工作来源
RAID 2025
工作背景
在威胁情报领域,虽然大家都知道“情报共享”很重要,但行业苦于“非结构化文本(报告PDF/博客文章)”与“结构化机读标准(STIX/TAXII)”之间的巨大鸿沟久矣。
为了实现不同组织、不同安全产品之间的自动化情报共享,OASIS 推出了名为 STIX 的框架,它目前已经成为全球安全行业的事实标准。STIX 2.1 将威胁情报表示为一个有向图,由 STIX 领域对象(SDO,如“攻击者”、“恶意软件”、“漏洞”)、STIX 关系对象(SRO,如“使用”、“利用”、“缓解”)与STIX可观测对象(SCO)组成。
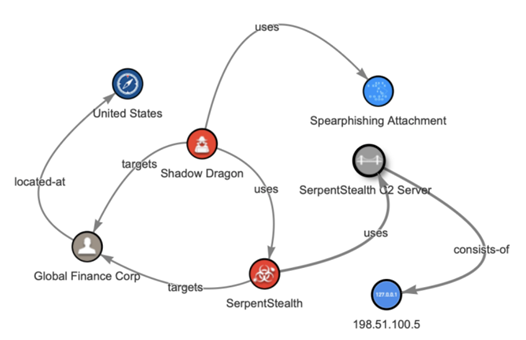
然而,由于威胁情报报告大多是非结构化的自然语言文本,目前将文本转换为 STIX 格式的过程在很大程度上仍然依赖于安全分析人员的手动提取。这个过程极其耗时、容易出错,且根本无法应对每天海量生成的威胁情报报告。
现有的传统自然语言处理(NLP)和深度学习方法在处理复杂的网络安全上下文时往往表现不佳。所以部分企业虽然买支持STIX/TAXII 的系统,但里面流转的往往只有最简单的 IP 和 Hash(变成了IoC 列表)。只有打通了“非结构化文本 -> STIX 图谱”的自动化处理管道,才能真正发挥STIX的价值。
工作准备
目前缺乏可用于训练和评估模型的大规模、高质量的 STIX 标注数据集。为了解决这个问题,研究人员进行了极为严谨的数据工程,构建名为AZERG与AnnoCTRPlus的数据集。其中,AZERG数据集包含11家威胁情报厂商发布的21份分析报告。AnnoCTRPlus数据集包含5家威胁情报厂商发布的120份分析报告。

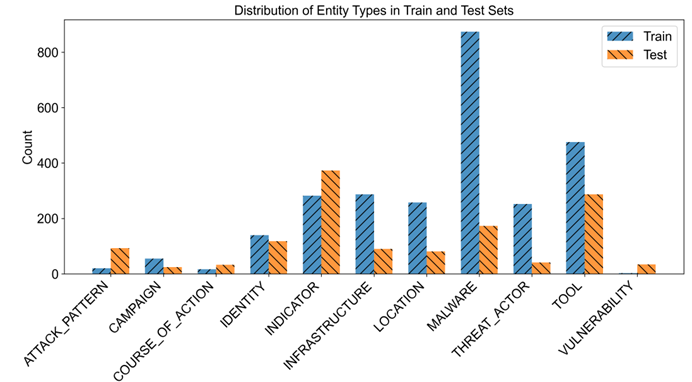
一共提取了11 种主要的 STIX 实体类型(如Attack Pattern, Identity, Intrusion Set, Malware, Tool, Vulnerability 等)和24 种核心关系类型(如 uses, mitigates, targets, exploits 等)。实体类型分布情况如下所示:
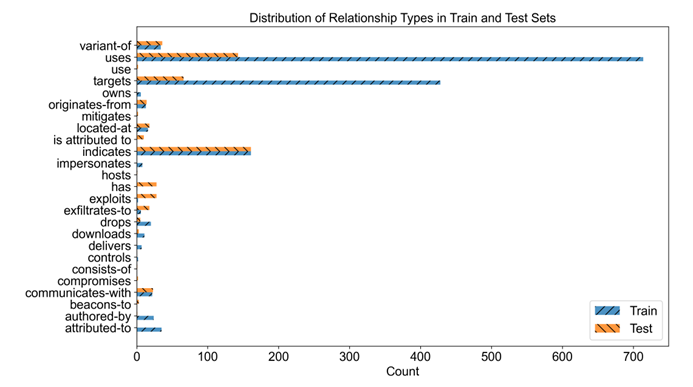
关系分布情况如下所示:
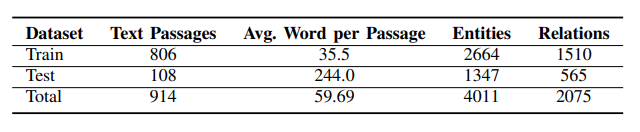
对于文本描述中经常出现重叠的指代,实施了最长字符串匹配策略来消解歧义,并剔除了那些无法在单一段落中找到实体对应关系的数据。训练集和数据集的具体划分如下所示:
工作设计
研究人员设计了一套名为 AZERG 的端到端自动化 STIX 提取系统。为了避免直接让大模型生成复杂 JSON 图谱导致的任务崩溃(幻觉、漏报),将一整个任务拆解成了四个串联的独立 NLP子任务流水线。
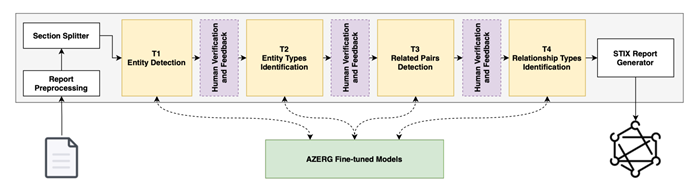
① 实体检测(T1):识别文本中对应 STIX 实体的文本片段,且这一步只找“词”,不分类。
② 实体分类(T2):大模型将上一步给出的实体映射到 14 种 STIX 实体类型中(如判定“Cobalt Strike”属于 Tool 或 Malware)。
③ 关系检测(T3):给定两个已分类的实体,判定它们之间是否存在有意义的语义关系(输出 YES 或 NO),通过这一步来过滤噪音。
④ 关系分类(T4):判定有关联的实体,进一步让大模型从 13 种 STIX 关系中选出最准确的一种(如 uses 或 targets)。

在谷歌的Gemma-2-9B-it、阿里的Qwen2-7B-Instruct、Meta的Llama-3.1-8B-Instruct、上海人工智能实验室的InternLM2_5-7B-Chat、Mistral AI的Mistral-7B-Instruct-v0.3与微软的Phi-3-mini-Instruct中,评估后研究人员选择了开源的 Mistral-7B-Instruct-v0.3。通过 LoRA,研究人员针对处理中的四个独立任务,分别微调训练了四个专属的适配器。
工作评估
微调后的 AZERG与其他大模型进行了全面的对比评估,包括 GPT-4o、原生的 Mistral与其他模型。专门针对每个任务的微调模型和混合微调模型在具体的场景上各有千秋,但整体来说在伯仲之间。从耗时来说,T1任务推理时间最长为2.57秒,其余任务分别为1.54秒、0.58秒、0.36秒,这说明是具备可扩展性的。
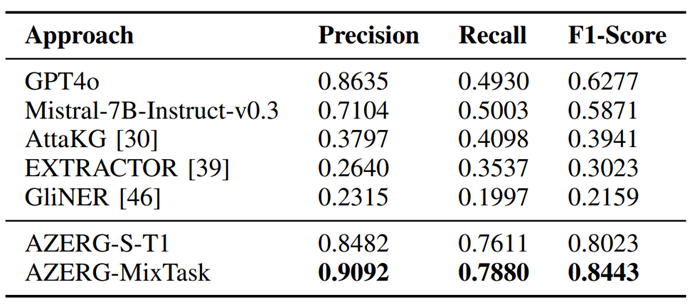
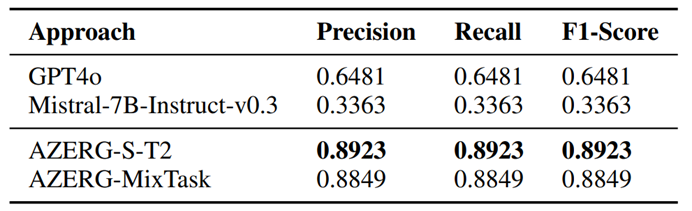
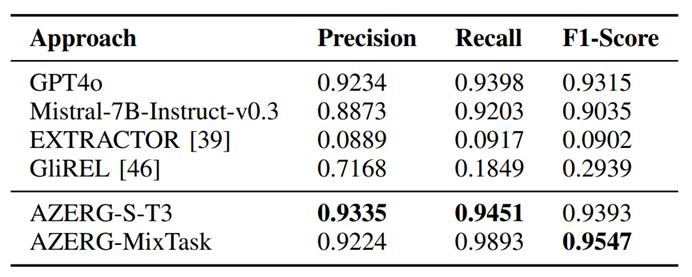
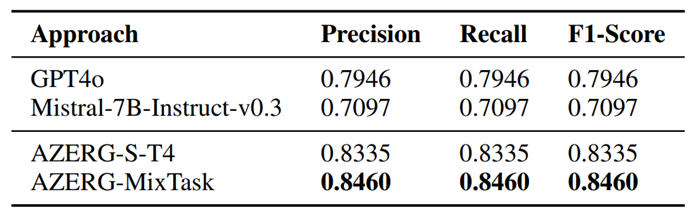
原生大模型经常被网络安全中模糊的术语混淆,导致实体提取错误。例如函数名为MalwareMain,就可能会被错误判断为攻击工具。还包括攻击者与恶意软件同名、行文中相同组织的不同别名、工具和环境本身混淆等。并且单个错误会扩散影响到上下文的其他实体,显著降低了准确率。
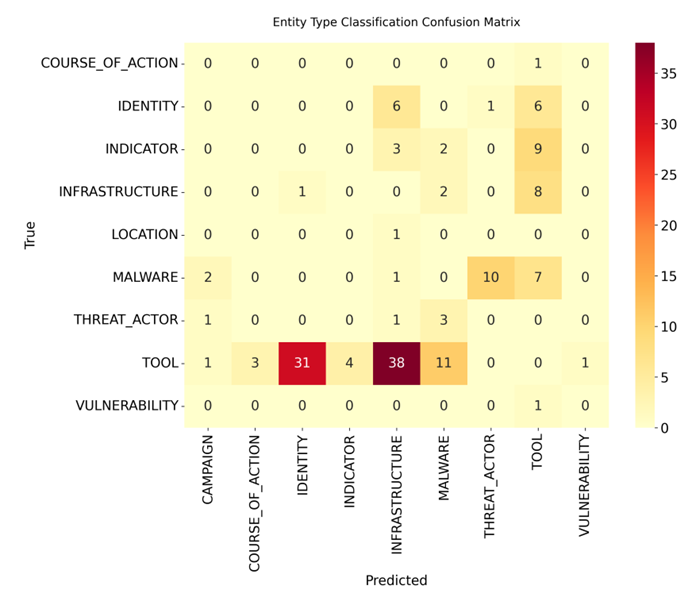
语义相似的关系之间也常常造成混淆,部分错误连分析人员也存在争议。
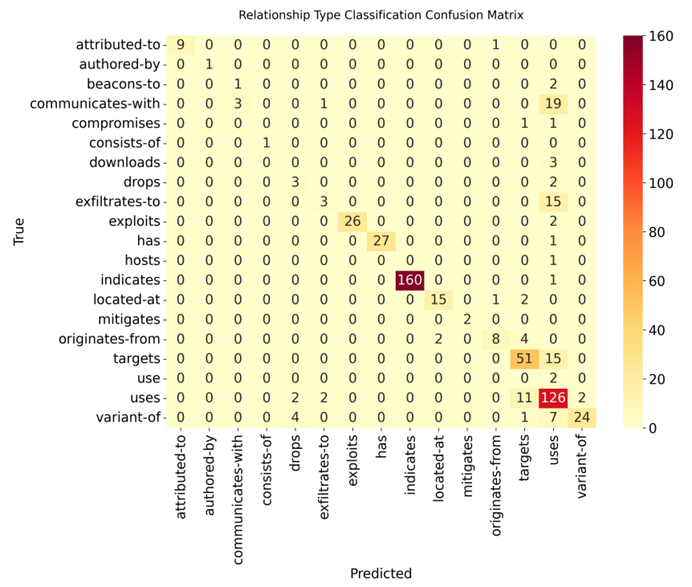
在高度专业化的垂直领域,小模型外加高质量的垂直指令微调可能是一个很不错的方案。不仅在成本上占据绝对优势,在业务准确率上也能追上维度规模大很多的模型的效果。
工作思考
受到上下文的限制,现在只能把文本切割开,这样会导致跨章节、跨段落的关系提取困难,但这也是长上下文场景下分析的共性挑战。
STIX 2.1 规范本身其实就存在一些语义模糊的地方,这也会导致一部分分类错误。这不仅仅是模型的问题,也说明了本体论(Ontology)本身就是很复杂的。
作者将模型与数据集开源放置在HuggingFace上,感兴趣的读者可以自行下载尝试。如7B混合微调模型下载大概15GB,本地可以测试看看情况。
https://huggingface.co/QCRI/AZERG-MixTask-Mistral
声明:本文来自威胁棱镜,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
