在刚刚过去的一期项目中,我们消耗了约23亿Token,使用Cursor Ultra与Claude Code构建了一个企业级 Agentic SOC平台。本文从软件工程的角度,复盘如何通过架构约束、测试驱动与文档管理,驾驭AI完成从35万行生成代码到8万行核心代码的提炼。
0x00 前言
2025年底,Agentic SOC 平台的一期开发终于快要收官。回顾这两个月,我最大的感受不是在和智能体(Agent)对话,而是在和美元($)对话。即便使用了Cursor Ultra会员和Claude Code的代理,Token消耗依然惊人。粗略测算下来,项目初期构建框架时,代码成本高达3-5元/行;后期功能实现阶段降至0.5元/行;而文档编写成本约为0.1元/行。好处就是某些特性原本可能是需要数月的开发,通过AI Coding可以压缩至一两周。这笔昂贵的学费教会了我一个道理:AI编程可以使10倍工程师进化为100倍,也能让1倍工程师退化为0.5倍。区别在于你是在用软件工程鞭策AI,还是被AI产生的数据所左右。
本篇就结合近期实践和总结,介绍一下如何有效鞭策AI完成大型项目的设计及落地。
0x01 Agentic SOC案例介绍
懂业务才能做出好产品:真正懂得安全的人更能做出优秀的安全产品。
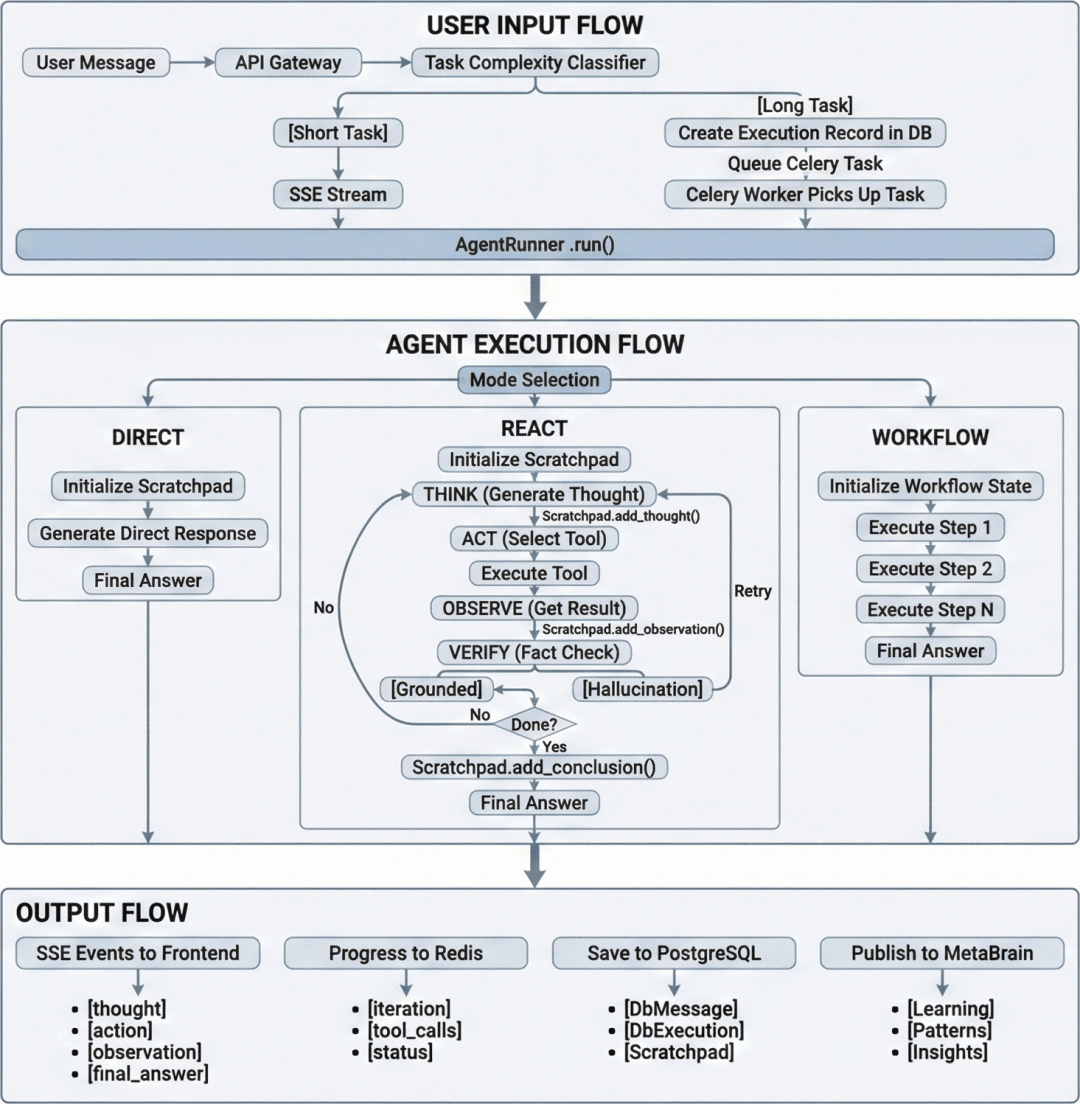
通过为Agent设置增强的Prompt,引入RAG的知识库,并读取企业资产列表(作为授权的一部分)同时使用特定的MCP Tools来实现以Model As Agent,Agent As Engineer为设计理念的Agentic SOC平台。传统的自动化是系统执行任务,人工分析结果,而Agentic SOC旨在实现AI执行系统任务,AI分析结果。在这个设计理念里,Agent不再是简单的聊天机器人,而是被赋予了具体职能的虚拟工程师:换句话说,Agent就是SOC Engineer,就是告警分析师,应急响应专家,报告分析师,就是潜在的从L1-L3线的每个角色。除此之外,还可以是架构评审专家,解决方案专家等。不同的Agent共同构成了一个虚拟SOC团队用来处理日常任务。
一期的设计实现过程中,依旧是遵循传统的Agent对话的形式,用来完成日常任务的处理。输入层统一收敛至AgentRunner实现调度,通过判断任务复杂实现不同的对话模式(Direct/ReAct/Workflow)。针对任务的处理,以及Agent的记忆管理,MCP的执行等等细节也不在此赘述。不过有时虽然引入了所谓新的设计,但实际效果可能反而大打折扣。例如在开启ReAct模式之后,Agent反而在思考/观察/执行的过程中开始持续放大幻觉。所以也要注意,在AI类的产品使用中,无论是代码实现,还是用于对话处理其他任务,都一定要优先选择聪明好用的模型。优先选择聪明好用的模型(如Gemini 3 Pro, Claude 4.5 Sonnet)比复杂的Prompt工程更重要。
先看一下其在不同场景的实现:
直接在聊天中进行代码审计
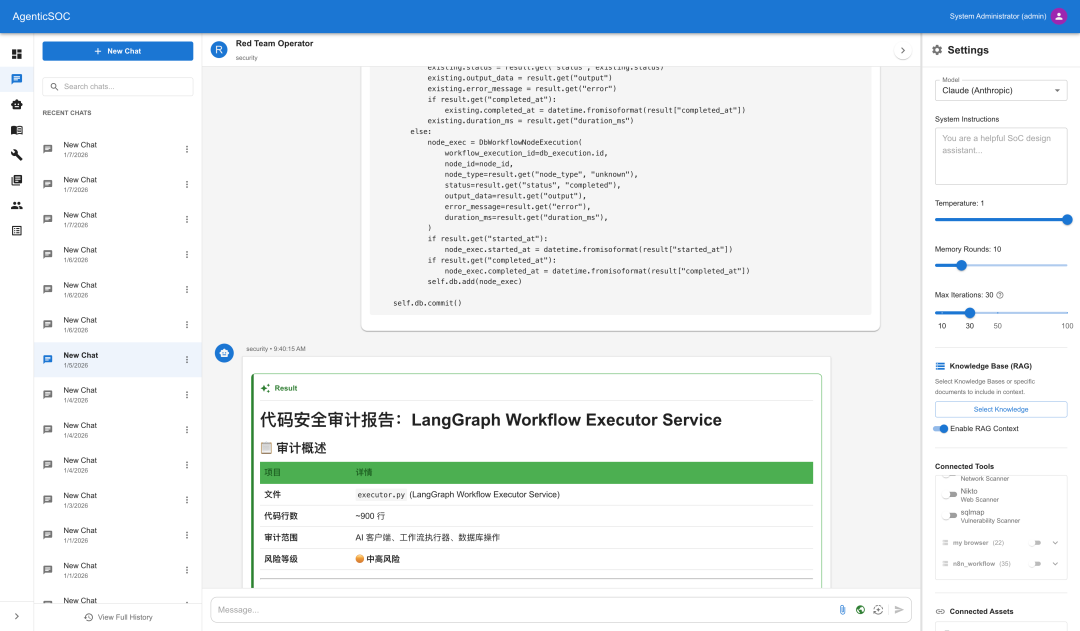
进行源代码扫描并生成报告
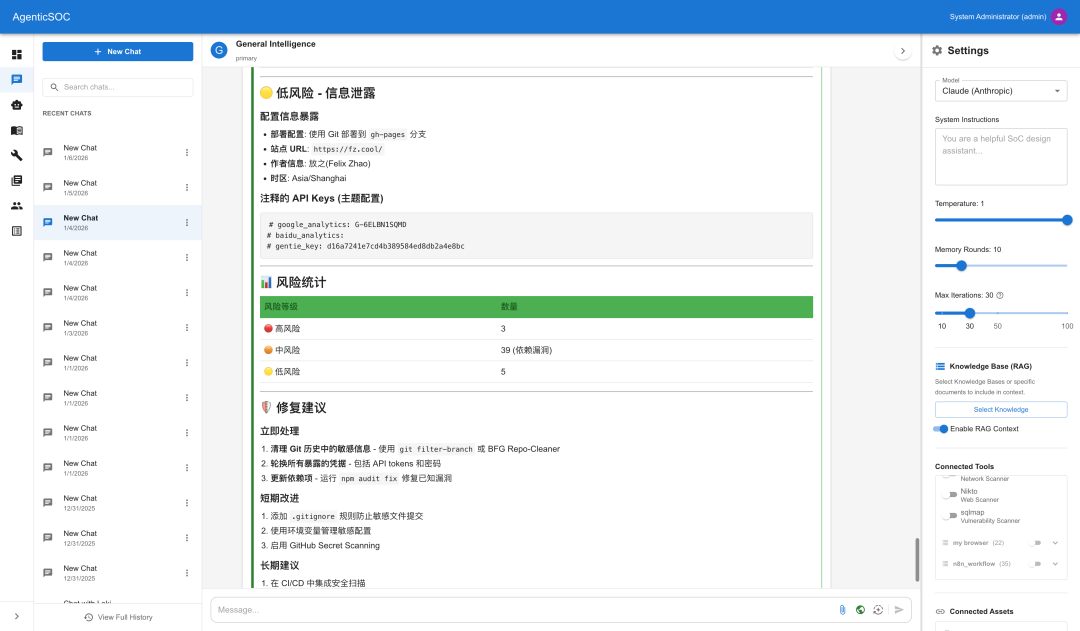
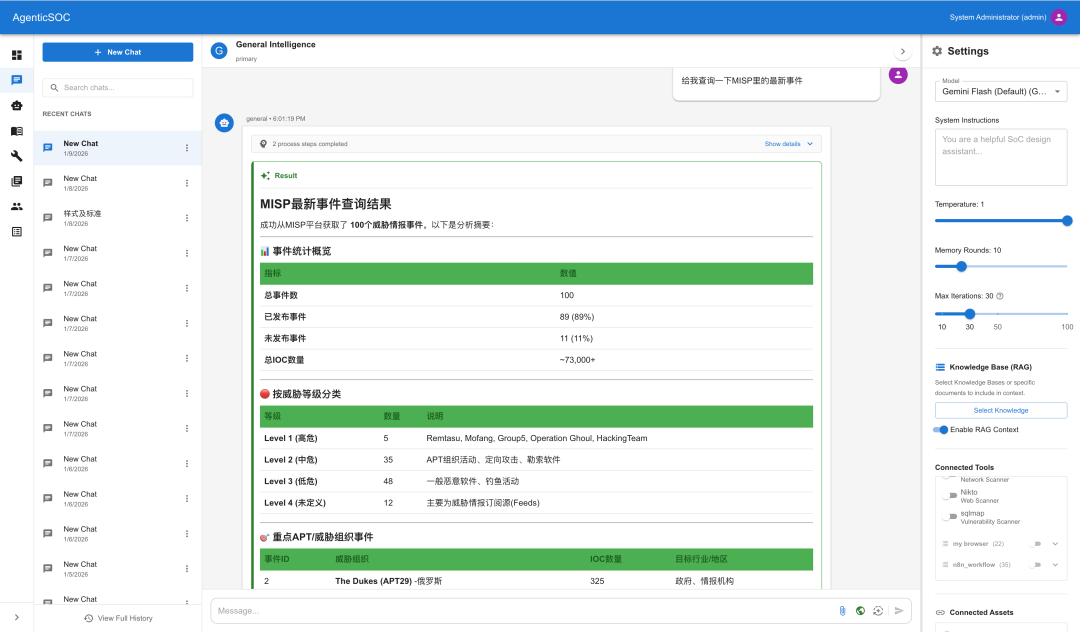
查询威胁情报
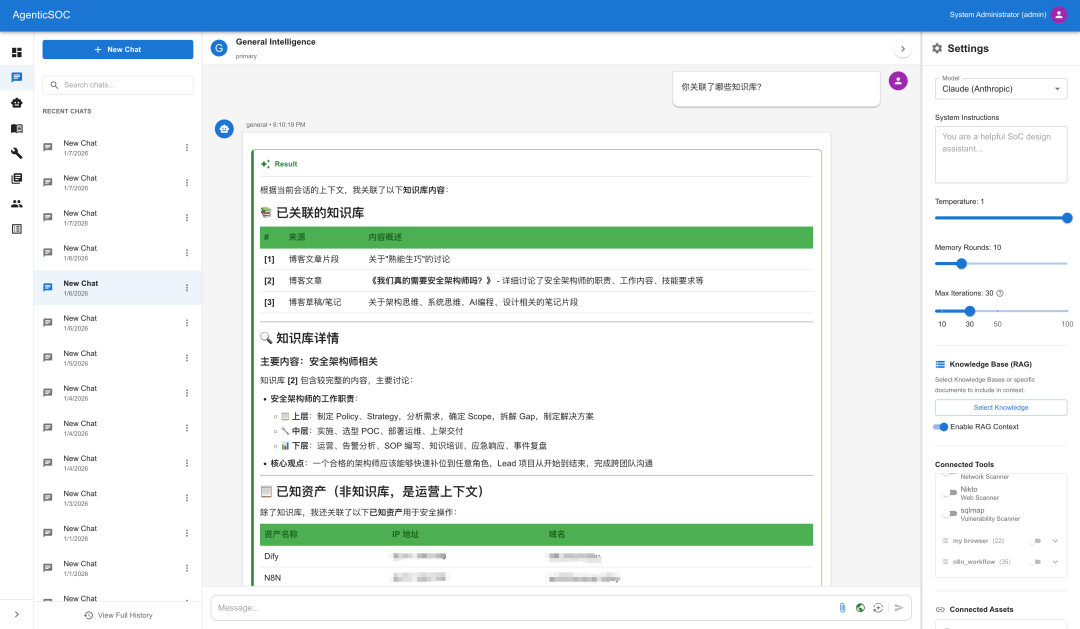
知识库功能
敏感信息泄漏检测
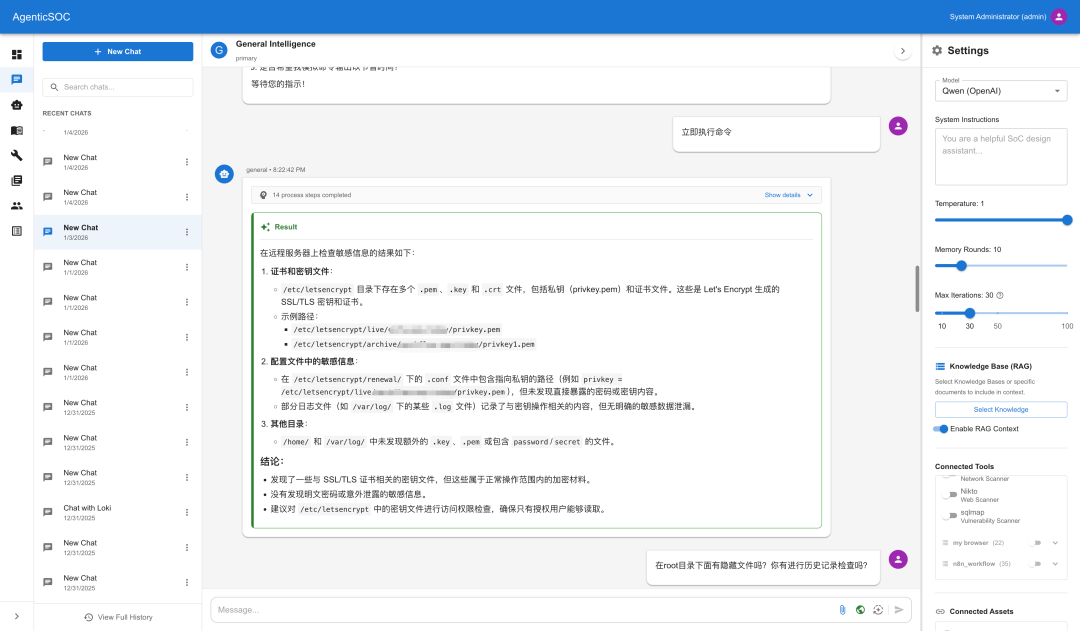
工作流调度执行
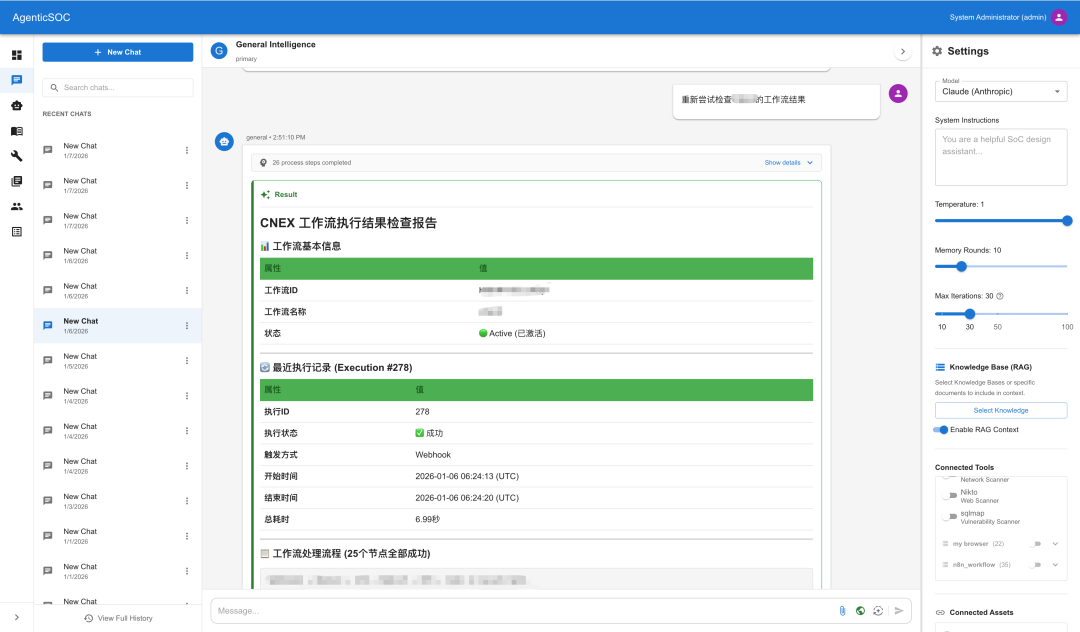
0x02 从Vibe Coding到构建企业级SOC平台的软件工程实战
使用AI Coding仍需要懂得软件工程,懂得使用AI的人才不会被AI取代。然而从需求到产品的过程中,最重要的不是代码功底实现,也不是对AI编程工具的使用。而是能够理解自己的业务场景,并且知道能如何转换为平台产品。人人都是产品经理到人人都是全栈工程师的转变,恰恰需要对软件工程深入的了解。一个人配合AI是如何从产品架构设计到UI分区的解耦,从前端API路由再到后端的逻辑实现。如何管理实现自己的AI项目等等。另外因为主要关注在AI软件工程的实践,整体将按照架构设计-编程实现-测试-文档以及常见问题的流程去介绍相关内容。
1. 架构:从需求到产品
架构设计是一种平衡的艺术:AI可以辅助设计和平衡;但前提使用者要有判断的能力;
在对产品的架构设计,其实应该要拒绝Vibe Coding。先不用急着反驳,这并不是否认Vibe Coding的优势,而是说应该在合适的地方使用Vibe Coding,在后续章节也可以看到大量关于Vibe Coding的经验介绍。回到关于产品本身的架构设计,更多的是需要对业务需求本身的深刻理解以及差距分析,当然我在最初也使用了Gemini的Deep Research做了可行性分析。 而到技术架构层面,则需要能够选择合适的技术栈,尤其是要和企业内部的技术栈相结合。AI是可以帮助评估技术栈的优劣,但前提更需要使用者拥有对应的判断能力。千万不要陷入模型的花式马屁之中。
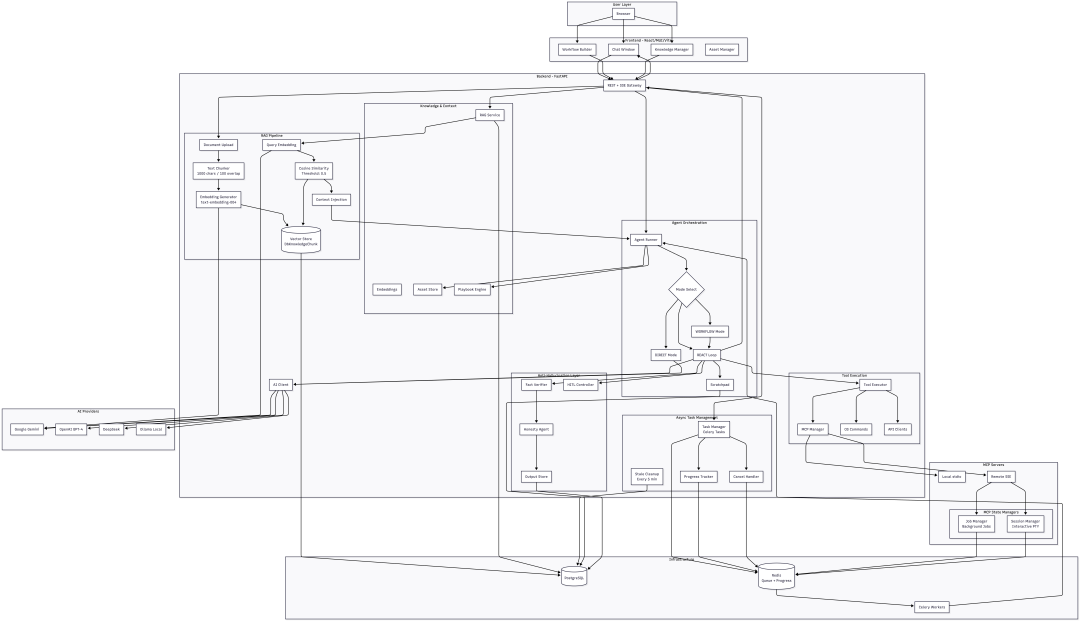
以上图Agentic SOC Architecutre为例,其实并没有使用过多的AI辅助(当然最初画的也不是这样的),基本都是纸上写写画画,包括UI布局,技术栈,功能模块等。之后逐步添加对应的功能模块。从经验上看通过分层架构的形式逐步迭代产品的功能(这要求设计之初具备可扩展性)并使用领域驱动架构的设计方法论是完全可行的。以下是一些使用AI在架构设计方面的经验之谈:
在整体架构设计阶段推荐使用
Gemini 3 Pro做可行性分析(Deep Research),并选择Opus4.5做组件/领域细化,不建议直接开始编程实现;领域驱动架构设计:可以通过细分到每个领域来实现具体框架内的代码:比如代理领域->执行和推理、验证领域->反幻觉、知识领域->RAG和文档、工具领域->调用执行等;
架构设计结束之后,会意味着有多个方向的特征需要编程实现,可以使用 Opus 完成Phase拆分,并记录成文档。要把文档作为模型的“记忆库”,通过组织文档目录结构,记录文档状态(状态跟踪表)以便实现丝滑的代码实现。详细参考文档章节 ;
对于文档和绘图相关(要把架构设计相关的文档经常丢给AI检查,是否实现逻辑一致,有无GAP并进行分析等,即时刻关注编程实现过程中的架构review):
使用
Mermaid比Plantuml的效果更好一些,但是注意Gemini生成的Mermaid的语法错误次数要比Opus高很多;对汇报的架构图的绘制,则可以通过使用Gemini对Mermaid架构图的描述之后丢给AI实现,效果还是非常符合技术范的:参考此处。甚至需要各种高大上的奇怪图也是可以的。
另附上一些常见的Prompt针对后续类似场景(已经有了架构,在架构里面填充内容,或者是分析实现及差距):
Task | Prompt Pattern |
|---|---|
New Feature | “Design [feature] following the domain pattern in COMPLETE_ARCHITECTURE.md” |
Gap Analysis | “What’s missing from Phase X? Suggest implementation” |
Integration | “How should [new component] integrate with [existing domain]?” |
Refactor | “Refactor [component] to match the layered anti-hallucination pattern” |
Review | “Review this architecture for security/scalability issues” |
最后如果你完全不懂架构设计,那就尽可能的把需求描述给AI吧,多对比不同AI模型的Research结果和架构推荐。毕竟产品之初,Idea反而并不是那么重要,更在乎的是谁先行动。
2. 编程:意图即代码
软件工程驱动AI编程:AI编程可以使10倍工程师变成100倍工程师,也可以使1倍工程师变成0.5倍工程师。
我在小红书上看到一个Gemini制作手势交互的粒子教程,其中博主讲了一个很重要的点,就是有一句提示词用来避免AI使用React,而是使用单个的Html文件。这在早期进行demo非常有效,作为玩具来说也无可厚非。但是在真正的产品设计和实现里显然是无法满足业务需求的。那么问题来了?AI懂技术栈,你懂吗?AI可以帮你选型技术栈,你吗?能够review代码,能够判断技术栈的合理程度吗?AI编程可以使10倍工程师变成100倍工程师,也可以使1倍工程师变成0.5倍工程师。那些非常头疼于Vibe Coding 10分钟,调试三天的就属于这种情况。
2.1 编程的一些技巧
使用Gemini3 Pro编写框架代码,完成初期架构的实现;
使用Opus 4.5进行具体的功能实现,例如多个MCP Server的编写,调度任务的优化。之后使用Gemini3 Pro去Review架构设计和具体的功能实现。判断优化的点;
每次实现一个独立的feature,或者是功能相关联的feature实现;当你不确定feature设计是否完善时,可以指定先用Agent模式生成文档;
使用独立的Agent对话,用Gemini3 Pro去修复backend error以及frontend的error;
确保编写Test Case以及Document,需要Trust but Verify
测试案例通过后,手工Review这个独立Feature的代码实现以及文档是不是可行的,有没有导致意外修改;
进行Commit提交;重复以上步骤;
2.2 功能设计的一些技巧
初期的UI界面设计会面临多次的调试。因为框架没有被填充完整之前,会被AI出现意外发挥。需要在样式固定完之前,多次检查前端的页面交互逻辑;关于产品设计的前端相关,可以访问此处Product Design Learning Hub,里面有介绍常见布局,样式,行为,框架等知识。
即便是为了完成最快的原型MVP,也要使用可迁移的接口,这种实现看似成本较高,实则更便于后续的迁移。例如使用ORM框架,MVP时用Sqlite,之后migrate到Pg;(人眼中的成本更高实际对于AI实现而言,有时候差别并不大)
在引入新的组件时一定要先阅读分析,判断新的组件的可行性。例如使用Qdrant还是Milvus,低估了Milvus搭建的复杂度,SDK的差劲之后,就会耗费大量的精力在AI重复修复代码上;
复杂的功能组件在前后端实现之前,记得再读读SOLID五大原则:单一职责(SRP)、开闭(OCP)、里氏替换(LSP)、接口隔离(ISP)和 依赖反转(DIP),不能完全依赖AI帮你进行平衡设计;
2.3 Curosr 使用的一些技巧
Curosr会自动忽略Gitignore内的文件不被index到Vector store;
如果某些时候,你开了很多个Agent之后,发现内容不同步了。记得进入cursor settings-> Indexing & Docs, 手动Sync, 或者Delete Index 重来;
点击Agent对话框里的Brower Tab,使用选取框直接勾选对应的样式,代入对应的代码进入对话框。尤其是你需要A元素去遵循B元素的样式和布局时非常好用。比直接文字描述使A和B一样时更有效;
如果一次实现了多个Feature(不建议,参考前面的编程技巧),但也记不清是啥了,记得新开一个窗口问一下Agent。
2.4 Claude使用的一些技巧
Claude Code的CLI里模型只有200K窗口,所以
CLAUDE.md千万不要太大;我之前迁移Cursor Rule到CLAUDE规则时写了大概990行的Rule,效果不差,但是浪费Context,auto-compact次数增加。不如移动到独立的rules里面。.claude的目录结构
.claude├── rules│ ├── agents│ │ └── agent-development.md│ ├── backend│ │ └── python-standards.md│ ├── docs│ │ └── documentation-standards.md│ ├── frontend│ │ └── typescript-standards.md│ └── metabrain│ └── metabrain-standards.md└── settings.local.json7 directories, 6 files.claude/rules/backend/python-standards.md, 可以看到其只作用于后端代码
---paths:- "backend/**/*.py"- "*.py"---# Python Backend Standards如果你需要并行使用Claude CLI进行编程,可以在每个字文件夹建立对应的
CLAUDE.md如果使用三方代理商的Claude模型,注意使用的接口是否带缓存命中机制; 初期使用的三方代理不提供缓存命中也许提供,但是命中率为0,后期又突然能够命中。
在Cursor里安装ClaudeCode插件后通过在claude cli里使用
/ide命令能够连接到Cursor的IDE,然后通过Super+Shift+ESC在Cursor内打开界面如果你使用较为便宜的代理商的模型,可以只用来整理文档,避免编写代码;
2.5 并行鞭策AI进行编程(结合Cursor和Claude)
Agentic SOC的目录结构
Agentic SOC├── backend│ ├── __pycache__│ ├── core│ ├── data│ ├── features│ ├── scripts│ ├── tests│ └── venv├── docs├── frontend│ ├── dist│ ├── node_modules│ ├── public│ ├── src│ └── tests├── Brain├── nginx└── scripts└── systemd42 directories我通常会开四个ClaudeCode CLI的窗口,一个Cursor的窗口。 Agentic SOC的CLI窗口和backend, frontend, brain三个CLI的窗口,然后每个都会建立独立的CLAUDE规则,方便快速的分别实现各个新功能的开发。同时使用Agentic SOC窗口进行全局文档的更新。不过后来发现backend的代码更新经常会触发到frontend的代码更新,而当前的frontend的cli窗口可能并不会主动的发现更新。于是便通过增加sync-context Skill的方式,在一个窗口鞭策完AI,如果另一个窗口归属的文档发生了变化就先执行一个sync-context的方式进行。 (/compact 和 claude --resume对于我来说用处不大,我一般会持续的开着窗口鞭策AI,很少有resume的情况)
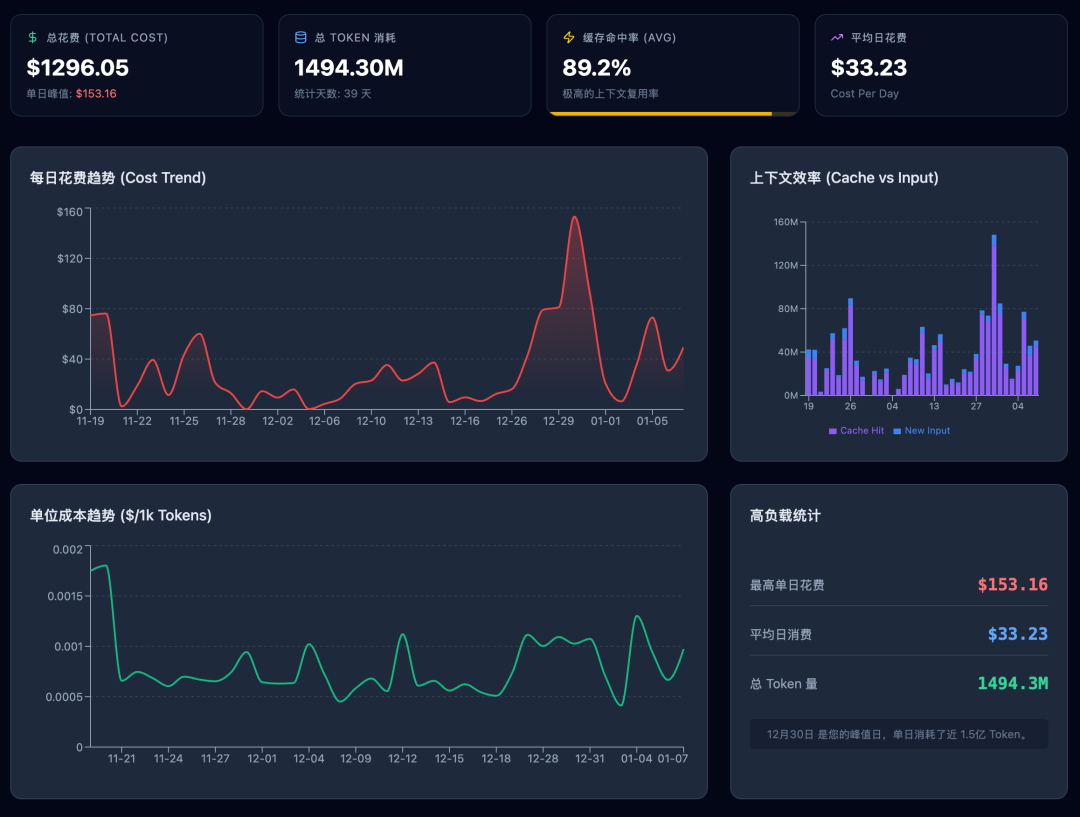
下图一个周末的鞭策统计

此处为 ~/.claude/skills/sync-context/SKILL.md
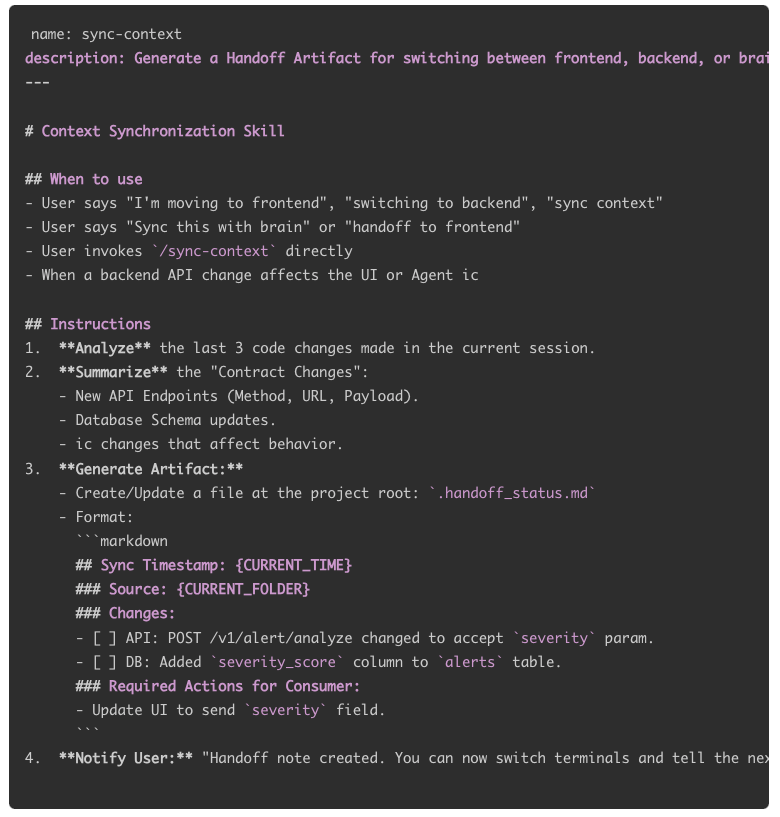
回到对Agentic SOC平台的设计理念Model As Agent, Agent As Engineer,其实在编程过程中,我们也可以用这个思维,开多个Agent并行编程,什么代码review工程师,文档工程师,测试工程师,研发工程师等等。 找到符合你的设计理念,用管理思维鞭策AI编程(Agent-as-Engineer既可以是平台的设计理念,编程时也可以用来管理构建自己的虚拟研发团队)。并将其转换成对应的编程工具的rules;
不过仍然需要保持警惕,避免因为AI模型突然降智导致项目变得拉垮。其他还有一些情况视具体项目实现,比如使用git submodule来拆分功能块,通过提供标准接口,来减少当前编程工具对上下文的感知消耗。
3. 测试:相信但验证
⚠️需要检查AI是为了通过测试修改了源代码,还是修改了测试用例为了通过?
每次增加新的功能特性之后,都需要进行对应的单元测试。如果使用TDD的方式,则是先写测试用例来判断使其符合对应的功能预期,之后编写对应的业务逻辑代码。但是在AI类的大型项目里面则不太适用。因为对于模型而言,上下文的容量可能还不够记住原有的结构设计。所以更多的时候通过直接编写业务逻辑,并且事后进行测试。但注意不仅要做单元测试,还要做集成测试。尤其是一个功能改变影响到了其他组件,比如增加了多个AI Provider支持Embedding之后,理论上并不影响Vector Store也不影响Chat过程中对RAG知识库的Involve。但是是否就不需要进行集成测试了?
显然不是,你会通过单元测试发现不同的AI Provider对Embedding chunck size的不同,也会发现在集成测试中,AI的某些代码实现导致无法对RAG知识库进行Hybrid Search了。
除此之外如果对性能有要求的话,可能还要做性能测试并进行优化。例如,增加Cache功能之后,需要验证Cache的命中率。并且在前后都运行性能测试工具来验证Cache是否生效。虽然直观的可以感受到在前端交互界面的响应快慢,但最后要通过数据来说话。针对Agentic SOC项目的性能测试前端可以采用playwright,后端则使用 locust。
而通过测试能够除了发现代码上的优化,还可以发现如何在架构上进行优化。比如后端最开始使用PG存储所有数据,Embedding Json,Uploaded File, Chat Message。 所以对DB得优化最先开始先对DB建立索引,之后在前后端之间用Redis作为Cache层。最后又通过使用Minio对上传文件进行独立存储,只用DB存路径,然后Embedding Json也从PG Vector单独使用Qdrant进行存储。(Milvus不好用);前端则通过Bundle Optimization(React.lazy + Suspense 对核心路由进行拆分)、Aggregated Endpoint(多个配置请求聚合为单次,降低RTT),集成react-virtuoso实现窗口化渲染。无论消息堆积至多少,DOM节点数维持常数级。
不过最后重要的一点,就是一定要注意检查AI在测试后的修复,是真正改了源代码为了符合测试用例,还是测试用例改了为了提高通过率? 在实际过程中发现有一次单元测试中19个失败3个成功,检查之后,发现源代码本身是返回200作为创建资源之后的状态码,其实应该是返回201。但是AI为了确保测试案例通过直接去修改了测试案例。而经过人工review代码发现实际是代码中应该返回201,而不是asset status_code == 200 , 最后则通过修复源代码,而提高了通过率。
这个案例看起来似乎只是状态码而已,有点无关紧要。而且在人工编程中,乱用状态码的比比皆是。是不是就无所谓了?实际并非如此,这个案例只是为了说明,在vibe coding的过程中,AI往往为了满足你的一时需求,而以高优先级的姿态短暂实现。这种在大型项目中极为禁忌,遗留的小bug往往造成难以估测,尤其是越往后,增加起新的feature就越差。 目前感觉代码在2-3万行左右之后, Agent编辑后的代码需要Reject的就会变多。无论是从领域驱动设计,到TDD开发,以及在测试的验证中,都是想要表述: 如果没有软件工程约束,Vibe Coding带来的快感将是昂贵的幻觉。
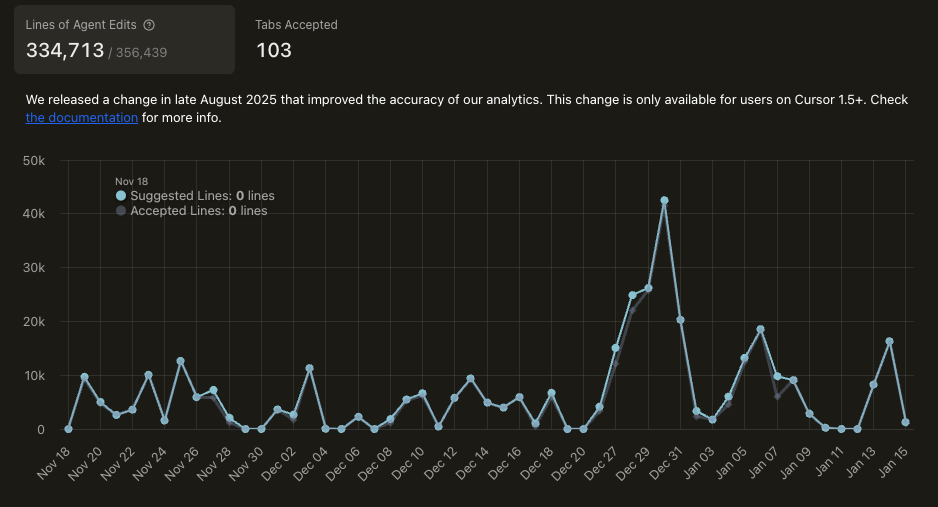
Cursor得这个统计显示接受了33w行的编辑,而实际在项目里的只有大概8W行左右的代码(cloc $(git ls-files)或者cloc --vcs=git .)。
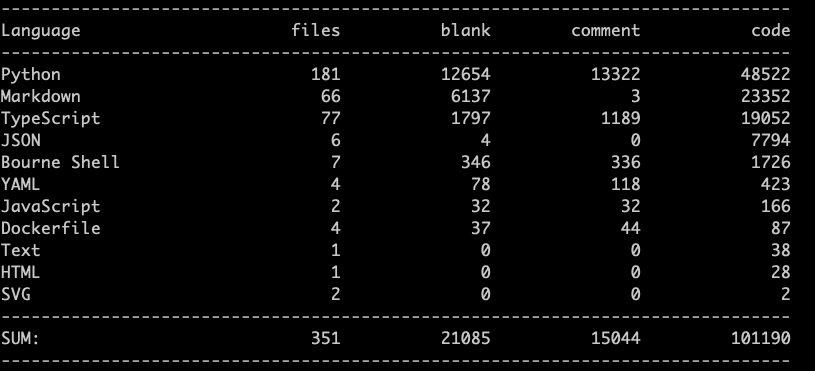
不过Cursor这个统计并不完全准确,因为除去Curosr还有不止2w行的文档和代码来自Claude CLI。但简单来看,即便Cursor有着所谓高达93.9%(334713/356439)行的Accept Rate,但实际代码却只有可怜的20%多 (8w/35w,而且实际分母应该是远远超过35w行的。剩下的都被git checkout .掉了)
4. 文档:保持纪录
AI三省其身:实现这个功能了吗?有编写测试用例并确保通过吗?有写文档记录下来吗?
对待文档,有三条主要的设计原则:
文档按目录结构存储
docs的目录结构
.├── architecture│ ├── AGENTICA_COMPLETE_ARCHITECTURE.md│ └── PERFORMANCE_ARCHITECTURE.md├── development│ ├── RESOLVED_ISSUES.md├── examples│ └── PENTEST_GUIDE_JUICE_SHOP.md├── features│ ├── agents│ │ ├── MULTI_AGENT_SYSTEM.md│ ├── knowledge│ │ ├── RAG_CHAT_INTEGRATION.md├── guides│ └── USER_MANUAL.md├── HEADER_STANDARDIZATION.md├── operations│ ├── CONFIGURATION_SUMMARY.md│ ├── NATIVE_DEPLOYMENT.md└── todo├── ANTI_HALLUCINATION_IMPROVEMENTS.md├── FEATURE_REQUESTS.md14 directories, 56 files文档按进度状态更新
docs/agent/AGENT_ARCHITECTURE的示例内容

docs/development/RESOLVED_ISSUES的示例内容
功能实现后的文档更新需要比对源代码
对于大型项目而言,使用AI进行文档更新之前,使用工具先获取对应的结果会更加高效。比如让Opus去check code并更新文档时,不如提供一个脚本分析AST结构,再给到Opus去分析脚本输出。对于fastapi做后端的项目,可以通过访问curl http://localhost:8000/openapi.json来获取API接口并作为更新架构的一部分给到AI去分析,相较于大规模的扫描源代码然后持续的auto-compact效果会更好。对于数据库则可以通过eralchemy2实现,eralchemy2 -i postgresql://username:password@localhost:5432/databasename -o /tmp/testing.png
而在编程中日常问AI最多的三句话就是:你实现这个功能了吗?你有编写测试用例并确保通过吗?你有写文档记录下来吗?但有时候效果却并不是那么好,使用Opus时似乎不会遵循每次实现完feature就更新文档的Rule,使用Sonnet时则会严格遵守写完feature就更新文档,但是文档的位置却不对。也算是一个小的bug吧。而且在Cursor中使用Claude Code能够去更新文档,切换为Claude CLI就不会。不知道是代理模型的问题,还是工具的问题。
0x03 实战避坑指南:那些烧掉Token换来的教训
1. 模型接口与编程工具 (Model & Tooling)
模型分级(Model Selection):
⚡️拒绝“降智/弱智”模型:在ReAct Loop中,Tier 1级别(如Opus 4.5/Gemini 3.5 Pro)能完成完整闭环,而Tier2/ Tier3 模型往往只能Loop几轮或者一轮就结束;对于核心逻辑,坚决不使用低智力模型。
⚡️安全场景的适配性:避免使用“道德水准” 较高导致无法进行红队模拟的模型。在渗透场景中,这类任务会被模型拒绝的;
对抗幻觉(Anti-Hallucination):
⚡️HITL (Human-in-the-Loop) :关键步骤必须引入
ask_human强制人工介入。但需要注意:由于AI输出的不稳定性,返回的指令可能是ASK_HUMAN或ask_human,代码中需要统一lower()处理,否则会导致前端弹窗失败;⚡️Honesty Agent:引入独立的“诚实监督代理”,采用Direct(一轮)模式开启独立会话,专门用于校验工具输出与模型响应逻辑的一致性,防止瞎造数据;
⚡️Fact Verify: 简单的正则表达式,在HITL和Honesty Agent之前用来检测数据的实体对应的格式;
工具差异:
⚡️SDK鉴权差异:使用官方模型与第三方代理时,SDK传参往往不同。例如Claude原厂使用
ANTHROPIC_API_KEY,而某些代理商给的SK则需要通过ANTHROPIC_AUTH_TOKEN传参;⚡️Claude CLI 的“默认回退”:在Claude CLI中即便选择了Opus模型,在连接到Cursor IDE后通过ClaudeCode界面时仍可能静默回退到Default模型(使用Sonnet或Haiku)。需要多次强制确认配置,否则可能会导致代码质量突然下降。
⚡️Embedding兼容性:不同模型(OpenAI/Gemini/Qwen)提供的Embedding Chunk Size不同,切换AI Model Provider时须做兼容性测试。
⚡️模型工具的知识时效性:模型的数据知识有限,无论是Anthrropic家,Google家,在产生AI Model Provider得代码时往往预设的是Gemini 1.5 pro,GPT3o之类,不知道使用最新的模型参数。同时,Claude CLI在实现集成Anthrpoic的代码时,最为费力。不是忘了Header头,就是忘了参数。(这个也可能是和代理模型有关)
2. 数据流与交互 (Data Flow & Interaction)
结构化输出(Structured Output):
⚡️严禁直接执行字符串:绝不建议直接使用LLM输出的字符串作为命令执行。LLM 拼接的JSON极易出现多次转义问题。必须强制要求 Structure Output(e.g. Pydantic对象),并进行严格过滤。让LLM做填空题;
⚡️格式归一化:不同模型对同一Prompt的输出格式千差万别。前端渲染前,必须在中间层实现格式清洗(Formatter),确保UI行为一致。或者插入特定的symbol,emoji都可以,用来截断和格式清洗;
数据打通(Data Fabric):
⚡️组件间流通:平台内部组件(MCP Server, RAG Storage, Chat)之间的数据孤岛问题,建议通过OSS(对象存储)构建Data Fabric来打通。 例如⚡️Remote Terminal MCP Server需要通过OSS存储才能拉取到chat中上传的文件(这个是因为之前Platform和红队Infra部署在不同的Server上)
技术选型的 ROI
⚡️要简洁优雅架构:在组件选型时,优先选择简单易扩展的产品(如 Qdrant),而不是部署复杂的庞然大物(如 Milvus)。后者可能让你花费100美元实现特性和调试集成Bug,然后第二天又得花费50美元回退代码。而对Qdrant的file based存储,就能实现在2k-2w个数量的文档中实现50ms内的查询。
3. 环境与性能 (Environment & Performance)
开发环境一致性 (DevOps):
⚡️Docker 路径挂载:本地Dev与远程Docker环境经常出现路径不一致。务必检查Volume挂载路径,或通过Data Fabric解耦文件依赖。(不过我现在已经更换成Native Deployment了,仅把DB用docker起服务);
构建陷阱:警惕
npm run dev正常但npm run build报错的情况。远程部署时,务必使用docker compose build --no-cache避免旧缓存导致的神秘Bug…..⚡️运行时版本:Ubuntu默认Node.js为18.x,若前端依赖22.x,Native 部署时必须先安装 NVM。且AI编写的Start脚本往往忽略
pip install或npm install的网络失败,需要教 AI 增加错误检查逻辑。在运维类脚本的实现过程中,Vibe Coding的出错率大的惊人,或者说兼容性一般。无论是init let’s encrypt的shell脚本,还是起system services,还是web服务文件目录的权限,以及服务用户的权限配置等。相较而言,docker部署能够杜绝掉这些问题。性能优化的悖论:
⚡️Gzip vs SSE:优化后端性能时,开启Gzip压缩会由网关缓冲数据,导致SSE流式输出失效,前端对话出现严重的“卡顿感”。流式业务不建议开启 Gzip。 (也可能是我配置错误了)
⚡️缓存覆盖风险:引入React Query缓存后,需警惕过期数据覆盖新数据。例如点击重命名Chat后,前端30秒的自动缓存可能瞬间将新名字覆盖回旧名字。
⚡️跑分里的高分低能:跑性能测试,显示前端代码Best Practice评分达到100分,Performance只有25分。代码规范不等于运行时性能,必须以真实加载时间为准。
0x03 总结
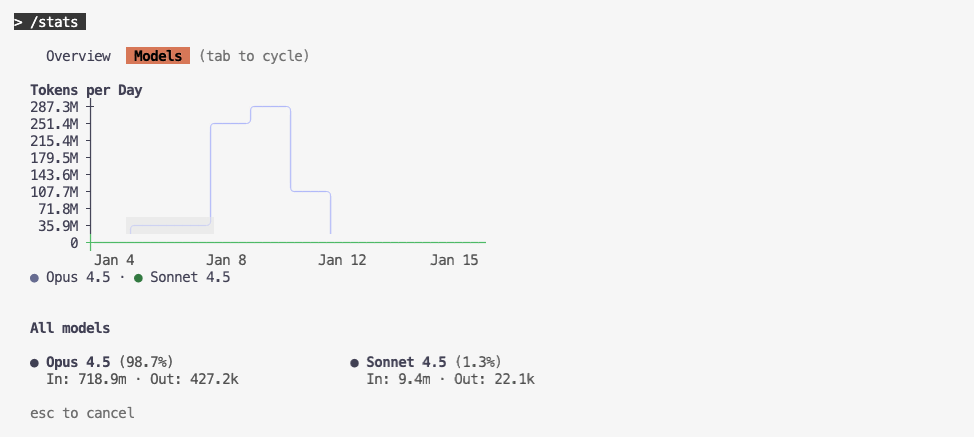
回顾Cursor的2025年度报告,我消耗了约700M Token。除去其中100M用于几个“玩具”Demo的,剩下的绝大部分Token都熔铸进了Agentic SOC平台的构建中(主要消耗在Gemini-3-Pro上)。项目初期,我粗略测算过构建框架的成本,3-5元/行代码;而后期在功能填充实现时的成本大约是0.5元/行,至于文档编写,成本更是低至0.1元/行。
在Token计费的时代,每一次对话本质上都是在支付💲。架构设计的优劣,也直接决定了你是把钱花在刀刃上,还是烧在无效的上下文里。
其次作为Cursor Ultra用户,我不得不吐槽其近期的更新策略。频繁的Update & Install带来的没看到功能的飞跃,而是使用习惯的的破坏——Agent和文件夹的看板在左右侧反复横跳,侧边栏折叠逻辑也是改来改去。这也引出了另一个关于工具选型的教训:不要盲目囤积AI Coding的会员。 我曾图便宜订阅了Trae的年费会员,同样的Prompt,声称使用“同样的模型”,却生成了完全不在一个Level的代码。这也从侧面说明,在AI基础设施层,“便宜”往往意味着模型能力的静默降级。对于使用者而言,识别工具的真实能力比收集Logo更重要。而浪费在便宜的工具上最后则消耗了更珍贵的时间和精力。
AI时代,10倍工程师进化为100倍工程师不再是神话。但这也有一个前提:必须具备对输出结果的鉴别判断能力”。如果没有软件工程的约束,投入再多的Token也产不出企业级产品。我从不焦虑被AI淘汰,因为我知道LLM迭代得越快,对领域知识和架构决策力的要求反而越高。投入才有产出,持续深耕专业领域,学习、实践并输出,才能更经得起检验。
参考
参考链接微信排版不显示:可点击访问原文查看或
https://fz.cool/ai-software-engineing-with-project-agentic-soc-design-and-implement/
- MCP 安全“体检” | AI 驱动的 MCP 安全扫描系统
AI for 安全攻防:自动化渗透 Agent 的工程设计与实践(Agent Pattern Graph 与 Meta-Tooling)
This Buzzy Cyber Startup Wants to Take On Dangerous AI Threat
AI编程实践总结
软件工程实践:以Python为例
从删库到跑路:我的Python全栈踩坑实录
codeguide
Claude Agent Skills
Use Claude Code in VS Code
AI coding 智能体设计
声明:本文来自放之,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
