
原文标题:Lost at C: A User Study on the Security Implications of Large Language Model Code Assistants
原文作者:Gustavo Sandoval, Hammond Pearce, Teo Nys, Ramesh Karri, Siddharth Garg, Brendan Dolan-Gavitt
原文链接:https://www.usenix.org/conference/usenixsecurity23/presentation/sandoval
发表会议:USENIX
笔记作者:牟浩天@安全学术圈
主编:黄诚@安全学术圈
编辑:张贝宁@安全学术圈
1、引言
大语言模型(LLMs)可用于代码补全、错误修复和摘要等功能,这对开发者来说是非常有用的功能,因此,最近的产品正在将LLMs商业化应用于代码领域。然而,有研究指出LLM补全的代码可能包含关键的安全漏洞。这表明,尽管LLM提高了开发者的生产力,但由于安全方面的担忧,应谨慎使用基于LLM的代码助手。
文章主要围绕三个研究问题调查了LLM生产代码的安全影响:
• RQ1:确认本研究的动机:AI代码助手能否帮助新手用户编写更好的功能性代码?
• RQ2:在功能性优势的基础上,用户使用AI辅助编写的代码相对于没有辅助情况下编写的代码的安全漏洞发生率是否可以接受?
• RQ3:被AI辅助的用户是如何与会生成易受攻击的代码的建议相互影响的——即在LLM辅助系统中漏洞是从哪里来的?
2、背景与相关工作
2.1 AI代码助手提升生产力
学术界和商业界的AI代码助手工具正在迅速发展,例如OpenAI 的 Codex、 AI21 的 Jurassic J1、Salesforce的CodeGen和CodeBERT。这些代码助手通过代码补全、修复和总结等功能提供便利,旨在提高开发者生产力。有许多相关工作与研究结果表明,AI代码助手的确能帮助程序员提升代码的编写效率。
2.2 从提示到建议:LLM如何编写代码
LLM在编写代码时,依赖于输入序列来预测下一个最可能出现的文本序列。这种机制类似于自动补全功能,LLM通过分析训练数据中的文本频率,构建概率序列以生成代码建议。LLM的自回归特性使其能够将预测结果反馈给自己,并进行后续的序列预测,从而生成更长的代码片段。这种特性使得LLM不仅能生成单个代码行,还能生成整个代码块,极大地提高了代码生成的效率和连贯性。
2.3 LLM 生成代码的安全问题
安全性问题是LLM生成代码时的重要关注点,前一小节中讨论的支撑 LLM 建议生成的的机制已被证明在安全角度上会导致问题。主要原因有两个:一方面,LLM可能在训练过程中学习到了不安全或存在漏洞的代码模式,从而在生成代码时重复这些错误;另一方面,即使某些代码片段在单独使用时是安全的,但在特定的执行顺序或与其他代码片段结合时,可能会引发安全漏洞。
2.4 代码的安全性评估
代码安全评估是确保软件安全性的关键环节,常见的评估方法包括静态分析工具、运行时分析工具和手动分析。静态分析工具在编译时检测代码中的潜在漏洞,尝试识别不安全的设计模式。运行时分析工具则通过调试器和检测器等工具,在程序运行时发现错误,并提供详细的错误位置和原因信息。手动分析虽然耗时,但仍然是软件设计各个阶段不可或缺的手段,尤其在自动化工具难以检测到某些特定类型的漏洞时,手动代码审查显得尤为重要。
3、安全为导向的用户级研究设计
3.1 概述
本研究旨在评估LLM辅助对程序员所编写代码安全性的影响。研究随机分配参与者至控制组(无LLM辅助)和辅助组(有LLM辅助),要求他们使用C语言实现单链表“购物清单”,通过分析代码功能性和安全性来比较两组表现,以确定LLM是否增加安全风险。
3.2 参与者招募
研究从大学招募计算机科学及相关专业学生,涵盖本科生和研究生。共105人报名,随机分配到控制组和辅助组,最终58人完成代码。参与者具备不同编程经验,使用自己的计算机和资源,并被告知在一般情况下可以使用互联网帮助,但他们不应向同学或其他人请求代码编写协助。在实验室环境中进行更结构化的研究虽然能提供更多控制权,但会牺牲现实性,而LLM代码助手是一种新颖的工具,在更多现实条件下观察其使用可能更有价值。
3.3 编程任务
参与者需要实现一个用C语言编写的单链表“购物清单”。选择C语言是因为其在内存管理方面易出错的特性,如空指针引用和缓冲区溢出,且C语言的默认编译工具链对这些问题的检查不足。
任务要求参与者实现11个函数,涵盖创建新链表、在指定位置添加、更新、删除和交换商品项等基本操作以及处理字符串、高级遍历、保存和加载购物清单等复杂功能,每个函数都有明确的API规范,参与者可以按任意顺序实现这些函数,并可随时修改之前的答案。
如下图所示,研究向参与者们提供了头文件和README形式的文档,以及教学视频。支持文档包括一个Makefile以及12个基本的功能测试,以便参与者可以自动测试他们的代码。

为了增加漏洞出现的概率,任务设计采用了一些不寻常的设计选择,如使用基于位置的索引而非指针操作、一基索引而非零基索引以及通过函数参数和指针进行I/O操作。这些设计增加了链表遍历的复杂性,从而提高了出现无意漏洞的可能性。
3.4 用于代码建议的Codex助手
辅助组使用基于GitHub Copilot的“Codex助手”,集成于Visual Studio Code。用户输入代码后暂停,助手向OpenAI Codex API发送数据,以灰色文本形式提供代码建议(如下图所示),用户可接受或拒绝。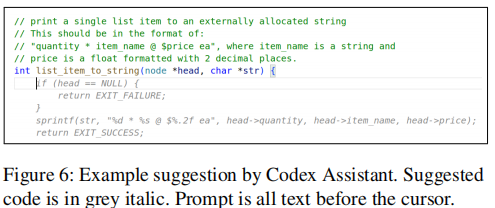
研究中的参数设置为max_tokens=64、temperature=0.6、top_p=1.0,以平衡代码生成建议的质量和多样性。
3.5 ‘Autopilot’ - 自动完成任务
为了全面评估LLM辅助编程的影响,研究团队创建了一个名为“Autopilot”的组别,完全由Codex LLM生成代码。具体来说,团队使用三种不同的OpenAI代码生成模型生成了30个解决方案。这一过程模拟了一个完全依赖AI助手生成代码的开发者可能的行为模式,即不进行深入的检查和修改。 此外,如图所示,研究团队还对生成的代码进行了部分干预,在文件中添加注释,列出节点结构的成员变量。这一步骤是必要的,因为LLM无法直接访问头文件中定义的结构体信息。通过这种方式,研究团队能够模拟一个几乎不干预LLM生成代码的开发者的行为模式,从而为控制组和辅助组提供一个基准进行比较。这种方法帮助研究团队更准确地衡量LLM生成代码的质量和安全性,以及它对开发者编码过程的影响。
此外,如图所示,研究团队还对生成的代码进行了部分干预,在文件中添加注释,列出节点结构的成员变量。这一步骤是必要的,因为LLM无法直接访问头文件中定义的结构体信息。通过这种方式,研究团队能够模拟一个几乎不干预LLM生成代码的开发者的行为模式,从而为控制组和辅助组提供一个基准进行比较。这种方法帮助研究团队更准确地衡量LLM生成代码的质量和安全性,以及它对开发者编码过程的影响。
3.6 实验基础设施
研究基于Anubis软件提供的云IDE环境,自动加载项目并根据组别提供代码建议。IDE记录用户输入、与LLM的交互及代码快照,每60秒更新一次。用户完成后上传代码并填写统计问卷,研究过程中还收集了开发过程数据以分析行为模式。
3.7 统计检验
文章使用标准的统计假设检验来分析结果。研究的目的是检验LLM代码助手是否在不加剧安全问题的前提下提高了代码质量。所以文章使用和比较假设检验和非劣效性检验分析结果。比较检验用于确定辅助组在功能实现上是否优于控制组,非劣效性检验用于评估辅助组的安全性是否在控制组可接受范围内。非劣效性测试设10%为容忍阈值,以判断LLM辅助是否显著增加漏洞。
4、研究结果与分析
4.1 用户群体统计
共有58名参与者完成了可供分析的代码。作为研究的一部分,参与者完成了一份简短的统计问卷,统计结果如下表所示。
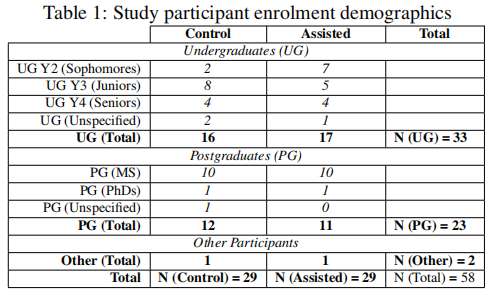
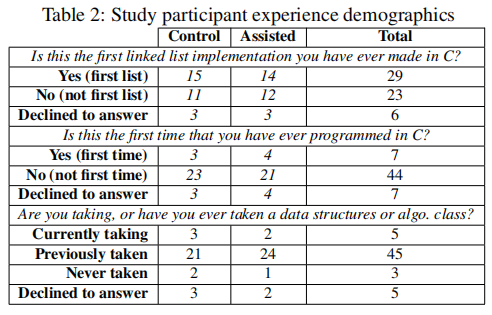
结果显示,两组在学历背景和编程经验知识方面具有可比性,这为研究结果的可靠性提供了基础。
4.2 RQ1 - 功能性
文章使用单元测试评估代码的功能。除了提供给参与者的11个基础测试外,还编写了43个扩展测试以测试边缘情况。下图展示了每组实现的函数平均百分比,无论它们是否编译成功;这些函数中编译成功的平均百分比;每组通过11个基础测试的平均百分比和通过43个扩展测试的平均百分比。
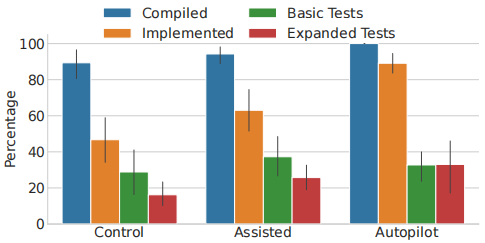
从上图的结果中可以观察到辅助组和对照组之间存在差异,辅助组相较于对照组有小幅度的优势。有趣的是,自动生成组在基础测试中稍逊于辅助组,但在扩展测试中略胜一筹。换句话说,AI代码助手确实帮助用户编写出功能更优的代码。
4.3 RQ2 - 安全性分析
尽管有许多不同的工具可用于查找C源代码中的安全相关缺陷,但文章发现没有一个工具适合本研究的使用场景。因此,文章选择手动审核58份用户的提交内容以及5份完全由LLM生成的代码。
4.3.1 漏洞数据编码
研究团队对58名参与者提交的代码进行了手动审计,一次处理一个函数,三名合著者共同阅读并标注安全相关的漏洞。审计过程参考编译日志、测试套件和词法分析,识别出67个独特的漏洞类别。审计发现,参与者代码中存在多个CWE,如CWE-476(空指针解引用)、CWE-758(依赖未定义行为)和CWE-787(越界写入)。
4.3.2 度量方法
在安全性分析中,文章采用了CWE/LoC(每行代码的常见弱点枚举数量)作为主要度量指标,以评估代码的安全性。由于大多数参与者仅为其被要求实现的11个函数的一个子集提交了有效的实现,因此文章采用两种有效性概念:(1)函数可以编译;(2)它可以编译并通过单元测试。文章将在在这些函数上计算CWEs/LoC。
CWEs/LoC的计算公式如下,Eij表示用户i提交的函数j中的CWEs数量,Vij ∈{0,1}是一个二元变量,只有当用户i为函数j提交了有效代码时才为1,Lij表示用户i为函数j编写的有效行数。
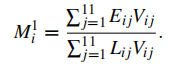
由于文章的研究方法允许独立测试每个函数,因此可以还可以通过下面的公式计算每个函数的CWE发生率。其中NAssist和NControl分别为Codex辅助组和对照组的用户数量。
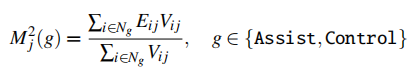
同时,研究还关注Mitre报告的前25个最危险的CWE,计算每行代码的严重漏洞数量CWE/LoC。这种方法不仅提供了对代码整体安全性的评估,还突出了关键的安全问题。通过比较辅助组和控制组在这些指标上的表现,研究团队能够评估LLM辅助是否对代码安全性产生显著影响。
4.3.3 主要结果—CWEs/LoC
下图展示了三个组在编译函数和通过单元测试的函数上的常见和严重CWEs/LoC的箱线图。
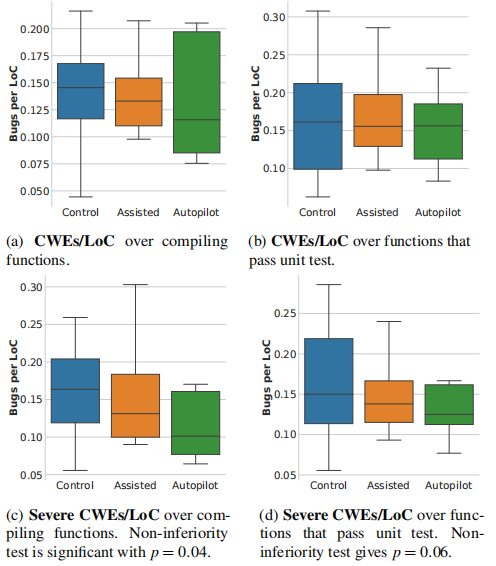
从结果中可以发现辅助组相比对照组具有更少的缺陷,其中辅助组在通过测试的情况下,严重CWEs的平均值最多比对照组低22%。即可以得出结论:辅助组的严重缺陷/LoC不超过对照组的10%。
4.3.4 各函数CWE比率
上一小节的主要结果表明,在assisted组和control组中CWE的发生情况相近。在本小节中检查这些组是否在功能级别上存在差异,即Codex辅助是否在某些功能上表现不同。结果如下表所示,其中N = 提交的功能数量,其中编译通过/测试通过的功能数量。 Rate是该组中每个功能的平均严重CWE数量。 黄色单元格表示control组的错误率比assisted高10%,蓝色则相反。 标有†的单元格表示这种差异在统计学上显著。
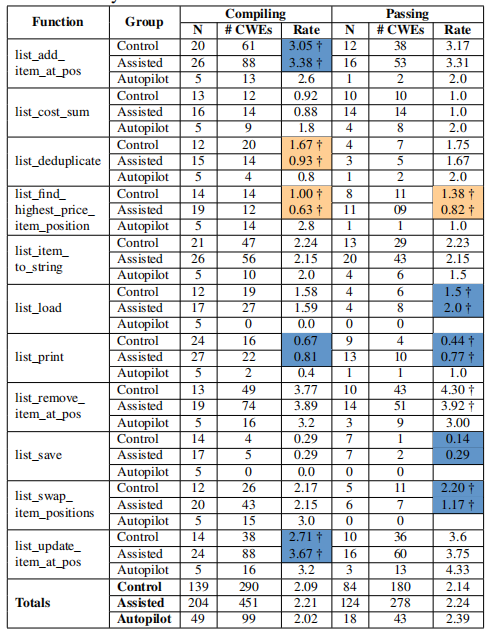
结果显示,在通过单元测试的代码中,辅助组在输入/输出操作函数中的漏洞更多。这可能是因为LLM在生成这些函数的代码时,更容易引入与字符串处理和内存管理相关的漏洞。控制组在涉及指针操作和复杂逻辑的函数中表现出更高的漏洞发生率。这表明人类开发者在处理复杂的指针操作时更容易出错。某些函数在两组中都表现出较高的严重CWE发生率。这可能与这些函数的复杂性以及C语言中指针和字符串操作的易错性有关。
4.3.5 CWE发生率
下图展示了用户提交中前10个CWE的发生率。
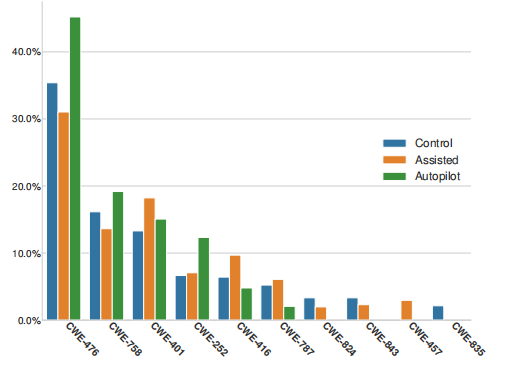
CWE-476(空指针解引用)是最常见的漏洞,这可能与API未保证参数正确性有关。CWE-787(越界写入)在辅助组和控制组中发生率相近,但在“Autopilot”组中较低,这可能与sprintf的使用有关。CWE-416(释放后使用)在辅助组中较常见,这可能与用户对item_name字段的处理不当有关。
4.3.6 观察结果
LLM代码辅助的影响在安全性方面不如功能性方面明显,但总体而言,辅助组和控制组的漏洞发生率相近,表明LLM辅助不会显著增加代码的安全风险。
4.4 RQ3 - 漏洞的起源
文章使用工具检查了第 4.3.5 节中识别出的全部 564 个安全漏洞,并将它们归类为由 Codex 建议引起或由人工用户手动引入,如下表所示,63%的漏洞由人类编写,36%来自LLM建议。 文章还分析了用户如何与LLM交互,以及这种交互如何影响漏洞的引入。文章认为主要有三种方式:(1)用户直接接受有漏洞的建议;(2)用户自行引入漏洞;(3)用户修改建议后引入漏洞。
文章还分析了用户如何与LLM交互,以及这种交互如何影响漏洞的引入。文章认为主要有三种方式:(1)用户直接接受有漏洞的建议;(2)用户自行引入漏洞;(3)用户修改建议后引入漏洞。
文章随后以 CWE-416(释放后使用) 为例定性地考察单个错误的来源。该漏洞主要来自LLM建议,用户接受有漏洞的建议后,未对代码进行充分检查。这种结果表明,用户与LLM的交互方式对代码安全性有重要影响。用户在使用LLM建议时,需要保持警惕,仔细检查代码的安全性。LLM建议虽然可以提高开发效率,但不能完全依赖,开发者仍需对代码进行仔细审查和测试。
5、讨论
5.1 对LLM代码助手的意义
功能性(RQ1):文章的研究表明有辅助的用户提交了更多的代码行数,并完成了更高比例的函数,这印证了最近的研究结论,即LLM助手可以提高开发者的生产力。
安全性(RQ2):LLM辅助并不会显著增加代码的安全风险,这与一些先前研究认为LLM可能引入大量安全漏洞的观点有所不同。研究发现,尽管LLM可能会引入某些安全漏洞,但在实际开发过程中,人类开发者自身的操作仍然主导了大部分漏洞的产生。
漏洞来源(RQ3):文章的研究发现用户与LLM的交互方式对代码安全性有重要影响。用户在使用LLM建议时,需要保持警惕,仔细检查代码的安全性。尽管LLM可以显著提高开发效率,但开发者仍需对代码进行仔细审查和测试,以确保代码的安全性。此外,研究还发现,某些函数的安全性可能因复杂性和开发经验而异,开发者需要根据具体情况调整对LLM建议的依赖程度。
5.2 对有效性的威胁
参与者选择:文章的研究招募的是大学生而非专业开发者,可能影响结果的普适性。但有相关研究证明,学生与专业开发者在安全性编码方面的缺陷密度无差异,且本研究的缺陷密度与已报告的相符,故影响有限。
代码编写任务难度:任务设计包含不寻常特性与非最优API,增加了难度。若开发者无法解决挑战,可能因沮丧交差了事。且C语言对不熟练者较其他语言更难,其他语言情境下的研究结果可能与文章中的结果不同。
数据捕获:由于基于云的IDE存在限制,只能每隔60秒拍摄一次开发过程的快照,无法捕捉所有参与者的全部数据,这限制了进行更精细分析的可能性。
6、总结
本文旨在研究LLM代码建议对参与者在用户研究中编写代码时的网络安全影响。通过对58名用户的调查,文章发现LLM对功能正确性有积极影响,并且不会增加严重安全漏洞的发生率。用户与LLM的交互方式对代码安全性有重要影响,开发者在使用LLM建议时需要保持警惕,需要进一步研究如何突出显示有问题的代码行以鼓励用户实时检查安全性。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
