本文首发自公众号:EnsecTeam
Part 1 引言
在大型互联网公司中,面对5万+域名、7千万+的url,同时线上服务各种开源软件随意使用,各团队研发实力及各服务承压能力参差不齐,在人力极其有限的情况下,漏洞检测想做好其实压力和挑战非常大。你经常需要反省为啥漏洞发现时间滞后于外界白帽子,为啥漏洞未被扫描发现;如何保证扫描的超高准确率,如何保证线上扫描不影响服务正常运行;扫描存在异常时如何监控报警并自动恢复,外界爆出0day时如何做到不影响正在运行的扫描任务而通过调度使应急任务得到快速响应执行,扫描框架或POC更新时如何热备自动上线,如此等等;这里面的任何一点想做好挑战和困难都挺大,我们经过几年的实践,在这些方面有了一些自己的感悟,这里分享给大家。
Part 2 扫描服务形态演变
做Web漏洞检测这块好几年,漏洞检测的形态也经过了几次演变,由最开始的单机形态到集群,更多的是解决公司URL量太大导致可接受时间范围内无法扫描完成的窘境。
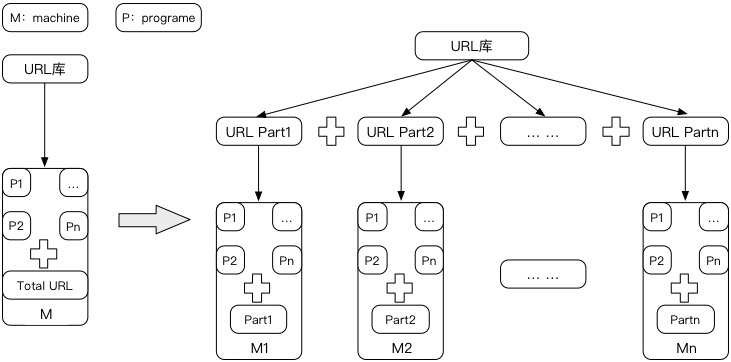
通过集群的确可以减少扫描的时间,但随之而来的是机器的非饱和使用导致资源的极度浪费,慢慢集群形态向分布式形式转换:
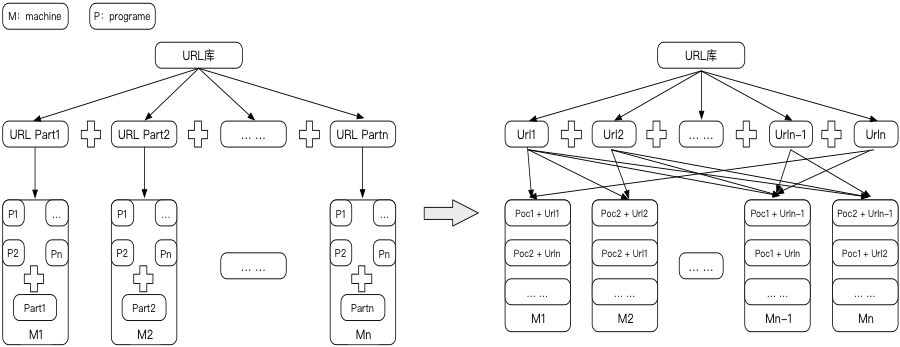
一台物理机根据其CPU核数及内存情况被虚拟成多台容器,以"单Poc+单Url"为基本单元,调度程序以基本单元为维度分配到存活的每台空闲虚拟容器中执行,降低了资源的浪费;同时分布式形态也能更好的满足应急扫描、容灾恢复等场景,具体后续再细说。扫描形态的转换过程中,独立的扫描脚本向集中的扫描框架方式转变也随之发生。
Part 3 扫描体系构建
基于分布式的集群形态,最终的扫描体系结构图如下:
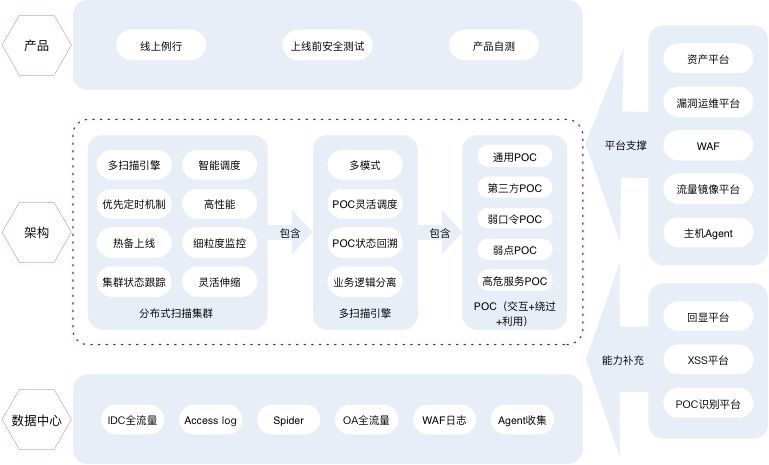
扫描场景及产品
整个扫描体系是基于云的分布式扫描平台,根据使用场景拆分为三个子平台,覆盖项目上线前及线上运行;其中上线前安全测试针对项目上线前进行漏洞提前发现,避免将安全漏洞带入到线上;线上例行是安全团队对线上所有业务进行完全自动化的每日例行漏洞巡检;产品自测则是提供给业务方针对线上业务一种安全自查方式,三者互补提升漏洞检测整体覆盖面。
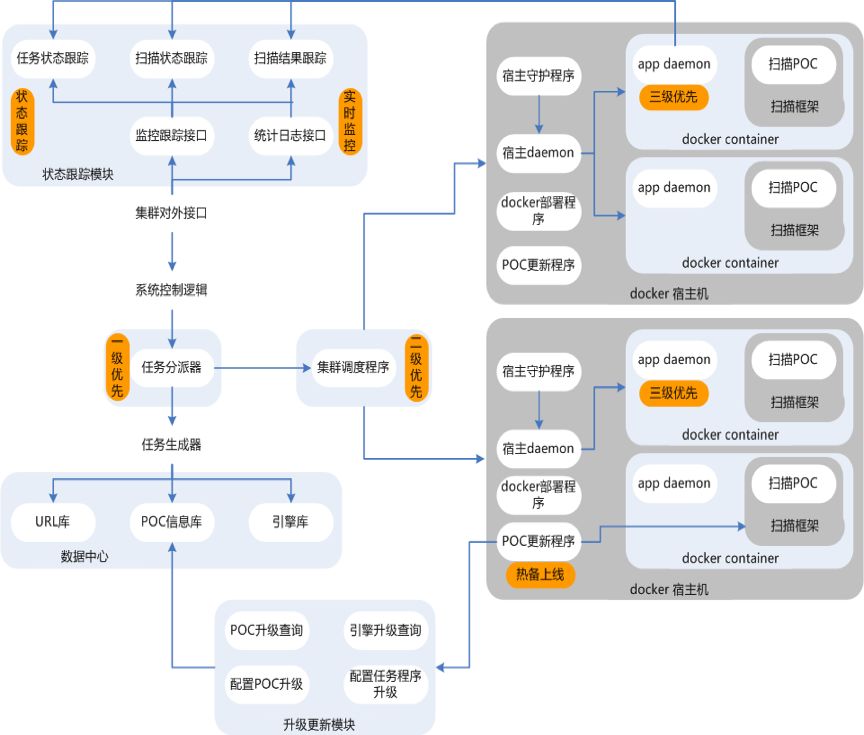
扫描架构及突出问题点
集群中每台物理机虚拟化成多个docker容器,每个docker容器中部署多扫描引擎镜像,引擎根据调度程序分配的基本单元,再去加载具体扫描能力poc运行特定的url;其中每个部分功能点简单介绍如下:
扫描集群支持优先级扫描、热备上线、url粒度监控及跟踪、扫描状态实时展示、容器粒度调度及伸缩;
扫描框架支持poc及fuzz模式、poc粒度扫描状态跟踪及灵活调度、集成通用逻辑简化poc开发实现;
Poc除了传统扫描思路外,加入交互式探测思路,同时考虑逻辑绕过+利用验证机制,并结合回显平台、poc自动识别平台等来做到扫描能力的足够全的覆盖面和持续自我完善能力。
整个扫描架构涉及内容太多,就不一一细说了,主要拿之前的一个版本升级解决的几个case举例来说吧。做漏洞扫描服务的同学经常会对几个问题比较困惑或者无奈:
(1)扫描漏报排查
扫描POC明显覆盖但就是没有扫出,而且还被SRC报告,对负责扫描的同学来说不可接受(其实特别打脸,偷笑);此时进行漏报排查必须要去复查扫描当时的场景(有可能刚好扫描后业务有变化导致引入的漏洞,或者刚好扫描时那个节点有异常等,其实各种情况都可能引起漏报);当时扫描的信息就至关重要了:当时URL库中是否存在该url?是否在扫描集群中扫描过?曾经一共扫描了多少次?分别在什么时候扫描的?是在扫描集群的哪个节点上扫描的?当时扫描时该扫描节点是否存在异常?扫描poc是否存在异常?扫描集群是否存在异常?当时扫描时扫描结果是?工单是否推送正常?甚至于当时的响应是?这些我们统统需要知道。
为了解决这个问题,我们记录了一个URL从数据中心取出,到扫描集群、扫描框架、扫描节点、结果入库、工单推送等各个阶段所发生的一切关键行为,一旦有漏报发生排查就会比之前容易很多,以前基本就是无可奈何(没有当时场景,我能怎么办?怪我咯)。
(2)异常监控及诊断恢复
之前扫描存在异常时我们无法及时感知,往往都是外界报告了一个case,我们去排查才发现,这种其实就比较滞后和被动了;需要一种手段去感知异常,存在异常时能够自动报警,甚至在特定的场景下能够自动恢复续扫或者重扫。
为了漏扫排查我们记录了很多关键信息,在此基础上,我们慢慢发现异常监控也好做了,比如其实可以提前大概计算或者统计每种poc大概的平均扫描耗时,当poc真实在扫描节点上扫描时一旦明显偏离这个基准耗时,就可以认为这里存在一个异常点并进行记录,可以简单调度扫描框架重新扫描这个单元("单poc+单url");比如当类似的异常点突然在某一时间点报出的特别多,此时就可以进行报警了,很有可能我们的扫描集群此时不健康需要人为干预排查。还比如一个扫描任务下发后,发现一个基本单元超时未返回结果,一样可以自动诊断并处理;还比如可以监控一段时间库中URL的入库量是否有异常、每天及每周的漏洞产出是否有异常(总漏洞产出量,单个poc漏洞产出量与基准值的对比衡量)、总的扫描时间是否有异常等,及对应的自动诊断恢复机制,最终判断是否需要人为干预。
(3)扫描优先级
由于扫描平台需要为测试环境,线上环境等进行测试服务,并且业务量本身就很大,导致扫描集群一直都是满负荷在运行,但是平时实际过程中,经常会有应急响应需求,需要进行应急扫描,此时如何保证紧急的任务能够第一时间执行呢?
以前只能等待扫描任务完成(可能需要等待很长时间,这是所不能接受的),才能执行本次紧急任务;为了不耽误紧急任务的执行,甚至平时只能搭建一个空闲集群,专门用于紧急任务执行,但是资源严重浪费;那是否可以考虑通过单一集群即可解决优先级的问题呢?
当然可以,通过优先级机制即可解决,优先任务优先分配、优先调度、优先扫描,通过三级优先队列来解决紧急扫描问题;同时在任务分配时候,以“单poc+单url”作为最小粒度,考虑poc发包量基础上,按照可用扫描节点进行平等拆分,这样即使集群没有空闲节点,一旦有紧急任务需要扫描,那么任务所需等待的时间最理想情况下将只需要等待“单个poc+单个url”所需要的扫描时间(资源足够情况下,这种理想情况其实很大概率会发生),这种不用浪费资源即可满足优先扫描难题。
(4)热备上线
安全扫描poc在方案调研及实现过程中,由于调研的不全面或者考虑的不严谨,肯定会出现误报或者漏报问题,这时候就需要通过更新poc予以解决,现在的难点是:扫描集群时刻都有任务在运行,为了更新任务只能热备上线,不然只能将未跑完的任务全部kill掉,这样既浪费扫描资源,又严重影响扫描及时度;通过内置升级更新模块,做到不干扰当前运行任务情况下,更新节点扫描镜像,做到热备上线。
数据中心建设
接下来简单说下数据中心这部分,数据中心主要负责纯净url的收集入库,解析程序每天解析T级别的日志,如果不去重的话将得到亿级别的url,为了保证扫描的及时度,需要对url进行去重去脏,主要通过hash机制进行:
https://www.baidu.com/test.php?a=1&b=2&c=3
https://www.baidu.com/test.php?c=10&a=20&b=30
针对每条URL,去掉参数值并根据key进行排序,计算hash =md5("https://www.baidu.com/test.php?a&b&c"),相同的认为两条URL是相似的,只保留一条URL即可(ps:当然这里存在后端代码逻辑覆盖不全的问题,因为有些后端逻辑是根据参数值进行判断的,覆盖这部分逻辑会导致待扫描的URL量急剧增加,被迫做了取舍,无奈的表情)。同时计算hash的时候还需要考虑几种特殊case:
path中含有随机字符串,比如:
/a/99c5e07b4d5de9d18c350cdf64c5aa3d
替换后:/a/U
/a/289dff07669d7a23de0ef88d2f7129e7
替换后:/a/U
计算hash之前替换随机字符串为特定的字符U,则上面两者可认为是相似的;同样path中包含有数字的(/a/123456789及/a/345678901)、中文编码的(/a/%E5%AE及/a/%E5%8F)也需要进行类似处理(严谨情况下用等同长度的U进行替换然后再计算hash,主要是扫描及时度和扫描的覆盖率之间的取舍)。
除了这些具有明显特征的case外,其实还存在很多无规则的case;本质我们其实是需要一种方法去判别path中伪静态的部分(path中根据"/"进行分割),针对伪静态的部分用相同长度的字符U进行替换即可;考虑用机器学习方法以分割部分的字符数量作为feature去判别,大部分的case其实都可以很好的识别出来,但不能很好区分纯小写字符的case,比如/api/yehdhee这种,最终通过引入Markov Chain来进行区分,基本可以解决。
除了去重去脏外,还需要定期对库中已存在的url进行存活判断、404判断等,针对这部分url需要定期进行删除处理;不过url存活判断务必放在扫描脏数据净化之后(特指带有扫描攻击payloads的url),不然你可能会不幸成为攻击者攻击自身业务的帮手(偷笑)
Part 4 总结
扫描服务累计在线上运行好几年了,到目前为止已经非常成熟,基本做到了无需人为干预(存在重大bug时其实还是需要人为干预,偷笑),存在异常时自动监测报警并自动排查恢复,POC更新时自动热备更新、高优任务第一时间优先执行而不影响之前正常运行的扫描任务,扫描出来的漏洞准确率达到98%以上基本可以做到无需人工check,输入源URL存在的情况下漏报率更是控制在0.5%以下,每天例行的任务控制在2小时内结束,漏洞发现及时度大幅提升,高危漏洞滞后于外界白帽子的case少之又少(输入源url不缺失情况下),基本实现了我们之前的预期及目标。同时也深深领悟了一句话"扫描技术虽已成熟,但只有精心耕耘方能知晓其精髓,而刚触及其精髓才知挑战依旧",分享给大家。
本文只是简单概述了整个扫描体系,如果对扫描集群、扫描框架、扫描POC、扫描策略等详细做法感兴趣的小伙伴可以继续关注后续"分布式Web漏洞扫描服务建设实践"系列技术文章。
声明:本文来自EnsecTeam,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
