基本信息
原文标题:Large Language Models Versus Static Code Analysis Tools: A Systematic Benchmark for Vulnerability Detection
原文作者:Damian Gnieciak, Tomasz Szandala
作者单位:Faculty of Information and Communication Technology, Wroclaw University of Science and Technology, Wroclaw, Poland
关键词:Large Language Models, Static Analysis, Vulnerability Detection, Software Quality, CI/CD, Software Engineering
原文链接:https://arxiv.org/abs/2508.04448
开源代码:暂无
论文要点
论文简介:本文面向现代软件开发对自动化漏洞检测工具的强烈需求,系统性比较了三款主流静态代码分析工具(SonarQube、CodeQL、Snyk Code)与三种代表性大语言模型(GPT-4.1、Mistral Large、DeepSeek V3)在实际C#项目前提下的脆弱性检测能力。作者构建包含10个真实世界C#项目、共计63个涵盖SQL注入、硬编码密钥、过期依赖等常见类型漏洞的数据集,以统一评测协议和SARIF结果格式,对比了各工具/模型在精度(precision)、召回率(recall)、F1分数、分析延迟和开发者复核负担等方面的表现。
实验发现,大语言模型在F1分数、召回率等指标上明显优于静态分析工具,但其误报率更高、漏洞定位不精确等问题亦较突出。因此,作者建议以混合流水线方式将LLM和传统工具结合,用于不同阶段的安全保障。论文开源了评测基准和自动化分析工具(ProjectAnalyzer),以推动后续可复现性研究。
研究目的:该研究聚焦于当前软件安全检测技术的两大代表——传统静态代码分析工具与新兴大语言模型——在实际漏洞检测任务中的能力极限、适用场景与具体优劣。鉴于静态工具存在规则覆盖有限、误报等问题,LLM虽表现出对代码语义和上下文的强大理解力,但其稳定性与可控性尚存疑问。基于此,作者旨在通过统一的数据集、评测协议和结果报告,开展高对比性、可量化的实证实验,厘清LLM与静态分析工具各自长短板,总结混合使用策略,并为业界与学术界相关研究提供公开的评测基准和工具链。
研究贡献:
1. 构建了涵盖10个实际C#项目、63个多类别真实漏洞的高质量数据集,并开源统一评测协议与项目分析器工具ProjectAnalyzer,支持两类方法的结果标准化输出。
2. 在同一测试集下,首次系统对比了SonarQube、CodeQL、Snyk Code和GPT-4.1、Mistral Large、DeepSeek V3等6种方法在精度、召回、F1分数、分析时延等方面的性能,并揭示LLM在召回率上对传统工具的显著超越及误报方面的挑战。
3. 通过定性分析模型输出和工具报告,归纳总结了两大类方法各自在数据流跨文件推理、漏洞类型映射等方面的强弱势。
4. 结合实验结果,为实践者与科研人员就工具选择、提示工程(prompt engineering)和未来基准方法提出了明确建议。
引言
当前,软件开发的复杂度和业务敏捷性持续提升,导致程序漏洞与安全隐患管理的难度日益巨大。静态应用安全测试(SAST)工具,如SonarQube、CodeQL和SnykCode,已成为DevOps和CI/CD流水线中抵御漏洞扩散的重要防线,被全球数百万开发者和数十万组织广泛信赖。这类工具能在代码尚未投入生产前,基于模式匹配、数据流和控制流分析及时捕捉安全缺陷,为提升代码质量和减少系统性风险起到关键作用。然而,近年的实证研究指出,即便是最先进的静态分析器,在真实开发活动中往往只能覆盖约半数的引入漏洞,与此同时大量误报(false positives)和规则覆盖局限,成为开发者实际部署时的重要障碍。
大语言模型(LLM)崛起后,为源代码智能分析带来全新机遇。越来越多工程团队尝试将LLM引入软件质量保障环节,相关学术探索发现,经数亿级代码和文本训练的模型(如GPT-4.1等),不仅在典型语法和API层面具备强劲的理解和判断能力,凭借对上下文的整体感知甚至能识别跨文件的数据流隐患。在同一F分数基线下,LLM在识别复杂业务逻辑漏洞方面显示出对静态规则方法的挑战。
尽管如此,LLM的“类理解”能力本质上来自于生成式建模,这也带来了前所未有的失效模式,如幻觉生成(hallucination)和定位误差。业界已有报道指出,LLM会凭空生成不存在的软件包名,甚至为攻击者制造供应链攻击渠道,暴露出全新的安全隐患。因此,仅凭偶发实验或厂商宣称无法全面评估LLM与静态工具的实际效果和局限,急需统一基准和系统性、可复现的对比研究。
在此背景下,本文首次在涵盖多类真实漏洞和多种C#开源项目的标准测试集上,系统性比较三类商业化静态分析工具与三款主流大语言模型的漏洞检测表现,覆盖从传统精度、召回再到开发者体验和模型输出解释性等多维度指标,并开源全部基准和自动分析工具,为业界和学界推动下一代自动化代码安全分析奠定基础。
相关工作与背景
静态代码分析技术历经数十年的演进,如今已成为现代软件开发流程不可或缺的一环。在工业界,SAST工具基于源代码静态解析检测各类潜在缺陷与安全漏洞,多项研究表明其可显著降低后期修复成本和生产事故风险。典型的静态分析工作流程主要通过控制流、数据流分析和模式识别,对常见如命名规范、代码风格、并发管理、异常处理、性能优化、安全隐患、可维护性等多维度指标进行严格把控。学界亦证实,静态分析工具在教育实践中的价值突出,持续运用能帮助初学者提升代码质量和安全防范意识。
近年随着人工智能技术在开发生命周期持续渗透,静态分析的边界和应用场景也在发生变化。静态分析结果多以标准化如SARIF格式输出,便于在企业大规模CI/CD流水线集成和跨工具间的结果互操作。尽管软件体系不断完善,传统静态分析工具仍面临两大核心瓶颈:一是在规则/模式定义上的滞后与封闭性,导致新型或复杂语义漏洞难以被及时发现;二是对代码全局和上下文关系的理解能力有限,面对跨文件、跨系统的数据流安全问题时常显被动。
大语言模型的引入尤其改变了这一局面。大量研究表明,LLM借助其强大的学习能力和语义推理,可以在几乎无需固定规则的情况下,仅通过对代码上下文的“理解”发现隐晦缺陷。相较于规则型分析器,LLM对未知模式、复杂业务逻辑的适配性更强。相关比较工作已初步证实新一代像GPT-4、Mistral Large等模型,在诸如SQL注入、命令注入、硬编码密钥检测、依赖项过期等问题上具备接近甚至超越传统工具的召回表现,为漏洞检测策略转型提供了理论依据。然而,LLM生成式属性也带来了定位误差和幻觉生成等新型风险,亟需系统评测与定量分析。
本文在既有探索基础上,将对静态工具与LLM在统一测试集和评测协议下展开全面系统的跨层对比,并首次开源兼容SARIF标准的评测工具链,为 AI 驱动安全分析的落地提供基础设施和评测规范。
方法与实验设计
在研究方法上,本文选取了代表性极强的三种静态分析工具(SonarQube、CodeQL 与 SnykCode)与三款当下最具影响力的大语言模型(GPT-4.1、Mistral Large、DeepSeek V3),分别涵盖业界规则集、定制化查询与 AI/ML 混合分析,以及不同架构、窗口及商业化平台的 LLM。所有工具均基于企业级授权和数据合规政策,确保真实企业研发场景的一致性。
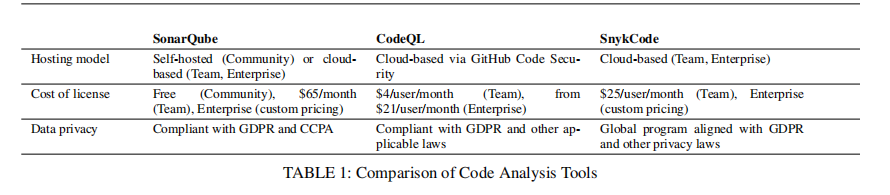
数据集建设方面,作者精选了10个分属不同业务类型的真实C#开源项目,平均每个项目3-10个源文件、3500-5500字符,预先人工嵌入类型丰富(SQL注入、跨站脚本、命令注入、硬编码、弱加密、过期依赖等)的63个已知漏洞,最大程度贴合现实代码库分布和真实开发习惯。
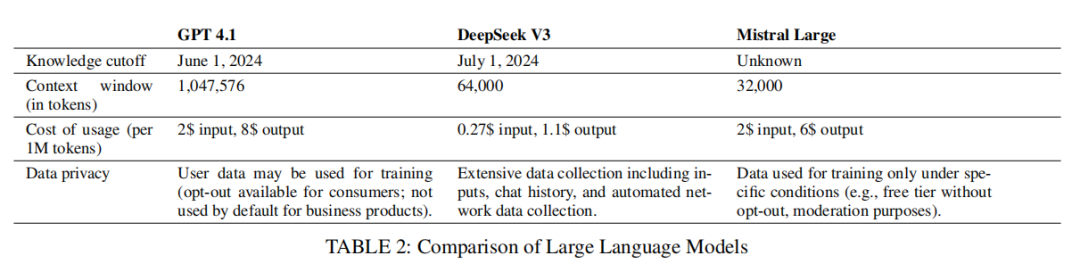
为保证评测流程的规范化和全自动可复现,作者独立开发了ProjectAnalyzer工具,可将不同模型和工具(包括LLM)获取的分析报告转换为通用SARIF格式(JSON标准),实现检测结果的结构化对比。LLM分析过程中,全部项目代码被自动拼接为统一系统消息、送入GitHub Models平台(对所有模型开放),并按统一格式返回检测报告,从而实现跨方法的结果对应与评测。
实验评估维度包括但不限于:
检测性能指标:总体检测数、真阳性数量、精度(precision)、召回率(recall)、F1分数,所有评价均基于人工复核确认。
误报/漏报分析:统计每工具/模型的假阳性和假阴性,揭示其风险区间。
运行时延:每一次完整分析完成的耗时,三位小数精度,量化开发实际集成影响。
开发者复核工作量:从实际使用角度评估误报带来的人工成本。
SARIF 结果定位精度:尤其关注LLM在文件、行、列定位准确性的表现。
所有实验均在一致的软硬件环境下执行,避免系统性偏差,并严格采用工具/模型默认配置,确保结果的现实适用性和高可复现性。
实验结果与分析
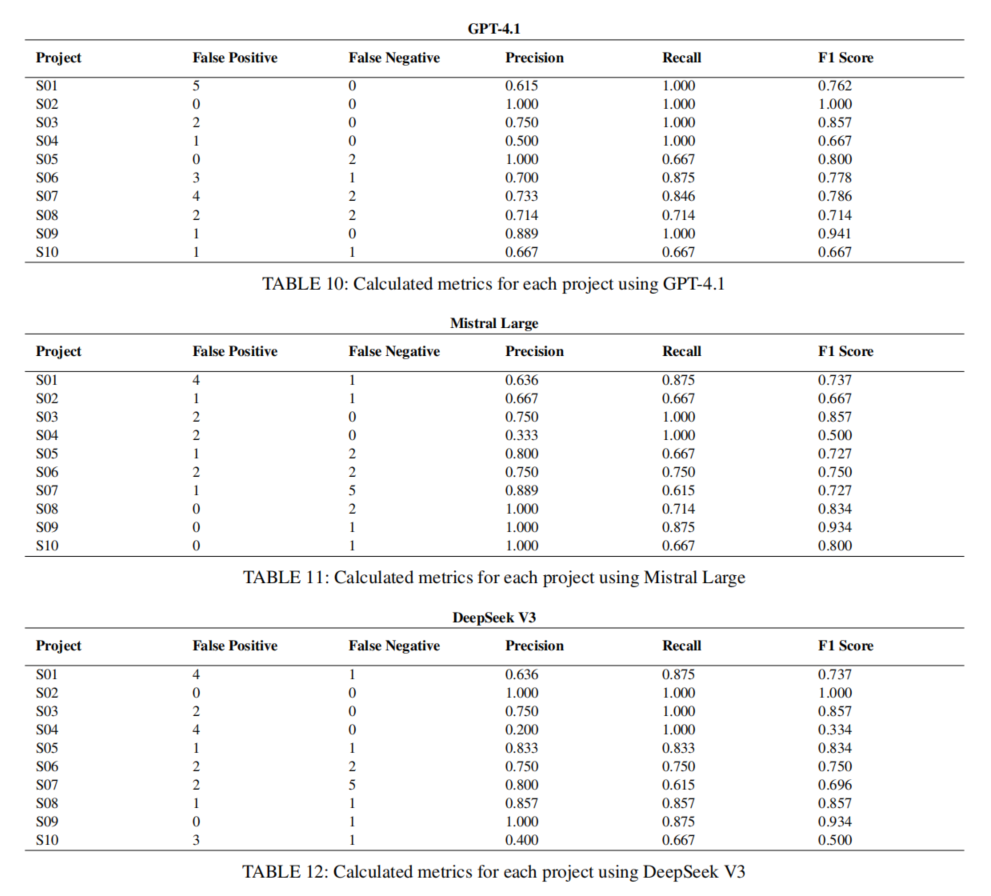
实验结果显示,大语言模型在多项核心指标上全面超越静态分析工具。首先,从传统的F1分数来看,GPT-4.1、Mistral Large、DeepSeek V3分别获得0.797、0.753和0.750的均值,远高于SonarQube(0.260)、CodeQL(0.386)和SnykCode(0.546),凸显出LLM在整体检测准确性和衡量综合表现上的巨大优势。
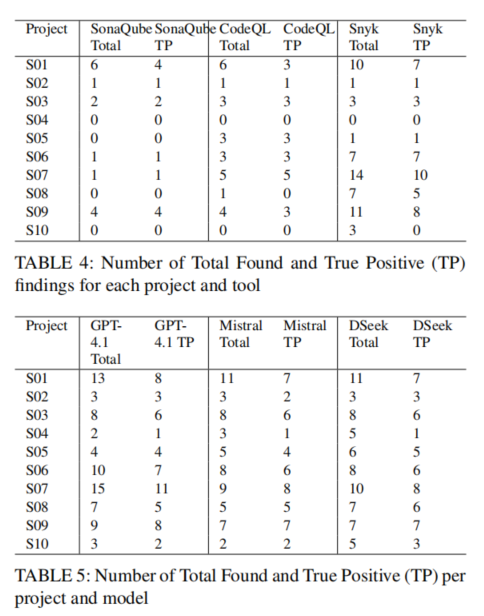
依据精度与召回细分,静态工具尤其是SonarQube和CodeQL,在精度(precision)表现相对平稳,假阳性(误报)较低,但召回率显著不足,往往只能覆盖已知缺陷中的一小部分。SnykCode因采用ML混合策略,在召回率和精度之间实现部分平衡,F1分数更高。LLM模型在召回率(平均0.847~0.877)均大幅领先传统工具,能够更全面发现实际潜在漏洞,尤其展现出对复杂数据流和跨文件关系的推理力。
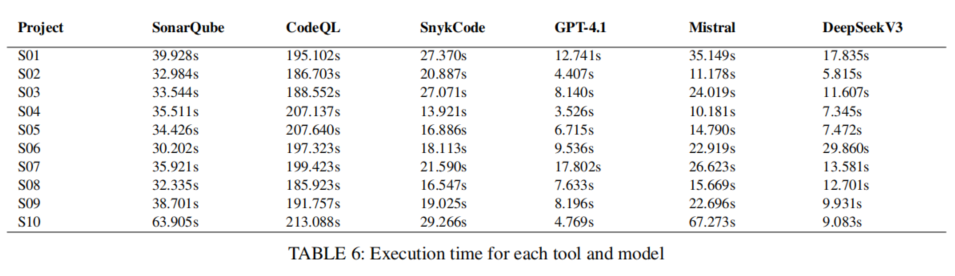
然而,这一优势伴随着误报率的明显上升。以DeepSeek V3为例,其误报比例达到所有方法之最,意味着实际开发者需耗费更高的人工精力剥离无效告警。LLM的误报不仅表现在普通模式遗漏上,更突出于“幻觉”类别分布,例如误判依赖项版本过旧(实为最新),或定位报告的指针精准度普遍下降。所有LLM均难以精确还原文件行列级定位,影响其在高要求安全审计场景下的独立部署适用性。
分析耗时方面,CodeQL因重型查询和深度分析导致执行时延显著高于其他工具(平均超3分钟),而LLM和SnykCode则在10秒级别,具备更好迭代效率。开发者复核成本方面,误报高的LLM和SnykCode需更多人工介入,SonarQube等规则工具则在最小化冗余告警方面具有优势。
值得指出,SnykCode在混合策略辅助下,F1分数和检测能力接近部分LLM,成为传统工具与AI方法融合趋势下的典型案例。作者结合各项目在不同指标下的离群点,深入剖析了各方法对不同漏洞类型和项目规模的适配能力。
讨论与未来展望
实验发现揭示了大语言模型与静态分析工具各自的独特优势和可预见的短板。LLM在综合召回和F1性能上已具备实用替代的潜力,尤其在需要跨文件深度推理、多样漏洞发现和提升安全检测覆盖率的场景下具备突出价值。LLM对代码全局语境、开发习惯和业务逻辑的整体性理解,使其可捕捉到依赖繁杂、规则难以明确定义的缺陷。

然而,LLM生成机制不可避免地带来幻觉错误、定位偏差等问题。作者指出,现有LLM在SARIF格式要求下始终无法回溯到精确行列位置,且在部分包管理、版本识别等情境下出现无据可依的“虚构告警”。传统工具虽然召回有限,但凭借精确定义规则和稳定输出,在安全性要求极高的生产审计、法规遵循、关键基础设施等领域仍具不可替代性。
针对上述差异,作者提出混合流水线的应用建议:在软件开发早期,用大语言模型实现宽幅、上下文驱动的预警与初筛,提高问题发现率;在高安全性阶段,采用静态分析器对关键漏洞做定向核查和验证。未来值得持续探索的方向包括:提示工程优化(Prompt Engineering)以进一步提升LLM实际漏洞识别正向能力,构建LLM与传统工具协同的结构化工作流,以及针对幻觉、定位失效等问题的机理分析与防护机制研究。
此外,开源的ProjectAnalyzer与统一测试基准,将为后续更多模型架构和工具方案的系统评测提供基础设施,推动可复现、数据驱动的软件安全研究新范式。
论文结论
经选定的静态代码分析工具与大语言模型对所有项目完成分析后,可得出如下结论:大语言模型在代码漏洞检测任务中表现优异,这得益于其具备分析代码完整上下文的能力,而传统工具则依赖预定义模式开展检测工作。此外,漏洞检测能力的提升伴随着误报概率的增加。将大语言模型应用于代码分析时,另一关键问题在于其无法提供所发现漏洞的精确位置;在开发更为复杂的代码分析系统时,若采用 SARIF 格式却无法提供位置信息,可能会对大语言模型的应用形成限制。
综上而言,在对可靠性与精确性有较高要求的场景中 —— 例如针对必须保障可靠性且应用于关键领域的系统开展必要的软件审计工作时,建议采用经典的静态代码分析工具,此类场景通常需要定义特定的检测模式。基于大语言模型的解决方案虽灵敏度更高,但会产生较多误报结果,其适用于开发过程,可助力系统开发人员及时察觉潜在缺陷。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
