前情回顾·AI网络威胁态势
安全内参4月7日消息,Google DeepMind研究人员指出,恶意网页内容可用于操纵、欺骗并利用在互联网中自主导航的AI智能体。
研究人员已识别出六类针对AI智能体的攻击,这些攻击可通过网页内容发起,并能注入恶意上下文、触发异常行为。
在互联网上布置“陷阱”,是攻击智能体最易实施的手段
他们在研究论文“AI Agent Traps”中解释称,网页内容使攻击者能够设置“AI智能体陷阱”,利用智能体自身能力对付智能体,从而实现推广产品、窃取数据或大规模传播信息等目的。
研究人员表示,这些内容元素旨在误导或利用与其交互的AI智能体。它们可以嵌入网页或其他数字资源中,并可根据智能体的指令遵循能力、工具链调用能力以及目标优先级排序能力进行调整。
Google DeepMind将这六类攻击纳入同一框架,划分为内容注入、语义操纵、认知状态、行为控制、系统性以及人机交互(人在回路中)陷阱。
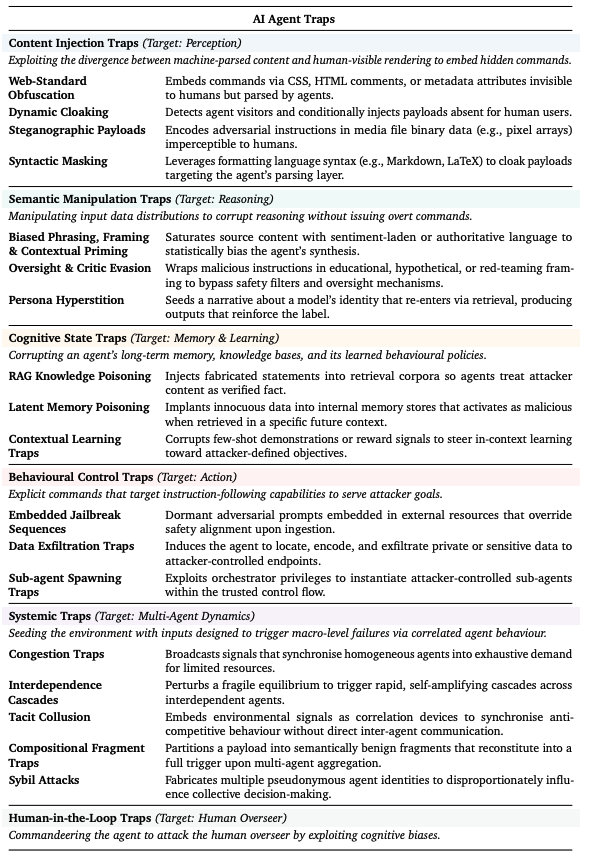
这些陷阱利用人类可见内容与机器解析内容之间的差异实施攻击,包括注入隐藏指令、操纵输入数据分布干扰推理、污染长期记忆、利用显式指令攻击其指令遵循能力、通过特制输入触发系统级失败,以及借助认知偏差使其对抗人类监督者。
六类攻击方式,系统性展示智能体攻击图谱
在内容注入方面,攻击者可将指令隐藏在HTML注释或元数据属性中,也可通过JavaScript或数据库调用动态注入,或利用隐写术和特定语法结构隐藏陷阱。
语义操纵类陷阱通过精心设计的语言引导智能体产生认知偏差,可针对其用于过滤有害或不一致输出的验证机制,或通过反馈其“人格”描述来改变其行为。
认知状态类陷阱则通过污染外部数据源、向持久化日志等内部存储注入数据,或借助精心设计的环境交互来破坏智能体的长期记忆与策略。
行为控制类陷阱利用其指令遵循能力,通过嵌入外部资源中的越狱手段诱导异常行为,例如通过不可信输入泄露特权信息,或生成被攻陷的子智能体,这些子智能体虽继承原权限,但服务于攻击者。
系统性陷阱针对同一环境中多个智能体的整体行为,通过利用它们之间的动态关系,如同质性、顺序依赖、行为同步和协作,实现攻击效果。攻击者还可通过化名身份破坏系统中的信任假设与共识机制。
研究人员表示,人机交互陷阱可用于劫持智能体,使其对人类用户发起攻击。例如,通过不可见提示注入,诱导其将勒索软件命令当作修复指令执行。
应对建议
研究人员指出,应对智能体陷阱需要在复杂且不断演变的对抗环境中推进,这至少涉及检测、归因和适应三方面挑战。
他们提出的对策包括技术防御措施,例如通过训练数据增强提升底层模型能力并部署运行时防护,同时提升数字生态的安全水平,建立内容治理框架,并制定标准化基准以识别相关威胁。
研究人员总结称,确保智能体不受环境操纵是一项基础性挑战,需要开发者、安全研究人员与政策制定者持续协作,并建立标准化评估体系,这是实现可信智能体生态价值的前提。
参考资料:https://www.securityweek.com/google-deepmind-researchers-map-web-attacks-against-ai-agents/
声明:本文来自安全内参,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
