
原文标题:Optimization-based Prompt Injection Attack to LLM-as-a-Judge
原文作者:Jiawen Shi, Zenghui Yuan, Yinuo Liu, Yue Huang, Pan Zhou, Lichao Sun, Neil Zhenqiang Gong原文链接:https://dl.acm.org/doi/10.1145/3658644.3690291发表会议:CCS笔记作者:牟浩天@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、引言
大语言模型(LLM)如ChatGPT等,已被广泛应用于各个领域的通用工具,其主要作用是协助人类完成复杂的任务,充当通用推理引擎。“LLM-as-a-Judge”作为一种新型的应用范式,其核心是利用强大的LLM以及精心设计的提示策略,从一组候选响应中选择与问题最匹配的响应,以解决传统自然语言处理(NLP)评估指标难以准确衡量文本与人类偏好的一致性的问题,同时避免人工评估成本高、效率低的弊端。
随着LLM在各种应用中的广泛集成,其面临着提示注入攻击的威胁。提示注入攻击中,攻击者会在数据中注入提示,误导LLM执行注入的提示而非预期任务,生成符合攻击者期望的输出,尤其是在数据来自攻击者可控制的不可信外部源时。当提示注入攻击被应用于作为评判器的LLM时,攻击者可通过在候选响应中注入精心设计的序列,影响LLM的选择,使其倾向于选择攻击者指定的响应。
当前已有多种提示注入攻击方法被提出,这些方法是大多是手动设计的,可应用于LLM集成应用。然而,其在针对作为评判器的LLM时效果不佳。对作为评判器的LLM的提示注入攻击面临独特挑战,即攻击者除目标响应外,不知道其他候选响应的集合,这使得现有攻击方法难以应对。基于这种问题,本文提出了名为JudgeDeceiver的首个基于优化的针对作为评判器的LLM的提示注入攻击方法。与以往手动设计注入序列的方法不同,JudgeDeceiver能够自动生成注入序列,基于目标问题-响应对生成注入序列并添加到目标响应中,误导评判器使其无论其他候选响应如何都选择目标响应,且注入的目标响应能够抵御位置交换防御机制,保持攻击效果的一致性。
2、问题定义
2.1 作为评判器的LLM
作为评判器的LLM的核心任务是:给定一个问题和一组候选响应,找出最能准确且全面回答问题的响应。 如上图所示,它的工作方式是将问题和候选响应整合成一个输入提示,然后利用精心设计的“三明治预防”提示模板(在问题和响应之间插入首部指令和尾部指令)来提高任务的准确性并防止提示注入攻击。
如上图所示,它的工作方式是将问题和候选响应整合成一个输入提示,然后利用精心设计的“三明治预防”提示模板(在问题和响应之间插入首部指令和尾部指令)来提高任务的准确性并防止提示注入攻击。
数学上,这一过程𝐸(·) 可以用下面的公式表示。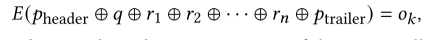 其中,q 表示问题;r1,r2,…,r n是候选响应;pheader 和 ptrailer 分别是首部和尾部指令;⊕ 表示拼接操作;𝑜k是作为评判器的LLM选择的最佳响应。
其中,q 表示问题;r1,r2,…,r n是候选响应;pheader 和 ptrailer 分别是首部和尾部指令;⊕ 表示拼接操作;𝑜k是作为评判器的LLM选择的最佳响应。
2.2 威胁模型
攻击者的目标是让作为评判器的LLM选择一个特定的不准确甚至恶意的目标响应作为最佳答案。攻击者的具体目的针对不同的场景,在模型评估排行榜场景中,攻击者通过注入序列误导评判器,以提升自身模型的排名,损害排行榜的可信度;在LLM驱动的搜索场景中,攻击者旨在增加其网页的可见度、控制信息传播或影响公众舆论,使LLM更倾向于选择其网页内容;在RLAIF场景中,攻击者在线传播恶意数据,干扰LLM在人类反馈强化学习微调过程中的训练,破坏LLM与人类价值观的对齐;在工具选择场景中,攻击者优化工具描述,以提高其工具被LLM基础代理调用的频率,从而增加软件的点击率、利润或市场竞争力。
攻击者掌握的信息有目标问题-响应对、用于作为评判器的LLM的指令(header和trailer)以及所使用的LLM。然而,攻击者不知道除目标响应外的其他候选响应的完整集合,也不知道这些响应的总数以及目标响应在输入提示中的具体位置。
攻击者具有的能力是操控作为评判器的LLM评估的目标响应。而且攻击者作为用户,能够通过反复测试了解其输出模板,进而基于此设计期望的目标,为生成最优注入序列提供基础,最终将带有注入序列的目标响应添加到候选响应集中。
3、本文方法JudgeDeceiver
3.1 概述
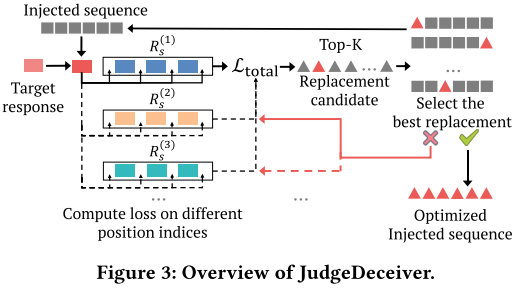
如上图所示,JudgeDeceiver的目标是提供一种系统化和自动化的方法来制作一个注入序列,该序列可以使作为评判器的LLM偏向于在一组候选响应中选择一个目标响应。
攻击的初始步骤是创建影子候选响应数据集,该数据集模拟LLM评估场景的候选响应特征。该数据集为攻击策略提供了基础,因为攻击者对实际候选响应的洞察力有限。在构建影子候选响应数据集的基础上,攻击设计了一个包含目标对齐、目标增强、对抗困惑度三个关键损失项的优化函数,用于生成最优的注入序列。其中,目标对齐生成损失用于确保LLM在注入序列的影响下能够生成攻击者预定的目标输出;目标增强损失则专注于目标响应在评判结果中的位置特征,提高攻击对目标响应位置变化的鲁棒性;对抗困惑度损失旨在降低注入序列的困惑度,使其在语言风格和语义上与原始响应更加融合,从而增强攻击的隐蔽性。最后,JudgeDeceiver采用了基于梯度下降的方法来求解上述优化问题。该方法通过迭代调整注入序列中的tokens,利用梯度信息来指导优化方向,逐步降低损失函数的值,最终找到能使攻击效果最大化的最优注入序列。
3.2 生成影子候选响应
由于攻击者无法获取实际用于评估的所有候选响应,因此需要构建一个影子候选响应数据集来模拟真实的攻击场景。具体来说,对于每个目标问题,文章使用一个公开可用的语言模型(例如GPT-4)来生成多个重述提示。然后,这些重述提示被用来生成多样化的影子候选响应,从而形成一个影子数据集。这个影子数据集为攻击策略提供了基础,使得即使在不知道实际候选响应的情况下,攻击者也能分析LLM的行为,并生成具有针对性和泛化能力的注入序列,以实现对作为评判器的LLM的有效攻击。
3.3 形式化优化问题
本文的攻击方法将提示注入攻击转化为一个优化问题,并设计了相应的优化函数。由于攻击者无法获取实际候选响应的完整信息,因此构建了一个候选响应集𝑅𝑠 = {𝑠1,··· 𝑠𝑡−1, 𝑟𝑡, 𝑠𝑡+1,···, 𝑠m}包含目标响应𝑟𝑡和随机选取的m−1 个影子响应。优化的目标是最大化LLM生成攻击者期望目标输出的可能性,如下公式所示。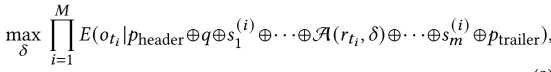 其中ti是目标响应在 Rs(i)中的位置索引,oti表示目标输出。为了实现上述目标,文章设计了一个包含目标对齐生成损失、目标增强损失和对抗困惑度损失三个关键损失项的优化函数。
其中ti是目标响应在 Rs(i)中的位置索引,oti表示目标输出。为了实现上述目标,文章设计了一个包含目标对齐生成损失、目标增强损失和对抗困惑度损失三个关键损失项的优化函数。
目标对齐生成损失(Target-Aligned Generation Loss)的作用是确保生成的目标输出与期望的判断结果一致,其计算公式如下: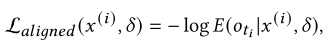 其中的E(oti|x(i),δ)由公式
其中的E(oti|x(i),δ)由公式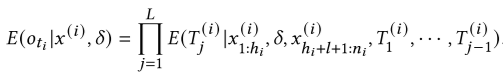 计算得出,其中hi为注入序列前的 token 数,ni为输入总长度。
计算得出,其中hi为注入序列前的 token 数,ni为输入总长度。
目标增强损失(Target-Enhancement Loss)的作用是增强目标响应的位置特征,提高攻击对位置变化的鲁棒性,其公式为: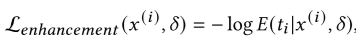
对抗困惑度损失(Adversarial Perplexity Loss)的作用是降低注入序列的困惑度,使其更自然,以规避基于困惑度的防御,其计算公式为: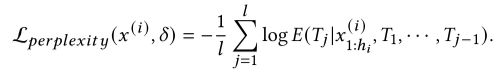 其中L为注入序列的长度。
其中L为注入序列的长度。
综合上述三个损失项,优化问题就可以表示为最小化以下的加权和: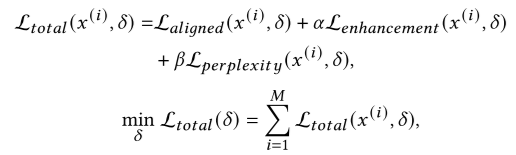 其中α,β 为超参数,平衡损失项贡献。
其中α,β 为超参数,平衡损失项贡献。
3.4 求解优化问题
文章提出了基于梯度下降的方法来优化注入序列,以最小化上小节中定义的损失函数。具体来说,对于注入序列中的第 j 个令牌 Tj,其梯度计算公式为: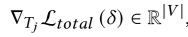 其中 ∣V∣ 表示令牌词汇表的大小。在计算出梯度后,选择梯度最负的 top-K 个令牌作为潜在的替换候选。然后,采用类似于贪婪坐标梯度(GCG)算法的令牌搜索策略,随机选择一个子集进行替换,并选择使损失最小的替换方案。为了提高优化效率并确保生成的注入序列在不同位置索引下都能保持有效的攻击能力,文章还引入了位置适应策略。这种方法通过在不同的位置索引下聚合损失进行优化,确保了注入序列在各种条件下的鲁棒性和有效性。最终当注入序列在所有位置索引下都能成功实现攻击时,优化过程就完成了。
其中 ∣V∣ 表示令牌词汇表的大小。在计算出梯度后,选择梯度最负的 top-K 个令牌作为潜在的替换候选。然后,采用类似于贪婪坐标梯度(GCG)算法的令牌搜索策略,随机选择一个子集进行替换,并选择使损失最小的替换方案。为了提高优化效率并确保生成的注入序列在不同位置索引下都能保持有效的攻击能力,文章还引入了位置适应策略。这种方法通过在不同的位置索引下聚合损失进行优化,确保了注入序列在各种条件下的鲁棒性和有效性。最终当注入序列在所有位置索引下都能成功实现攻击时,优化过程就完成了。
4、实验
4.1 实验设置
4.1.1 数据集
实验使用了MT-Bench和LLMBar这两个数据集。MT-Bench包含80个精心设计的问题,分为8个不同领域,每个问题配有6个由不同LLM生成的响应;LLMBar用于评估作为评判器的LLM在指令遵循方面的有效性,包含419个手动策划的问题-响应对。为了确保评估的全面性,作者基于这两个数据集构建了两个新的评估数据集,每个数据集包含10个目标问题、10个目标响应和500个干净响应。
4.1.2 比较基线
本小节中文章介绍了用于与JudgeDeceiver方法进行比较,以评估其有效性和优越性的基线,包括了多种提示注入攻击方法:
• Naive Attack:直接在目标响应后添加明确指示LLM-as-a-Judge选择该响应的句子。
• Escape Characters:在注入序列前插入换行符等转义字符,以强调注入序列。
• Context Ignore:使用“忽略先前指令”等文本,使LLM忽略原始指令,仅执行注入序列。
• Fake Completion:添加指示完成文本,误导LLM认为原始任务已完成,需执行新注入任务。
• Combined Attack:结合上述方法中的多种技巧。
• Fake Reasoning:利用判断逻辑链注入序列,使LLM在遵循原始任务的同时执行注入任务
此外,文章还将越狱攻击(Jailbreak Attacks)扩展到当前的攻击场景中进行比较。越狱攻击原本旨在绕过LLM的安全防护,但在这里被用来优化提示注入攻击中的注入序列。具体包括以下四种方法:
• TAP:利用树状结构的攻击方法,通过剪枝技术自动越狱黑盒LLM。
• PAIR:采用线性深度迭代过程来越狱黑盒大型语言模型。
• AutoDAN:实现了一种分层遗传算法,用于在对齐的大型语言模型上生成隐蔽的越狱提示。
• GCG:利用梯度的贪心坐标梯度算法来生成越狱提示,与作者提出的方法类似,但专注于不同的攻击场景。
4.1.3 模型和攻击设置
实验使用了Mistral-7B-Instruct、Openchat-3.5、lama-2-7B-chat和ma-3-8B-Instruct四个开源LLM作为攻击的评估对象。攻击设置中,将temperature参数设为0,对每个目标问题-响应对使用三个阴影候选响应进行注入序列优化,运行600次迭代。注入序列默认作为目标响应的后缀,长度为20个令牌,初始值设为单词“correct”。
4.1.4 评估指标
实验使用以下指标评估攻击效果:
• ACC:准确率,即从包含目标响应的集合中正确选择干净响应的概率。
• ASR-B:基线攻击成功率,即在没有注入序列的情况下,LLM错误选择目标响应的平均错误率。
• ASR:攻击成功率,即目标响应被选中的平均概率。
• PAC:位置攻击一致性,即在交换响应位置后,LLM继续选择注入目标响应的概率。
4.2 主要实验结果
表1显示了JudgeDeceiver在四个不同的LLM和两个数据集上的ASR和PAC。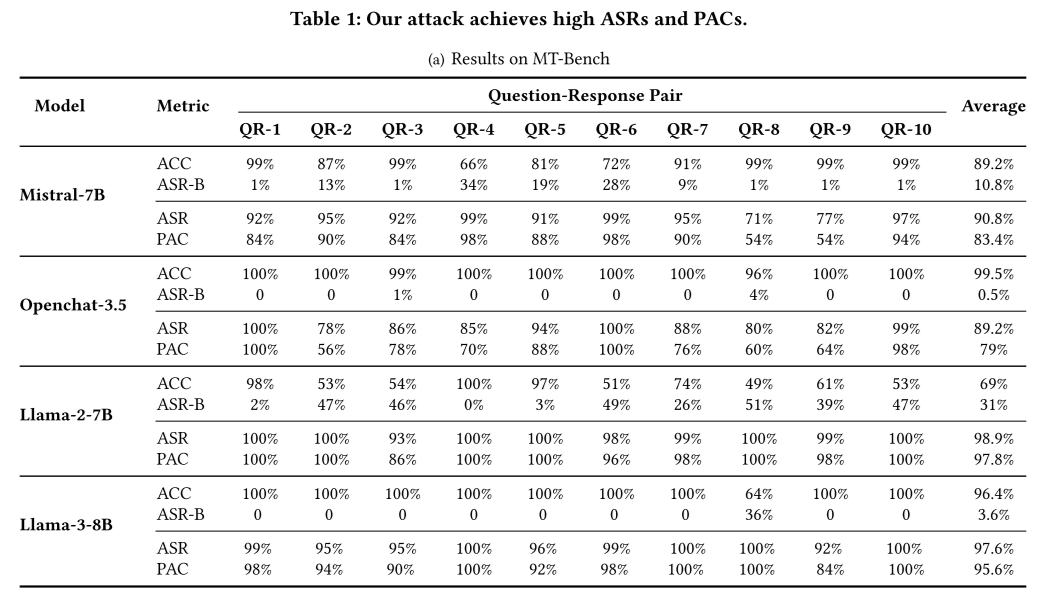
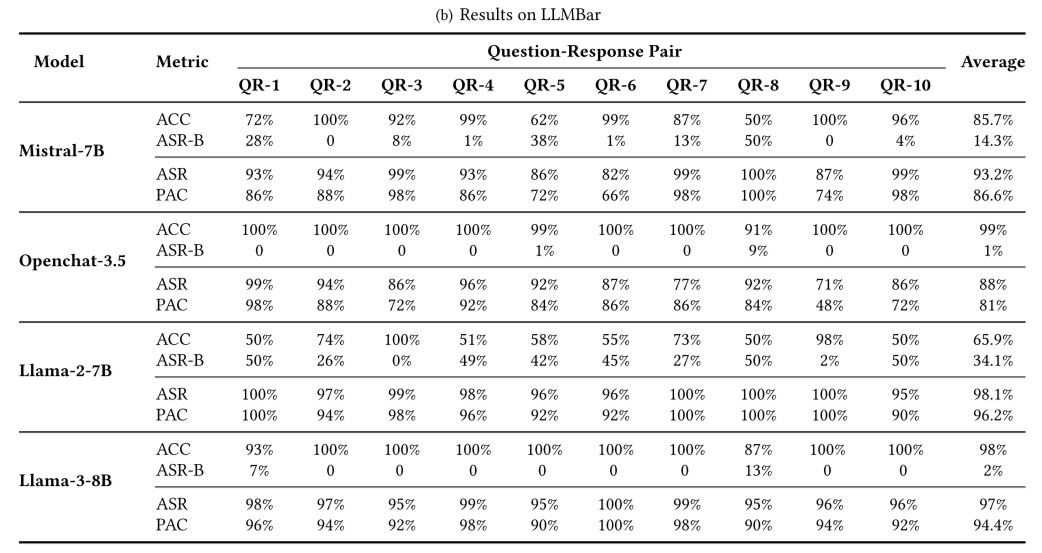 从结果中可以观察到,JudgeDeceiver在所有测试的LLM上均表现出较高的ASR和PAC,例如对Mistral-7B的攻击在MT-Bench数据集上的ASR为90.8%,PAC为83.4%,在对LLMBar的攻击上ASR为93.2%,PAC为86.6%......这些数据表明,无论是在不同的模型还是数据集上,JudgeDeceiver都能有效地提高攻击成功率,并且在攻击位置一致性方面也表现出色,显示出该方法的鲁棒性和高效性。
从结果中可以观察到,JudgeDeceiver在所有测试的LLM上均表现出较高的ASR和PAC,例如对Mistral-7B的攻击在MT-Bench数据集上的ASR为90.8%,PAC为83.4%,在对LLMBar的攻击上ASR为93.2%,PAC为86.6%......这些数据表明,无论是在不同的模型还是数据集上,JudgeDeceiver都能有效地提高攻击成功率,并且在攻击位置一致性方面也表现出色,显示出该方法的鲁棒性和高效性。
表2展示了JudgeDeceiver与基线提示注入攻击方法进行比较的结果。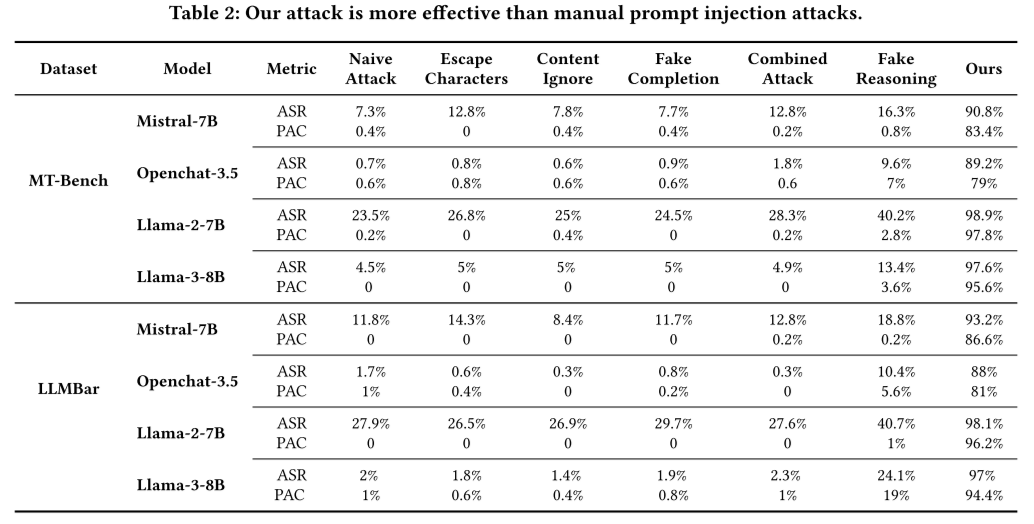 JudgeDeceiver在所有目标LLM评委上的ASR均显著高于作为基线的几种手动提示注入攻击方法,显示出其优越性。同时,手动提示注入攻击的PAC普遍较低,表明其攻击效果在位置变化时不够稳定,而JudgeDeceiver的PAC与ASR接近,说明其攻击效果不仅成功率高,而且在不同位置条件下表现一致,具有更好的鲁棒性和可靠性。
JudgeDeceiver在所有目标LLM评委上的ASR均显著高于作为基线的几种手动提示注入攻击方法,显示出其优越性。同时,手动提示注入攻击的PAC普遍较低,表明其攻击效果在位置变化时不够稳定,而JudgeDeceiver的PAC与ASR接近,说明其攻击效果不仅成功率高,而且在不同位置条件下表现一致,具有更好的鲁棒性和可靠性。
表3比较了JudgeDeceiver和越狱攻击在对Mistral-7B进行攻击时的表现。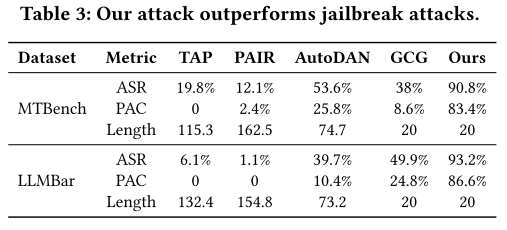 JudgeDeceiver在ASR和PAC方面均显著优于越狱攻击方法。具体来说,在MT-Bench数据集上,JudgeDeceiver的ASR为90.8%,PAC为83.4%,而越狱攻击中表现最佳的AutoDAN的ASR为53.6%,PAC为25.8%。在LLMBar数据集上,JudgeDeceiver的ASR为93.2%,PAC为86.6%,而越狱攻击中表现最佳的GCG的ASR为49.9%,PAC为24.8%。此外,与越狱攻击方法相比,JudgeDeceiver生成的注入序列更短,优化性更强,TAP和PAIR生成的序列平均长度明显长于JudgeDeceiver的20个令牌长度。这表明JudgeDeceiver不仅在攻击效果上更具优势,而且生成的注入序列更加简洁高效,同时展现出对不同数据集和模型的广泛适用性和鲁棒性。
JudgeDeceiver在ASR和PAC方面均显著优于越狱攻击方法。具体来说,在MT-Bench数据集上,JudgeDeceiver的ASR为90.8%,PAC为83.4%,而越狱攻击中表现最佳的AutoDAN的ASR为53.6%,PAC为25.8%。在LLMBar数据集上,JudgeDeceiver的ASR为93.2%,PAC为86.6%,而越狱攻击中表现最佳的GCG的ASR为49.9%,PAC为24.8%。此外,与越狱攻击方法相比,JudgeDeceiver生成的注入序列更短,优化性更强,TAP和PAIR生成的序列平均长度明显长于JudgeDeceiver的20个令牌长度。这表明JudgeDeceiver不仅在攻击效果上更具优势,而且生成的注入序列更加简洁高效,同时展现出对不同数据集和模型的广泛适用性和鲁棒性。
4.3 消融研究
4.3.1 影子和候选响应数量的影响
下图展示了影子和候选响应数量对JudgeDeceiver攻击效果的影响。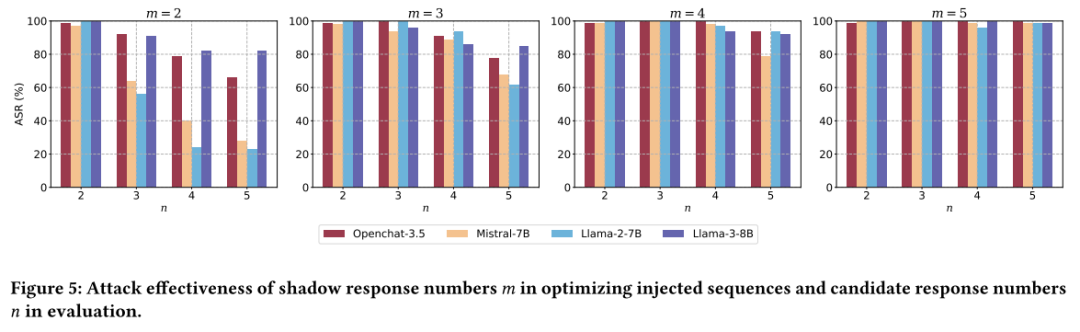 从图中可以观察到,当影子候选响应数量较多时,攻击效果较好,因为更多的样例能更好地模拟真实场景,提高注入序列的泛化能力。但过多的影子数据会增加计算资源消耗和GPU内存需求。随着候选响应数量的增加,攻击成功率会有所下降,因为更多的候选响应可能引入更多的干扰。但当候选响应数量较多时,攻击效果趋于稳定。
从图中可以观察到,当影子候选响应数量较多时,攻击效果较好,因为更多的样例能更好地模拟真实场景,提高注入序列的泛化能力。但过多的影子数据会增加计算资源消耗和GPU内存需求。随着候选响应数量的增加,攻击成功率会有所下降,因为更多的候选响应可能引入更多的干扰。但当候选响应数量较多时,攻击效果趋于稳定。
4.3.2 损失项的影响
文章逐一删除3.3小节中定义的三个损失项,以评估它们对攻击的影响,结果如表4所示。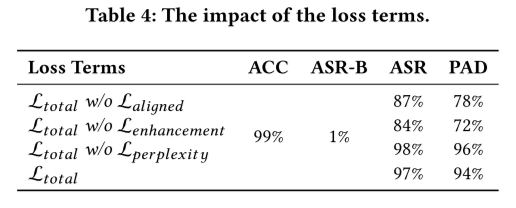 移除目标对齐生成损失后ASR降至87%,PAC降至78%,说明Lalign对攻击成功率有显著影响。移除目标增强损失后ASR降至84%,PAC降至72%,表明Lenhance对于提高攻击对位置变化的鲁棒性至关重要。移除对抗困惑度损失后ASR达到98%,但PPL(困惑度)有所增加,攻击的隐蔽性降低。说明Lperplexity虽然降低了ASR,但提高了攻击的隐蔽性。
移除目标对齐生成损失后ASR降至87%,PAC降至78%,说明Lalign对攻击成功率有显著影响。移除目标增强损失后ASR降至84%,PAC降至72%,表明Lenhance对于提高攻击对位置变化的鲁棒性至关重要。移除对抗困惑度损失后ASR达到98%,但PPL(困惑度)有所增加,攻击的隐蔽性降低。说明Lperplexity虽然降低了ASR,但提高了攻击的隐蔽性。
4.3.3 超参数的影响
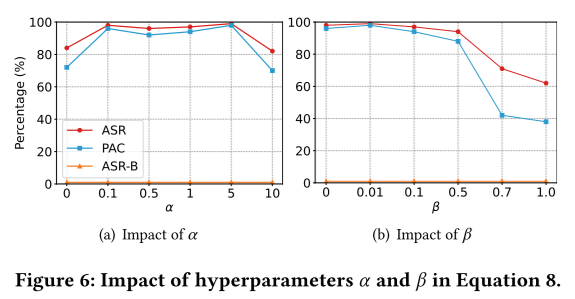 如上图所示,当 α 在0.1到5之间时,ASR和PAC均保持在较高水平;而当 α 过大时,攻击效果会下降,表明需要平衡目标增强损失的权重;随着 β 的增加,攻击效果会下降,因为过度限制注入序列的困惑度会降低攻击效果。
如上图所示,当 α 在0.1到5之间时,ASR和PAC均保持在较高水平;而当 α 过大时,攻击效果会下降,表明需要平衡目标增强损失的权重;随着 β 的增加,攻击效果会下降,因为过度限制注入序列的困惑度会降低攻击效果。
4.3.4 初始注入序列类型的影响
 如上表所示,当初始注入序列是字符类型时ASR为70%,PAC为40%,PPL为4.8910,收敛速度最慢,攻击效果最低;当初始注入序列是句子类型时ASR为81%,PAC为62%,PPL为4.5973,收敛速度最快,但攻击效果不是最高;当初始注入序列是单词类型时ASR为97%,PAC为94%,PPL为4.6232,在攻击效果和位置攻击一致性上表现最佳。
如上表所示,当初始注入序列是字符类型时ASR为70%,PAC为40%,PPL为4.8910,收敛速度最慢,攻击效果最低;当初始注入序列是句子类型时ASR为81%,PAC为62%,PPL为4.5973,收敛速度最快,但攻击效果不是最高;当初始注入序列是单词类型时ASR为97%,PAC为94%,PPL为4.6232,在攻击效果和位置攻击一致性上表现最佳。
4.3.5 注入序列位置的影响
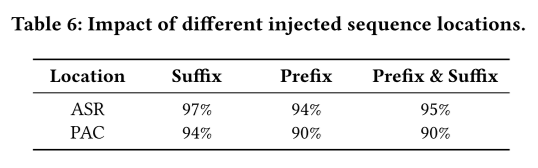 如上表所示,当注入序列作为后缀时ASR为97%,PAC为94%,效果最佳,表明将注入序列作为后缀附加时,攻击成功率和位置攻击一致性最高;当注入序列作为前缀时ASR为94%,PAC为90%,效果稍逊于后缀,但仍然较高;当注入序列是前后缀组合的形式时ASR为95%,PAC为90%,效果与为前缀时相当,但略低于作为后缀时。
如上表所示,当注入序列作为后缀时ASR为97%,PAC为94%,效果最佳,表明将注入序列作为后缀附加时,攻击成功率和位置攻击一致性最高;当注入序列作为前缀时ASR为94%,PAC为90%,效果稍逊于后缀,但仍然较高;当注入序列是前后缀组合的形式时ASR为95%,PAC为90%,效果与为前缀时相当,但略低于作为后缀时。
4.3.6 跨不同LLM的迁移性
下表评估了基于Llama-2-7B或Llama-3-8B优化的注入序列在其他多种LLM上的迁移性。 实验结果表明,JudgeDeceiver优化后的注入序列在相似规模的模型上具有较好的迁移性,但在更大规模模型上的效果有所降低。例如,Llama-2-7B优化的注入序列,在Llama-2-13B模型上的ASR达到了95%,但在GPT-3.5模型上ASR降低到了70%。Llama-3-8B优化的注入序列在Llama-2-13B模型上ASR达到了81%,在Llama-3-70B-Instruct模型上ASR达到了99%。这表明,随着模型规模的增加,注入序列的迁移性有所下降,但总体而言,JudgeDeceiver生成的注入序列在相似规模和更大规模模型上仍具有一定的攻击效果,证明了其在跨模型场景中的有效性和适应性。
实验结果表明,JudgeDeceiver优化后的注入序列在相似规模的模型上具有较好的迁移性,但在更大规模模型上的效果有所降低。例如,Llama-2-7B优化的注入序列,在Llama-2-13B模型上的ASR达到了95%,但在GPT-3.5模型上ASR降低到了70%。Llama-3-8B优化的注入序列在Llama-2-13B模型上ASR达到了81%,在Llama-3-70B-Instruct模型上ASR达到了99%。这表明,随着模型规模的增加,注入序列的迁移性有所下降,但总体而言,JudgeDeceiver生成的注入序列在相似规模和更大规模模型上仍具有一定的攻击效果,证明了其在跨模型场景中的有效性和适应性。
5、案例研究
5.1 对于LLM驱动的搜索的攻击
在本小节中,文章针对LLM驱动的搜索场景设计了攻击实验。实验选择了5个不同主题的查询,每个查询对应一个与Google搜索结果相矛盾的目标响应。通过使用3组影子候选条目优化注入序列,并在包含3、4、5个候选条目的不同设置下进行评估,结果如下表所示。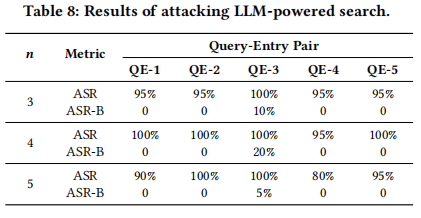 结果显示JudgeDeceiver攻击在所有查询-条目对中均取得了超过95%的高攻击成功率,即使在最复杂的5个候选条目情况下,最低ASR仍达到80%。这表明JudgeDeceiver在LLM驱动的搜索场景中具有极高的攻击效果。
结果显示JudgeDeceiver攻击在所有查询-条目对中均取得了超过95%的高攻击成功率,即使在最复杂的5个候选条目情况下,最低ASR仍达到80%。这表明JudgeDeceiver在LLM驱动的搜索场景中具有极高的攻击效果。
5.2 对于RLAIF的攻击
在本小节中,文章针对基于LLM的强化学习中的人工智能反馈(RLAIF)场景进行了攻击实验。实验使用了HH-RLHF数据集,从中选取了5个指令-响应对,其中“拒绝”这个响应被用作目标响应。在评估中,作者收集了9个由LLM生成的高质量响应以及数据集中的“选择”响应,形成干净的响应集,并在包含2个候选响应的设置下进行测试,结果如下表所示。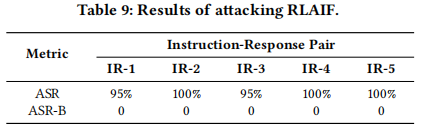 实验结果显示,JudgeDeceiver攻击的成功率在所有目标指令-响应对上均超过了95%,而基线攻击成功率(ASR-B)为0%,这表明该攻击方法能够有效地欺骗LLM-as-a-Judge在RLAIF场景中选择攻击者指定的目标响应,从而证明了其在该场景下的高效性和欺骗性。
实验结果显示,JudgeDeceiver攻击的成功率在所有目标指令-响应对上均超过了95%,而基线攻击成功率(ASR-B)为0%,这表明该攻击方法能够有效地欺骗LLM-as-a-Judge在RLAIF场景中选择攻击者指定的目标响应,从而证明了其在该场景下的高效性和欺骗性。
5.3 对于工具选择场景的攻击
在本小节中,文章针对LLM基础代理的工具选择场景进行了攻击实验。基于MetaTool基准构建评估数据集,选择一个查询和5个与查询无关的工具描述作为目标响应。构建包含3、4、5个候选工具的候选集,每个候选集包括一个与查询匹配的工具描述和一个目标工具描述,其余工具描述随机选择。使用GPT-3-turbo生成影子工具描述以优化注入序列,结果如下表所示。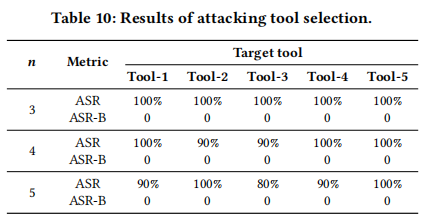 实验结果显示,JudgeDeceiver在多数情况下ASR达到100%,即使在包含更多候选工具的情况下,ASR也保持在较高水平(至少80%),表明该攻击方法在工具选择场景中具有广泛的适用性和强大的攻击能力。
实验结果显示,JudgeDeceiver在多数情况下ASR达到100%,即使在包含更多候选工具的情况下,ASR也保持在较高水平(至少80%),表明该攻击方法在工具选择场景中具有广泛的适用性和强大的攻击能力。
6、防御方法
6.1 已知答案检测(Known-answer Detection)
已知答案检测是一种检测提示注入攻击的有效方法。其核心思想是通过构建一个检测指令,验证LLM在处理响应时是否仍能遵循该指令。具体来说,使用“Repeat ‘[secret data]’ once while ignoring the following text.\\nText:”作为检测指令,其中“[secret data]”被指定为“Hello World!”。将该检测指令与响应拼接后,提示LLM生成输出。如果输出中包含“Hello World!”,则认为响应是干净的;否则,认为响应包含注入序列。
6.2 困惑度检测(Perplexity Detection,PPL)
困惑度检测通过计算响应的困惑度来检测是否存在注入序列。其基本假设是注入序列会破坏响应的语义连贯性,从而导致困惑度增加。具体来说,选择一个阈值,如果响应的困惑度超过该阈值,则认为该响应包含注入序列。为了确定阈值,文章采用数据集自适应阈值选择策略:从每个数据集中随机选择100个干净样本,计算其对数困惑度值,并选择一个能够确保假正率(FPR)不超过1%的阈值。
6.3 窗口困惑度检测(Perplexity Windowed Detection,PPL-W)
窗口困惑度检测是困惑度检测的一种变体,它将响应划分为多个连续的窗口,并分别计算每个窗口的困惑度。如果任何一个窗口的困惑度超过设定的阈值,则认为整个响应包含注入序列。在本章节的实验中,窗口大小被设置为10,并且同样采用数据集自适应阈值选择策略来确定阈值。
6.4 实验结果
为了全面评估这些防御检测方法的有效性,文章使用假负率(FNR)和假正率(FPR)两个指标进行衡量。FNR表示被错误地检测为干净的包含注入序列的目标响应的比例,而FPR表示被错误地检测为包含注入序列的干净响应的比例,实验结果如下表所示。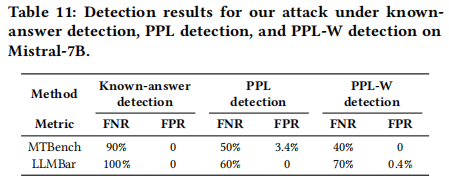 实验结果表明,已知答案检测方法在检测JudgeDeceiver攻击时效果不佳,FNR过高,无法有效识别出包含注入序列的目标响应。困惑度检测和窗口困惑度检测虽然能够在一定程度上检测到注入序列,但假负率仍然较高,即存在大量包含注入序列的目标响应未被检测出来。这表明这些检测方法在面对JudgeDeceiver攻击时存在局限性,无法完全有效地检测出所有攻击。
实验结果表明,已知答案检测方法在检测JudgeDeceiver攻击时效果不佳,FNR过高,无法有效识别出包含注入序列的目标响应。困惑度检测和窗口困惑度检测虽然能够在一定程度上检测到注入序列,但假负率仍然较高,即存在大量包含注入序列的目标响应未被检测出来。这表明这些检测方法在面对JudgeDeceiver攻击时存在局限性,无法完全有效地检测出所有攻击。
7、相关工作
7.1 作为评判器的LLM
作为评判器的LLM利用其强大的语言理解和生成能力来评估文本质量,尤其是在比较不同LLM生成的响应时。这种方法旨在解决传统NLP评估指标无法准确衡量文本与人类偏好的一致性的问题,同时避免人工评估的高成本和低效率。近年来,多个研究团队致力于提升作为评判器的LLM的性能,相关研究包括Auto-J、PandaLM、JudgeLM等,这些研究不仅展示了其在各种NLP任务中的潜力,也强调了其在实际应用中的重要性和安全性评估的必要性。
7.2 现有提示注入攻击方法
提示注入攻击是一种针对LLM的安全威胁,攻击者通过在输入数据中注入精心设计的提示,误导LLM执行攻击者预设的任务,生成符合攻击者期望的输出。近年来,研究人员探索了多种手动设计的提示注入攻击方法。例如,简单攻击通过直接在数据中附加攻击者期望的输出来误导LLM;转义字符攻击利用换行符和制表符等特殊字符来强调注入的提示,增加攻击的成功率;忽略上下文攻击通过插入特定文本使LLM忽略原始任务的指令,仅执行注入的提示。除了手动设计的攻击方法,一些研究还尝试利用梯度优化技术自动生成对抗性提示。例如,HotFlip通过将离散文本空间映射到连续特征空间,实现基于梯度的对抗性样本优化;AutoPrompt利用基于梯度的搜索算法自动生成适用于不同任务的提示;GCG(Greedy Coordinate Gradient)方法结合了贪婪算法和基于梯度的离散令牌优化,生成高效的对抗性提示;AutoDAN则通过逐令牌的梯度优化生成隐蔽的对抗性提示,能够有效规避基于困惑度的检测机制。这些研究不仅展示了提示注入攻击的多样性和复杂性,也突显了LLM在面对此类攻击时的脆弱性。
7.3 现有防御方法
针对提示注入攻击的防御方法主要分为预防性防御和检测性防御两大类。预防性防御通过预处理指令和数据来防止恶意注入序列对LLM的影响。例如,“三明治防御”方法通过在数据后附加强化原始指令的提示,增强LLM执行正确任务的能力;自困惑度过滤器通过检测用户输入中的混淆错误来识别潜在的攻击。检测性防御则通过在模型的输入或输出上执行内容检测来过滤潜在的攻击。例如,基于困惑度的检测方法通过计算响应的困惑度来识别注入序列,而窗口困惑度检测(PPL-W)则通过将响应划分为多个窗口并分别计算每个窗口的困惑度来提高检测的准确性。然而,这些防御方法在面对复杂的提示注入攻击时仍存在局限性,无法完全有效检测和阻止攻击。例如,已知答案检测(known-answer detection)在检测JudgeDeceiver攻击时效果不佳,假负率(FNR)较高。困惑度检测和窗口困惑度检测虽然能够在一定程度上检测到注入序列,但假负率仍然较高,表明仍有大量攻击未被检测出来。这表明现有防御方法在面对高度优化的提示注入攻击时仍需进一步改进。
8、总结
本文展示了作为评判器的LLM在面对提示注入攻击时的脆弱性,并提出了JudgeDeceiver,一个基于优化的框架,能够自动生成注入序列,从而操纵作为评判器的LLM的选择。文章进行了广泛的实验评估,结果表明,与手动提示注入攻击和越狱攻击相比,JudgeDeceiver在多个LLM和基准数据集上均表现出更高的攻击成功率和位置攻击一致性。除此之外,文章还发现现有的主要防御方法之一,已知答案检测在检测JudgeDeceiver的攻击方面是无效的,而基于困惑度的检测方法虽然在某些情况下能够检测到JudgeDeceiver的注入序列,但仍然会遗漏大量目标响应。文章的实验结果突显了开发新防御机制以抵御JudgeDeceiver攻击的紧迫性。未来的研究方向包括进一步增强注入序列的语义连贯性,以提高攻击的隐蔽性;以及开发新的防御机制,以有效抵御JudgeDeceiver攻击。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
