
原文标题:THINK-ON-GRAPH 2.0: DEEP AND FAITHFUL LARGE LANGUAGE MODEL REASONING WITH KNOWLEDGE GUIDED RETRIEVAL AUGMENTED GENERATION
原文作者:Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li*, Mingfeng Xue Dayiheng Liu, Wei Wang, Zheng Yuan, Chang Zhou, Jingren Zhou
原文链接:https://aclanthology.org/2024.acl-long.12/
发表会议:ACL"24
笔记作者:彭佳仁@安全学术圈
主编:黄诚@安全学术圈
编辑:张贝宁@安全学术圈
1. 研究背景
大型语言模型(LLM)通过海量的预训练数据和参数,涌现出包括数学推理、代码生成和指令遵循在内的多样化能力。这些能力通过监督微调(SFT)得到进一步增强。尽管开源社区已经探索了通过特定任务的微调(ad-hoc SFT)来增强单一能力,但商业闭源的LLM在多种技能上表现出更强的通用性。因此,理解如何通过SFT促进多种能力的协同发展至关重要。
本研究特别关注在SFT过程中,数学推理、代码生成和通用人类对齐能力这三者之间数据构成的相互作用。作者提出了四个有趣的研究问题,以探索模型性能与数据量、构成比例、模型大小和SFT策略等多种因素之间的关联。
2 结论
不同的SFT能力表现出独特的规模效应模式,而在相同数据量下,更大的模型通常表现更佳。
与单一能力学习相比,多任务学习在低资源情况下表现出性能提升,而在高资源情况下则表现出性能下降。
随着模型尺寸的增加,数学和通用能力在低资源环境下的性能增益更大。
数据量直接影响每种能力,而数据比例的影响则不显著。
数学推理和代码生成能力随着数据量的增加而持续提升,而通用能力在大约一千个样本后就达到瓶颈。
(混合)顺序训练会遗忘专业能力。
模型需要大量数据来激活专业能力,少量专业数据不会影响通用能力的性能。
3 实验
3.1 研究问题与实验设置:
研究问题:
数学推理、编码和通用能力如何随着SFT数据量的增加而扩展?
在SFT中结合这三种能力时,是否存在性能冲突?
导致性能冲突的关键因素是什么?
不同的复合数据SFT策略会带来什么影响?
实验设置:
作者收集了三个SFT数据集 ,包括代表数学推理能力的GSM8K RFT、代表编码能力的Code Alpaca以及代表通用人类对齐能力的ShareGPT。将通过这三个数据集来组合一个新的SFT数据集D,以研究数据构成如何影响模型性能。使用GSM8K测试集、HumanEval和MT-Bench来分别衡量数学推理、编码和通用人类对齐的能力。使用LLaMA系列作为实验的预训练语言模型,并使用FastChat框架进行微调。作者对模型进行3个epoch的微调,峰值学习率为 。SFT过程中的批处理大小为16。
3.2 研究问题1:单一能力性能 vs. 数据量
实验设计: 使用GSM8K RFT、Code Alpaca和ShareGPT训练集的{ , , , , }比例的数据,对不同规模的LLaMA进行SFT。这使作者能够评估在不同数据规模和模型大小下每种能力的表现。

结果与分析: 图2展示了SFT后不同能力在各自数据上的规模效应曲线。
观察得到以下结论:
数学推理能力在各种模型大小上都与数据量呈正相关。
通用能力仅需约1k数据样本(范围从 到 )即可涌现,并在达到某个阈值( )后,其性能提升缓慢。这进一步支持了“少量高质量SFT数据足以在LLM中涌现通用人类对齐能力”的观点。
更大的模型能够捕捉到领域内样本中跨代码数据分布的共享知识,这使得它们能够对分布外(OOD)样本展现出一定程度的泛化能力
在相同数据量下,更大的模型通常表现更佳。一个例外是在数据极少( )的情况下,较小的模型可能会优于较大的模型。如果数据充足,较大模型则稳定地表现更优
3.3 研究问题2:性能差异 vs. 混合数据量
实验设计: 对于单一来源设置,与研究问题1的设置保持一致,分别使用GSM8K、Code Alpaca和ShareGPT的{ , , , , }比例的训练数据对不同大小的LLaMA模型进行微调。对于混合来源设置,从GSM8K、Code Alpaca和ShareGPT中采样{ , , , , }比例的训练数据,并按相应比例直接混合。通过这种方式,构建了具有固定能力领域比例但总数据量变化的数据集。
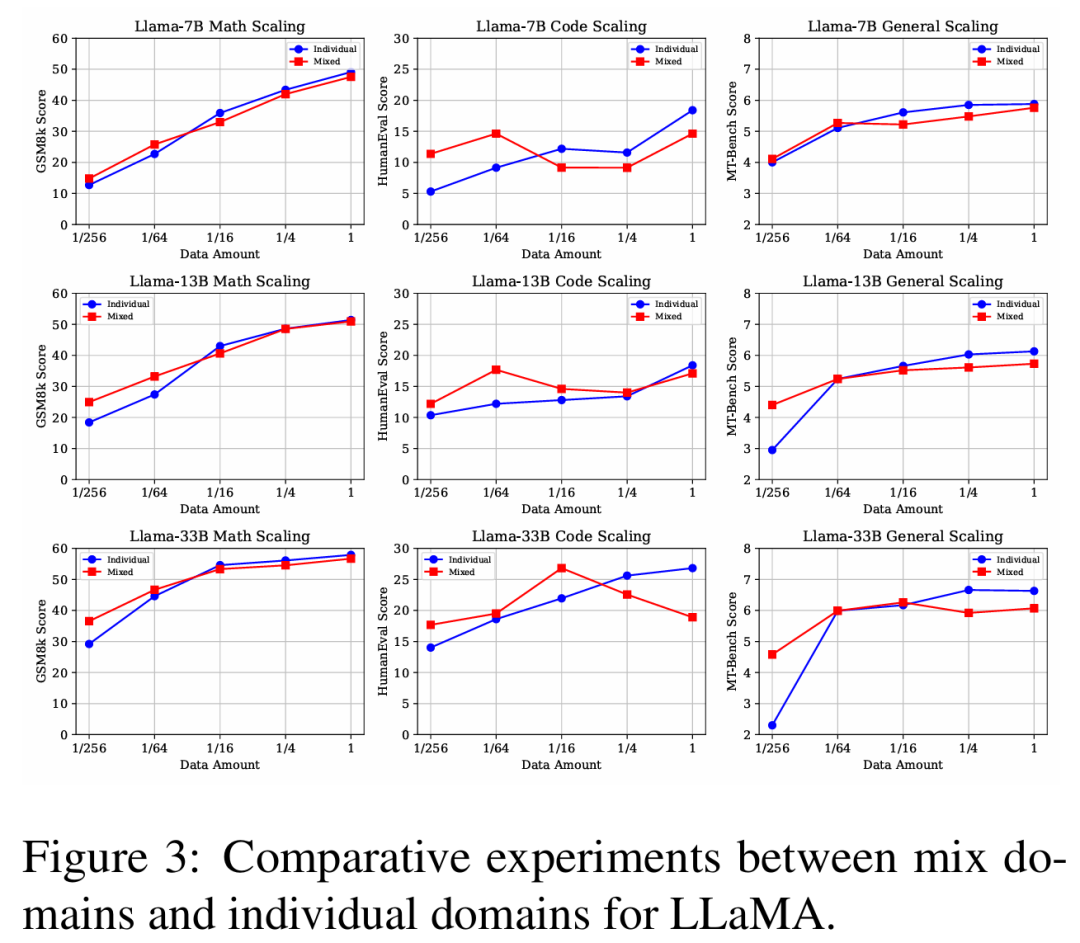
结果与分析: 图3展示了不同大小的LLaMA在单一来源和混合来源设置下于三个基准测试上的结果。
观察得到以下结论:
与单一来源的能力相比,混合数据在低资源情况下能力得到提升,在高资源情况下则有所下降。
来自不同来源的SFT数据在低资源设置下是互惠互利的。然而,当数据充足时,来自其他来源的数据可能被视为领域内泛化的噪音。
随着模型参数规模的增加,更大的模型在低资源条件下表现出更显著的性能增益。
3.4 研究问题3:性能差异 vs. 数据构成比例
实验设计: 作者将编码和数学视为一个组合的专业数据源,将ShareGPT视为通用数据源。设计了以下三个设置,通过控制一个来源的数据量并改变通用数据与专业数据之间的比例来进行研究:
固定(fix)通用数据,扩展专业数据: 使用完整的ShareGPT训练集,并采样GSM8K RFT和Code Alpaca的不同比例{ , , , , }作为混合。
固定专业数据,扩展通用数据: 使用完整的GSM8K RFT和Code Alpaca训练集,并采样ShareGPT的不同比例作为混合。
固定1/64通用数据,扩展专业数据: 受LIMA设置的启发,使用 的ShareGPT集(约1500个例子),并采样GSM8K RFT和Code Alpaca的不同比例作为混合。
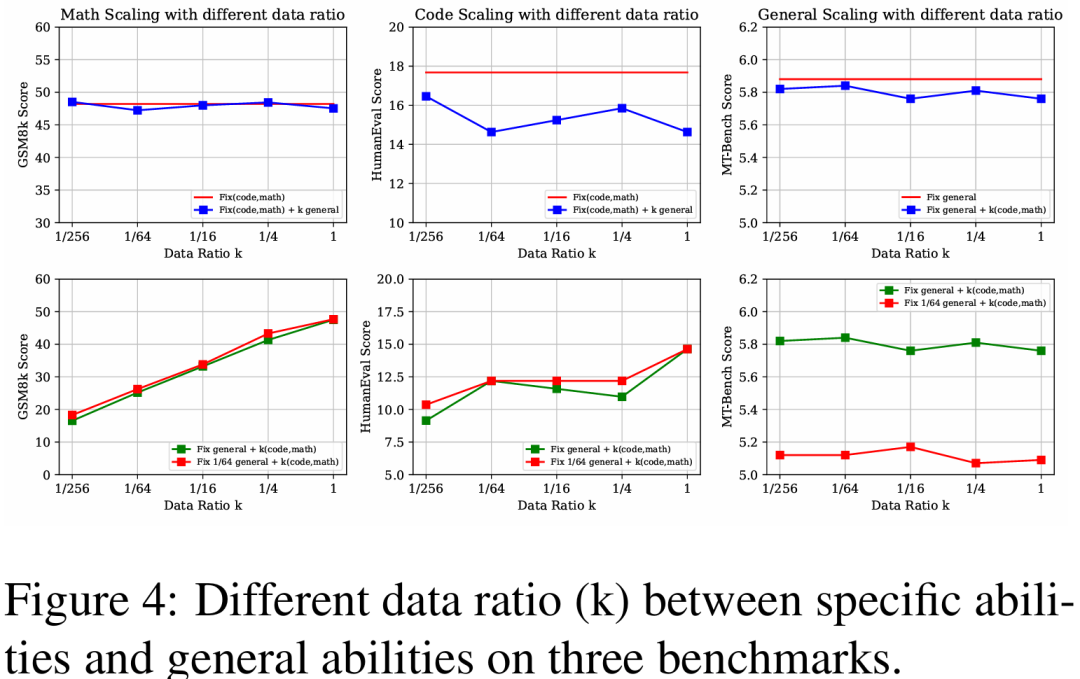
结果与分析:问题1:模型的性能是否会随着通用数据和专业数据比例的不同而变化? 如图4的上三张图所示。
观察得到以下结论:
随着通用数据比例从 增加到 ,“固定专业数据,扩展通用数据”设置在数学推理方面的性能与“固定专业能力”的设置相似。这表明数据比例k的变化对数学能力的影响微乎其微。作者认为原因是数学和通用能力在语义空间中差异太大,因此不构成冲突。
在HumanEval(编码)上,“固定专业数据,扩展通用数据”设置与基线相比显示出明显的波动。作者将其归因于ShareGPT中包含了一定比例的代码数据。由于数据格式和分布的差异,相似数据特征的存在加剧了当数据比例k增加时能力之间的性能冲突。
当不同SFT能力之间的任务格式和数据分布存在显著差异时,数据比例的影响是最小的。然而,当存在一定程度的相似性时,数据比例可能导致明显的性能波动。
问题2:在通用数据资源极其有限的情况下,专业数据的比例是否会影响模型性能? 图4的下三张图展示了两种设置的对比实验。
观察得到以下结论:
无论通用能力的数据量是充足( )还是稀缺( ),随着专业数据比例的变化,MT-Bench(人类对齐能力)上的性能都没有显著波动。
在数学推理方面, 通用数据设置展现出与完整通用数据设置几乎相同的规模效应趋势。然而,对于编码能力,在代码数据量相同但比例不同的情况下,两种设置下的编码能力是不同的。作者仍然认为其原因是代码数据与ShareGPT数据部分相关,导致了性能差异。
3.5 研究问题4:性能差异 vs. 训练策略
实验设计: 首先,引入三种朴素的训练策略如下:
多任务学习(Multi-task): 直接混合不同的SFT数据源 并进行SFT。如果将每个数据源视为一个不同的任务,这可以被看作是多任务学习。
顺序训练(Sequential):在每个数据集上顺序进行SFT。按编码、数学推理和通用能力的顺序进行训练。由于通用能力对于人类对齐最重要,将ShareGPT作为最后一个数据集。
混合顺序训练(Mixed Sequential): 首先对专业数据集(代码、数学)进行多任务学习,然后再对通用能力数据集进行SFT。
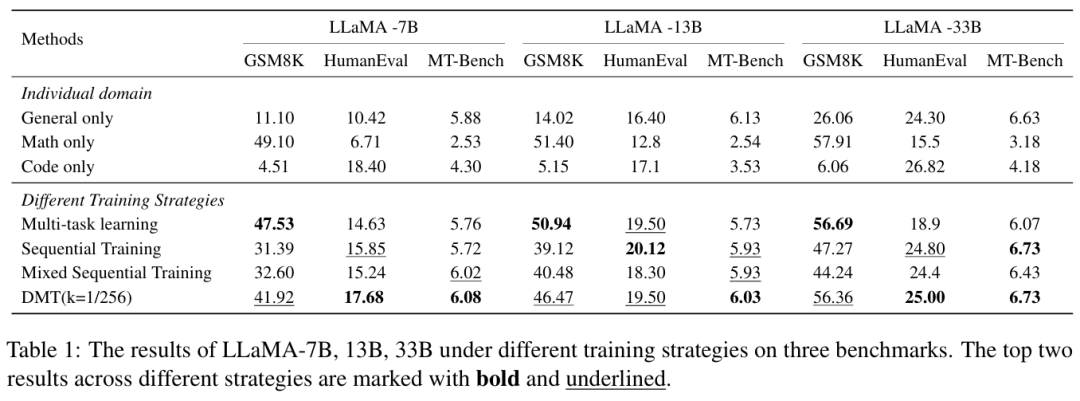
结果与分析: 表1展示了不同训练策略下在数学推理、代码生成和通用人类对齐能力方面的性能。
观察得到以下结论:
多任务学习保留了专业能力,但对通用能力的损害最大。顺序训练和混合顺序训练保留了通用能力,但损失了过多的专业能力。
多阶段训练的一个固有缺点是会发生对先前知识的灾难性遗忘
4. 双阶段混合微调(DMT):
从研究问题1可知,模型需要大量数据来激活专业能力。
从研究问题2可知,用全部专业数据和通用数据进行多任务学习会损害每种能力。
从研究问题3可知,少量专业数据不会影响通用能力的性能。
从研究问题4可知,(混合)顺序训练会遗忘专业能力。
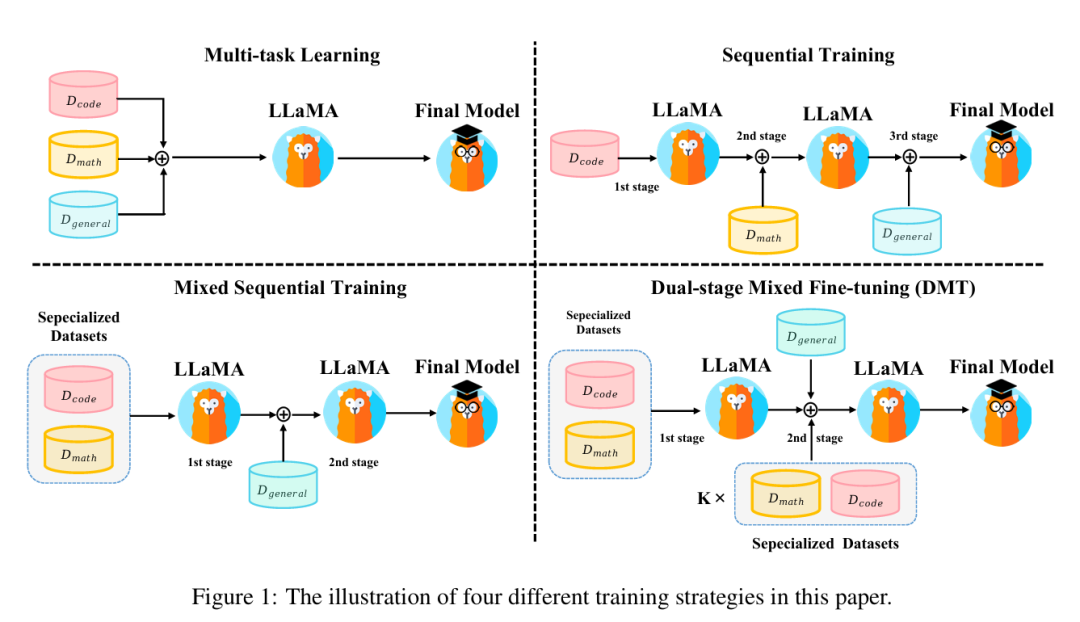
因此,模型需要学习大量的专业数据,并且在学习通用能力时不应忘记它们。一个自然的选择是先学习全部的专业数据,然后在顺序训练的最后阶段向通用数据中添加少量专业数据以防止遗忘。如图1所示,作者首先在专业数据集上进行SFT,这与混合顺序训练策略的第一阶段相同。在第二阶段,使用一个混合数据源进行SFT,该数据源由通用数据和不同比例k( , , , , , )的代码和数学数据组合而成。在第二阶段加入代码和数学数据有助于模型回忆起专业能力。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
