基本信息
原文标题:Coverage-Guided Multi-Agent Harness Generation for Java Library Fuzzing
原文作者:Nils Loose, Nico Winkel, Kristoffer Hempel, Felix Mächtle, Julian Hans, Thomas Eisenbarth
作者单位:德国吕贝克大学信息安全研究所(University of Lübeck, Institute for IT Security)
关键词:模糊测试、桩代码生成、大语言模型、多智能体系统、覆盖率引导测试、程序分析、Java
原文链接:https://arxiv.org/abs/2603.08616
开源代码:暂无
论文要点
论文简介:覆盖率引导的模糊测试(Coverage-Guided Fuzzing)是当前软件安全测试领域最为有效的漏洞挖掘手段之一,但将其应用于库代码时,必须依赖高质量的"模糊测试桩代码"(Fuzz Harness)作为中间适配层,将模糊器生成的随机字节序列转化为合法的 API 调用。长期以来,桩代码的编写高度依赖人工,需要开发者深入理解目标 API 的语义、对象初始化顺序以及异常处理契约,这一过程耗时费力,严重制约了模糊测试在 Java 生态中的大规模推广。
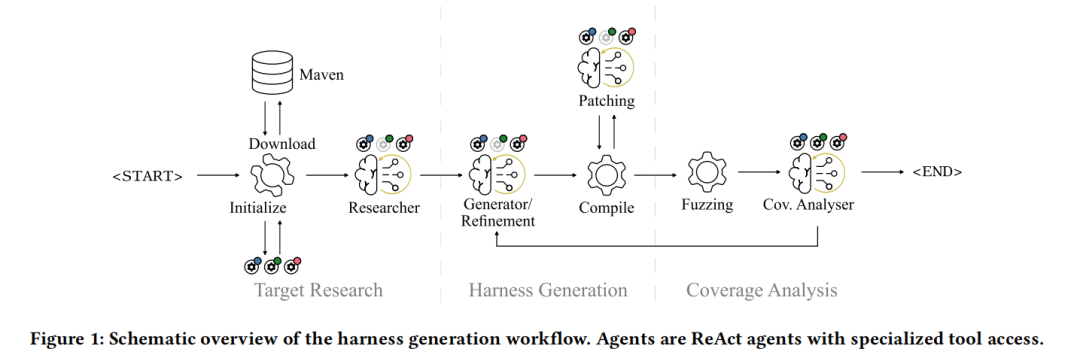
本文来自德国吕贝克大学信息安全研究所,提出了一套基于多智能体架构的 Java 库桩代码自动生成系统。该系统由五个专职 ReAct 智能体协同完成从目标研究、代码合成、编译修复到覆盖率分析与迭代精化的完整工作流,并通过模型上下文协议(Model Context Protocol,MCP)实现按需查询文档与源码,有效规避了上下文窗口饱和问题。论文在六个广泛部署的 Java 库(共超过 115,000 个 Maven 依赖项)的七个目标方法上进行了评估,生成的桩代码在方法级覆盖率上比 OSS-Fuzz 基线提升了中位数 26%,在全包范围覆盖率上比 JazzerAutoFuzz 高出 5%,平均生成成本仅为 3.20 美元、耗时约 10 分钟,并在 12 小时模糊测试活动中发现了 3 个此前未被报告的真实漏洞。
研究目的:本研究的核心目标是解决 Java 库模糊测试中桩代码生成的自动化难题。现有方法要么依赖大量消费者代码语料(Usage-based),要么仅从类型签名推导(Structure-based),要么采用固定阈值终止迭代(Feedback-driven),均存在明显局限。本文希望构建一套无需人工干预、无需消费者代码语料、能够语义化解读覆盖率反馈并自适应终止的端到端自动化系统,使高质量桩代码的生成成本降低到可集成进持续模糊测试工作流的实用水平。
研究贡献:本文的核心贡献体现在四个层面。
第一,提出了一套将大语言模型推理与程序分析深度融合的多智能体架构,能够在不依赖消费者代码语料或人工干预的前提下,为 Java 库 API 自动生成模糊测试桩代码。
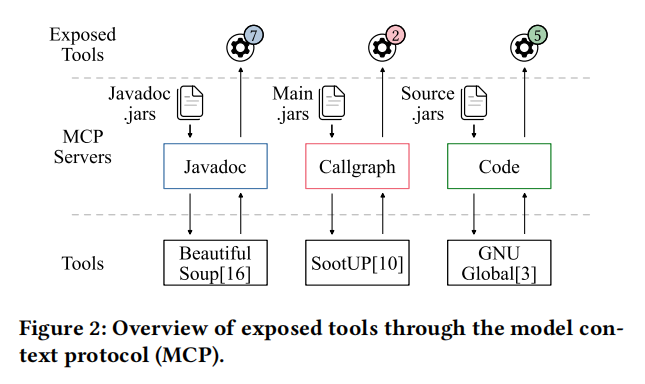
第二,设计了基于模型上下文协议的按需查询工具接口,能够精确检索预分析的程序信息,在探索大型代码库的同时防止上下文饱和。
第三,引入了方法级覆盖率插桩机制与智能体引导的终止策略,通过源码分析解读覆盖率缺口,而非依赖固定数值阈值,从而实现有效的精化迭代。
第四,在广泛部署的 Java 库上完成了实证验证,证明了与人工编写基线相当的覆盖率水平、实用的生成成本,以及三个此前未被报告漏洞的发现能力。
背景与动机
模糊测试作为一种通过向程序输入大量随机或变异数据来触发异常行为的测试技术,已在 C/C++ 生态中取得了显著成果,Google 的 OSS-Fuzz 平台更是将其推向了持续集成的工程实践层面。然而,Java 库在这一领域长期处于边缘地带。究其原因,Java 库的 API 往往具有复杂的对象初始化序列、隐式前置条件和精细的异常处理契约,手工编写一个能够有效驱动模糊器深入探索目标方法的桩代码,需要开发者投入大量时间研读 API 文档与源码,这一门槛使得大多数 Java 库无法获得充分的模糊测试覆盖。
现有的自动化桩代码生成方法可以归纳为三类,但各有其根本性局限。基于使用模式的方法(Usage-based)从现有消费者代码或单元测试中挖掘 API 调用模式,能够捕捉真实的交互习惯,但对于新发布或专用库而言,往往缺乏足够的消费者代码语料。基于结构的方法(Structure-based)直接从类型签名和接口规范推导桩代码,适用范围更广,但难以处理隐式前置条件,且通常依赖领域特定的启发式规则,泛化能力有限。基于反馈的方法(Feedback-driven)利用运行时信号迭代精化桩代码,思路最为接近本文,但普遍采用固定的覆盖率阈值作为终止条件,缺乏对覆盖率缺口的语义理解,容易在无效迭代上浪费资源。
大语言模型的兴起为桩代码生成带来了新的可能性,但直接应用 LLM 同样面临挑战:预处理整个 API 表面会耗尽有限的上下文窗口;一次性生成对于需要多步初始化的复杂库往往失败;基于覆盖率的精化在缺乏语义解读机制时容易产生语义漂移。这些观察共同指向一个核心需求:有效的桩代码生成需要将 LLM 推理与有针对性的程序分析相结合,按需检索信息而非预处理整个代码库,并对覆盖率反馈进行语义化解读而非应用固定数值阈值。
多智能体桩代码生成架构
本文提出的系统以五个专职 ReAct 智能体为核心,将桩代码生成工作流分解为研究、合成、编译修复、覆盖率分析和精化五个阶段,每个智能体通过模型上下文协议按需查询文档、源码和调用图信息,在探索复杂依赖关系的同时保持聚焦的上下文。
工作流的起点是静态分析与插桩预处理阶段。系统首先从 Maven 制品附带的 Javadoc HTML 档案中提取 API 文档,使用 BeautifulSoup 解析方法签名和参数描述,为智能体提供可按需查询的简洁 API 契约索引。其次,使用 GTAGS 对源码建立索引,支持高效的符号解析与上下文检索。最后,使用 SootUp 的类层次分析(CHA)构建以目标方法为根的静态调用图,遍历深度为 10(大型库为 5),每个节点记录方法签名、所属类和距目标的距离,用于将覆盖率分析范围限定在可达方法集合内。
在此基础上,系统引入了方法级覆盖率插桩这一关键技术创新。标准覆盖率插桩会测量所有执行代码,这会产生一种错误激励:智能体可能倾向于调用与目标无关的工具方法来虚增覆盖率指标。本文通过扩展 JaCoCo 实现运行时覆盖率记录的动态切换,使用 ASM 进行离线字节码插桩,将覆盖率记录的激活时机精确限定在目标方法执行期间,确保覆盖率指标真实反映目标行为而非偶发的框架初始化代码。
研究智能体是整个工作流的起点,负责将目标方法签名转化为关于 API 语义的结构化知识。智能体以目标方法的签名、文档和源码作为初始上下文,随后通过 MCP 工具接口按需迭代查询额外的文档和源码,追踪所需的初始化序列、工厂方法用法和隐式前置条件。研究阶段的输出是一份结构化的自然语言研究报告,采用预定义的 Markdown 章节组织发现内容,在不约束内容为刚性模式的前提下适应多样化的 API 设计。
合成智能体接收研究报告,生成初始桩代码,处理参数构造、对象状态初始化和异常处理契约。异常处理是桩代码合成的关键挑战:智能体必须区分代表预期 API 行为的异常(如 IllegalArgumentException,应被捕获以继续模糊测试)与指示真实漏洞的意外异常(必须传播给 Jazzer 的崩溃检测机制)。将研究与生成分离的设计防止了上下文饱和:研究阶段广泛探索而不承诺代码结构,生成阶段则专注于产出语法正确的桩代码。若编译失败,编译修复智能体通过分析编译器诊断信息、查询源码和文档来理解根本原因,迭代产出修正代码直至编译成功或达到迭代上限。
覆盖率引导的精化阶段由覆盖率分析智能体和精化智能体协同完成。系统将方法级覆盖率数据与静态调用图合并,生成一个按调用深度分组、标注覆盖状态的可达方法注释视图。覆盖率分析智能体通过查询未覆盖或部分覆盖方法的源码和文档,判断覆盖率缺口是可解决的桩代码缺陷(缺少输入多样性、未探索的 API 路径)还是根本性限制(不可达的防御性代码、外部 I/O 依赖)。基于这一判断,智能体做出终止决策:若精化收益递减则停止,否则继续并给出针对特定未覆盖方法的策略。精化智能体接收当前桩代码、覆盖率分析策略和注释覆盖率数据,通过多样化输入生成、调用替代 API 路径或触发边界情况异常处理器等策略修改桩代码。代码哈希收敛检测防止系统在语义等价的桩代码变体之间振荡。
实验评估
实验在七个目标方法上展开,涵盖六个广泛部署的 Java 库:命令行解析库 commons-cli(5K+ Maven 依赖)、JSON 库 gson(27K+)和 jackson-databind(36K+)、核心工具库 guava(42K+)、HTML 解析库 jsoup(4K+)以及解析器生成器 antlr4(1K+)。所有目标方法在 OSS-Fuzz 中均有现有桩代码,提供了强有力的基线对比。系统使用 LangGraph 进行工作流编排,底层模型为 Claude Sonnet 4.5(2025-09-29),桩代码使用 Gradle 编译,在带有插桩覆盖率收集的 Jazzer 下执行,每个目标运行 12 小时,使用单个模糊测试线程和空种子语料库。
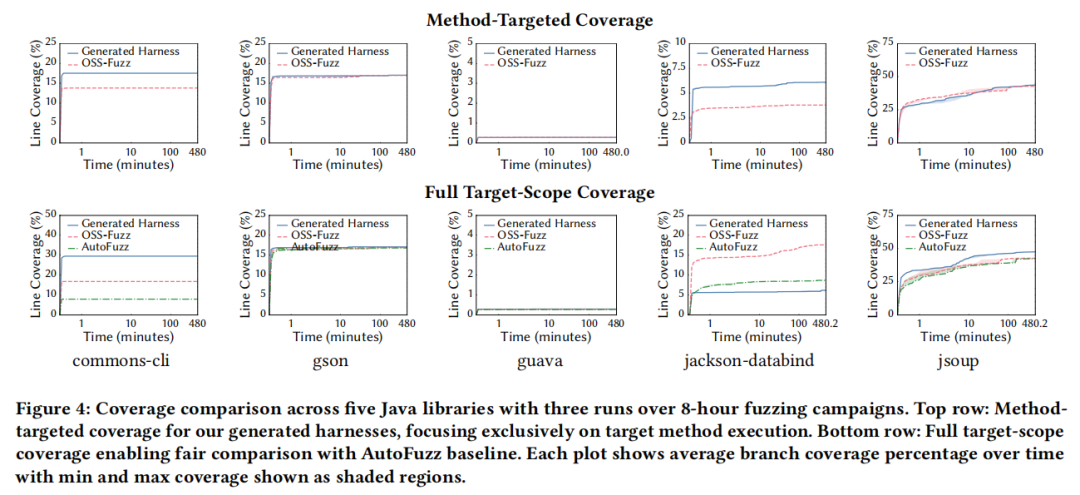
在覆盖率有效性方面,生成的桩代码在方法级覆盖率上比 OSS-Fuzz 基线实现了中位数 26% 的提升,时间动态分析表明主要差异在模糊测试活动早期即可观察到,表明生成的桩代码提供了更好的结构性输入多样性。在全包范围覆盖率下,生成的桩代码比 AutoFuzz 和 OSS-Fuzz 基线分别高出中位数 5% 和 6%。唯一未能超越基线的目标是 jackson-databind,原因在于 OSS-Fuzz 的桩代码在目标方法执行后包含了额外的模糊测试逻辑,导致整体覆盖率更高。
ANTLR4 的案例尤为典型,展示了针对性桩代码生成的优势。OSS-Fuzz 的现有桩代码顺序执行两个目标方法:先从模糊输入创建 Grammar 对象,再调用 createParserInterpreter。这种顺序依赖意味着只有当语法创建不抛出异常时,解析器解释器才能被触发。实验结果显示,OSS-Fuzz 桩代码对 createParserInterpreter 的方法级覆盖率在整个活动期间始终为 0%,说明语法创建始终在到达解析器解释器调用之前抛出异常。相比之下,本文生成的桩代码通过合成满足语法构造器前置条件的输入,成功触发了该方法的执行。
在漏洞发现方面,12 小时模糊测试活动中,生成的桩代码在两个库中共触发了 14 次崩溃,经人工调查确认全部为真实漏洞,零误报。人工分类后归纳为 3 个独立漏洞:commons-cli 中两个不同的空指针异常,分别位于长选项和短选项代码路径,由选项配置与格式错误参数的边界情况组合触发;jsoup 中一个数组越界异常,由约 1KB 的复杂格式错误 HTML 输入触发,构成潜在的拒绝服务攻击向量。这些漏洞均存在于已集成进 OSS-Fuzz 的成熟库中,证明了自动生成的桩代码具备发现真实漏洞的能力。
在生成成本方面,桩代码生成成本从 1.34 美元(guava)到 6.25 美元(commons-cli)不等,平均为 3.20 美元,平均耗时 599 秒(约 10 分钟)。Token 消耗与工作流复杂度直接相关,更复杂的 API 需要更多的研究和精化轮次,而简单目标则更快收敛,体现了系统对目标特性的自适应能力。
相关工作
桩代码生成领域的研究可追溯至多个不同的程序分析传统。基于使用模式的方法以 FUDGE 为代表,从现有消费者代码中切片出可复用的 API 片段;UTopia 则从单元测试中注入模糊输入。这类方法能够捕捉真实的交互模式,但依赖于可用的消费者代码语料。基于结构的方法如 GraphFuzz 构建生命周期感知的数据流图,LibAFL 相关工作引入中间表示以支持大规模库,适用范围更广但缺乏迭代精化能力。基于反馈的方法如 CZZ 等采用自动机学习 API 使用模式,或使用编译时和运行时预言机验证候选桩代码,但普遍依赖领域特定启发式规则或固定覆盖率阈值。
在 LLM 驱动的桩代码合成方向,PromptFuzzing 通过覆盖率引导的提示变异实现迭代精化,但缺乏对覆盖率缺口的语义解读;CKGFuzzer 用代码知识图谱增强 LLM 推理,但需要预处理整个 API 表面。OSS-Fuzz-Gen 等实用工具采用了类似的多智能体工作流,但使用通用源码访问和固定迭代次数。本文的核心区别在于:通过 MCP 提供按需查询的文档、源码和调用图访问,引入专门的静态分析(调用图构建、方法级覆盖率),并将终止决策委托给能够解读覆盖率缺口的智能体,而非应用固定阈值或启发式规则。
结论
本文提出的多智能体桩代码生成系统代表了将 LLM 推理与程序分析深度融合的一次重要探索。五个专职 ReAct 智能体通过模型上下文协议按需查询信息,方法级覆盖率插桩与智能体引导的终止策略共同实现了有效的覆盖率引导精化,整个系统在不依赖消费者代码语料或人工干预的前提下,以实用的成本(平均 3.20 美元、10 分钟)生成了质量与人工编写基线相当甚至更优的桩代码,并在生产级库中发现了真实漏洞。
这一工作的意义不仅在于技术指标的提升,更在于它将高质量桩代码的生成成本降低到了可集成进持续模糊测试工作流的实用水平,有望推动 Java 生态中模糊测试的大规模普及。未来工作方向包括:扩展至有状态 API 的处理、识别最大化库覆盖率的最小方法集以降低生成成本,以及将方法适配至合成基于属性的安全桩代码,以验证超越崩溃检测的不变量。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
