基本信息
原文标题:QLPro: Automated Code Vulnerability Discovery via LLM and Static Code Analysis Integration
原文作者:Junze Hu, Xiangyu Jin, Yizhe Zeng, Yuling Liu, Yunpeng Li, Dan Du, Kaiyu Xie, Hongsong Zhu
作者单位:未明确
关键词:漏洞检测、静态分析、大语言模型、代码审计、自动化规则生成
原文链接:https://arxiv.org/pdf/2506.23644
开源代码:暂无
论文要点
论文简介:本文提出了一种名为QLPro的新框架,通过将大语言模型(LLM)与静态代码分析工具结合,实现了对代码漏洞的全自动化检测。该框架引入了三重投票机制和三角色机制,有效解决了传统静态分析工具依赖预定义规则以及LLM在语法正确性和上下文理解方面的不足。实验表明,QLPro在JavaTest数据集上的表现优于现有工具,能够识别更多已知漏洞并发现6个0day漏洞。
研究目的:针对当前静态代码分析工具和LLM在漏洞检测中的局限性,如规则通用性不足、LLM生成代码的语法错误率高、依赖专家手动编写规则等,本文旨在开发一种无需人工干预的自动化漏洞检测方法,使非安全专业人员也能高效识别项目中的潜在漏洞。
研究贡献:
提出首个结合LLM与静态分析工具的全自动漏洞扫描规则生成框架,通过投票机制和三角色机制提升LLM的性能。
构建了一个包含10个开源Java项目的JavaTest数据集,涵盖62个已知漏洞,作为评估基准。
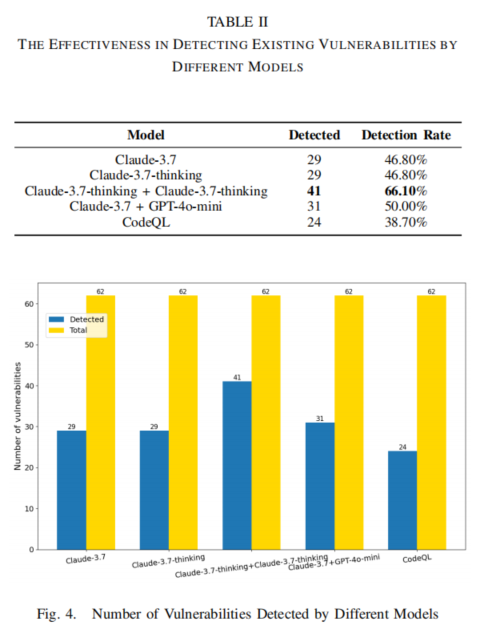
实验结果表明,QLPro在CodeQL语法正确率(90.90%)和漏洞检测数量(41个)上均优于官方规则库(24个),并发现了6个此前未知的0day漏洞。
引言
在现代软件开发中,代码审计已成为识别高危漏洞的重要手段。然而,随着开源项目规模和复杂度的增加,传统的手工代码审查方式变得越来越不切实际。静态代码分析工具(如GitHub CodeQL、Snyk Code等)虽然能够在一定程度上自动检测漏洞,但其依赖于预定义的扫描规则,这些规则通常是通用性的,难以适应不同项目的特定上下文和业务逻辑,导致无法深入挖掘潜在风险点。
为了解决这一问题,当前主流做法是依靠安全专家手动编写定制化的扫描规则。尽管这种方法可以在一定程度上提高规则与项目代码的匹配度,但也存在诸多限制:首先,规则质量高度依赖于专家的知识水平和经验;其次,规则的设计、测试和维护需要大量时间和人力资源;最后,即使投入大量资源,也无法保证规则能有效检测未知漏洞或覆盖所有潜在风险点。
近年来,大语言模型(LLM)在代码生成领域展现出巨大潜力。例如,Codex模型基于GPT-3,成为GitHub Copilot的核心技术;Claude 3模型在零样本代码生成任务中表现出色。然而,直接使用LLM生成漏洞扫描规则仍面临挑战:一方面,LLM生成的规则质量严重依赖于输入的静态污点规范(taint specification),而这些规范通常需要精确描述污点传播路径;另一方面,LLM在处理特定编程语言(如CodeQL)时,由于语法结构的特殊性,难以生成可直接编译的代码文件。
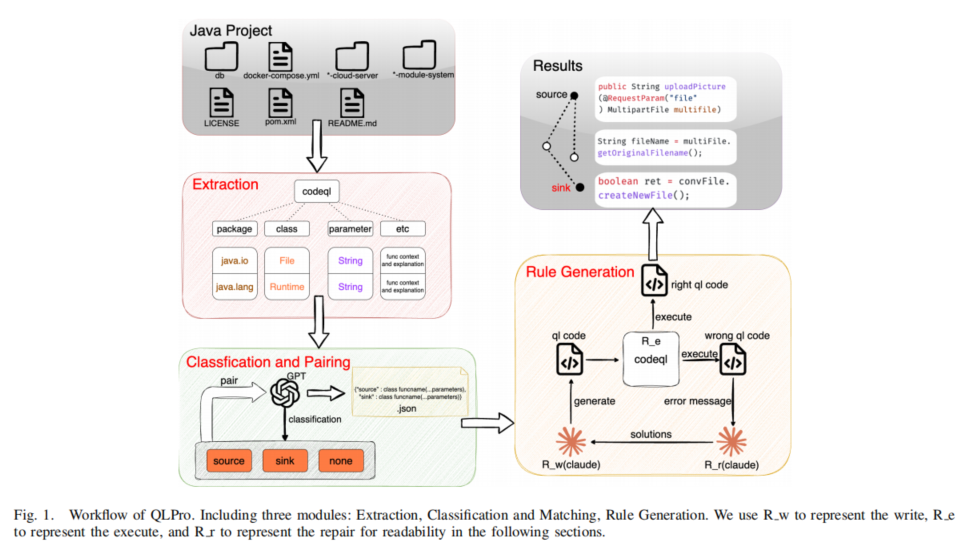
为应对上述挑战,本文提出了QLPro框架,它结合了LLM与静态分析工具,实现了从静态污点规范提取、分类匹配到漏洞扫描规则生成的全过程自动化。具体而言,QLPro首先利用静态分析工具(如CodeQL)提取项目中的所有污点规范,然后通过LLM和三重投票机制对这些规范进行分类和匹配,形成有效的(source, sink)二元组。最后,通过三角色机制(Writer、Repair、Execute)增强LLM生成的QL文件的语法正确性,从而显著提高漏洞扫描规则的质量和检测能力。
前期工作
在静态代码分析中,污点追踪(taint tracking)是核心概念之一,主要包括源(source)、汇(sink)和消毒器(sanitizer)三个关键要素。源代表程序中未受信任数据的入口点,如用户输入;汇则是可能引发漏洞的操作点,如数据库查询或文件操作;消毒器则用于清理或验证数据,可能中断污点传播链。
在CodeQL中,源和汇的配对构成了漏洞检测的基础。只有正确的(source, sink)配对才能触发特定的漏洞类型。例如,在SQL注入场景中,一个有效的配对可能是(getParameter(), executeQuery()),其中getPrameter()获取未受信任的输入,而executeQuery()执行可能引发漏洞的SQL查询。
为了实现有效的漏洞检测,静态分析工具通常需要完成以下三个步骤:
源和汇的提取与分类:从代码中提取潜在危险的函数调用,并将其分类为源、汇或消毒器。
源汇配对:根据代码逻辑和污点传播路径,将源和汇进行合理配对。
查询规则生成:基于配对结果,自动生成符合语法要求的查询规则(如CodeQL规则)。
然而,传统方法在处理大规模项目时面临挑战。一方面,静态分析工具的规则库通常过于通用,难以适应特定项目的需求;另一方面,LLM在生成代码时容易出现语法错误,尤其是在处理特定语言(如CodeQL)时,这限制了其在实际应用中的效果。
QLPRO框架
QLPro框架由三个主要模块组成:提取模块、分类与匹配模块和规则生成模块,分别负责从项目中提取污点规范、分类和匹配源汇对,以及生成语法正确的漏洞扫描规则。
A. 提取技术
提取模块的目标是从Java开源项目中提取潜在危险的函数调用。首先,使用CodeQL提取项目中的所有API,包括包名、参数列表、返回类型、注解信息等元数据。随后,去除那些不太可能引发安全风险的函数调用,并删除重复的调用,因为它们通常出现在不同的文件或位置,而研究者的关注点在于函数特征和相关代码片段,而非调用位置。最终,将这些信息整理成JSON格式,以便后续处理。
B. 分类与组合
在分类与匹配模块中,研究者设计了一种结构化提示模板,引导LLM对API信息进行语义分析和分类。该模板包括五个关键概念:源点、汇点、消毒器点、污点传播链等。通过输入API信息,LLM可以逐步解析每个方法,并依据9个特征识别潜在的汇点,8个启发式方法定位源点,3个标准识别可能中断污点传播的消毒器点。随后,通过三阶段算法确定源和汇之间的有效污点传播路径,并输出符合安全隐含条件的(source, sink)二元组。
然而,由于LLM的输入容量有限,无法一次性处理所有JSON数据,因此研究者将数据分组以确保每组长度在模型输入范围内。这种分组策略带来了新的挑战——模型在处理同一组内的API时容易受到上下文干扰,影响分类精度。为此,研究者提出了三重投票机制:每个API被放置在三个不同的上下文中独立评估,最终分类结果通过多数投票原则决定,从而有效减少上下文偏差对分类准确性的影响。
C. 规则生成
在规则生成模块中,研究者采用三角色机制(Writer、Repair、Execute)来提高LLM生成的QL文件的语法正确性。Writer负责根据上游模型提供的(source, sink)二元组生成相应的QL文件,并传递给Executor。Executor尝试编译和执行这些文件,若失败,则将QL文件和错误信息传递给Repairer。Repairer分析错误信息并提出修改建议,反馈给Writer,后者根据建议调整代码,重复上述过程,直到QL文件成功编译和执行。若经过最大修改次数后仍未成功,则认为该文件无效。
研究评估
为验证QLPro的有效性,研究者构建了JavaTest数据集,包含10个广泛使用的开源Java项目,平均星标数为10.53K,总共有62个已确认的漏洞。这些项目平均包含50K行代码,部分项目甚至超过100K行,具有较高的复杂度,适合作为漏洞检测的基准数据集。
A. 数据集
JavaTest数据集的选择标准包括:项目必须完全可编译,以支持静态分析技术的应用;项目应来自真实应用场景,以体现更高的复杂性和挑战性;项目中的漏洞必须可验证,以便可靠评估检测工具的性能。
B. 模型选择
在实验中,研究者选择了两个封闭源代码的LLM:Claude-3.7(版本:Claude3.7-sonnet-2025-0219)和Claude-3.7-thinking(版本:Claude-3-7-sonnet-20250219-thinking)。此外,还纳入了一个额外的封闭源代码LLM GPT-4o-mini,以提供更全面的对比分析。
C. 研究结果
1) RQ1: Syntactic Correctness Rate of Rules Generated by QLPro
由于CodeQL的语法结构特殊,LLM在生成代码时难以达到接近完美的语法正确性,除非经过特定优化。因此,研究者评估了QLPro生成的QL文件的语法正确率,以成功编译为基准。实验结果显示,当使用两个Claude-3.7-sonnet-thinking实例协作时,语法正确率达到90.90%,显著高于单一模型的表现。
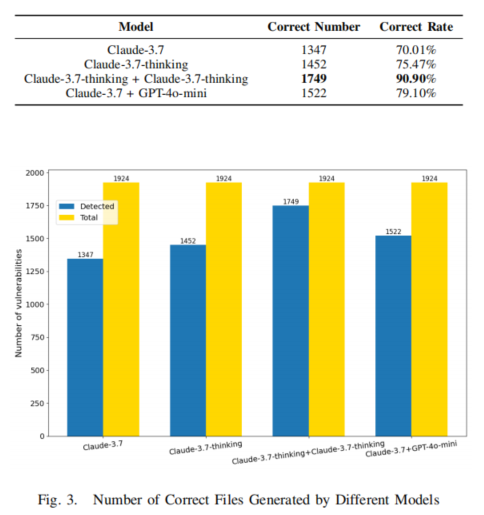
2) RQ2: Effectiveness of QLPro in Detecting Existing Vulnerabilities
在JavaTest数据集上,QLPro(与两个Claude-3.7-sonnet-thinking结合)检测到了41个漏洞,而官方规则库仅检测到24个。分析表明,官方规则库中(source, sink)对的定义较为宽泛,导致部分漏洞被遗漏。这表明QLPro在检测已有漏洞方面优于官方规则库,降低了遗漏潜在安全问题的可能性。
3) RQ3: Capability of QLPro in Detecting Unknown (0-Day) Vulnerabilities
研究者对QLPro(与两个Claude-3.7-sonnet-thinking结合)和官方CodeQL规则库进行了测试。结果发现,QLPro检测到了6个此前未报告的漏洞(0day),其中2个已被开发者确认为0day漏洞,其余4个正在确认中。这些漏洞包括SQL注入、任意文件上传和任意文件读取等类型,且未被官方规则库检测到,证明了QLPro在检测未知漏洞方面的能力。
论文结论
本文系统地探讨了如何通过集成大语言模型与静态代码分析工具,实现代码漏洞的全自动化检测。为最大化LLM的潜力,研究者设计了三重投票机制和三角色机制。QLPro的评估结果表明,它在测试数据集中成功检测到62个漏洞中的41个(66.1%),显著优于官方CodeQL工具的24个(38.7%)。此外,QLPro还发现了6个此前未知的0day漏洞,证明了其在检测未知漏洞方面的优势。
QLPro使非安全专业的开发人员能够高效快速地识别开源项目中的漏洞,从而推动了安全分析能力的民主化。未来的研究方向包括扩展QLPro到其他编程语言,以及优化其在实时检测中的性能。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
