基本信息
原文标题:LLM-CSEC: Empirical Evaluation of Security in C/C++ Code Generated by Large Language Models
原文作者:Muhammad Usman Shahid, Chuadhry Mujeeb Ahmed, Rajiv Ranjan
作者单位:Independent Researcher(巴基斯坦);Newcastle University(英国)
关键词:LLM 生成代码,AI 代码助手,代码安全,CWE,CVE,C/C++,静态应用安全测试(SAST)
原文链接:https://arxiv.org/pdf/2511.18966
开源代码:暂无
论文要点
论文简介:随着大语言模型(LLM)在自动代码生成领域的迅猛发展,其助力开发者提升效率、缩短开发周期的能力日益显著。但与此同时,LLM生成代码的安全性问题逐渐凸显,对实际生产环境乃至影响全球数百万用户的应用构成潜在威胁。
本研究专注于评估LLM生成C/C++代码的安全性,设计了标准化的Prompt数据集,选取包括GPT-3.5 Turbo、Gemini Pro等10个主流开源与闭源LLM,对比常规助手与安全助手两种指令设置下的代码生成效果。为系统测评安全风险,论文引入MITRE的CWE分类和NVD的CVE映射,借助CodeQL、Snyk Code和CodeShield三大静态分析工具,从多角度、定量化评判生成代码的漏洞分布与严重性。
实验证明,当前LLM生成的C/C++代码普遍存在大量高危安全漏洞,包括缓冲区溢出、整数溢出、内存管理缺失等,而且安全指令并未根本解决这些隐患。论文呼吁开发者慎用LLM自动代码,将本研究方法与数据集作为后续安全评估与模型改进的重要基线,并为AI代码自动化与软件安全的持续进步提供数据支撑与方法论参考。
研究目的:随着LLM在代码合成、调试中的广泛落地,亟需深入思考其生成代码的安全可控性。作者聚焦于当前开放与闭源主流LLM自动生成的C/C++代码,关注因训练数据安全性不确定、代码自动化生成缺乏人类审查所带来的新型安全风险。研究试图回答两个关键科学与工程问题:一是不同LLM(含专用与通用模型)、不同Prompt指令设置下,所生成C/C++代码具体会暴露出哪些类型的弱点和脆弱性?二是应用现有主流静态安全分析工具,能否有效量化、对比和归纳LLM输出代码中的漏洞分布、关键高危CWE类型及与实际CVE事件的关系?作者旨在通过标准化、可复现的实验设计,构建跨多模型的代码安全量化评估框架,为社区理解LLM自动编程的安全现状、识别风险模式、推动更安全的AI开发助手奠定数据与实证基础。
研究贡献:
创建并开放了面向C/C++安全漏洞(CWE全谱系)的标准化Prompt数据集,可作为后续LLM代码生成安全测评基线。
构建了高覆盖率、多样化的生成代码数据集,涵盖10个主流LLM(开源/闭源、通用/专用、轻量/高参)在常规与安全两种助手模式下合计20个代码库。
提出了系统化的实验流程和评测框架:以MITRE CWE为Prompt生成基线,结合CodeQL、Snyk Code和CodeShield三类静态安全分析工具,进行跨工具多维漏洞检测与结果归因。
系统性分析了当前多个主流LLM生成C/C++代码时不同安全弱点在代码库中的分布、工具间检测差异,并量化了关键CWE/CVE类型发生频次与危害等级。
公开了完整Benchmark数据集、分析脚本及结果报告,推动该领域后续复现性与可持续性评测工作的标准化发展。
引言
近年来,大语言模型(LLM)在编程自动化与辅助开发场景中展现出突破性进步。自从早期文本生成与简单代码片段合成起步,演进到如今可支持多语言代码生成、自动调试及编程方案建议,LLM正深刻地改变着开发者编写与验证代码的方式。其带来的研发效能提升已获得业界广泛认可。然而,安全问题始终是自动化代码合成领域必须直面的核心风险之一,尤其是在C/C++等底层系统语言中,因固有的内存操作自由度高、类型弱约束等特性,潜在的缓冲区溢出、整数越界、悬垂指针等高危漏洞极易滋生
作者指出,尽管LLM依赖于大规模、多源的公共与私有代码库训练,实际训练过程中代码样本的安全性参差不齐,因此模型很可能“继承”了训练数据中的不安全编码习惯,将真实世界中的安全隐患复制或变体引入生成结果。基于此,论文对“LLM自动生成代码是否可以直接用于生产系统,是否值得开发者和企业信任”提出了疑问和系统性实证探究。
与此同时,论文明确定义了与评估相关的核心概念,包括漏洞(vulnerability)、常见弱点枚举(CWE)、公共漏洞与曝光(CVE)等,奠定了后续评测、统计归因的专业基础。作者通过调研和映射真实漏洞事件的CWE/CVE分类,结合以静态安全分析为主的SAST评测工具链,为LLM生成的C/C++代码设计了全面的风险识别和归类方案。
论文聚焦现有LLM在C/C++语言场景下的安全表现,采用十个具有代表性的语言模型,基于标准化的Prompt系统生成多样化的典型代码片段,并用CodeQL、Snyk Code、CodeShield等多源、安全性各异的SAST工具对静态代码进行漏洞检测和归类,最终呈现当前AI代码助手在业界高危语言领域的真实安全风险画像。研究发现,所有主流LLM生成的C/C++代码均或多或少地暴露出已知高危CWE弱点,指示开发者在直接采纳AI生成代码前,需对其安全性进行多层次检测与严格把控。此外,论文倡导将系统性评测方法、数据集与工具链开放共享,助力行业社区持续改进LLM代码生成的可控性与安全性。
相关工作
近年来,LLM生成代码的安全性问题逐步成为软件工程与AI安全交叉领域的研究热点。已有多项工作关注了AI助手生成代码中的安全缺陷现象。如早期针对GitHub Copilot的定向研究,通过基于“2021 CWE Top 25”构造情境,发现在Copilot自动生成代码中广泛存在诸如未检查返回值、缺乏防御性编程操作等漏洞,并利用CodeQL和人工检视评测其表现。部分工作则通过在GitHub公开项目中检索AI生成代码片段,实证支持AI助手在无严格安全约束下,可能放大原有错误模式,开发者应提高防范意识。
学界也有研究尝试将LLM代码生成安全性与人类编程相比,发现在诸多基础安全失误(如缓冲区溢出、指针处理不慎、算法实现错误)上,AI生成代码弱点密集,且部分安全错误难以被常规单元测试捕获。更进一步的用户实证研究表明,开发者借助AI代码助手时受其输出影响显著,倾向于采纳部分不安全建议,安全防御意识反淡化。
除C/C++外,已有研究初步拓展至Python、JavaScript等高层语言,评测不同Prompt设计、辅助提示对代码生成安全性的影响,发现人机协作与Prompt专业度显著影响最终安全性。值得一提的是,部分工作已提出基于安全驱动Benchmarks与新型指标(如secure@k, vulnerable@k)系统量化AI模型在安全与功能正确性间的表现落差,推动了Benchmark标准建设。
不过,整体来看,历史工作仍存在较为突出局限:其一,过往Meta(如Copilot)类研究主要聚焦高层语言,对C/C++等底层、高风险语境下的系统性安全测评仍不充分。其二,多数实验规模仅覆盖单一或有限LLM模型,缺乏大规模跨模型跨版本的综合评测,难以反映模型家族间的优化趋势与风险差异。其三,Prompt工艺与标准化尚未统一,大量实验依赖主观经验构造情境,不易推广或复现。
本研究正是针对上述不足,基于MITRE标准CWE分类搭建了自动化、批量化、可复现的Prompt与评测流程,并在包括通用/专用、开源/闭源、轻量/全参的10个主流LLM上系统开展安全评测,为C/C++领域的安全风险、评估基线与未来改进提供了重要补充。
研究方法
本研究提出了一套分三步走的系统化实验流程,兼顾数据基线统一、结果可复现与跨工具多维对比。具体而言,整体流程依次包括Prompt工程、代码生成、静态安全性分析三大环节。
首先,Prompt工程阶段基于MITRE公开的C/C++ CWE知识库,通过深度研究和案例理解,设计涵盖82类C与86类C++ CWE的代表性场景描述,并归并消除冗余,最终形成84条高代表性的标准化Prompt集合。每条Prompt均明确定义漏洞场景、输入输出与安全要求,并经由GPT-3.5与Gemini辅助生成与专家人工复审,多轮修订,确保能全面覆盖关键安全弱点,为所有模型统一出题。
第二步,代码生成阶段,针对上述Prompt集合,分别为每个LLM实例化两种助手模式:一类为通用助手(CG),采用规范性任务指令;另一类为安全强化助手(SCG),在系统提示中显式要求更加注重安全编程习惯。随后,针对每条Prompt,由10个LLM各自输出两组(通用与安全)C/C++代码,共构成涵盖20套代码库的生成数据集,极大丰富了风险控制实验的边界场景。
第三步,安全分析与评测阶段,将所有生成代码分别通过三类主流静态安全分析工具——CodeQL(覆盖CWE最全面,GitHub维护,基于语法/语义查询)、Snyk Code(专注C/C++,商业规则库)和CodeShield(Meta出品,面向LLM特化)进行漏洞扫描与归类。工具输出以SARIF标准格式归档,再通过自研的SarifMiner工具自动抽取、归类、映射CWE与实际CVE发生频次,并进一步实现可视化分析与横向对比。
如此流程兼顾了设计上的规范性(统一Prompt、统一工具、统一代码结构)、开放性(数据与分析脚本全开源)和扩展性(可纳入更多语言与模型),可作为后续业内LLM代码安全基准评测的重要蓝本。
实验设置
实验部分首先围绕数据集与资源配置展开详细说明。Prompt数据集方面,基于MITRE官方CWE列表,在全面覆盖82类C与86类C++漏洞类型的基础上,针对重叠场景与语义冗余逐步精简合并,最终确定84条高质量、高区分度、可映射真实CVE事件的Prompt集合。该集合已通过GitHub与Hugging Face公开,便于标准化评测。
在模型选型方面,实验涵盖10个当前主流LLM,形成兼具多样性和对照效能的矩阵。开源模型包括:Codegemma-7B、CodeLlama-7B、Codestral-22B、Granite-code-3b、Llama2-7B、Llama3-8B、Mistral-7B、phi3-3.8B;闭源模型则为Gemini-1.5 pro与GPT-3.5 Turbo。既有高度代码专用训练模型(如CodeLlama-7B、Codestral-22B、Codegemma-7B等),亦包含轻量化与通用型大模型,部分还成对设计专用/通用、轻量/全参的对比实验,为后续评测不同训练范式与参数量对安全表现的影响提供细粒度对照。
工具配置方面,三大SAST安全工具设置如下:CodeQL选用“security-extended”扩展语句库以保障CWE覆盖面和深度,对C/C++项目需成功编译自动建库后运行查询;Snyk Code聚焦C/C++检测规则,实现对31类特有CWE的细粒度识别;CodeShield结合正则表达式与semgrep等底层分析工具,专为LLM代码输出特定漏洞行为而优化。这一多工具并行方案既能增强发现能力,也为横向工具对比提供依据。
软硬件环境方面,开源模型均通过Ollama平台在本地消费级硬件部署,系统为Windows 10,配备16GB内存与2GB NVIDIA GPU;闭源模型则通过API方式在线调用,最大化利用其最新版本能力。生成与分析流程全过程自动化,所有实验中间数据、SARIF报告与最终结果均已开源,最大限度助力社区复现与迭代。
结果分析
实验结果从静态分析结果、CWE与CVE的映射、以及模型拒绝生成代码的特殊情形三方面展开系统梳理。整体来看,所有主流LLM无论基础还是专用安全指令(安全助手),其生成的C/C++代码均大量暴露出高危安全漏洞类型,安全性表现普遍令人担忧。
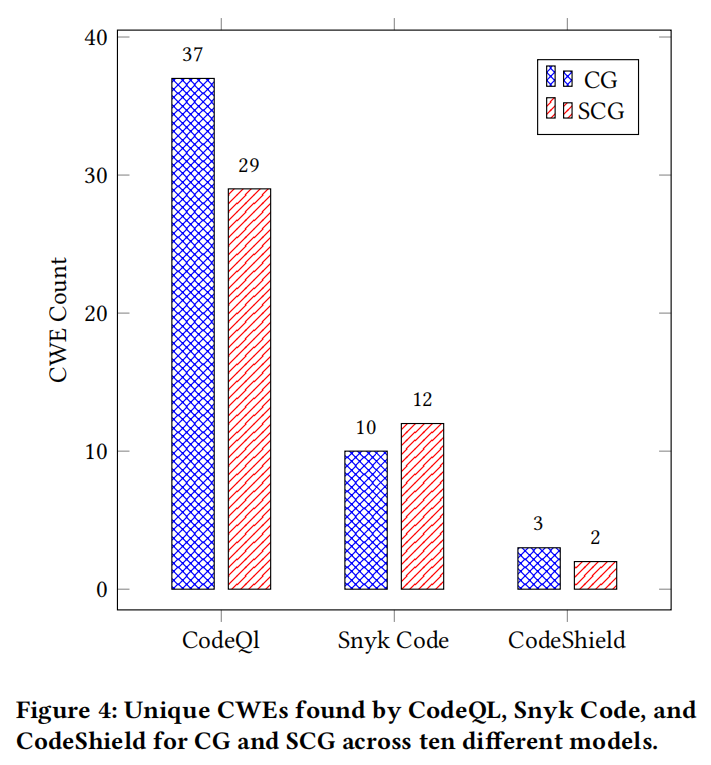
首先在静态分析阶段,CodeQL、Snyk Code与CodeShield三工具各自独立报告了数十种常见与高危CWE类别。以CodeQL为例,Mistral-7B在通用模式下检出18类CWE,安全模式下略降至16类,凸显漏洞数量的普遍偏高。Llama2-7B表现较优,但归因于安全助手下其拒绝/放弃生成部分高风险代码(74%代码覆盖率),并非本质安全提升。CodeQL与Snyk在特定CWE检出能力表现出明显差异,例如CodeQL的覆盖范围明显更宽,而Snyk则在特定CWE(如CWE-122:堆缓冲区溢出)上表现突出。CodeShield则更聚焦于内存敏感类CWE,尽管规则数较少,但实际检出依然显示严重问题。例如,部分模型在安全助手指导下,反而暴露出新型CWE,或未能规避安全指令诱导下的逻辑陷阱。
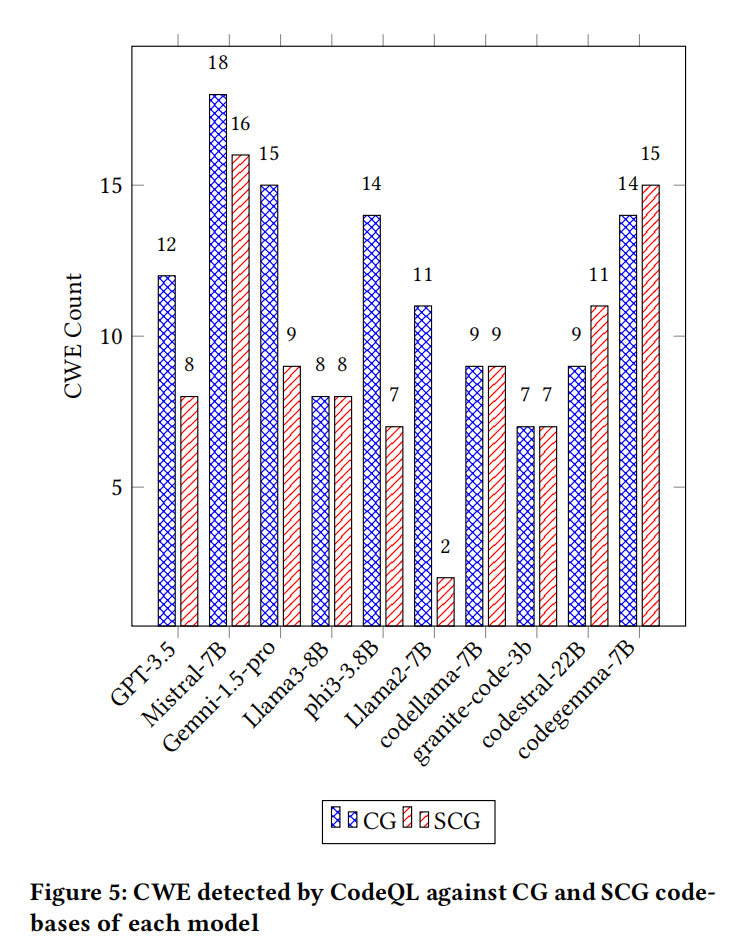
结合具体漏洞类型分布,常见高频CWE包括CWE-120(输入未检查复制、缓冲区溢出)、CWE-252/253(返回值未检查)、CWE-787(越界写)、CWE-805(指针使用错误)、CWE-401(内存释放后未销毁)等。这些类型不仅在代码库中多次高频出现,部分甚至在安全助手(SCG)模式下检测次数增加,反映模型在面对具体安全提示时,可能片面关注表层安全术语,实际代码实质性修复效果有限。
关键漏洞进一步映射实际CVE事件,发现诸如CWE-119、CWE-120、CWE-190等历史高发、影响极为巨大的漏洞类型频繁发生,对应真实世界中数千起严重安全事件。高达1万多项CVE与CWE-119绑定,CWE-416(悬垂指针)等同样关联上千真实安全告警,凸显LLM生成代码一旦未严格审核,其直接生产应用所带来的巨量安全风险。
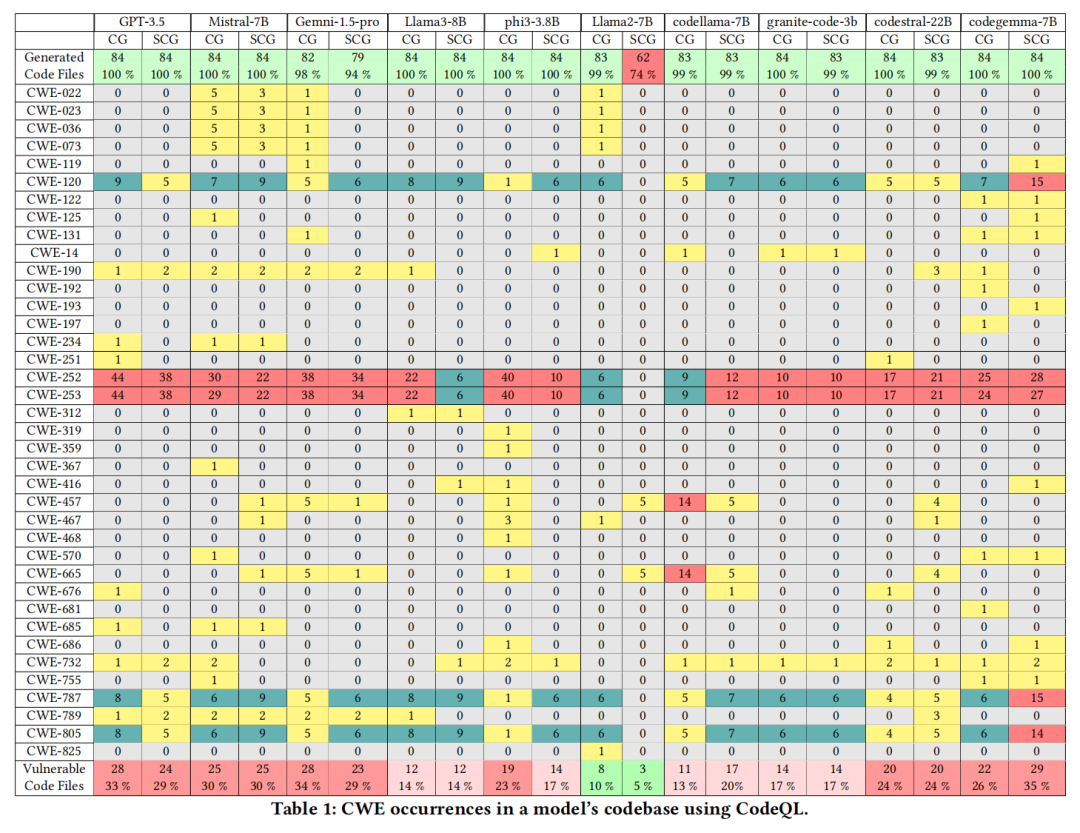
值得注意的是,部分模型在遇到特定高风险Prompt(如存储明文密码、操作敏感内存)时,安全助手模式会拒绝/规避生成相关代码,体现出一定的安全防范意识。然而,也有如CodeLlama一类,其普通助手拒绝但安全助手却输出了极为不安全的变体代码,实测依然暴露多重关键CWE。这一现象表明,模型对安全语境的场景理解与正确反应依然极度有限。
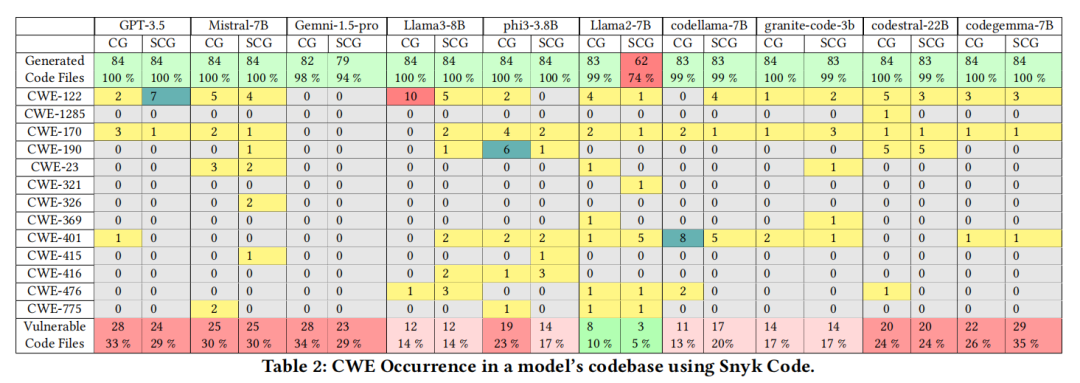
该实验证明,当前无论是专用代码模型还是通用大模型,其自动生成的C/C++代码在安全性上都无法达到生产级别要求。不同LLM间安全表现有一定差距,但无一能解决关键高危CWE类别的根本性威胁。安全助手在部分场景下体现出更加保守的生成策略,但在实际漏洞防护上并未取得本质突破。多工具交叉分析进一步显示,SAST工具自身的策略差异可能影响漏洞覆盖,但高危CWE层出不穷的局面总体未变。这一结果向业界、开发社区发出明确信号:对于所有LLM代码产出,需实施多层安全验证和严格审查流程,绝不可盲目信任自动生成结果投入敏感业务实践。论文同时为学界后续深度Benchmark建设、Prompt驱动安全优化、以及多模型安全策略研究提供了详备的数据和分析基础。

论文结论
本文以标准化、多模型、多工具的实验方案,对当前主流LLM自动生成C/C++代码的安全性做出了系统量化评估。研究表明,无论采用何种模型家族、参数规模、训练范式,或何种显式安全强化提示,LLM输出的C/C++代码均或多或少带有高危CWE类型,且所关联真实CVE事件数量庞大,安全风险极难容忽视。部分模型在面临高风险输入时选择拒绝生成或输出流程建议,体现出一定的AI安全敏感性,但这种消极规避并不能替代深层漏洞消除。在工具链角度,不同SAST工具对漏洞类型的识别集中与分散,进一步推动了“多工具协同检测”成为保障LLM代码安全的重要现实路径。
论文强调,随着AI助手日益渗透开发流程,自动化代码生成的功能正确性固然重要,但安全性短板绝不能被忽视,开发者应将LLM生成代码视为初稿而非定稿,必须经过严格测试与专业审查方可应用到真实生产环境。论文研究不仅为行业建立了高质量、可复现的C/C++ LLM代码安全测评基线,也为Prompt工程优化、模型安全增强、交叉工具联用等后续研究提供了详实数据、方法与资源支持。
未来,深化Prompt工程与动态交互技巧,对安全漏洞递进修复与模型自我纠错能力展开系统探索;扩展至更多语言、代码场景与新兴LLM版本,建立全栈安全性评价体系;推动社区标准化Benchmark与工具链建设,提升行业整体自动化开发的安全信心和风险防控水平。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
