引言
2026 年,AI Agent 正以前所未有的速度从"对话玩具"演变为企业的核心基础设施。它们不再只是接收 prompt 返回文本的 LLM wrapper,而是长出了读写文件系统、执行终端命令、调用内部 API、管理密钥和设备配对的能力。
当这类高权限的 AI 基础设施开始规模化部署时,安全团队面临一个根本性的范式转换:目标不再是 Web 应用或数据库,而是一个能够自主决策、拥有极高控制面价值的智能编排网关。
本文聚焦一个极具代表性的具体产品——OpenClaw,从它的心脏ACP(Agent Client Protocol)端口入手,系统性地展示如何在未授权条件下利用协议语义特征进行精准暴露面测绘,并在授权条件下验证内部编排机制的真实行为。
01 什么是 ACP?OpenClaw 又是如何“魔改”它的?
ACP(Agent Client Protocol)是 Zed Industries 提出的一种标准化协议,主要用于 AI Agent 与代码编辑环境的通信。设计初衷很简单:为 IDE(如 VS Code)与本地 Agent 进程(如 Claude Code)之间提供一个统一的 JSON-RPC 通信格式。可以把 ACP 理解为"AI Agent 的 HTTP"——它定义了消息怎么发、会话怎么管、工具调用怎么走。
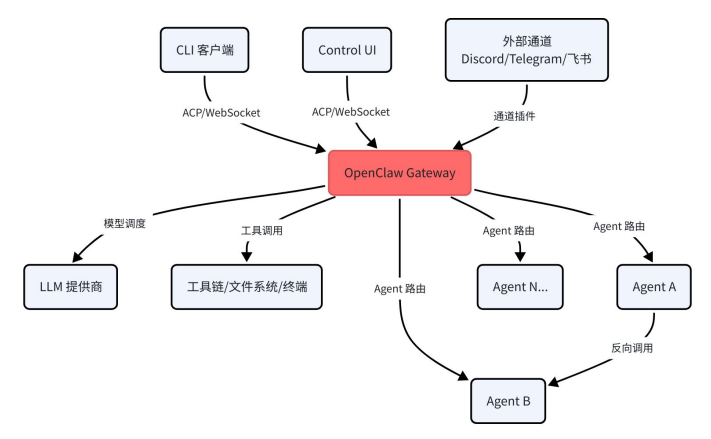
在传统的标准范式中,ACP 主要是为了“IDE 与本地 Agent 进程”单向通信而设计的。但 OpenClaw 的野心不止于此,它对 ACP 进行了深度的“魔改”与扩充。其设计目标远超"IDE ↔ 本地 Agent"的范畴。它将 ACP 扩展为一个多 Agent 编排网关,并在其上构建了完整的设备管理、通道桥接和工具调度体系。
在 OpenClaw 的架构中,ACP 呈现出几个非常关键的特殊性:
双层桥接架构(Bridge & Gateway):OpenClaw 表面上通过 ACP 接收客户端请求,但内部实际上会将请求翻译并转发到自己的 Gateway,再由 Gateway 去调度真正的模型或工具。
多 Agent 调度(Multi-Harness):OpenClaw 可以同时挂载多个 Agent,并利用 ACP 反向调用外部 Agent 进行工作流接力。
会话的持久化与线程绑定:传统 ACP 断开即丢失,而 OpenClaw 的 ACP 会话可以持久化存储,并且能与 Discord、Telegram 等外部通道的频道/用户进行线程绑定。
同时,OpenClaw 在 WebSocket 连接之上叠加了多因子认证:Gateway Token、设备签名(Ed25519)、Bootstrap Token、Tailscale 身份等,形成了严格的零信任接入策略。简而言之:在 OpenClaw 的语境下,ACP 已经从一个本地开发协议,升级为进入整个多 Agent 编排体系的"远程控制总线"。
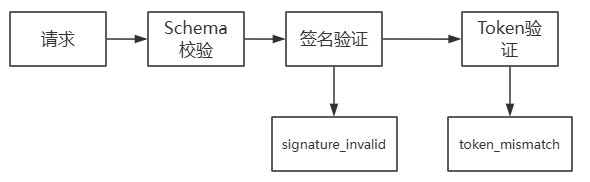
02 未授权暴露面探测:四层协议指纹
传统的资产测绘依赖端口扫描和 HTTP 响应中的特征字符串(如匹配 openclaw 关键字)。这种方法的局限性很明显:修改默认端口、套反向代理、换自定义路径就能让扫描器"变瞎"。
我们的思路是从字符串匹配升级为协议语义探测——利用 WebSocket 协议本身的行为特征来识别目标。
⚠️ 认证要求说明:
指纹 1、2、4:完全无需认证✅
指纹 3:需要认证后才能进行⚠️
指纹 1
被动握手特征 — connect.challenge
项目 | 内容 |
认证要求 | 无需认证 ✅ |
探测方式 | 对目标发起 WebSocket 连接(默认路径 /ws),什么都不用发 |
指纹类型 | 被动指纹(服务端主动推送) |
响应示例:
{"type": "event","event": "connect.challenge","payload": {"nonce": "550e8400-e29b-41d4-a716-446655440000","ts": 1774000000000}}
特征要素:
字段 | 值/格式 | 说明 |
event | 固定为 connect.challenge | 事件类型标识 |
payload.nonce | UUID v4 格式 | 随机数,用于后续认证 |
payload.ts | 毫秒级 Unix 时间戳 | 时间戳,用于防重放 |
测绘价值:
100% 确认目标身份 — connect.challenge是 OpenClaw 特有的握手消息
完全被动 — 无需发送任何载荷,不存在误触发风险
无法规避 — 即使更换 WebSocket 路径,只要连接成功就会触发
极其隐蔽 — 不会在目标日志中留下请求记录
指纹 2
认证拒绝响应
项目 | 内容 |
认证要求 | 无需认证 ✅ |
探测方式 | 连接建立后发送任何缺少凭证的请求帧 |
指纹类型 | 主动指纹(需要发送请求) |
响应示例:
缺少凭证时:
{"type": "res","id": 1,"ok": false,"error": {"code": -32600,"message": "unauthorized: gateway token missing (open the dashboard URL and paste the token in Control UI settings)"}}
Token 位置错误时:
{"error": {"message": "invalid connect params: at /device: unexpected property "token" "}}
特征要素:
信息类型 | 特征值 | 说明 |
产品身份 | gateway token、Control UI settings | OpenClaw 特有术语 |
认证架构 | 区分 CLI 和 Control UI 场景 | 多客户端支持 |
Schema 校验 | unexpected property "token" | 严格的 JSON Schema 校验 |
测绘价值:
确认产品身份 — gateway token、Control UI settings 是 OpenClaw 特有术语
推断认证架构 — 区分 CLI 和 Control UI 两种客户端场景
确认 Schema 机制 — 网关使用严格的 JSON Schema 校验,且校验发生在认证之前
指纹 3
Schema 分层校验
项目 | 内容 |
认证要求 | 需要认证 ⚠️(未认证状态下直接调用业务方法会被 handshake 校验拦截) |
探测方式 | 认证后,向业务方法发送包含额外字段的请求 |
指纹类型 | 主动指纹(需要认证后发送请求) |
未认证时的响应:
{"type": "res","id": "...","ok": false,"error": {"code": "INVALID_REQUEST","message": "invalid handshake: first request must be connect"}}
认证后的探测:
向 chat.history 方法发送一个包含 Discord 风格 sessionKey 但掺杂了多余 agentId 字段的请求
请求:
{"type": "req","id": "test-id-456","method": "chat.history","params": {"sessionKey": "agent:main:discord:channel:12345","agentId": "main","limit": 10}}
响应:
{"type": "res","id": "test-id-456","ok": false,"error": {"code": "INVALID_REQUEST","message": "invalid chat.history params: at root: unexpected property "agentId""}}
特征要素:
观察点 | 现象 | 说明 |
未认证请求 | 被 handshake 校验拦截 | 业务方法需要先认证 |
agentId 字段 | 报错 unexpected property | 该字段不在 Schema 中 |
sessionKey 格式 | 静默接受 | 格式语法合法 |
测绘价值:
确认处理链路 — 请求需经过 WebSocket 帧解析 → RPC 方法路由 → Agent 级参数校验
确认 Schema 独立性 — 不同方法的 Schema 是独立定义的
推断 sessionKey 格式 — agent:名称:平台:类型:ID 被 Schema 层接受
这种通过"故意触发 Schema 异常"来探测内部结构的手法,本质上是一种安全的协议级 Fuzzing——不触碰业务逻辑,仅利用校验层的错误回显来逆向推导 API 定义。
指纹 4
认证模式枚举
项目 | 内容 |
认证要求 | 无需认证 ✅ |
探测方式 | 系统性遍历不同认证方式,观察错误响应 |
指纹类型 | 主动指纹(需要发送请求) |
经多次实验即对源码的分析发现错误响应主要有两种:
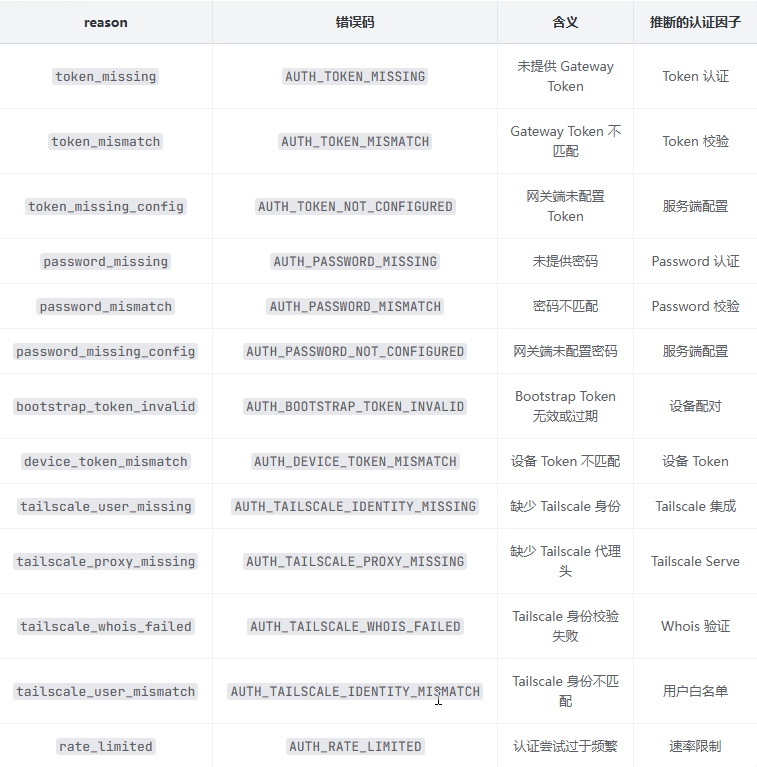
AUTH* 系列(共享密钥认证)
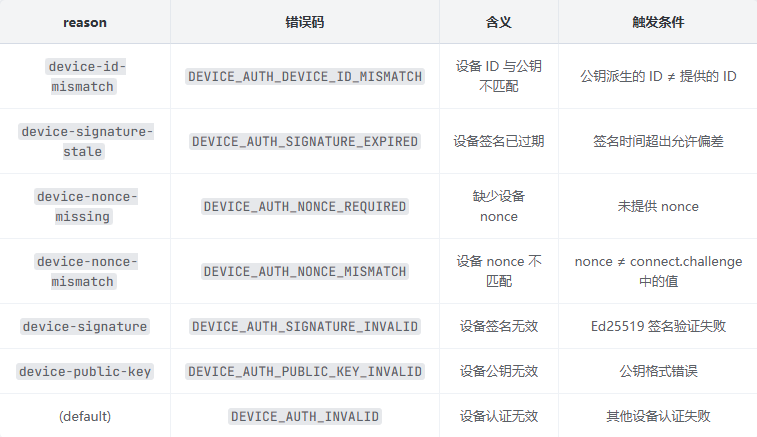
DEVICE_AUTH* 系列(设备身份认证)
AUTH* 系列(共享密钥认证):
举例:
{"error": {"message": "unauthorized: gateway token mismatch"}}
DEVICE_AUTH* 系列(设备身份认证):
举例:
{"error": {"message": "device signature invalid"}}
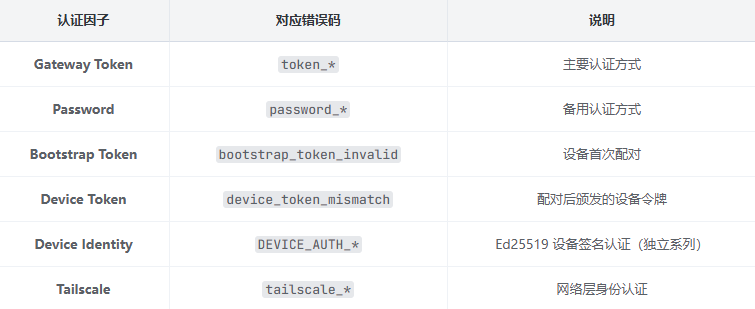
其对应的认证因子主要有以下几种:
测绘价值:
完整认证架构地图 — AUTH* 系列:13 种错误原因;DEVICE_AUTH* 系列:7 种错误原因;6 种认证因子
确认防护机制 — 存在速率限制(`rate_limited`);设备签名有时效性(device-signature-stale);nonce 防重放(device-nonce-mismatch)
确认设备配对机制 — 设备身份认证(DEVICE_AUTH*);共享密钥认证(AUTH*);设备签名验证优先于 token 验证
03 在野资产测绘:双轮验证实验
前面介绍的四层协议指纹,从理论层面展示了如何利用 ACP 协议的语义特征识别 OpenClaw 实例。但一个关键问题仍然存在:这些指纹在真实网络环境中是否真的有效?
为了回答这个问题,我们设计了两轮在野验证实验,分别针对高噪声混合样本和大规模确定资产进行测试。
实验设计:
项目 | 说明 |
测试对象 | 对比"ACP 协议语义指纹"(新方案)与"传统 HTTP 字符串匹配"(旧方案) |
评估指标 | 命中率、一致性、互补性(仅单一方案命中的数量) |
实验环境 | 基于 Python WebSocket 客户端实现 ACP 握手探测 |
实验数据总览:
指标 | 第一轮(混合样本) | 第二轮(确定资产) |
总目标数 | 78 | 954 |
不可达 | 22 | 520 |
可达 | 56 | 434 |
ACP 指纹命中 | 14 | 418 |
传统 HTTP 命中 | 30 | 428 |
两者共同命中 | 10 | 415 |
仅 ACP 命中 | 4 | 3 |
仅传统 HTTP 命中 | 20 | 13 |
可达但都未命中 | 22 | - |
第一轮分析:公网混合样本
第一轮测试的目标来自公网混合资产池,包含大量噪声(前端页、代理页、品牌页等),模拟真实测绘场景中的高干扰情况。
实验结果显示,旧方案命中 30 个目标,其中有一部分是"相关页面线索"(如官网、文档站、社区页),而非真实的 ACP 网关。新方案命中 14 个,数量虽少,但直接对应 WebSocket 层的真实 ACP 端点,精度更高。
关键发现:在 56 个可达目标中,有 4 个仅被 ACP 指纹识别,传统 HTTP 方法完全遗漏。这 4 个目标经人工验证,确认为真实 OpenClaw 实例。
结论:在高噪声环境下,新旧方案定位角度不同——旧方案偏广覆盖,新方案偏高精度。新方案能有效发现隐藏或非标准部署的真实网关。
第二轮分析:确定资产大规模验证
第二轮测试的目标来自公开的 OpenClaw 测绘网站爬取结果,属于"已知确定资产",用于验证新方案在大规模样本上的稳定性。
基于 434 个可达端点的统计:
ACP 指纹命中率:418 / 434 = 96.3%
传统 HTTP 命中率:428 / 434 = 98.6%
两者一致命中:415 / 434 = 95.6%
数据显示,两套方案在大规模样本上高度一致,新方案稳定性验证通过。同时,仍有 3 个端点仅被 ACP 指纹发现,说明即使在确定资产中,协议语义探测仍具备补充价值。
结论:新方案在大规模样本上表现稳定,与传统方法一致性超过 95%,且仍能覆盖部分传统盲区。
验证结论:
综合两轮实验,我们得出以下结论:
协议语义指纹在真实环境中有效且稳定 — 在大规模确定资产上达到 96.3% 命中率,与方案一致性超过 95%。
能发现传统 HTTP 方法的漏网之鱼 — 第一轮捡漏 4 个,第二轮补充 3 个,累计 7 个目标仅被 ACP 指纹识别。
两套方案定位角度不同,应配合使用 — 传统方法覆盖广(适合初筛),ACP 指纹精度高(适合确认真实网关)。在实际测绘中,建议先 HTTP 初筛,再 ACP 复核,以提高识别准确性和覆盖完整性。
这组实验揭示了一个重要事实:在 AI Agent 基础设施测绘中,传统的 HTTP 字符串匹配已经不够用了。当目标刻意隐藏 Web 前端或使用非标准路径时,只有深入协议层的语义探测才能揭开真相。
04 授权后深层探测:内部控制面的暴露与风险评估
前面的四层指纹已经足够完成高置信度的暴露面测绘。但为了验证 OpenClaw 作为"编排器"的深层协议特征,我们在实验室环境中完成了 Ed25519 设备签名与 Token 认证,进行深层语义探测。
⚠️ 注意:以下实验均在自有 OpenClaw 实例上完成,不涉及任何第三方目标。
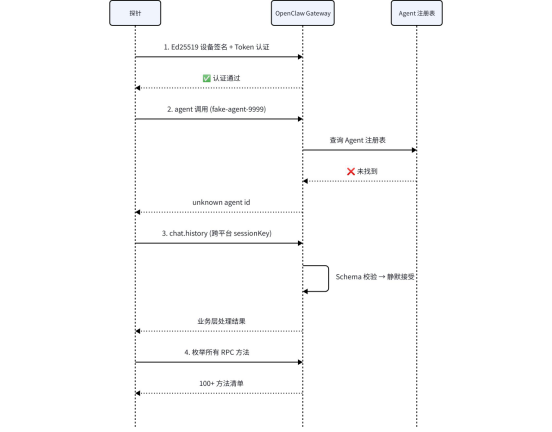
实验 1
多 Agent 路由表验证
项目 | 内容 |
实验目的 | 验证 OpenClaw 内部是否维护 Agent 注册表 |
前提条件 | 已完成认证 |
假设:
作为编排器,OpenClaw 内部必然维护着一个 Agent 注册表,用于将 agent 请求路由到正确的 Agent。
验证方法:
向网关发送指向不存在 Agent 的调度请求:
{"type": "req","id": "...","method": "agent","params": {"idempotencyKey": "...","agentId": "fake-agent-9999","method": "health","params": {},"timeout": 10000}}
响应结果:
{"type": "res","id": "...","ok": false,"error": {"code": "INVALID_REQUEST","message": "invalid agent params: unknown agent id \\"fake-agent-9999\\""}}
分析结论:
结论 | 依据 |
存在 Agent 注册表 | 系统精确报告"未知 Agent ID"而非通用错误 |
路由层有存在性校验 | 未注册的 Agent ID 会被拒绝 |
请求处理链路 | WebSocket 帧解析 → RPC 方法路由 → Agent 级参数校验 |
实验 2
Agent 身份伪造防护验证
项目 | 内容 |
实验目的 | 验证是否可以通过伪造 Agent ID 劫持任务 |
前提条件 | 已完成认证 |
假设:
既然存在 Agent 路由表,那么是否可以通过伪造 Agent ID 来欺骗调度层,将任务劫持到恶意 Agent?
验证方法:
构造包含自定义 agentId 的请求,尝试调用不属于自己的 Agent:
{"type": "req","id": "...","method": "agent","params": {"agentId": "nonexistent-harness","message": "hello","idempotencyKey": "uuid-here"}}
响应结果:
{"type": "res","id": "...","ok": false,"error": {"code": "INVALID_REQUEST","message": "invalid agent params: unknown agent id \\"nonexistent-harness\\""}}
分析结论:
结论 | 依据 |
采用白名单校验 | 只有已注册的 Agent 才能被调度 |
有效防止伪造攻击 | 未注册的 ID 会被直接拒绝 |
⚠️ 潜在信息泄露 | 错误响应返回完整 Agent ID,可能暴露内部命名规范 |
实验 3
会话持久化语义探测
项目 | 内容 |
实验目的 | 验证 sessionKey 格式和跨平台会话绑定能力 |
前提条件 | 已完成认证 |
假设:
OpenClaw 原生支持跨平台会话绑定,sessionKey 中应包含通道类型和标识符。
验证方法:
向 chat.history 发送包含不同平台特征 sessionKey 的请求:
sessionKey: agent:main:discord:channel:12345sessionKey: agent:main:telegram:chat:67890sessionKey: agent:main:feishu:chat:oc_xxxsessionKey: agent:main:qqbot:direct:abc123
响应结果:
网关对这些 sessionKey 的处理行为一致:
Schema 校验通过(仅检查非空)
业务层根据实际是否存在对应会话返回结果或空结果
没有任何一个被拒绝为"格式非法"
分析结论:
结论 | 依据 |
sessionKey 格式合法 | agent:名称:平台:类型:ID 被 Schema 层静默接受 |
支持跨平台绑定 | 不同平台的 sessionKey 使用统一格式规范 |
独立子系统 | 会话管理与 Agent 调度是两个独立的子系统 |
实验 4
内部 RPC 方法全景枚举
项目 | 内容 |
实验目的 | 获取完整的 RPC 方法清单和风险评估 |
前提条件 | 已完成认证 |
假设:
OpenClaw 作为编排网关,暴露了大量 RPC 方法,其中可能存在高风险方法。
验证方法:
在授权状态下,通过分析网关的方法路由表和事件订阅列表。
响应结果:
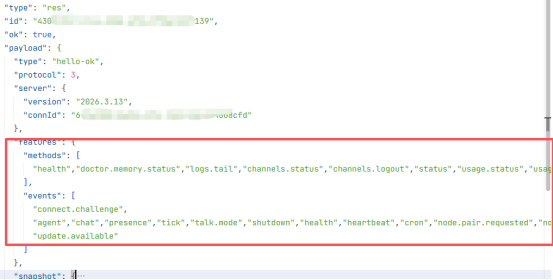
通过对源码的分析,发现其主要分为13类:系统诊断、配置管理、模型工具、Agent 管理、会话管理、对话交互、命令执行、设备管理、节点控制、定时任务、凭证管理、系统更新、通道插件。
方法分类(13 类,100+ 方法):
类别 | 方法示例 |
系统诊断 | health, status, doctor.* |
配置管理 | config.get, config.set, config.patch |
模型工具 | models.list, tools.*, tts.* |
Agent 管理 | agents.list, agents.create, agents.delete |
会话管理 | sessions.list, sessions.delete, sessions.compact |
对话交互 | chat.history, chat.send, agent |
命令执行 | exec.approval.* |
设备管理 | device.pair.*, device.token.* |
节点控制 | node.invoke, node.pair.*, node.list |
定时任务 | cron.add, cron.remove, cron.list |
凭证管理 | secrets.resolve, secrets.reload |
系统更新 | update.run, wizard.* |
通道插件 | channels.*, send, browser.* |
高风险方法清单(14 个):

分析结论:
结论 | 依据 |
方法总数 100+ | 涵盖系统控制的全生命周期 |
存在严重风险方法 | exec.run, node.invoke, cron.add, credential.get |
可动态扩展 | 通道插件可动态注册方法 |
认证后完全暴露 | 服务端在认证响应中主动返回完整方法列表 |
05 攻击面总结与威胁模型
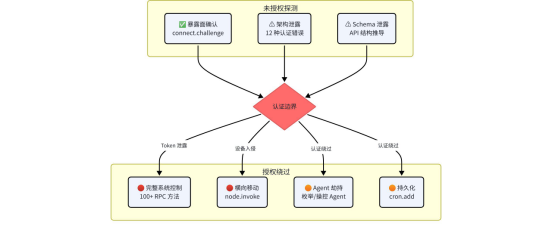
基于上述四层指纹和四项授权后实验,我们可以为 OpenClaw 的 ACP 暴露面绘制一个完整的威胁模型:
5.1
未授权场景(公网暴露)
风险等级 | 攻击面 | 描述 |
高 | 暴露面确认 | 通过 connect.challenge 被动指纹 100% 确认目标,无法规避 |
中 | 架构信息泄露 | 20种认证错误枚举出完整的认证架构 |
中 | API Schema 泄露 | 通过错误消息推导 API 定义(有限),通过 Schema Fuzzing 推导出内部 API 定义 |
中 | 产品版本指纹 | 错误消息中的术语特征可用于版本/配置推断 |
5.2
认证绕过场景(Token 泄露)
风险等级 | 攻击面 | 描述 |
严重 | 完整系统控制 | 100+ RPC 方法暴露,涵盖配置、凭证、命令执行、设备管理 |
严重 | 横向移动 | node.invoke 可远程调用已配对物理节点执行命令 |
高 | Agent 劫持 | 可枚举并操控已注册的 Agent 实例 |
高 | 持久化后门 | 可通过 cron.add` 植入定时任务实现持久化 |
5.3
核心结论
OpenClaw 的 ACP 端口不是一个简单的"聊天接口",而是一个具备完整系统管理能力的零信任网关。
它的认证机制虽然完善(多因子、速率限制、设备签名),但安全边界完全依赖于认证层的完整性。一旦认证被绕过(Token 泄露、设备被入侵、Bootstrap Token 截获),攻击者获取的不是聊天记录,而是一条能横向移动、能操纵物理节点的完整控制通道。
06 安全建议
针对部署了 OpenClaw 或类似 AI Agent 网关的企业:
建议 | 描述 |
暴露面管控 | ACP 端口不应直接暴露到公网。通过 Tailscale、WireGuard 等 VPN 或反向代理进行访问控制。OpenClaw 原生支持 Tailscale 身份认证,建议作为首选接入方式。 |
认证强化 | 使用高强度随机 Gateway Token;启用设备签名认证;定期轮换设备 Token |
监控与告警 | 将 ACP 端口的异常连接行为纳入监控——频繁连接/断开、大量认证失败、Schema Fuzzing 特征 |
最小权限部署 | 评估是否需要启用所有 RPC 方法,考虑通过配置限制可用方法和 Agent |
错误信息审计 | 定期审计面向客户端的错误响应,评估是否包含可被利用的内部架构信息 |
本次研究揭示了一个值得深思的现象:在 OpenClaw 这样的控制平面系统中,失败响应提供了远比成功响应更多的语义信息。
传统安全思路是隐藏错误细节——报错越模糊越好,以免泄露内部信息。但 OpenClaw 选择了详细的业务级错误回显,源于其开发者体验优先的设计哲学:当用户遇到认证问题时,系统需要精确告诉他"为什么失败"以及"如何修复"。这种设计降低了运维门槛,但在安全视角下,但在安全的视角下,这些详细的错误回显无意中暴露了系统内部逻辑和认证流程。
声明:本文来自M01N Team,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
