
原文标题:SymAgent: A Neural-Symbolic Self-Learning Agent Framework for Complex Reasoning over Knowledge Graphs
原文作者:Ben Liu, Jihai Zhang, Fangquan Lin, Cheng Yang, Min Peng, Wotao Yin原文链接:https://dl.acm.org/doi/10.1145/3696410.3714768发表会议:WWW "25笔记作者:彭佳仁@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1. 研究背景
大语言模型(LLMs)在解决复杂推理问题时容易产生幻觉,导致错误结果。为解决此问题,研究者引入知识图谱(KGs)以增强LLMs的推理能力。然而,现有方法存在两大局限:1) 通常假设问题答案完全包含在KG中,忽视了KG的不完整性问题;2) 将KG视为静态知识库,忽略了KG中固有的隐式逻辑推理结构。
为此,本文提出SymAgent,将KG概念化为动态环境,将复杂推理任务转化为多步交互过程,使KG深度参与推理。SymAgent包含两个模块:智能体规划器(Agent-Planner)和智能体执行器(Agent-Executor)。规划器利用LLM的归纳推理能力从KG中提取符号规则,指导高效问题分解;执行器自主调用预定义动作工具整合KG与外部文档信息,解决KG不完整性问题。此外,SymAgent设计了包含在线探索和离线策略迭代更新的自学习框架,使智能体能自动合成推理轨迹并提升性能。
实验表明,基于弱骨干LLM(如7B系列)的SymAgent在多项复杂推理数据集上优于或媲美各类强基线模型。进一步分析揭示,本框架能识别缺失三元组,促进KG自动更新。
2. 问题定义
知识图谱是事实三元组的集合,表示为 ,其中 和 分别表示实体和关系的集合。知识图谱中的符号规则通常表示为一阶逻辑公式:
其中左手边表示规则头,其关系 可以由右手边的规则体导出,规则体形成一个封闭链,连续的关系共享中间变量,由规则体关系的合取( )表示。一个知识图谱可以被看作是符号规则的实例化,通过用特定实体替换所有变量 , , 实现。
给定一个问题 和知识图谱 ,大型语言模型智能体根据其策略 生成行动 。智能体接收执行反馈作为观察 ;然后,智能体继续探索环境,直到找到合适的答案或满足其他停止条件。在步骤 时的历史轨迹 ,由一系列行动和观察组成,可以表示为:
其中 是总交互步数。最后,计算最终奖励 ,其中 1 表示答案正确。
3. SymAgent框架设计
SymAgent 包括一个 Agent-Planner (智能体规划器),它从知识图谱中提取符号规则以分解问题和规划推理步骤;以及一个 Agent-Executor ,它综合来自反思和环境反馈的见解来回答问题 。为了解决缺乏已标注推理数据的问题,SymAgent 引入了一个自学习框架,通过自主交互实现协作改进。整体架构如下图所示:
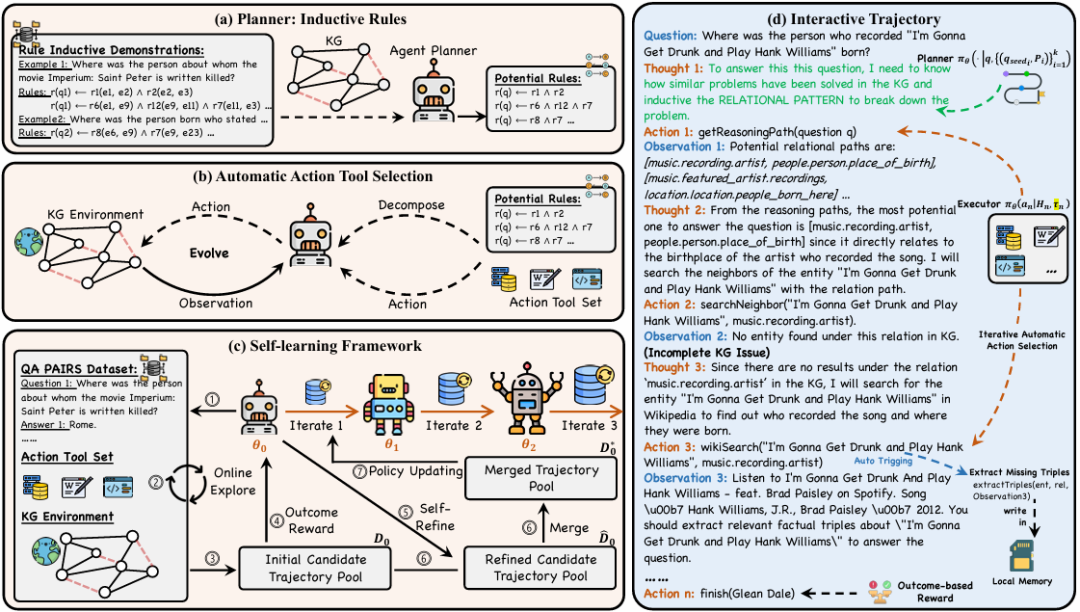
3.1 Agent-Planner 模块
给定一个问题 ,Planner使用 BM25 从训练集中检索一组种子问题 ,其中每个 与 具有相似的问题结构,可能需要类似的解决策略。对于每个 ,采用广度优先搜索 (BFS)从查询实体 到答案实体 在知识图谱 中采样一组封闭路径 ,其中 是一系列关系。这些封闭路径可以被视为回答问题的符号规则的实例化。然后,通过用变量替换特定实体来泛化这些封闭路径,将它们转化为方程 中所示的规则体。这个过程构建了少样本演示 来提示 SymAgent 为 生成适当的规则体:
其中 代表指导规则体生成的提示。生成的与知识图谱对齐的符号规则 用于指导 SymAgent 的全局规划,并防止其在推理过程中陷入盲目的试错。
3.2 Agent-Executor模块
基于从知识图谱 生成的符号规则,Agent-Executor 进行观察(observation)、思考(thought)和行动(action)的循环模式,以导航自主推理过程。
通过利用大型语言模型的函数调用能力,SymAgent 不仅克服了大型语言模型在处理结构化数据方面的局限性,而且提供了一种灵活的机制来集成不同的信息源,从而增强智能体的推理能力和适应性。智能体包括以下功能工具:
getReasoningPath(sub_question):接收子问题sub_question作为输入,并返回潜在的符号规则。如方程3所示,此行动利用大型语言模型的归纳推理能力生成与知识图谱对齐的符号规则,这些规则分解子问题,从而有效指导推理过程。wikiSearch(ent, rel):当知识图谱信息不足时,从维基百科或互联网检索相关文档。此行动将结构化的知识图谱数据与非结构化文本联系起来,以不完整信息增强推理能力。extractTriples(ent, rel, doc):从检索到的文档中提取与当前查询实体和关系相关的三元组。值得注意的是,此行动并非由智能体显式调用,而是在wikiSearch被调用后自动触发。提取的三元组与知识图谱的语义粒度对齐,并且可以集成到知识图谱中,从而促进其扩展。searchNeighbor(ent, rel):这是一个图探索函数。它返回知识图谱中特定实体在给定关系下的邻居,从而能够有效地遍历和发现相关实体。finish(e_{1},e_{2},...,e_{n})$:返回一个答案实体列表,表示已获得最终答案并且推理过程已结束
形式上,SymAgent 扩展方程 ,步骤 时的交互轨迹可以进一步表示为:
其中 是智能体通过反思历史轨迹产生的内部思考, 是从上述定义的工具集中选择的行动, 是通过执行行动确定的观察结果。基于此历史轨迹,生成后续思考 和行动 的过程可以公式化为:
其中 和 分别代表 的第 个标记和总长度, 和 分别代表 的第 个标记和总长度。智能体循环持续进行,直到调用 finish() 行动或达到预定义的最大迭代步数。
3.3 自学习
在线探索:
在此阶段,基础智能体 通过思考-行动-观察循环与环境自主交互,合成一组初始轨迹 。对于每个轨迹 ,采用基于结果的奖励机制,将奖励定义为最终答案的召回率值:
其中 是从轨迹 的最终行动中提取的答案实体集合, 是真实答案实体的集合。这个过程产生了一个自探索轨迹的集合 。
为解决智能体行动调用中可能存在的错误(例如,不正确的工具调用格式)可能损害探索有效性的问题,SymAgent 利用大型语言模型的自我反思能力来优化轨迹。使用 作为参考,策略大型语言模型 重新生成新的优化轨迹,公式化为 。在应用相同的奖励机制后,可以得到一个优化的轨迹集合 。 经过自探索和自反思后,可以获得两个大小相等的轨迹集合: 和 。为提高候选轨迹的质量,采用启发式方法合并这两个集合,从而得到一个优化的轨迹集。遵循最终答案一致性的原则,获得合并后的轨迹集合 。
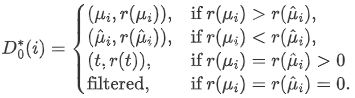
在此方程中, 表示当奖励相等且非零时,选择长度较短的轨迹。
离线迭代策略更新:
给定合并后的轨迹 ,改进智能体性能的一个直观方法是使用这些轨迹进行微调。在自回归方式下,智能体模型的损失可以公式化为:
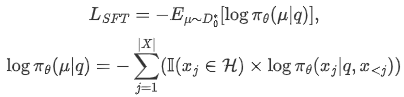
其中 是关于 是否属于智能体生成的思考或行动的指示函数。
4 实验
4.1 数据集
实验采用三个流行的知识图谱问答数据集进行评估:WebQuestionSP (WebQSP)、Complex Web Questions (CWQ) 和 MetaQA-3hop。WebQSP 和 CWQ 数据集是根据常识知识图谱 Freebase 构建的,其中包含最多4跳的问题。MetaQA-3hop 基于一个特定领域的电影知识图谱,这个数据集用于评估模型在特定领域场景下的零样本推理性能。这意味着模型只在 CWQ 和 WebQSP 上进行训练,然后在 MetaQA-3hop 上进行上下文推理,以评估模型的泛化能力。为了进一步模拟不完整的知识图谱,采用广度优先搜索方法从问题实体到答案实体提取路径,然后遵循相关研究的设置随机移除一些三元组。在这种情况下,由于形式化表达式不可执行,语义解析方法无法获得正确答案。为了更好地评估模型在复杂推理任务上的性能,从测试集中抽样了一个子集,这些问题特别需要多跳推理来解决。
4.2 实验结果

安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
