型(BLIP)的图像字幕任务。实验结果(表4)表明,与Co-Attack相比,所提出的SGA在对抗迁移性方面有明显改进。具体来说,SGA将BLEU得分提高了高达2.6%,将CIDEr得分提高了高达9.5%。
视觉定位: 类似地,使用源模型(ALBEF)从图文检索生成对抗图像,以攻击目标模型(ALBEF)的视觉定位任务。表5显示了在RefCOCO+上的结果,其中SGA仍然优于Co-Attack。 消融研究 (图3):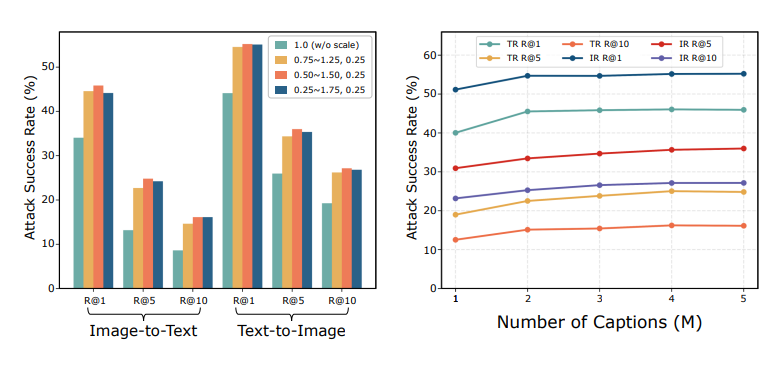 (图3:消融研究:集合级增强的攻击成功率(%)。左图为图像集,右图为标题集。)多尺度图像集: 图3左侧的结果显示,随着引入具有不同尺度的更多样化图像,迁移性显著增加,当尺度范围设置为[0.50, 1.50],步长为0.25时达到峰值。因此,将尺度范围S设置为{0.50, 0.75, 1.00, 1.25, 1.50}以获得最佳性能。
(图3:消融研究:集合级增强的攻击成功率(%)。左图为图像集,右图为标题集。)多尺度图像集: 图3左侧的结果显示,随着引入具有不同尺度的更多样化图像,迁移性显著增加,当尺度范围设置为[0.50, 1.50],步长为0.25时达到峰值。因此,将尺度范围S设置为{0.50, 0.75, 1.00, 1.25, 1.50}以获得最佳性能。
多对标题集: 图3右侧的结果表明,如果M > 1(M表示每个图像最匹配的标题对数量),黑盒性能会显著提高,但最终会趋于平稳。这些结果证明了使用多个保留对齐的模态间信息来增强对抗迁移性的有效性。此外,观察到性能对额外标题的数量相对不敏感,但添加更多标题可以提高整体对抗迁移性。
6、结论
本文首次尝试研究典型VLP模型的对抗迁移性。系统地评估了现有的攻击方法,并揭示了尽管它们在白盒设置中表现出色,但仍然表现出较低的迁移性。本文的研究强调了在多模态学习中需要专门设计的可迁移攻击,这种攻击可以对多对多跨模态对齐和交互进行建模。本文提出了SGA,一种高度可迁移的多模态攻击,它通过跨模态指导利用集合级的保留对齐增强来彻底利用多模态交互。希望这项工作能够激励进一步的研究来评估和增强VLP模型的对抗鲁棒性。
[1]:Jiaming Zhang, Qiaomin Yi, and Jitao Sang. Towards adversarial attack on vision-language pre-training models. Proceedings of the 30th ACM International Conference on Multimedia, 2022.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
