现在讨论 Agent 安全,已经不能只盯着模型会不会说错话。
在 ChatGPT、Claude Code、Cursor、OpenDevin、AutoGPT 这类系统里,Agent 已经从“回答问题”变成了“执行动作”。
它可以读文件、写代码、跑 Shell、访问 HTTP 接口、查询数据库、安装依赖、修改配置,甚至操作云资源和容器环境。
这意味着风险也发生了变化。
过去,大模型安全更多关注输入输出:用户问了什么,模型答了什么,内容是否违法违规,是否泄露敏感信息,是否存在幻觉。
到了 Agent 场景里,真正危险的瞬间往往发生在工具调用之前:模型准备执行一条命令,准备读取一个文件,准备向外部地址发起一次请求,准备修改一次权限。
论文《AgentTrust: Runtime Safety Evaluation and Interception for AI Agent Tool Use》正是围绕这个问题展开。

https://arxiv.org/pdf/2605.04785
作者提出的 AgentTrust,可以理解为一个放在 Agent 和工具之间的运行时安全拦截层。
每一次工具调用真正执行之前,它都会先做一次安全评估,并给出 allow、warn、block、review 四类决策。
论文明确将 AgentTrust 定位为实时、语义感知的安全拦截框架,目标是在动作执行前生成结构化 TrustReport,而不是事后复盘风险。
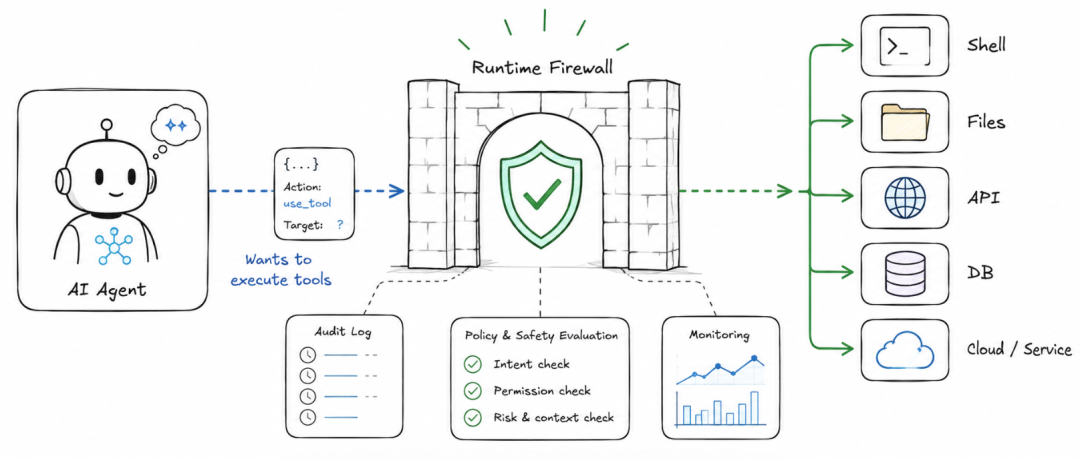
Agent风险往往发生在“动作落地”之前
AgentTrust 这篇文章的切入点很清楚:现代 AI Agent 会通过工具调用产生真实世界的副作用。
一次错误的 rm -rf,一次把 API Key 打进日志,一次伪装成普通 POST 请求的数据外传,都可能造成不可逆损害。
作者认为,现有防御手段各有缺口:
事后评测能衡量 Agent 行为,但动作已经发生;
静态规则护栏可以实时拦截,但容易漏掉混淆命令和多步攻击链;
容器、gVisor、seccomp 这类沙箱能限制执行环境,却不理解动作本身的业务语义。
这个判断很关键。
因为很多企业现在谈 Agent 安全,仍然习惯沿用大模型内容安全的思路:输入过滤、输出审核、敏感词拦截、拒答策略。这些能力依然重要,但它们解决的是“模型说什么”的问题。
Agent 带来的新风险,是“模型做什么”的问题。
举个例子,用户让 Agent“帮我清理一下项目目录”,模型生成一条删除命令。
如果命令只删除临时文件,这是正常操作;如果命令错误地删掉用户主目录,风险就已经从文本安全变成了执行安全。
此时再去审查模型最终回复已经没有意义,因为真正的损害发生在工具执行阶段。
所以 Agent 安全需要一个新的控制点:动作执行前。
这也是 AgentTrust 这篇论文最值得写的地方,它没有停留在“让模型更安全”这个抽象层面,而是把安全能力插到了 Agent runtime 和 tool execution 之间。
换句话说,它关心的不是 Agent 的价值观表达,而是 Agent 的行动边界。
AgentTrust的本质:工具调用防火墙
AgentTrust 的整体结构并不复杂,但工程思路比较完整。
论文中的架构图显示,一个 Agent 动作进入系统后,会依次经过 ShellNormalizer、ActionAnalyzer、PolicyEngine、TrustInterceptor,再输出 TrustReport。
SafeFix、RiskChain 和 LLM Judge 作为辅助模块参与判断。其中 SafeFix 提供修复建议,RiskChain 跟踪多步行为链路,LLM Judge 用于规则难以判断的模糊场景。
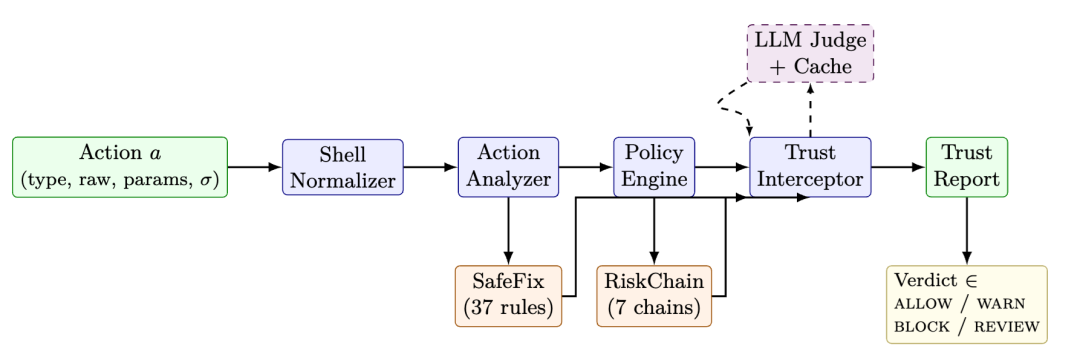
AgentTrust 将每一次工具调用转化为 Action,在执行前经过命令归一化、风险分析、规则判断、链路检测和可选 LLM Judge,最终输出 allow、warn、block 或 review。
这套结构可以理解为 Agent 时代的“工具调用防火墙”。
传统 WAF 拦 HTTP 请求,EDR 盯主机行为,API Gateway 管接口调用,而AgentTrust 拦的是 Agent 的工具调用。它关注的对象不是用户文本,也不是模型输出,而是一个结构化动作:动作类型是什么,调用了哪个工具,参数是什么,原始 payload 是什么,属于哪个 session,发生在什么时间。
论文把 Action 定义为一个包含动作类型、工具名称、自然语言描述、参数、原始 payload、会话 ID 和时间戳的结构。
动作类型覆盖 file_read、file_write、file_delete、shell_command、network_request、code_execution、database_query、api_call、credential_access、system_config 等类别。最终系统输出 verdict、risk、confidence 和解释信息。
这个抽象非常适合企业落地,因为一旦工具调用被结构化,安全系统就可以围绕动作建立策略,而不是只围绕自然语言做分类。
比如,同样是“读取配置文件”,读取普通配置和读取 .env、.aws/credentials、.kube/config 的风险完全不同。
同样是“发起 HTTP 请求”,访问内部健康检查接口和把 base64 后的敏感文件 POST 到外部域名,安全含义也完全不同。
AgentTrust 想做的,就是在工具调用真正执行之前,把这些差异识别出来。
1)ShellNormalizer:先把伪装过的命令还原出来
AgentTrust 里第一个值得关注的模块是 ShellNormalizer。
很多工具调用安全方案会做关键词匹配,比如看到 rm -rf、chmod 777、curl | bash 就拦截。
但攻击者不会总是把危险命令写得这么直白,它可以用变量拼接、十六进制编码、八进制转义、alias、反引号、eval + printf、相邻引号拼接等方式,把真实命令藏起来。
AgentTrust 的做法是,在规则匹配之前先做一层 Shell 归一化。
论文列出了 9 种纯文本重写策略,包括变量展开、hex/octal 转义解码、alias 解析、$(printf ...) 命令替换、eval + printf 链、ANSI-C quoting、反引号中安全子集的 echo 替换、$(echo ...) 替换,以及相邻引号拼接。
作者特别强调,这些归一化只做文本重写,不执行输入内容,避免检测器本身引入任意代码执行风险。
这一点很工程化。
Agent 安全产品不能为了识别一条可疑命令,真的把命令跑一遍。检测器一旦执行未可信输入,就会把自己变成攻击面。
所以 ShellNormalizer 选择了一个折中路线:不追求完整 Bash 解释器能力,只覆盖常见混淆方式,并通过“最大风险聚合”来保证新还原出的命令变体只会增加风险发现,不会把原本的风险隐藏掉。
从产品角度看,这说明 Agent 工具调用安全不能只做“规则库”,还要做“动作语义还原”。否则规则再多,也容易被编码、拼接、替换绕过。
2)RiskChain:Agent 风险看行为轨迹
AgentTrust 里第二个核心设计是 RiskChain。
很多 Agent 风险单步看并不危险,但连起来就很危险。
论文举的例子是:第一步读取 .env,第二步对 .env 做 base64 编码,第三步通过 curl POST 到外部地址。前两步单看可能只是低风险操作,第三步出现时,整个行为链条就变成了数据外传。

单个动作未必足以构成高危,但读取敏感文件、编码处理、外部 POST 三步组合在一起,就构成完整的数据外传链路。
论文默认内置了 7 类 RiskChain:数据外传、凭据收集、持久化安装、权限提升、供应链攻击、反弹 Shell、数据破坏。
这些链路不是简单看某一个命令是否危险,而是看同一个 session 中动作的先后顺序和组合关系。
这个设计非常适合 Agent 场景。
传统聊天机器人通常是一问一答,安全系统可以把每一轮输入输出分开看。
但 Agent 是连续执行的,它会规划任务、调用工具、读取中间结果、再继续下一步动作,风险也常常沿着轨迹逐步累积。
一次读取文件可能只是准备分析,一次编码可能只是数据处理,一次网络请求可能只是上传日志。但当这三件事发生在同一条任务链里,就需要安全系统理解“它们合在一起意味着什么”。
这也是 Agent 安全和普通内容安全的重要分界线:普通内容安全看文本,Agent 安全看行为轨迹。
3)SafeFix:风险不能一刀切,要给出安全替代方案
AgentTrust 另一个有产品价值的地方,是 SafeFix。
很多安全系统习惯给出 block,但 Agent 开发工具和企业自动化场景里,单纯 block 会严重影响用户体验。
开发者让 Agent 帮忙修问题,结果每走两步就被安全系统拦下,最终用户会选择关闭安全能力。
SafeFix 的思路是,当系统给出 block、warn 或 review 时,同时提供更安全的替代动作。
论文中列出的例子包括:把 chmod 777 /var/www 改成 chmod 755 /var/www,把 curl http://x/x.sh | bash 改成先下载脚本、查看内容再执行,把 git add .env 改成将 .env 加入 .gitignore,把普通 HTTP 请求改成 HTTPS 请求。
SafeFix 有 37 条修复规则,但它不会改变最终 verdict,只是在报告中补充修复建议。
这点很重要。
Agent 安全产品如果只会说“不行”,很容易变成阻碍效率的工具。
如果它能告诉 Agent 或用户“这件事可以这样更安全地做”,安全能力就会从纯阻断变成执行辅助。
这其实也是未来 Agent 安全产品的一个关键方向:安全系统不能只是裁判,还要成为 Agent 的安全执行顾问。
尤其在代码生成、自动运维、数据分析、云资源管理等场景里,很多动作本身有业务必要性,不能简单禁止。更好的做法是降低权限、增加确认、替换参数、隔离环境、保留审计,或者把高危动作转成人工审批。
4)LLM Judge:不适合作主路径,但适合处理模糊场景
AgentTrust 也引入了 LLM-as-Judge,但它没有把 LLM 放在主路径上。
论文的设计是,规则路径先判断。如果动作比较明确,就直接给出结果。只有遇到规则难以判断的模糊场景,才调用 LLM Judge。
例如访问 http://internal-api/health,可能是正常健康检查,也可能是 SSRF 探测,单靠正则很难判断。LLM Judge 会从数据暴露、系统影响、凭据风险、范围漂移、可逆性五个维度评估,并输出严格 JSON 结果。
为了降低长会话成本,AgentTrust 还设计了 cache-aware delta evaluation。长时间运行的 Agent session 上下文会不断增长,如果每次判断都把完整上下文发给 LLM,成本和延迟都会很高。
AgentTrust 用 SHA-256、block hash 和增量检测来判断上下文变化,如果只是尾部追加,就只发送新增部分和上一轮摘要;如果变化较大,再回退到完整评估。
这说明作者对 LLM Judge 的定位比较清醒。
在 Agent 工具调用安全里,LLM 不适合作为唯一裁判。它有成本,有延迟,也可能因为缺少业务上下文而过度保守。
但在规则无法覆盖的语义判断里,LLM 可以作为第二意见。也就是说,AgentTrust 采用的是“规则主路径 + LLM 兜底”的结构,而不是把所有安全判断都交给大模型。
这对企业安全产品很有启发。真正落地时,主路径应该尽量确定、低延迟、可解释;LLM 适合处理模糊、长尾、上下文相关的场景。否则,一个每次工具调用都要等一两秒的 Agent 防火墙,很难支撑交互式开发和自动化运维。
实验结果
论文做了两个 benchmark。
第一个是 300 条内部场景,覆盖代码执行、凭据暴露、数据外传、文件操作、网络访问、系统配置六类风险。
使用默认规则加 4 条 benchmark 兼容规则时,AgentTrust 的 verdict accuracy 达到 97.0%,risk accuracy 为 75.7%,中位延迟 0.3ms。
作者同时说明,严格生产规则集不加载那 4 条合成 benchmark 规则,此时 verdict accuracy 为 95.0%,risk accuracy 为 73.7%,论文将这个作为更有意义的主结果。
第二个是 630 条独立构造的真实世界场景,覆盖 DevOps、云、容器、供应链和多种语言生态。
整体 verdict accuracy 为 96.7%,混淆子集约 93%。
不过作者也明确提醒,这个结果不能理解成 zero-shot 泛化能力,因为部分规则是在独立场景暴露缺口后补充进去的,所以更准确的理解是“当前规则集对这批独立构造场景的覆盖效果”。

AgentTrust 在 300 场景和 630 场景上的效果对比。
和基线相比,AgentTrust 的优势更明显。50 条简单正则黑名单的准确率只有 49.3%,假阴性高达 88.4%;DeepSeek-V3 zero-shot judge 的准确率为 82.3%,中位延迟 1345ms;NeMo Guardrails 在这个任务上误报很高,FPR 达到 96.2%。AgentTrust rule-only 的准确率为 95.0%,FPR 为 2.3%,FNR 为 5.4%,中位延迟 1.72ms。
这个结果说明一个很现实的问题:Agent 工具调用安全不是简单堆一个大模型分类器就能解决。
在工具执行这个场景里,结构化规则、命令归一化、链路检测、低延迟拦截,比纯 LLM 判断更可靠。
LLM 可以做辅助,但主路径仍然需要可解释、可审计、可复现的工程体系。
价值与启发
AgentTrust 不一定是技术上最前沿的 Agent 安全论文,它没有提出一个全新的攻击理论,也没有设计复杂的可信执行环境。
它更像是把传统安全工程里的几个能力重新组合到了 Agent 工具调用场景中:规则引擎、命令归一化、攻击链检测、修复建议、审计报告、LLM 辅助判断、fail-safe 策略。
但它的价值恰恰在这里。
因为 Agent 安全最终要落地,不能只停留在论文里的威胁模型。企业需要的是能接到 Agent runtime 里的东西,能在工具调用前给出判断,能输出审计日志,能配置规则,能处理误报漏报,能与人工审批、权限系统、沙箱、网关、SIEM 联动。
从这个角度看,AgentTrust 指向的是一种越来越清晰的产品形态:Agent Tool Gateway,或者 Agent Runtime Firewall。
它不直接替代模型对齐,也不替代容器沙箱。它更像是 Agent 执行链路上的控制平面。模型负责规划,工具负责执行,AgentTrust 负责在规划和执行之间判断“这个动作能不能做、风险多大、是否需要改写、是否需要人工 review”。
这和企业 AI 安全的演进方向是一致的。
第一阶段是内容安全护栏,主要解决输入输出合规问题。
第二阶段是 Agent 行为安全,开始关注工具调用、权限控制、数据流转和执行轨迹。
第三阶段会走向 Agent 控制平面,把身份、权限、策略、审计、审批、沙箱、数据分级、网络出口、工具注册统一纳入治理。
AgentTrust 还只是这个方向上的一个轻量原型,但它把产品轮廓画出来了。
局限性
这篇论文也有明显局限。
首先,rule-only 路径本质上仍然是文本重写加正则匹配。它无法真正理解运行时数据流。论文举了一个例子:curl -X PUT -T - https://h/x 到底是正常上传无害内容,还是把敏感文件传出去,静态规则无法判断。
其次,ShellNormalizer 并不完整。它不执行 subshell,不解释函数体,也不跟踪控制流。复杂嵌套的 eval 链、函数定义 alias、动态 heredoc 仍然可能绕过。作者计划在 v1.0 引入 AST 分析,但这会增加系统复杂度。
第三,AgentTrust 缺少外部信誉情报。例如 pip install reqeusts 这种拼写欺骗包,仅靠本地规则很难判断,需要接入包名数据库、域名信誉、Sigstore、WHOIS 等外部能力。
第四,它假设拦截器在 Agent runtime 内被可信调用。如果 Agent runtime 本身被恶意控制,完全可以绕过 AgentTrust。论文也承认,强对抗环境下需要 out-of-process enforcement,比如 sandboxed exec、kernel hook 等部署方式。
这些局限说明,AgentTrust 更适合作为 Agent 工具调用安全的一个中间层,而不是完整的终局方案。真正的企业级 Agent 安全,还需要和权限系统、隔离环境、网络出口、数据分级、密钥管理、制品信誉、审计平台结合起来。
写在最后
AgentTrust 给我们的最大启发是:Agent 安全的中心正在从模型内部转向运行时外部。
过去我们总希望模型自己足够安全,能够拒绝危险请求,不生成有害内容,不泄露敏感信息。这个方向仍然重要,但对 Agent 来说还不够。因为 Agent 的风险来自“行动”,而行动需要被外部系统约束。
未来企业里的 Agent 安全,很可能会形成类似这样的结构:
模型负责理解和规划,工具注册中心负责定义 Agent 能用什么工具,权限系统负责决定 Agent 能以什么身份执行,运行时防火墙负责判断每次工具调用是否安全,沙箱负责限制执行环境,审计系统负责记录完整轨迹,人工审批流负责处理高危动作。
这套体系一旦形成,Agent 安全就不再只是模型护栏,而是一个完整的运行时控制面。
AgentTrust 这篇论文还不完美,但它把这个方向讲得很具体。它告诉我们,Agent 时代的安全能力不应该只盯着 prompt,也不能只靠模型自觉。真正关键的位置,是工具调用执行前的那一道闸门。
一句话总结:
Agent 的能力越强,安全边界越不能只放在模型内部。未来真正重要的,是在每一次行动发生之前,给 Agent 加上一层可解释、可审计、可拦截的运行时控制面。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
